

根據位元組部分解析文件

php小編百草為您介紹一種根據位元組部分解析檔案的方法。這種方法可以讓我們在處理大型檔案時,不需要一次載入整個檔案到記憶體中,而是根據需要逐步解析檔案內容。這種方式不僅可以減少記憶體佔用,還可以提高程式的運作效率。具體的實作方法是,我們可以透過設定一個緩衝區,每次從檔案中讀取一定數量的位元組到緩衝區中,然後逐步解析緩衝區中的內容,直到完成檔案的解析。這種方法可以應用於各種文件解析場景,例如日誌檔案解析、大型資料檔案解析等。
問題內容
我正在解析一個文件,該文件是逐字節讀取的,我有關於哪個位元組代表文件的哪一部分的說明。
訂單檔:
-
前 4 個位元組是版本
-
接下來的 4 個位元組是一個整數,表示預期的訂單數量。
-
對於每個訂單(從 #2 開始),4 位元組整數是訂單 id。
為了解析這個,我先載入檔案:
file, err := os.Open("orders.abc")
version := make([]byte, 4)
c, err := file.Read(version)
fmt.Printf("read %d, version is %d", c, version)
orderCount := make([]byte, 4)
c2, err := file.Read(orderCount)
fmt.Printf("read %d, orderCount is %d", c2, orderCount)
for i := 0; i < orderCount_as_int; i++ {
orderId := make([]byte, 4)
c3, err := file.Read(orderId)
}是否有更優雅的方式來解析這樣的檔案?
另外,如何將 version/ordercount 轉換為整數以便我可以使用該值?
解決方法
您想要使用 encoding/binary.read 而不是直接呼叫 read。例如
var version int32 err := binary.Read(file, binary.LittleEndian, &version)
(您還需要知道檔案中的資料是大端還是小端,並選擇適當的位元組順序)。二進制包將為您進行解碼。
以上是根據位元組部分解析文件的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 華為手機記憶體不足怎麼辦(解決記憶體不足問題的實用方法)
Apr 29, 2024 pm 06:34 PM
華為手機記憶體不足怎麼辦(解決記憶體不足問題的實用方法)
Apr 29, 2024 pm 06:34 PM
華為手機內存不足已經成為許多用戶面臨的常見問題、隨著行動應用程式和媒體檔案的增加。幫助用戶充分利用手機的儲存空間、本文將介紹一些實用方法來解決華為手機記憶體不足的問題。 1.清理快取:歷史記錄以及無效數據,以釋放記憶體空間,清除應用程式產生的臨時檔案。在華為手機設定中找到「儲存」點擊,選項「清除快取」按鈕即可刪除應用程式的快取檔案。 2.卸載不常用的應用程式:以釋放記憶體空間,刪除一些不常用的應用程式。拖曳到手機螢幕上方的、長按要刪除的應用程式圖示「卸載」然後點擊確認按鈕即可完成卸載,標誌處。 3.移動應用到

 AI 潮影響明顯,TrendForce 上修本季 DRAM 記憶體、NAND 快閃記憶體合約價漲幅預測
May 07, 2024 pm 09:58 PM
AI 潮影響明顯,TrendForce 上修本季 DRAM 記憶體、NAND 快閃記憶體合約價漲幅預測
May 07, 2024 pm 09:58 PM
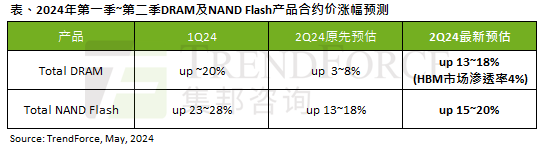
根據TrendForce的調查報告顯示,AI浪潮對DRAM記憶體和NAND快閃記憶體市場帶來明顯影響。在本站5月7日消息中,TrendForce集邦諮詢在今日的最新研報中稱該機構調升本季兩類儲存產品的合約價格漲幅。具體而言,TrendForce原先預估2024年第二季DRAM記憶體合約上漲3~8%,現估計為13~18%;而在NAND快閃記憶體方面,原預估上漲13~18%,新預估為15 ~20%,僅eMMC/UFS漲幅較低,為10%。 ▲圖源TrendForce集邦諮詢TrendForce表示,該機構原預計在連續
 Edge瀏覽器記憶體佔用太多怎麼辦 記憶體佔用太多的解決方法
May 09, 2024 am 11:10 AM
Edge瀏覽器記憶體佔用太多怎麼辦 記憶體佔用太多的解決方法
May 09, 2024 am 11:10 AM
1.首先,進入Edge瀏覽器點選右上角三個點。 2、然後,在工作列中選擇【擴充】。 3、接著,將不需要使用的插件關閉或卸載即可。
 deepseek怎麼本地微調
Feb 19, 2025 pm 05:21 PM
deepseek怎麼本地微調
Feb 19, 2025 pm 05:21 PM
本地微調 DeepSeek 類模型面臨著計算資源和專業知識不足的挑戰。為了應對這些挑戰,可以採用以下策略:模型量化:將模型參數轉換為低精度整數,減少內存佔用。使用更小的模型:選擇參數量較小的預訓練模型,便於本地微調。數據選擇和預處理:選擇高質量的數據並進行適當的預處理,避免數據質量不佳影響模型效果。分批訓練:對於大數據集,分批加載數據進行訓練,避免內存溢出。利用 GPU 加速:利用獨立顯卡加速訓練過程,縮短訓練時間。
 只要250美元,Hugging Face技術主管手把手教你微調Llama 3
May 06, 2024 pm 03:52 PM
只要250美元,Hugging Face技術主管手把手教你微調Llama 3
May 06, 2024 pm 03:52 PM
我們熟悉的Meta推出的Llama3、MistralAI推出的Mistral和Mixtral模型以及AI21實驗室推出的Jamba等開源大語言模型已經成為OpenAI的競爭對手。在大多數情況下,使用者需要根據自己的資料對這些開源模型進行微調,才能充分釋放模型的潛力。在單一GPU上使用Q-Learning對比小的大語言模型(如Mistral)進行微調不是難事,但對像Llama370b或Mixtral這樣的大模型的高效微調直到現在仍然是一個挑戰。因此,HuggingFace技術主管PhilippSch
 golang與java做web哪個效能比較好
Apr 21, 2024 am 12:49 AM
golang與java做web哪個效能比較好
Apr 21, 2024 am 12:49 AM
Golang 在 Web 效能上更優於 Java,原因如下:編譯型語言,直接編譯成機器碼,執行效率更高。高效率的垃圾收集機制,降低記憶體洩漏風險。較快的啟動時間,無需載入運行時解釋器。請求處理效能相近,支援並發和非同步程式設計。更低的記憶體佔用,直接編譯為機器碼無需額外解釋器和虛擬機器。
 讓大模型不再「巨無霸」,這是最新的大模型參數高效微調綜述
Apr 28, 2024 pm 04:04 PM
讓大模型不再「巨無霸」,這是最新的大模型參數高效微調綜述
Apr 28, 2024 pm 04:04 PM
AIxiv專欄是本站發布學術、技術內容的欄位。過去數年,本站AIxiv專欄接收通報了2,000多篇內容,涵蓋全球各大專院校與企業的頂尖實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或聯絡報道。投稿信箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。近期,大語言模式、文生圖模型等大規模AI模型快速發展。在這種情勢下,如何適應瞬息萬變的需求,快速適應大模型至各類下游任務,成為了一個重要的挑戰。受限於運算資源,傳統的全參數微
