

一文搞懂 Linux 核心的 4 大 IO 調度演算法

Linux核心包含4種IO調度器,分別是Noop IO scheduler、Anticipatory IO scheduler、Deadline IO scheduler和CFQ IO scheduler。
通常情況下,磁碟的讀寫延遲是由磁頭移動到柱面造成的。為了解決這種延遲,核心主要採用了兩種策略:快取和IO調度演算法。
調度演算法概念
- # 當寫入資料塊至裝置或從裝置讀取資料區塊時,請求會被放置在一個佇列中等待完成。
- 每個區塊設備都有自己的隊列。
- I/O調度程序負責維護這些佇列的順序,以更有效地利用媒體。 I/O調度程序將無序的I/O操作變成有序的I/O操作。
- 在進行調度之前,核心必須先確定佇列中總共有多少個請求。
IO調度器(IO Scheduler)
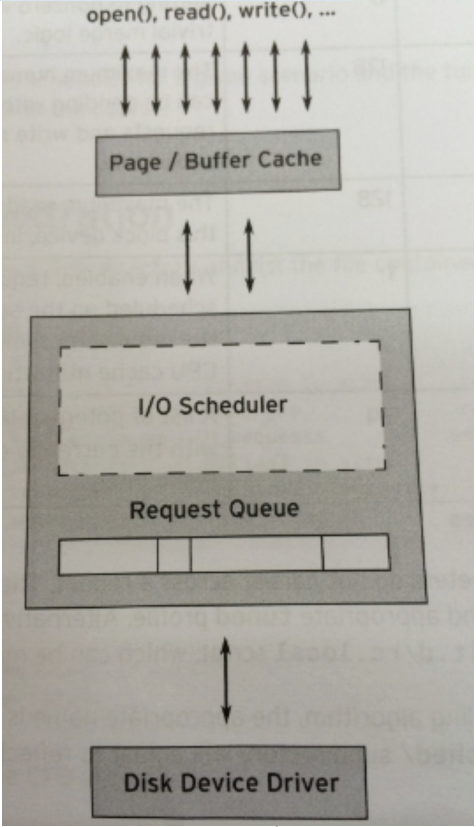
IO調度器(IO Scheduler)是作業系統用來決定在區塊裝置上IO操作提交順序的方法。存在的目的有兩個,一是提高IO吞吐量,二是降低IO反應時間。
然而IO吞吐量和IO回應時間往往是矛盾的,為了盡量平衡這兩者,IO調度器提供了多種調度演算法來適應不同的IO請求場景。其中,對資料庫這種隨機讀寫的場景最有利的演算法是DEANLINE。
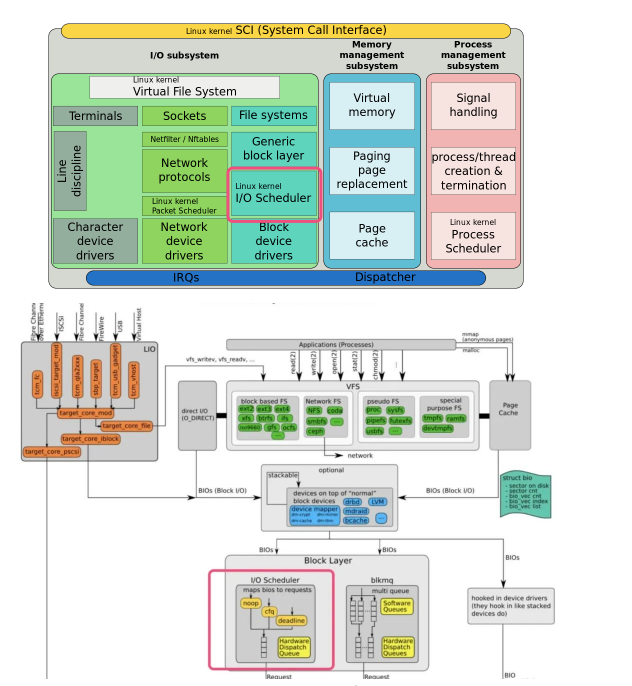
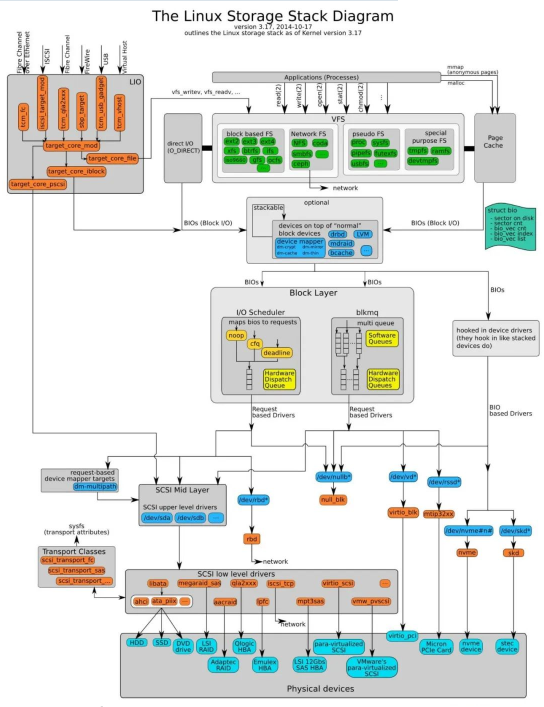
IO調度器在核心堆疊中所處位置如下:
區塊裝置最悲劇的地方就是磁碟轉動,這個過程會很耗時間。每個區塊裝置或區塊裝置的分區,都對應有自身的請求佇列(request_queue),而每個請求佇列都可以選擇一個I/O調度器來協調所遞交的request。
I/O調度器的基本目的是將請求依照它們對應在區塊裝置上的磁區號排列,以減少磁頭的移動,提高效率。每個裝置的請求佇列裡的請求將依序回應。
實際上,除了這個隊列,每個調度器本身都維護有不同數量的隊列,用來對遞交上來的request進行處理,而排在隊列最前面的request將適時被移動到請求隊列中等待響應。

IO scheduler 的功能主要是為了減少磁碟轉動的需求。主要透過2種方式實現:
- 合併
- 排序
每個裝置都會自行對應請求佇列,所有的請求在被處理之前都會在請求佇列上。在新來一個請求的時候如果發現這個請求和前面的某個請求請求的位置是相鄰的,那麼就可以合併為一個請求。
如果找不到合併的,就會依照磁碟的轉動方向進行排序。通常IO scheduler 的角色就是為了在進行合併和排序的同時,也不會太影響單一請求的處理時間。
1、NOOP
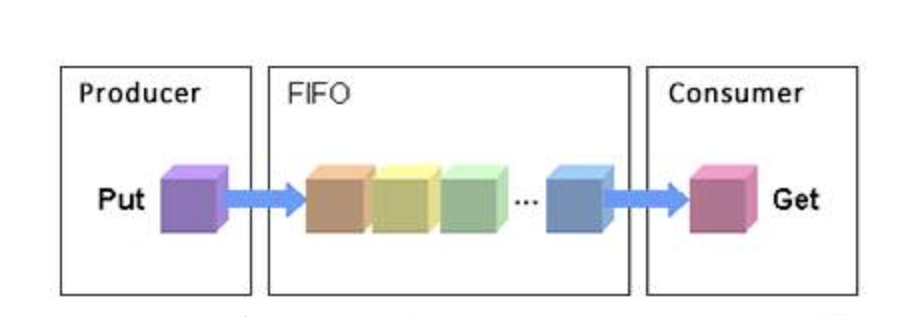
#FIFO
- noop是什麼? noop是一種輸入輸出調度演算法 . NOOP, No Operation. 什麼都不做,請求來一個處理一個。這種方式事實起來簡單,也更有效。問題就是disk seek 太多,對於傳統磁碟,這是不能接受的。但對於SSD 磁碟就可以,因為SSD 磁碟不需要轉動。
- noop的別稱 又稱為電梯調度演算法.
- noop原理是怎樣的?
將輸入輸出請求放到一個FIFO佇列中,然後依序執行佇列中的輸入輸出請求:當來一個新請求時:
-
如果能合併就合併
-
如果不能合併,就會嘗試排序。如果隊列上的請求都已經很老了,這個新的請求就不能插隊,只能放到最後面。否則就插到適當的位置
-
如果既不能合併,又沒有適當的位置插入,就放到請求佇列的最後。
-
適用場景
4.1 在不希望修改輸入輸出請求先後順序的場景下;
4.2 在輸入輸出之下具有更智慧調度演算法的設備,如NAS儲存設備;
4.3 上層應用程式已經精心優化過的輸入輸出請求;
4.4 非旋轉磁頭式的磁碟設備,如SSD磁碟
2、CFQ(Completely Fair Queuing, 完全公平排隊)
CFQ(Completely Fair Queuing)演算法,顧名思義,絕對公平演算法。它試圖為競爭塊設備使用權的所有進程分配一個請求隊列和一個時間片,在調度器分配給進程的時間片內,進程可以將其讀寫請求發送給底層塊設備,當進程的時間片消耗完,進程的請求佇列將被掛起,等待調度。
每個進程的時間片和每個進程的佇列長度取決於進程的IO優先權,每個進程都會有一個IO優先權,CFQ調度器將會將其作為考慮的因素之一,來確定該進程的請求佇列何時可以取得區塊設備的使用權。
IO優先權從高到低可以分成三大類:
RT(real time)
BE(best try)
IDLE(idle)
其中RT和BE又可以再分割為8個子優先權。可以透過ionice 去查看和修改。優先權越高,被處理得越早,用於這個行程的時間片也越多,一次處理的請求數也會越多。
實際上,我們已經知道CFQ調度器的公平是針對於進程而言的,而只有同步請求(read或syn write)才是針對進程而存在的,他們會放入進程本身的請求隊列,而所有同優先權的非同步請求,無論來自於哪個進程,都會被放入公共的佇列,非同步請求的佇列總共有8(RT) 8(BE) 1(IDLE)=17個。
從Linux 2.6.18起,CFQ作為預設的IO調度演算法。對於通用的伺服器來說,CFQ是較好的選擇。具體使用哪種調度演算法還是要根據具體的業務場景去做足benchmark來選擇,不能只靠別人的文字來決定。
3、DEADLINE
#DEADLINE在CFQ的基礎上,解決了IO請求餓死的極端情況。
除了CFQ本身俱有的IO排序佇列之外,DEADLINE額外分別為讀IO和寫IO提供了FIFO佇列。
讀取FIFO佇列的最大等待時間為500ms,寫FIFO佇列的最大等待時間為5s(當然這些參數都是可以手動設定的)。
FIFO佇列內的IO請求優先權要比CFQ佇列中的高,而讀FIFO佇列的優先權又比寫FIFO佇列的優先權高。優先權可以表示如下:
「
#FIFO(Read) > FIFO(Write) > CFQ
#」
#deadline 演算法保證對於既定的 IO 請求以最小的延遲時間,從這一點理解,對於 DSS 應用應該會是很適合的。
deadline 其實是對Elevator 的一種改進:
\1. 避免有些請求太長時間不能被處理。
\2. 區分對待讀取操作和寫入操作。
deadline IO 維護3個佇列。第一個隊列和Elevator 一樣, 盡量依照物理位置排序。第二個佇列和第三個佇列都是依照時間排序,不同的是一個是讀取操作一個是寫入操作。
deadline IO 之所以區分讀和寫是因為設計者認為如果應用程式發了一個讀取請求,一般就會阻塞到那裡,一直等到的結果回傳。而寫請求則不是通常是應用程式請求寫到記憶體即可,由後台程序再寫回磁碟。應用程式一般不等寫完成就繼續往下走。所以讀請求應該比寫請求有更高的優先權。
在這個設計下,每個新增請求都會先放到第一個佇列,演算法和Elevator的方式一樣,同時也會增加到讀取或寫入佇列的尾端。這樣先處理一些第一隊列的請求,同時檢測第二/三隊列前幾個請求是否等了太長時間,如果已經超過一個閥值,就會去處理一下。這個閥值對於讀取請求時 5ms, 對於寫入請求時5s.
個人認為對於記錄資料庫變更日誌的分割區,例如oracle 的online log, mysql 的binlog 等等,最好不要使用這種分割區。因為這類寫入請求通常是呼叫fsync 的。如果寫完不成,也會很影響應用效能的。
4、ANTICIPATORY
CFQ和DEADLINE考慮的焦點在於滿足零散IO請求上。對於連續的IO請求,例如順序讀,並沒有做最佳化。
為了滿足隨機IO和順序IO混合的場景,Linux也支援ANTICIPATORY調度演算法。 ANTICIPATORY的在DEADLINE的基礎上,為每個讀IO都設定了6ms的等待時間窗。如果在這6ms內OS收到了相鄰位置的讀取IO請求,就可以立即滿足。
小結
IO調度器演算法的選擇,既取決於硬體特徵,也取決於應用場景。
在傳統的SAS碟上,CFQ、DEADLINE、ANTICIPATORY都是不錯的選擇;對於專屬的資料庫伺服器,DEADLINE的吞吐量和回應時間都表現良好。
然而在新興的固態硬碟例如SSD、Fusion IO上,最簡單的NOOP反而可能是最好的演算法,因為其他三個演算法的最佳化是基於縮短尋道時間的,而固態硬碟沒有所謂的尋道時間且IO反應時間非常短。
以上是一文搞懂 Linux 核心的 4 大 IO 調度演算法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 centos和ubuntu的區別
Apr 14, 2025 pm 09:09 PM
centos和ubuntu的區別
Apr 14, 2025 pm 09:09 PM
CentOS 和 Ubuntu 的關鍵差異在於:起源(CentOS 源自 Red Hat,面向企業;Ubuntu 源自 Debian,面向個人)、包管理(CentOS 使用 yum,注重穩定;Ubuntu 使用 apt,更新頻率高)、支持週期(CentOS 提供 10 年支持,Ubuntu 提供 5 年 LTS 支持)、社區支持(CentOS 側重穩定,Ubuntu 提供廣泛教程和文檔)、用途(CentOS 偏向服務器,Ubuntu 適用於服務器和桌面),其他差異包括安裝精簡度(CentOS 精
 centos如何安裝
Apr 14, 2025 pm 09:03 PM
centos如何安裝
Apr 14, 2025 pm 09:03 PM
CentOS 安裝步驟:下載 ISO 映像並刻錄可引導媒體;啟動並選擇安裝源;選擇語言和鍵盤佈局;配置網絡;分區硬盤;設置系統時鐘;創建 root 用戶;選擇軟件包;開始安裝;安裝完成後重啟並從硬盤啟動。
 Centos停止維護2024
Apr 14, 2025 pm 08:39 PM
Centos停止維護2024
Apr 14, 2025 pm 08:39 PM
CentOS將於2024年停止維護,原因是其上游發行版RHEL 8已停止維護。該停更將影響CentOS 8系統,使其無法繼續接收更新。用戶應規劃遷移,建議選項包括CentOS Stream、AlmaLinux和Rocky Linux,以保持系統安全和穩定。
 docker原理詳解
Apr 14, 2025 pm 11:57 PM
docker原理詳解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux內核特性,提供高效、隔離的應用運行環境。其工作原理如下:1. 鏡像作為只讀模板,包含運行應用所需的一切;2. 聯合文件系統(UnionFS)層疊多個文件系統,只存儲差異部分,節省空間並加快速度;3. 守護進程管理鏡像和容器,客戶端用於交互;4. Namespaces和cgroups實現容器隔離和資源限制;5. 多種網絡模式支持容器互聯。理解這些核心概念,才能更好地利用Docker。
 Centos停止維護後的選擇
Apr 14, 2025 pm 08:51 PM
Centos停止維護後的選擇
Apr 14, 2025 pm 08:51 PM
CentOS 已停止維護,替代選擇包括:1. Rocky Linux(兼容性最佳);2. AlmaLinux(與 CentOS 兼容);3. Ubuntu Server(需要配置);4. Red Hat Enterprise Linux(商業版,付費許可);5. Oracle Linux(與 CentOS 和 RHEL 兼容)。在遷移時,考慮因素有:兼容性、可用性、支持、成本和社區支持。
 centos停止維護後怎麼辦
Apr 14, 2025 pm 08:48 PM
centos停止維護後怎麼辦
Apr 14, 2025 pm 08:48 PM
CentOS 停止維護後,用戶可以採取以下措施應對:選擇兼容髮行版:如 AlmaLinux、Rocky Linux、CentOS Stream。遷移到商業發行版:如 Red Hat Enterprise Linux、Oracle Linux。升級到 CentOS 9 Stream:滾動發行版,提供最新技術。選擇其他 Linux 發行版:如 Ubuntu、Debian。評估容器、虛擬機或云平台等其他選項。
 docker desktop怎麼用
Apr 15, 2025 am 11:45 AM
docker desktop怎麼用
Apr 15, 2025 am 11:45 AM
如何使用 Docker Desktop? Docker Desktop 是一款工具,用於在本地機器上運行 Docker 容器。其使用步驟包括:1. 安裝 Docker Desktop;2. 啟動 Docker Desktop;3. 創建 Docker 鏡像(使用 Dockerfile);4. 構建 Docker 鏡像(使用 docker build);5. 運行 Docker 容器(使用 docker run)。
 vscode 無法安裝擴展
Apr 15, 2025 pm 07:18 PM
vscode 無法安裝擴展
Apr 15, 2025 pm 07:18 PM
VS Code擴展安裝失敗的原因可能包括:網絡不穩定、權限不足、系統兼容性問題、VS Code版本過舊、殺毒軟件或防火牆干擾。通過檢查網絡連接、權限、日誌文件、更新VS Code、禁用安全軟件以及重啟VS Code或計算機,可以逐步排查和解決問題。
