

語音生成的「智慧湧現」:10萬小時資料訓練,亞馬遜祭出10億參數BASE TTS

隨著生成式深度學習模型的快速發展,自然語言處理(NLP)和電腦視覺(CV)已經發生了重大變革。從以前需要專門訓練的監督模型,轉變為只需要簡單明確的指令就能完成各種任務的一般模型。這個轉變為我們提供了更有效率和靈活的解決方案。
在語音處理和文字轉語音(TTS)領域,轉變正在發生。透過利用數千小時的數據,模型使合成結果越來越接近真實人類語音。
在最近的一項研究中,亞馬遜正式推出了 BASE TTS,將 TTS 模型的參數規模提升到了前所未有的 10 億級別。

論文標題:BASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data
論文連結:https://arxiv.org/pdf/2402.08093.pdf
BASE TTS 是一個大型的多語言、多說話人的TTS( LTTS)系統。它使用了約10萬小時的公共領域語音資料進行訓練,比之前訓練資料量最高的VALL-E多了一倍。受到LLM成功經驗的啟發,BASE TTS 將TTS視為下一個token預測的問題,並結合大量的訓練數據,以實現強大的多語言和多說話者的能力。
本文的主要貢獻概述如下:
提出的BASE TTS是目前規模最大的TTS模型,參數達到10億,並且是基於由10萬小時公共領域語音資料組成的數據集進行訓練的。透過主觀評估,BASE TTS在表現上優於公開的LTTS基線模型。
本文展示如何透過擴展BASE TTS到更大的資料集和模型規模,提高其對複雜文本呈現適當韻律的能力。為了評估大規模TTS模型的文本理解和渲染能力,研究者開發了一個「湧現能力」測試集,並報告了不同變體的BASE TTS在該基準上的表現。結果表明,隨著資料集規模和參數量的增加,BASE TTS的品質也在逐步提升。
3、提出了建立在 WavLM SSL 模型之上的新型離散語音表示法,旨在只捕捉語音訊號的音位和韻律訊息。這些表示法優於基準量化方法,儘管壓縮程度很高(僅 400 位元 / 秒),但仍能透過簡單、快速和串流解碼器將其解碼為高品質的波形。
接下來,讓我們看看論文細節。
BASE TTS 模型
與近期的語音建模工作類似,研究者採用了基於 LLM 的方法來處理 TTS 任務。文字被輸入到基於 Transformer 的自回歸模型,該模型可預測離散音訊表示(稱為語音編碼),再透過由線性層和卷積層組成的單獨訓練的解碼器將它們解碼為波形。
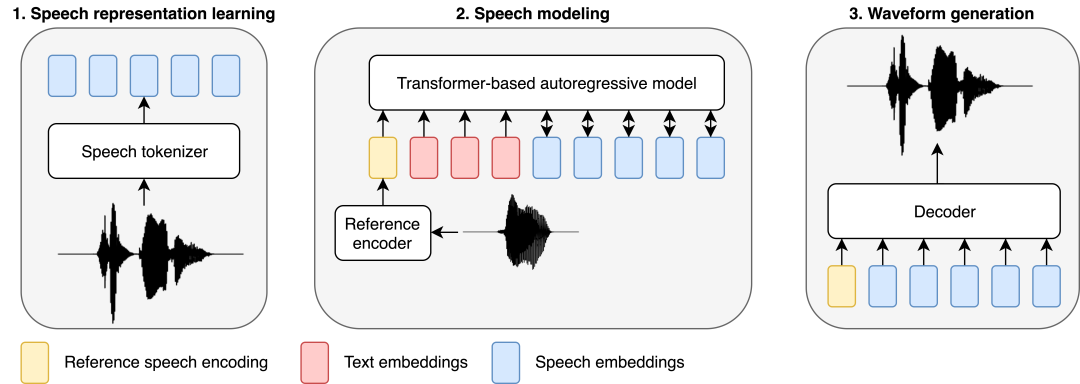
BASE TTS 設計的目的是模擬文本 token 的聯合分佈,然後是離散的語音表示,研究者稱之為語音編碼。透過音訊編解碼器對語音進行離散化是設計的核心,因為這樣就能直接應用為 LLM 開發的方法,而 LLM 正是 LTTS 最新研究成果的基礎。具體來說,研究者使用具有交叉熵訓練目標的解碼自回歸 Transformer 對語音編碼進行建模。儘管簡單,但這一目標可以捕捉到表達性語音的複雜機率分佈,從而緩解早期神經 TTS 系統中出現的過度平滑問題。作為一種隱式語言模型,一旦在足夠的資料上訓練出足夠大的變體,BASE TTS 在韻律渲染方面也會有質的飛躍。
離散語言表示
離散表示法是LLM 成功的基礎,但在語音中識別緊湊且資訊豐富的表示不如在文本中那麼明顯,此前的探索也較少。對於 BASE TTS,研究者首先嘗試使用 VQ-VAE 基線(第 2.2.1 節),該基線基於自動編碼器架構,透過離散瓶頸重構 mel 頻譜圖。 VQ-VAE 已成為語音和影像表徵的成功範例,尤其是作為 TTS 的建模單元。
研究者也介紹了一種透過基於 WavLM 的語音編碼學習語音表示的新方法(第 2.2.2 節)。在這種方法中,研究者將從 WavLM SSL 模型中提取的特徵離散化,以重建 mel 頻譜圖。研究者應用了額外的損失函數來促進說話人的分離,並使用字節對編碼(BPE,Byte-Pair Encoding)壓縮生成的語音代碼,以減少序列長度,從而使得能夠使用Transformer 對較長的音頻進行建模。
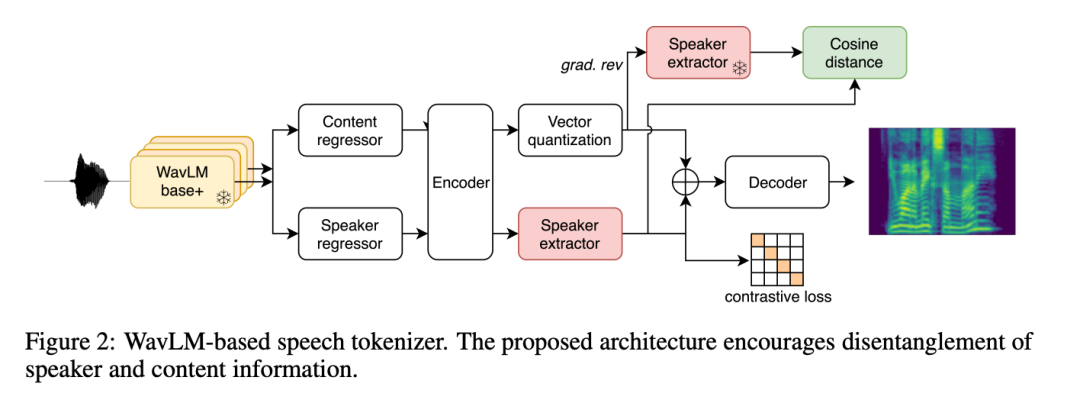
與流行的音訊編解碼器相比,這兩種表示法都經過了壓縮(分別為 325 bits/s 和 400 bits/s),以實現更有效率的自回歸建模。基於此壓縮水平,接下來的目標是移除語音編碼中可在解碼過程中重建的訊息(說話者、音訊噪音等),以確保語音編碼的容量主要用於編碼語音和韻律訊息。
自回歸語音建模(SpeechGPT)
研究者訓練了一個GPT-2 架構的自回歸模型“SpeechGPT”,用於預測以文本和參考語音為條件的語音編碼。參考語音條件包括從同一說話者隨機選擇的語句,該語句被編碼為固定大小的嵌入。參考語音嵌入、文字和語音編碼被串聯成一個序列,該序列由基於 Transformer 的自回歸模型建模。研究者對文字和語音使用單獨的位置嵌入和單獨的預測頭。他們從頭開始訓練了自回歸模型,而不對文本進行預訓練。為了保留文字訊息以指導擬聲,也對 SpeechGPT 進行了訓練,目的是預測輸入序列文字部分的下一個 token,因此 SpeechGPT 部分是純文字 LM。與語音損失相比,此處對文字損失採用了較低的權重。
波形產生
此外,研究者指定了一個單獨的語音編碼到波形解碼器(稱為「語音編碼解碼器」),負責重建說話者身份和錄音條件。為了使模型更具可擴展性,他們用卷積層取代了 LSTM 層,對中間表示進行解碼。研究表明,這種基於卷積的語音編碼解碼器計算效率高,與基於擴散的基線解碼器相比,整個系統的合成時間減少了 70% 以上。
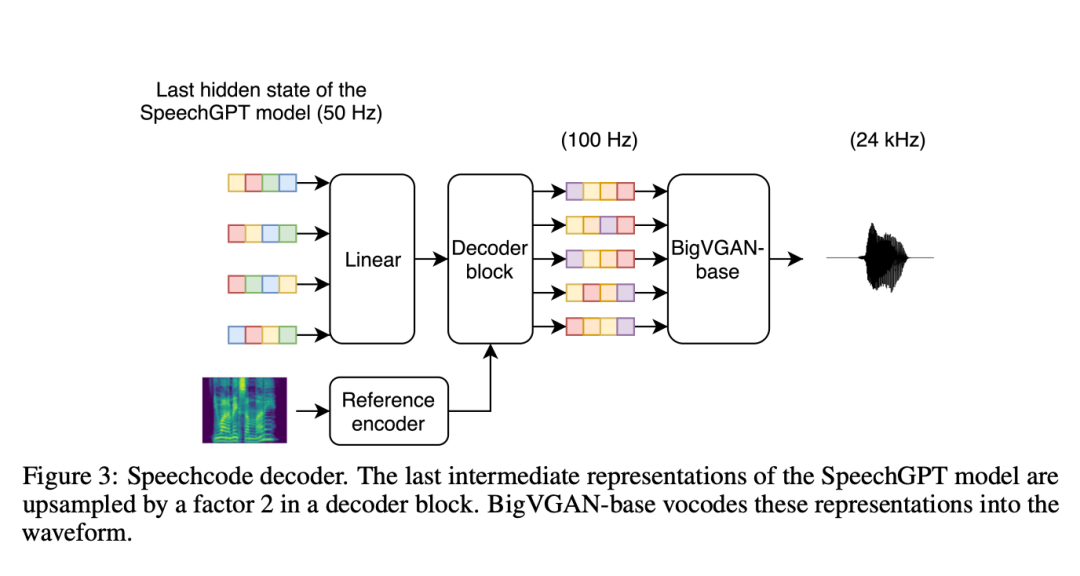
研究者同時指出,實際上語音編碼解碼器的輸入並不是語音編碼,而是自回歸 Transformer 的最後一個隱藏狀態。之所以這樣做,是因為先前 TortoiseTTS 方法中密集的潛在表徵提供了比單一語音代碼更豐富的資訊。在訓練過程中,研究者將文字和目標程式碼輸入訓練好的 SpeechGPT(參數凍結),然後根據最後的隱藏狀態對解碼器進行調整。輸入 SpeechGPT 的最後隱藏狀態有助於提高語音的分段和聲學質量,但也會將解碼器與特定版本的 SpeechGPT 聯繫起來。這使得實驗變得複雜,因為它迫使兩個組件總是按順序建構。這項限制需要在今後的工作中加以解決。
實驗評估
研究者探索了縮放如何影響模型針對具有挑戰性的文本輸入產生適當的韻律和表達的能力,這與LLM 透過數據和參數縮放「湧現」新能力的方式類似。為了驗證這個假設是否同樣適用於LTTS,研究者提出了一個評估方案來評估TTS 中潛在的湧現能力,確定了七個具有挑戰性的類別:複合名詞、情感、外來語、副語言、標點符號、問題和句法複雜性。
多項實驗驗證了BASE TTS 的結構及其品質、功能和計算性能:
首先,研究者比較了基於自動編碼器和基於WavLM 的語音編碼所達到的模型品質。
然後,研究者評估了對語音編碼進行聲學解碼的兩種方法:基於擴散的解碼器和語音編碼解碼器。
在完成這些結構消融後,研究者評估了 BASE TTS 在資料集大小和模型參數的 3 種變體中的湧現能力,並由語言專家進行了評估。
此外,研究者還進行了主觀的MUSHRA 測試以衡量自然度,以及自動可懂度和說話人相似度測量,還報告了與其他開源文本到語音模型的語音品質比較。
VQ-VAE 語音編碼vs. WavLM 語音編碼
為了全面測試兩種語音token 化方法的品質和通用性,研究者對6 位美式英語和4 位西班牙語說話者進行了MUSHRA 評估。就英語的平均 MUSHRA 分數而言,基於 VQ-VAE 和 WavLM 的系統不相上下(VQ-VAE:74.8 vs WavLM:74.7)。然而,對於西班牙語,基於 WavLM 的模型在統計上顯著優於 VQ-VAE 模型(VQ-VAE:73.3 vs WavLM:74.7)。請注意,英語資料約佔資料集的 90%,而西班牙語資料僅佔 2%。
表3 顯示了按說話者分類的結果:
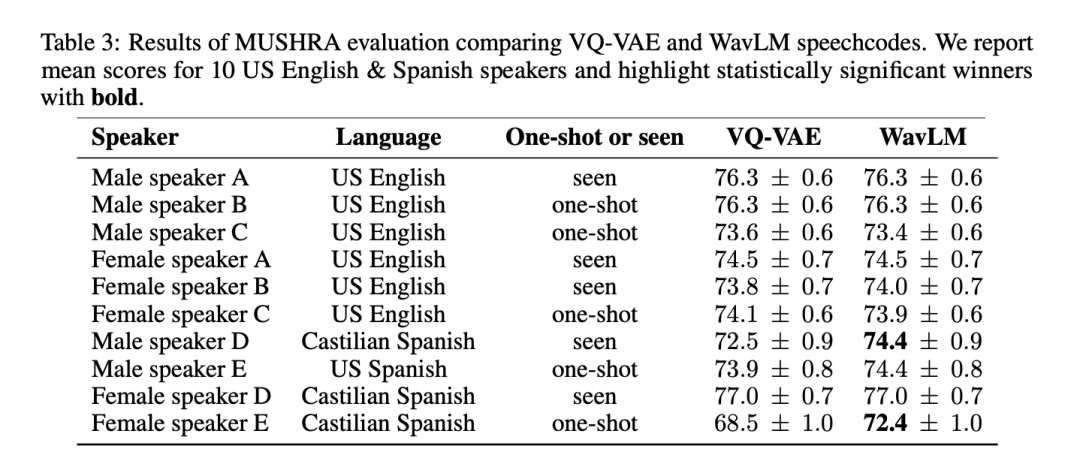
#由於基於WavLM 的系統表現至少與VQ-VAE 基準相當或更好,因此研究者在進一步的實驗中使用它來表示BASE TTS。
基於擴散的解碼器 vs. 語音代碼解碼器
如上文所述,BASE TTS 透過提出端對端語音編碼解碼器,簡化了基於擴散的基線解碼器。此方法具有流暢性,推理速度提高了 3 倍。為了確保這種方法不會降低質量,研究者對所提出的語音編碼解碼器與基準進行了評估。表4 列出了對4 位說英語的美國人和2 位說西班牙語的人進行的MUSHRA 評估結果:
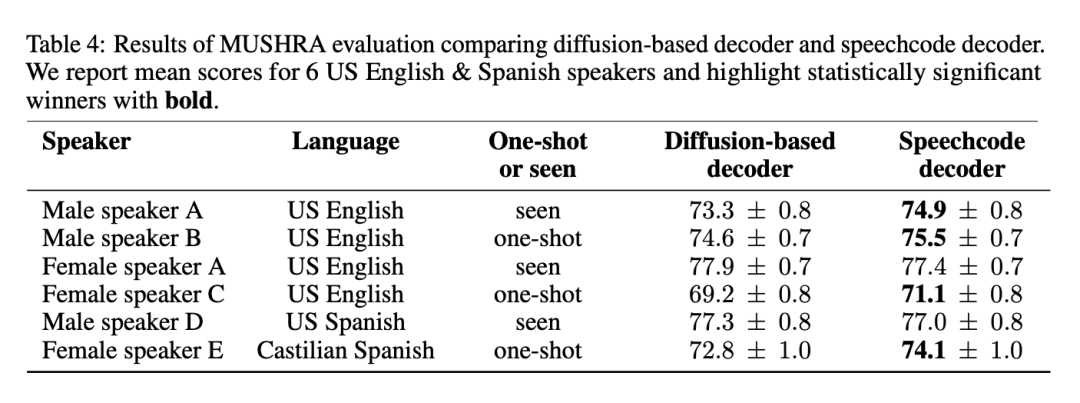
結果顯示,語音編碼解碼器是首選方法,因為它不會降低質量,而且對大多數語音而言,它能提高質量,同時提供更快的推理。研究者同時表示,結合兩個強大的生成模型進行語音建模是多餘的,可以透過放棄擴散解碼器來簡化。
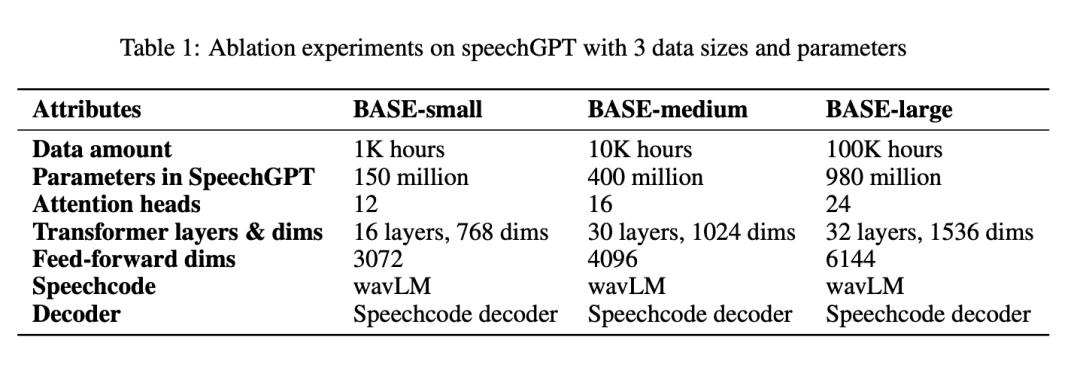
湧現能力:資料和模型規模的消融
表1 按BASE-small、BASE-medium 和BASE-large 系統報告了所有參數:
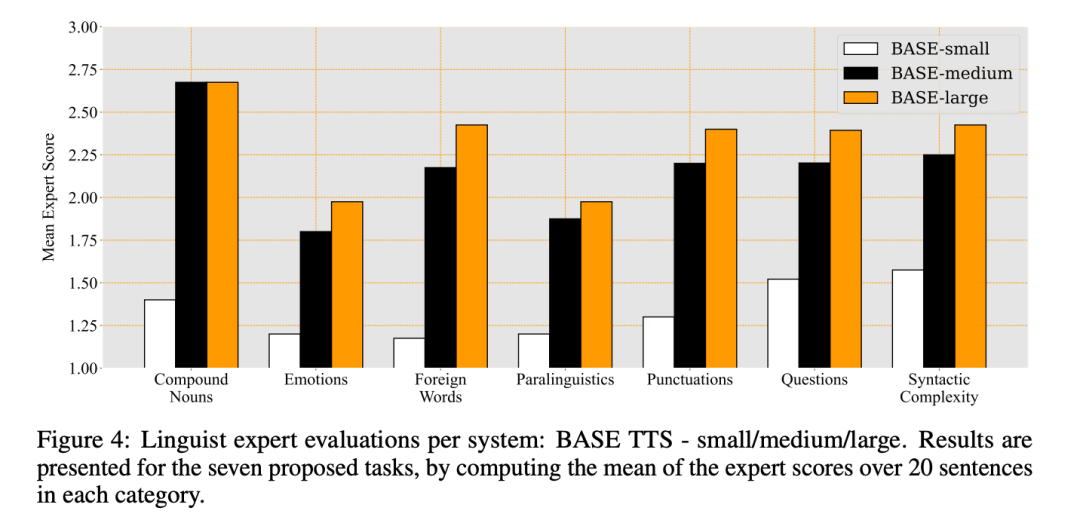
三個系統的語言專家判斷結果以及每個類別的平均分數如圖4 所示:
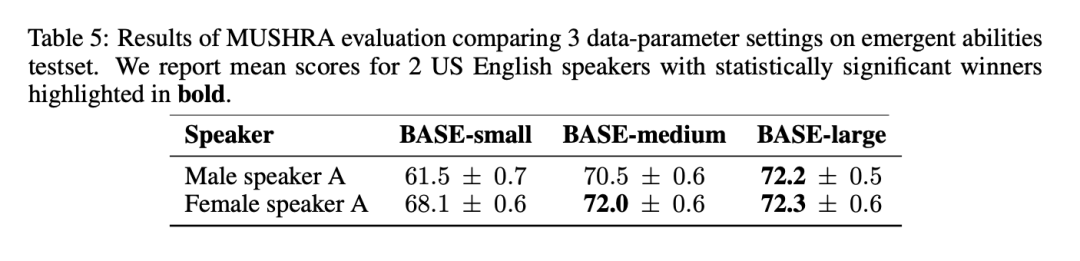
在表5 的MUSHRA 結果中,可以注意到語音自然度從BASE-small 到BASE-medium 有明顯改善,但從BASE-medium 到BASE-large 的改善幅度較小:
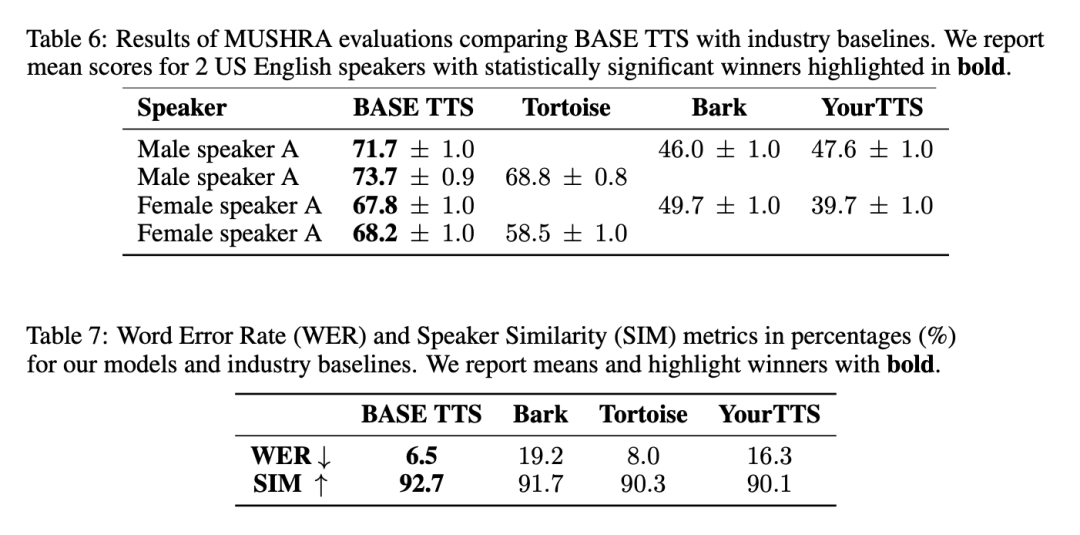
BASE TTS vs. 產業baseline
整體來說,BASE TTS 產生的語音最自然,與輸入文字的錯位最少,與參考說話者的語音最相似,相關結果如表6 及表7 所示:
語音編碼解碼器帶來的合成效率提升
語音編碼解碼器能夠進行串流處理,即以增量方式產生語音。將這項功能與自回歸 SpeechGPT 結合,該系統的首字節延遲可低至 100 毫秒 —— 只需幾個解碼語音代碼就足以產生可懂的語音。
這種最低延遲與基於擴散的解碼器形成了鮮明對比,後者需要一次性生成整個語音序列(一個或多個句子),而首字節延遲等於總生成時間。
此外,研究者還觀察到,與擴散基線相比,語音編碼解碼器使整個系統的計算效率提高了 3 倍。他們執行了一個基準測試,在 NVIDIA® V100 GPU 上產生 1000 個持續時間約 20 秒的語句,批次大小為 1。平均而言,使用擴散解碼器的十億參數 SpeechGPT 需要 69.1 秒才能完成合成,而使用語音編碼解碼器的相同 SpeechGPT 只需要 17.8 秒。
更多研究細節,可參考原論文。
以上是語音生成的「智慧湧現」:10萬小時資料訓練,亞馬遜祭出10億參數BASE TTS的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 DeepMind機器人打乒乓球,正手、反手溜到飛起,全勝人類初學者
Aug 09, 2024 pm 04:01 PM
DeepMind機器人打乒乓球,正手、反手溜到飛起,全勝人類初學者
Aug 09, 2024 pm 04:01 PM
但可能打不過公園裡的老大爺?巴黎奧運正在如火如荼地進行中,乒乓球項目備受關注。同時,機器人打乒乓球也取得了新突破。剛剛,DeepMind提出了第一個在競技乒乓球比賽中達到人類業餘選手等級的學習型機器人智能體。論文地址:https://arxiv.org/pdf/2408.03906DeepMind這個機器人打乒乓球什麼程度呢?大概和人類業餘選手不相上下:正手反手都會:對手採用多種打法,機器人也能招架得住:接不同旋轉的發球:不過,比賽激烈程度似乎不如公園老大爺對戰。對機器人來說,乒乓球運動
 首配機械爪!元蘿蔔亮相2024世界機器人大會,發布首個走進家庭的西洋棋機器人
Aug 21, 2024 pm 07:33 PM
首配機械爪!元蘿蔔亮相2024世界機器人大會,發布首個走進家庭的西洋棋機器人
Aug 21, 2024 pm 07:33 PM
8月21日,2024世界機器人大會在北京隆重召開。商湯科技旗下家用機器人品牌「元蘿蔔SenseRobot」家族全系產品集體亮相,並最新發布元蘿蔔AI下棋機器人-國際象棋專業版(以下簡稱「元蘿蔔國象機器人」),成為全球首個走進家庭的西洋棋機器人。作為元蘿蔔的第三款下棋機器人產品,全新的國象機器人在AI和工程機械方面進行了大量專項技術升級和創新,首次在家用機器人上實現了透過機械爪拾取立體棋子,並進行人機對弈、人人對弈、記譜複盤等功能,
 Claude也變懶了!網友:學會給自己放假了
Sep 02, 2024 pm 01:56 PM
Claude也變懶了!網友:學會給自己放假了
Sep 02, 2024 pm 01:56 PM
開學將至,該收心的不只即將開啟新學期的同學,可能還有AI大模型。前段時間,Reddit擠滿了吐槽Claude越來越懶的網友。 「它的水平下降了很多,經常停頓,甚至輸出也變得很短。在發布的第一周,它可以一次性翻譯整整4頁文稿,現在連半頁都輸出不了!」https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/在一個名為“對Claude徹底失望了的帖子裡”,滿滿地
 世界機器人大會上,這家承載「未來養老希望」的國產機器人被包圍了
Aug 22, 2024 pm 10:35 PM
世界機器人大會上,這家承載「未來養老希望」的國產機器人被包圍了
Aug 22, 2024 pm 10:35 PM
在北京舉行的世界機器人大會上,人形機器人的展示成為了現場絕對的焦點,在星塵智能的展台上,由於AI機器人助理S1在一個展區上演揚琴、武術、書法三台大戲,能文能武,吸引了大量專業觀眾和媒體的駐足。在有彈性的琴弦上優雅的演奏,讓S1展現出速度、力度、精準度兼具的精細操作與絕對掌控。央視新聞對「書法」背後的模仿學習和智慧控制進行了專題報道,公司創始人來傑解釋到,絲滑動作的背後,是硬體側追求最好力控和最仿人身體指標(速度、負載等),而是在AI側則採集人的真實動作數據,讓機器人遇強則強,快速學習進化。而敏捷
 ACL 2024獎項發表:華科大破解甲骨文最佳論文之一、GloVe時間檢驗獎
Aug 15, 2024 pm 04:37 PM
ACL 2024獎項發表:華科大破解甲骨文最佳論文之一、GloVe時間檢驗獎
Aug 15, 2024 pm 04:37 PM
本屆ACL大會,投稿者「收穫滿滿」。為期六天的ACL2024正在泰國曼谷舉辦。 ACL是計算語言學和自然語言處理領域的頂級國際會議,由國際計算語言學協會組織,每年舉辦一次。一直以來,ACL在NLP領域的學術影響力都名列第一,它也是CCF-A類推薦會議。今年的ACL大會已是第62屆,接收了400餘篇NLP領域的前沿工作。昨天下午,大會公佈了最佳論文等獎項。此次,最佳論文獎7篇(兩篇未公開)、最佳主題論文獎1篇、傑出論文獎35篇。大會也評出了資源論文獎(ResourceAward)3篇、社會影響力獎(
 李飛飛團隊提出ReKep,讓機器人具備空間智能,還能整合GPT-4o
Sep 03, 2024 pm 05:18 PM
李飛飛團隊提出ReKep,讓機器人具備空間智能,還能整合GPT-4o
Sep 03, 2024 pm 05:18 PM
視覺與機器人學習的深度融合。當兩隻機器手絲滑地互相合作疊衣服、倒茶、將鞋子打包時,加上最近老上頭條的1X人形機器人NEO,你可能會產生一種感覺:我們似乎開始進入機器人時代了。事實上,這些絲滑動作正是先進機器人技術+精妙框架設計+多模態大模型的產物。我們知道,有用的機器人往往需要與環境進行複雜精妙的交互,而環境則可被表示成空間域和時間域上的限制。舉個例子,如果要讓機器人倒茶,那麼機器人首先需要抓住茶壺手柄並使之保持直立,不潑灑出茶水,然後平穩移動,一直到讓壺口與杯口對齊,之後以一定角度傾斜茶壺。這
 分散式人工智慧盛會DAI 2024徵稿:Agent Day,強化學習之父Richard Sutton將出席!顏水成、Sergey Levine以及DeepMind科學家將做主旨報告
Aug 22, 2024 pm 08:02 PM
分散式人工智慧盛會DAI 2024徵稿:Agent Day,強化學習之父Richard Sutton將出席!顏水成、Sergey Levine以及DeepMind科學家將做主旨報告
Aug 22, 2024 pm 08:02 PM
會議簡介隨著科技的快速發展,人工智慧成為了推動社會進步的重要力量。在這個時代,我們有幸見證並參與分散式人工智慧(DistributedArtificialIntelligence,DAI)的創新與應用。分散式人工智慧是人工智慧領域的重要分支,這幾年引起了越來越多的關注。基於大型語言模型(LLM)的智能體(Agent)異軍突起,透過結合大模型的強大語言理解和生成能力,展現了在自然語言互動、知識推理、任務規劃等方面的巨大潛力。 AIAgent正在接棒大語言模型,成為目前AI圈的熱門話題。 Au
 鴻蒙智行享界S9全場景新品發表會,多款重磅新品齊發
Aug 08, 2024 am 07:02 AM
鴻蒙智行享界S9全場景新品發表會,多款重磅新品齊發
Aug 08, 2024 am 07:02 AM
今天下午,鸿蒙智行正式迎来了新品牌与新车。8月6日,华为举行鸿蒙智行享界S9及华为全场景新品发布会,带来了全景智慧旗舰轿车享界S9、问界新M7Pro和华为novaFlip、MatePadPro12.2英寸、全新MatePadAir、华为毕昇激光打印机X1系列、FreeBuds6i、WATCHFIT3和智慧屏S5Pro等多款全场景智慧新品,从智慧出行、智慧办公到智能穿戴,华为全场景智慧生态持续构建,为消费者带来万物互联的智慧体验。鸿蒙智行:深度赋能,推动智能汽车产业升级华为联合中国汽车产业伙伴,为
