
Sora一經面世,瞬間成為頂流,話題熱度只增不減。
強大的逼真影片產生能力,讓許多人紛紛驚呼「現實不存在了」。
甚至,OpenAI技術報告中透露,Sora能夠深刻地理解運動中的物理世界,堪稱為真正的「世界模型」。

而一直將「世界模型」作為研究重心的圖靈巨人LeCun,也捲入了這場論戰。
起因是,網友挖出前幾天LeCun參加WGS高峰會上發表的觀點:「在AI影片方面,我們不知道該怎麼做」。
他認為,僅憑文字提示產生逼真影片並不等於模型理解物理世界。產生影片的方法與基於因果預測的世界模型截然不同。

接下來,LeCun更詳細地解釋:
雖然可以想像出來的影片種類繁多,但視訊生成系統只需創造出「一個」合理的樣本就算成功。
而對於一個真實視頻,其合理的後續發展路徑就相對較少,生成這些可能性中的具代表性部分,尤其是在特定動作條件下,難度大得多。
此外,產生這些影片後續內容不僅成本高昂,實際上也毫無意義。
更理想的做法是產生那些後續內容的「抽象表示」,去除與我們可能採取的行動無關的場景細節。
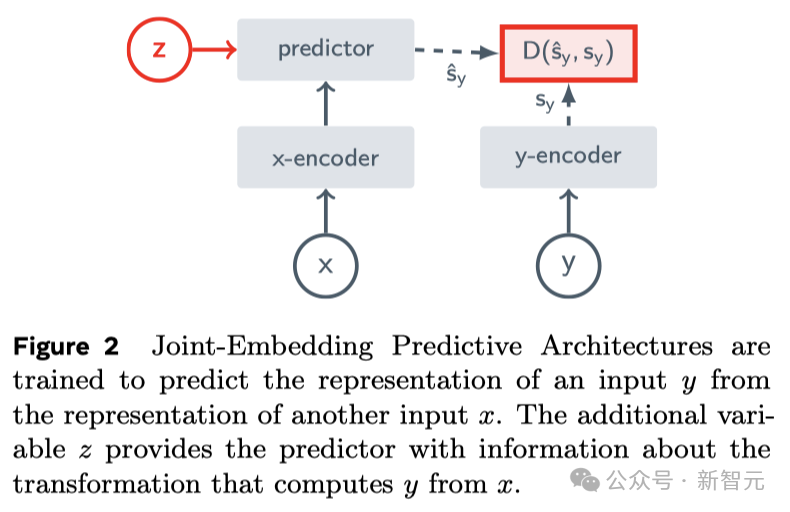
這正是JEPA(聯合嵌入預測架構)的核心思想,它並非生成式的,而是在表示空間中進行預測。
然後,他用自己的研究VICReg、I-JEPA、V-JEPA以及他人的工作證明:
與重建像素的生成型架構,如變分自編碼器(Variational AE)、遮罩自編碼器(Masked AE)、去噪自編碼器(Denoising AE)等相比,「聯合嵌入架構」能夠產生更優秀的視覺輸入表達。
當使用學習到的表示法作為下游任務中受監督頭部的輸入(無需對主幹進行微調),聯合嵌入架構在效果上超過了生成式架構。
也就是在Sora模型發布的當天,Meta重磅推出全新的無監督「影片預測模型」-V-JEPA。
自2022年LeCun首提JEPA之後,I-JEPA和V-JEPA分別基於影像、影片擁有強大的預測能力。
號稱能夠以「人類的理解方式」看世界,透過抽象性的高效預測,產生被遮蔽的部分。

論文地址:https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual- representations-from-video/
V-JEPA看到下面影片中的動作時,會說「將紙撕成兩半」。

再比如,翻看筆記本的影片被遮住了一部分,V-JEPA能夠對筆記本上的內容做出不同的預測。

值得一提的是,這是V-JEPA在觀看200萬個影片後,才獲得的超能力。
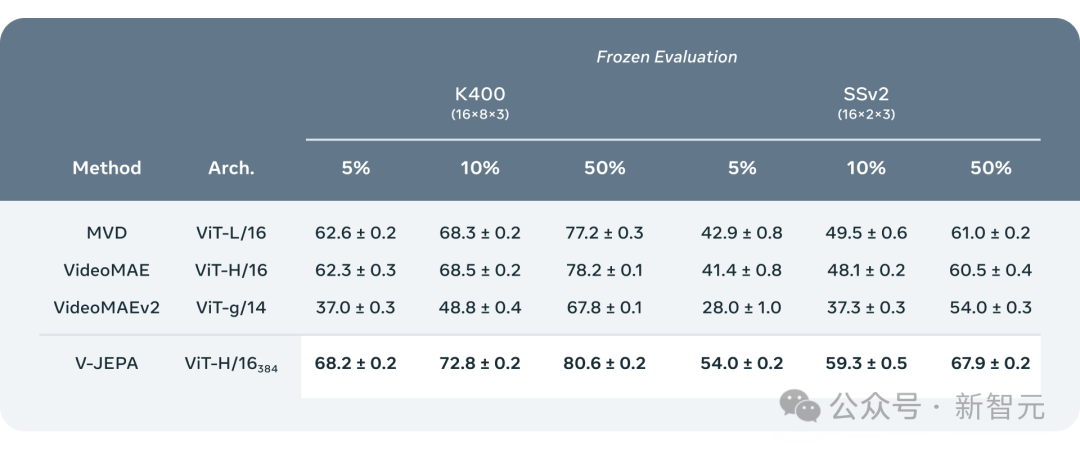
實驗結果表明,僅透過視訊特徵預測學習,就能夠得到廣泛適用於各類基於動作和外觀判斷的任務的「高效視覺表示」,而且不需要對模型參數進行任何調整。
基於V-JEPA訓練的ViT-H/16,在Kinetics-400、SSv2、ImageNet1K 基準上分別取得了81.9%、72.2%和77.9%的高分。
人類對於周圍世界的認識,特別是在生命的早期,很大程度上是透過「觀察」而獲得的。
就拿牛頓的「運動第三定律」來說,即使是嬰兒,或者貓,在多次把東西從桌上推下並觀察結果,也能自然而然地領悟到:凡在高處的任何物體,終將掉落。
這種認識,並不需要經過長時間的指導,或閱讀海量的書籍就能得出。
可以看出,你的內在世界模型——一種基於心智對世界的理解所建立的情景理解——能夠預見這些結果,並且極其高效。
Yann LeCun表示,V-JEPA正是我們向著對世界有更深刻理解邁出的關鍵一步,目的是讓機器能夠更為廣泛的推理和規劃。

2022年,他曾首次提出聯合嵌入預測架構(JEPA)。
我們的目標是打造出能夠像人類一樣學習的先進機器智慧(AMI),透過建構對周圍世界的內在模型來學習、適應和高效規劃,以解決複雜的任務。

與生成式AI模型Sora完全不同,V-JEPA是一種「非生成式模型」。
它透過預測影片中被隱藏或缺少部分,在一種抽象空間的表示來進行學習。
這與影像聯合嵌入預測架構(I-JEPA)類似,後者透過比較影像的抽象表示進行學習,而不是直接比較「像素」。
不同於那些嘗試重建每一個缺失像素的生成式方法,V-JEPA能夠捨棄那些難以預測的信息,這種做法使得在訓練和樣本效率上實現了1.5 -6倍的提升。
V-JEPA採用了自我監督的學習方式,完全依賴未標記的資料進行預訓練。
僅在預訓練之後,它便可以透過標記資料微調模型,以適應特定的任務。
因此,這種架構比以往的模型更為高效,無論是在需要的標記樣本數量上,還是在對未標記資料的學習投入上。
在使用V-JEPA時,研究人員將影片的大部分內容遮擋,只展示極小部分的「上下文」。
然後請求預測器補全所缺少的內容-不是透過具體的像素,而是以一種更抽象的描述形式在這個表示空間中填入內容。
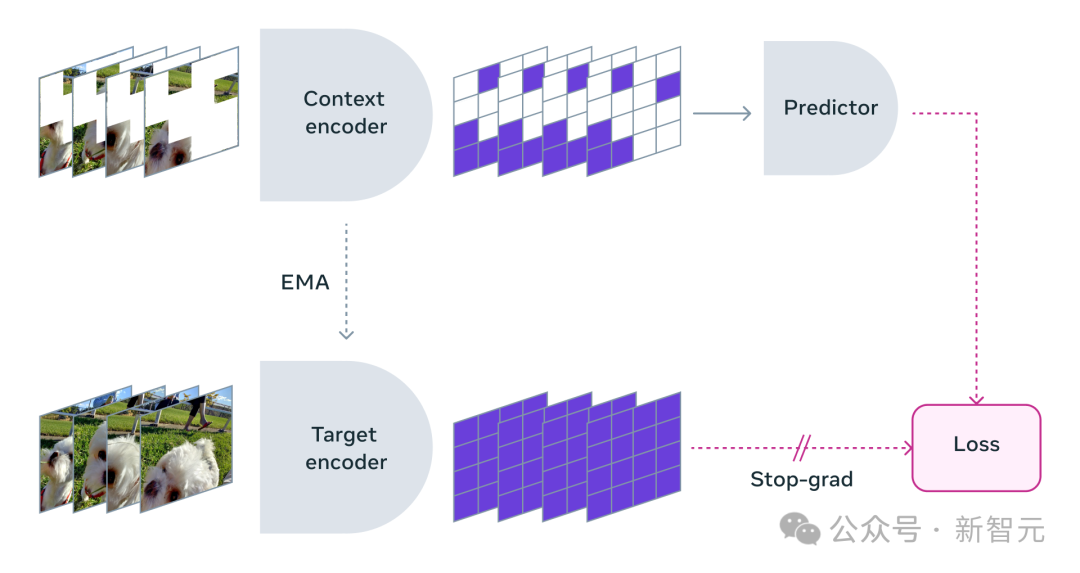
V-JEPA透過預測學習潛空間中被隱藏的時空區域來訓練視覺編碼器
V-JEPA並不是為了理解特定類型的動作而設計的。
相反,它透過在各種影片上應用自監督學習,掌握了許多關於世界運作方式的知識。
Meta研究者也精心設計了遮罩(masking)策略:
If you do not block most areas of the video, but just randomly select some small fragments, this will make the learning task too simple, causing the model to be unable to learn complex information about the world.
Again, it’s important to note that in most videos, things evolve over time.
If you only mask a small part of the video in a short period of time so that the model can see what happened before and after, it will also reduce the difficulty of learning and make it difficult for the model to learn interesting content. .
Therefore, the researchers took the approach of simultaneously masking parts of the video in space and time, forcing the model to learn and understand the scene.
Prediction in an abstract representation space is critical because it allows the model to focus on high-level aspects of the video content concepts without having to worry about details that are often unimportant to completing the task.
After all, if a video showed a tree, you probably wouldn't care about the tiny movements of each leaf.
What really excites Meta researchers is that V-JEPA is the first video model to perform well on "frozen evaluation".
Freezing means that after all self-supervised pre-training is completed on the encoder and predictor, it will no longer be modified.
When we need the model to learn new skills, we just add a small, specialized layer or network on top of it, which is efficient and fast.
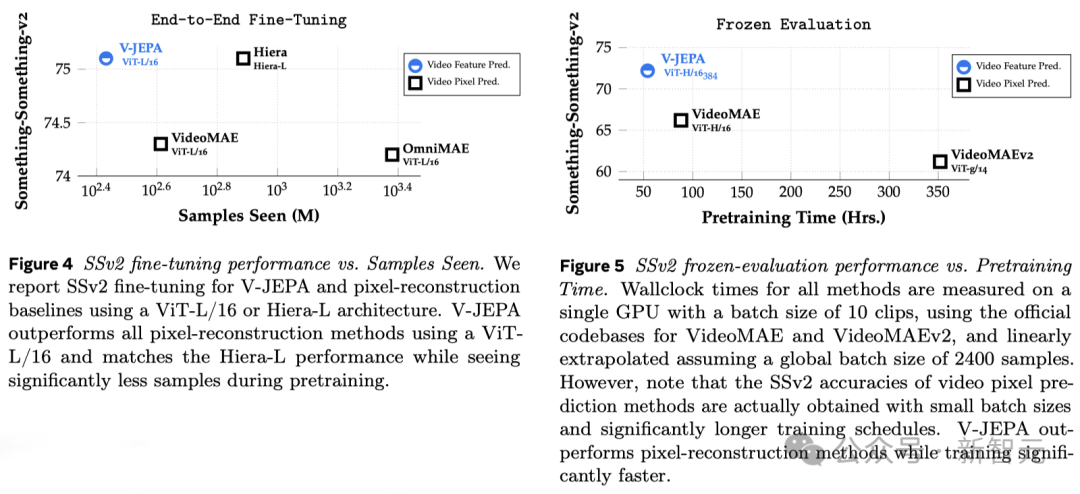
Previous research also required comprehensive fine-tuning, that is, after pre-training the model, in order to make the model perform on tasks such as fine-grained action recognition Excellent, any parameters or weights of the model need to be fine-tuned.
To put it bluntly, the fine-tuned model can only focus on a certain task and cannot adapt to other tasks.
If you want the model to learn different tasks, you must change the data and make specialized adjustments to the entire model.
V-JEPA’s research shows that it is possible to pre-train the model in one go without relying on any labeled data, and then use the model for multiple different tasks, such as action classification, fine-grained Object interactive recognition and activity positioning open up new possibilities.

- Few-sample frozen evaluation
## The researchers compared V-JEPA with other video processing models, paying particular attention to performance when the data is less annotated.
They selected two data sets, Kinetics-400 and Something-Something-v2, and adjusted the proportion of labeled samples used for training (5%, 10% and 50% respectively) , to observe the performance of the model in processing videos.
To ensure the reliability of the results, 3 independent tests were conducted at each ratio, and the average and standard deviation were calculated.
The results show that V-JEPA is better than other models in annotation usage efficiency, especially when the available annotation samples for each category are reduced, the difference between V-JEPA and other models The performance gap is even more obvious.

Although the "V" of V-JEPA stands for video, but so far it has mainly focused on analyzing the "visual elements" of video.
Obviously, Meta’s next step in research is to introduce a multi-modal method that can simultaneously process “visual and audio information” in videos.
As a proof-of-concept model, V-JEPA excels at identifying subtle object interactions in videos.
For example, being able to distinguish whether someone is putting down the pen, picking up the pen, or pretending to put down the pen but not actually putting it down.
However, this high-level motion recognition works well for short video clips (a few seconds to 10 seconds).
Therefore, another focus of the next step of research is how to make the model plan and predict over a longer time span.
So far, Meta researchers using V-JEPA have mainly focused on "perception" - —Understand the real-time situation of the world around you by analyzing video streams.
In this joint embedding prediction architecture, the predictor acts as a preliminary "physical world model" that can tell us generally what is happening in the video.
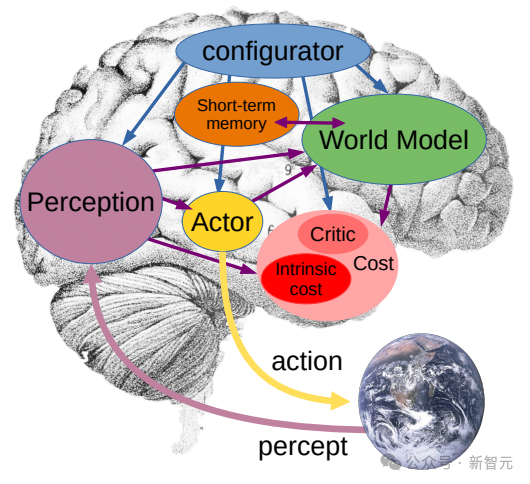
Meta’s next goal is to show how this predictor or world model can be used for planning and continuous decision-making.
We already know that the JEPA model can be trained by observing videos, much like a baby observing the world, and can learn a lot without strong supervision.
In this way, the model can quickly learn new tasks and recognize different actions using only a small amount of labeled data.
In the long run, V-JEPA’s strong situational understanding will be of great significance to the development of embodied AI technology and future augmented reality (AR) glasses in future applications.
Now think about it, if Apple Vision Pro can be blessed by the "world model", it will be even more invincible.
Obviously, LeCun is not optimistic about generative AI.

"Hear the advice of someone who has been trying to train a "world model" for presentation and planning."
Perplexity AI’s CEO says:
Sora is amazing, but not yet Get ready to model physics accurately. And the author of Sora was very smart and mentioned this in the technical report section of the blog, such as broken glass cannot be modeled well.
It is obvious that in the short term, reasoning based on such a complex world simulation cannot be run immediately on a home robot.
In fact, a very important nuance that many people fail to understand is:
Generating interesting-looking content in text or video does not mean (nor does it require) that it "understands" the content it generates. An agent model capable of reasoning based on understanding must, definitely, be outside of large models or diffusion models.

But some netizens said, "This is not the way humans learn."
"We only remember something unique about our past experiences, losing all the details. We can also model (create representations of) the environment anytime and anywhere because we perceive it .The most important part of intelligence is generalization.”

There are also claims that it is still an embedding of the interpolated latent space, and so far you cannot build a "world model" this way.

Can Sora and V-JEPA really understand the world? What do you think?
以上是LeCun怒斥Sora無法理解物理世界! Meta首發AI視頻'世界模型”V-JEPA的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















