
尽管视觉语言模型 (VLM) 在许多任务上取得了显著进展,包括图像描述、视觉问答、具身规划和动作识别等,但在空间推理方面仍然存在挑战。许多模型在理解目标在三维空间中的位置或空间关系方面仍有困难。这表明在进一步发展视觉语言模型的过程中,需要着重解决空间推理的问题,以提高模型在处理复杂视觉任务时的准确性和效率。
研究者经常通过人类的身体体验和进化发展来探讨这个问题。人类拥有固有的空间推理技能,可以轻松确定空间关系,比如目标相对位置、估算距离和大小,而无需进行复杂的思维过程或心理计算。
这种对直接空间推理任务的熟练,与当前视觉语言模型能力的局限形成鲜明对比,并引发了一个引人注目的研究问题:是否能够赋予视觉语言模型类似于人类的空间推理能力?
最近,谷歌提出了一种具备空间推理能力的视觉语言模型:SpatialVLM。

研究者认为当前视觉语言模型在空间推理能力方面的限制可能并非来自其架构的限制,而更可能是由于训练时使用的常见数据集的限制。许多视觉语言模型是在大规模的图像 - 文本对数据集上进行训练的,这些数据集中包含的空间信息有限。获取富含空间信息的具身数据或进行高质量的人工注释是一项具有挑战性的任务。为了解决这一问题,自动数据生成和增强技术被提出。然而,之前的研究大多集中在生成真实语义标注的逼真图像上,而忽略了对象和 3D 关系的丰富性。因此,未来的研究可以探索如何通过自动生成技术来提高模型对空间信息的理解,例如通过引入更多的具身数据或者注重对象和 3D 关系的建模。这将有助于改善视觉语言模型在空间推理方面的性能,使其更适用于现实世界的应用场景。
相反地,本研究专注于利用现实世界数据直接提取空间信息,以展现真实3D世界的多样性和复杂性。这一方法的灵感源自最新的视觉模型技术,能够自动从2D图像中生成3D空间注释。
SpatialVLM系统的一个关键功能是利用目标检测、深度估计、语义分割和目标中心描述模型等技术,对大规模密集注释的真实世界数据进行处理,以加强视觉语言模型的空间推理能力。通过将视觉模型生成的数据转换成能够用于描述、VQA和空间推理的混合数据格式,SpatialVLM系统实现了数据生成和对视觉语言模型进行训练的目标。研究者的努力使得这种系统能够更好地理解和处理视觉信息,从而提高其在复杂空间推理任务中的表现。这种方法有助于训练视觉语言模型更好地理解并处理图像和文本之间的关系,从而提高其在各种视觉任务中的准确性和效率。
研究表明,本文提出的视觉语言模型在多个领域展现了令人满意的能力。首先,它在处理定性空间问题时表现出明显的提升。其次,即使在训练数据存在噪声的情况下,该模型也能够可靠地进行定量估计。这种能力不仅使其具备了关于目标大小的常识知识,还使其在处理重新排列任务并进行开放词汇奖励标注方面非常有用。最后,结合强大的大型语言模型,该空间视觉语言模型在自然语言界面的基础上,能够进行空间推理链,解决复杂的空间推理任务。
為了讓視覺語言模型具備定性和定量的空間推理能力,研究者提出產生一個大規模的空間VQA 資料集用於訓練視覺語言模型。具體而言,就是設計一個全面的資料生成框架,首先利用現成的電腦視覺模型,包括開放詞彙檢測、度量深度估計、語義分割和以目標為中心的描述模型,提取以目標為中心的背景信息,然後採用基於模板的方法產生品質合理的大規模空間VQA 數據。本文中,研究者使用了生成的資料集來訓練 SpatialVLM,以學習直接的空間推理能力,然後將其與 LLMs 嵌入的高層常識推理相結合,解鎖鍊式思維的空間推理。

2D 映像的空間基準
研究者設計了一個產生包含空間推理問題的VQA 資料的流程,具體流程如圖2 所示。

1、語意篩選:在本文的資料合成流程中,第一步是採用基於CLIP 的開放詞彙分類模型將所有影像分類,排除不適合的影像。
2、2D 影像擷取以目標為中心的背景:這一步獲得由像素簇和開放詞彙描述組成的以目標為中心的實體。
3、2D 背景資訊到 3D 背景資訊:經過深度估計,將單眼的 2D 像素提升到度量尺度的 3D 點雲。本文是第一個將互聯網規模的圖像提升至以目標為中心的 3D 點雲,並用其合成帶有 3D 空間推理監督的 VQA 數據。
4、消除歧義:有時一張圖像中可能有多個相似類別的目標,導致它們的描述標籤存在歧義。因此,在詢問關於這些目標的問題之前,需要確保參考表達不含有歧義。
大規模空間推理VQA 資料集
#研究者透過使用合成資料進行預訓練,將「直觀」的空間推理能力融入VLM。因此,合成涉及影像中不超過兩個目標(表示為 A 和 B)的空間推理問答對。這裡主要考慮以下兩類問題:
1、定性問題:詢問某些空間關係的判斷。例如「給定兩個物件 A 和 B,哪個更靠左?」
2、定量問題:詢問更精細的答案,包括數字和單位。例如「相對於物件B,物件A 向左多少?」、「物件A 距離B 有多遠?」
此處,研究者指定了38 種不同類型的定性和定量空間推理問題,每個問題包含大約20 個問題模板和10 個答案模板。
圖 3 展示了本文所獲得的合成問答對的範例。研究者創建了一個包括 1000 萬張圖像和 20 億個直接空間推理問答對 (50% 是定性問題,50% 是定量問題) 的龐大數據集。

學習空間推理
##學習空間推理
直接空間推理:視覺語言模型接收圖像I 和關於空間任務的查詢Q 作為輸入,並輸出一個答案A,並且以文本的格式呈現,無需使用外部工具或與其他大型模型進行交互。本文採用與 PaLM-E 相同的架構和訓練流程,只是將 PaLM 的骨幹替換為 PaLM 2-S。然後,使用原始 PaLM-E 資料集和作者的資料集的混合進行模型訓練,其中 5% 的 token 用於空間推理任務。
###鍊式思維空間推理:SpatialVLM 提供了自然語言接口,可用於查詢具有基礎概念的問題,當與強大的 LLM 結合使用時,可以執行複雜的空間推理。 ############與Socratic Models 和LLM 協調器中的方法類似,本文利用LLM (text-davinci-003) 來協調與SpatialVLM 進行通信,以鍊式思維提示的方式解決複雜問題,如圖4 所示。 ######
#研究者以實驗證明並回答如下的問題:
問題1:本文設計的空間VQA 資料產生與訓練流程,是否提升了VLM 的一般空間推理能力?以及它的表現如何?
問題 2:充滿雜訊資料的合成空間 VQA 資料和不同的訓練策略,對學習表現有何影響?
問題 3:裝備了「直接」空間推理能力的 VLM,是否能夠解鎖諸如鍊式思維推理和具身規劃等新能力?
研究者透過使用 PaLM-E 訓練集和本文設計的空間 VQA 資料集的混合來訓練模型。為了驗證 VLM 在空間推理上的限制是否是資料問題,他們選擇了目前最先進的視覺語言模型作為基準。這些模型的訓練過程中語意描述任務佔據了相當的比重,而不是使用本文的空間 VQA 資料集進行訓練。
空間 VQA 表現
#定性空間 VQA。對於這個問題,人工註釋的答案和 VLM 輸出都是自由形式的自然語言。因此,為了評估 VLM 的效能,研究者使用人工評定員來確定答案是否正確,表 1 中展示了各個 VLM 的成功率。
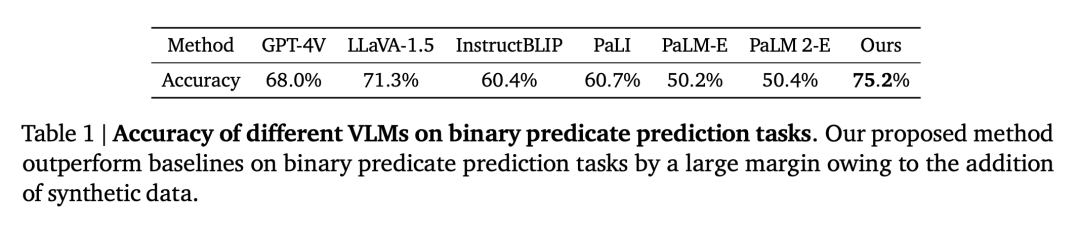
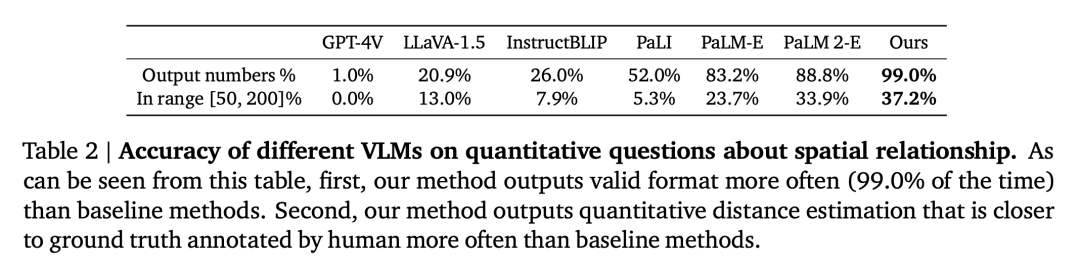
量化空間 VQA。如表 2 所示,本文的模型在兩個指標上都比基準表現更好且遙遙領先。
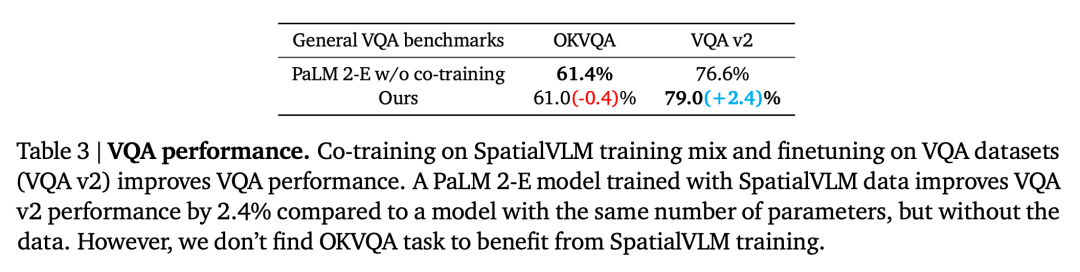
。空間VQA 資料對通用VQA 的影響
第二個問題是,由於與大量的空間VQA 資料共同訓練,VLM 在其他任務上的表現是否會因此而降低。透過將本文模型與在通用VQA 基準上沒有使用空間VQA 資料進行訓練的基本PaLM 2-E 進行了比較,如表3 所總結的,本文的模型在OKVQA 基准上達到了與PaLM 2-E 相當的性能,其中包括了有限的空間推理問題,並且在VQA-v2 test-dev 基準上表現略好,該基準包含了空間推理問題。
ViT 編碼器在空間推理中的影響
Frozen ViT (在對比目標上進行訓練) 是否編碼了足夠的資訊來進行空間推理?為了探索這一點,研究者的實驗從第 110,000 步的訓練開始,分成兩個訓練運行,一個 Frozen ViT,另一個 Unfrozen ViT。透過對這兩個模型進行了 70,000 步的訓練,評估結果如表 4 所示。

含雜訊的量化空間答案的影響
研究者使用機器人操作資料集訓練視覺語言模型,發現模型能夠在操作領域進行精細的距離估計(圖5),進一步證明了資料的準確性。
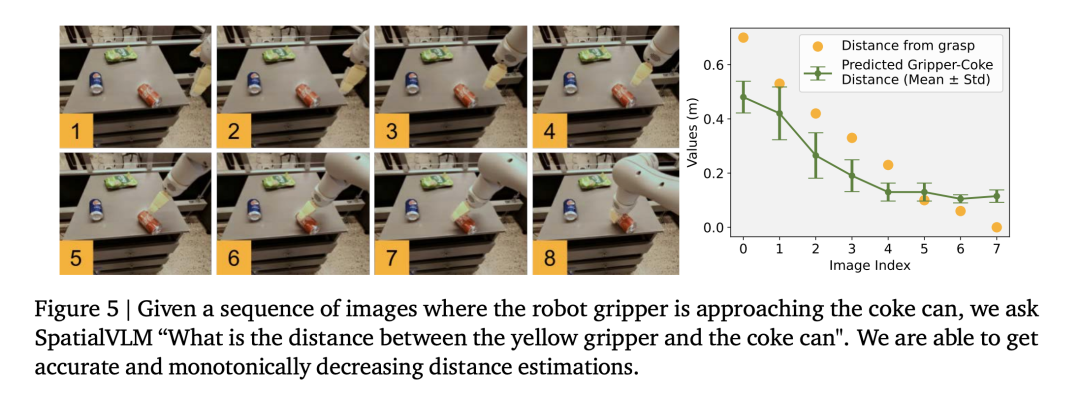
表 5 比較了不同的高斯雜訊標準差對定量空間 VQA 中整體 VLM 效能的影響。

1、視覺語言模型作為密集獎勵註解器
#視覺語言模型在機器人學領域有一個重要的應用。最近的研究表明,視覺語言模型和大型語言模型可以作為機器人任務的通用開放詞彙獎勵註釋器和成功偵測器,可用於建立有效的控制策略。然而,VLM 的獎勵標註能力通常受到空間意識不足的限制。由於 SpatialVLM 能夠從圖像中定量估計距離或尺寸,因此它獨特地適用作為密集的獎勵註釋器。作者進行一項真實的機器人實驗,用自然語言指定了一個任務,並要求 SpatialVLM 為軌跡中的每一幀註釋獎勵。
圖 6 中每個點表示一個目標的位置,它們的顏色表示註解的獎勵。隨著機器人朝著指定目標的進展,可以看到獎勵是單調增加的,這表明 SpatialVLM 作為密集獎勵註釋器的能力。

2、鍊式思考空間推理
#研究者也研究了SpatialVLM 是否能夠用於執行需要多步驟推理的任務,考慮到它對基本空間問題的增強回答能力。作者在圖 1 和圖 4 中展示了一些例子。當大語言模型 (GPT-4) 裝備 SpatialVLM 作為空間推理子模組時,可以執行複雜的空間推理任務,例如回答環境中的 3 個物件是否能夠形成「等腰三角形」。
更多技術細節和實驗結果請參考原文。
以上是讓視覺語言模型搞空間推理,Google又整新活了的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















