

Windows、Office直接上手,大模型智慧體操作電腦太6了

提到AI助理的未來,人們很容易想到《鋼鐵人》系列中的AI助理賈維斯。賈維斯在電影中展現了令人炫目的功能,不僅是東尼・史塔克的得力助手,也是他與先進科技溝通的橋樑。隨著大型模型的出現,人類使用工具的方式正在革命性變化,或許我們離科幻場景更近了一步。想像一下,一個多模態Agent能夠像人類一樣透過鍵盤和滑鼠直接操控我們周圍的電腦,這種突破將是多麼令人興奮。
AI助理賈維斯
#吉林大學人工智慧學院最新研究《ScreenAgent: A Vision Language Model-driven Computer Control Agent》展示了利用視覺大語言模型直接控制電腦GUI 的想像成為現實。研究提出了 ScreenAgent 模型,首次探討在不需要額外標籤輔助的情況下,透過 VLM Agent 直接操控電腦滑鼠和鍵盤,實現大規模模型直接進行電腦操作的目標。此外,ScreenAgent 運用自動化的「規劃-執行-反思」流程,首次實現對 GUI 介面的連續控制。這項工作對人機互動方式進行了探索和創新,同時也開源了包含具有精確定位資訊的資料集、控制器、訓練程式碼等資源。

- 論文網址:https://arxiv.org/abs/2402.07945
- #計畫網址:https://github.com/niuzaisheng/ScreenAgent
##ScreenAgent為用戶提供便利的線上娛樂、購物、旅遊和閱讀體驗。它還可作為貼心管家,協助管理個人電腦,實現快速辦公。無需費力,即可成為得力的辦公室助理。透過實際效果,使用者可了解其功能。
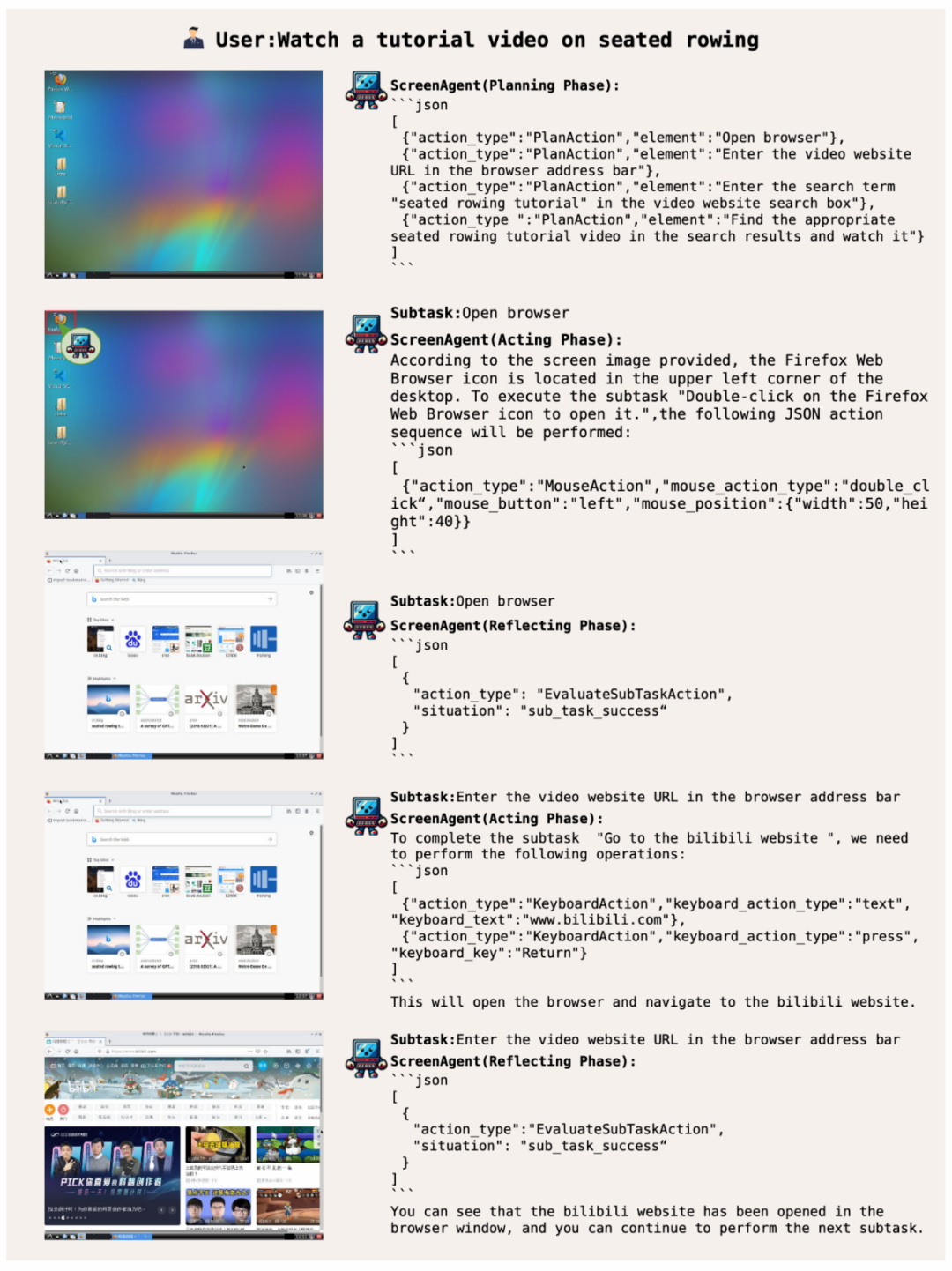
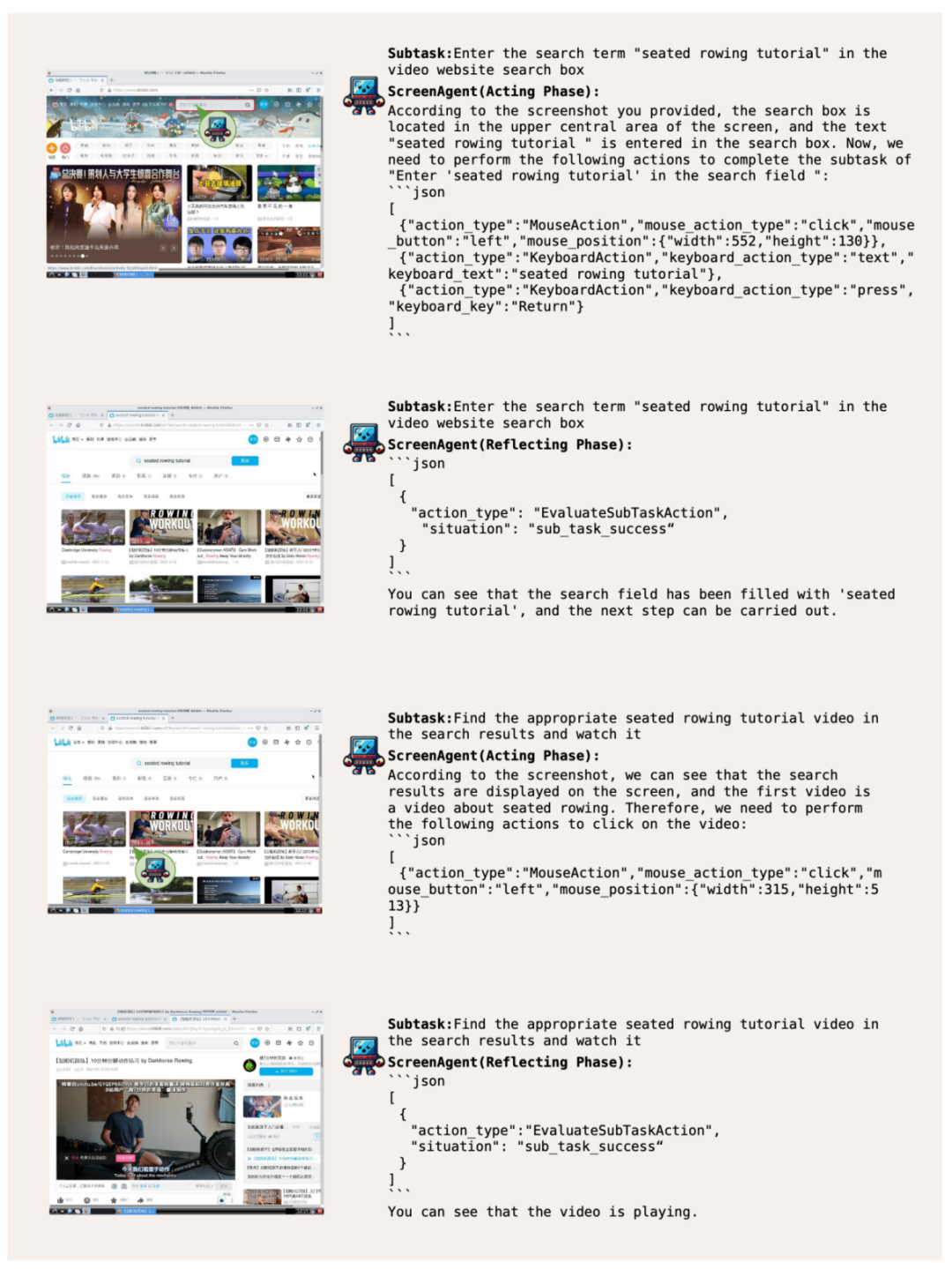
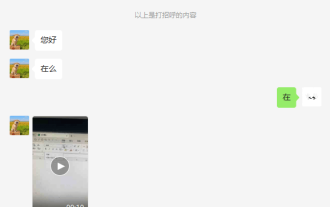
帶你上網,實現娛樂自由
ScreenAgent 根據用戶文本描述上網查找並播放指定的視頻:
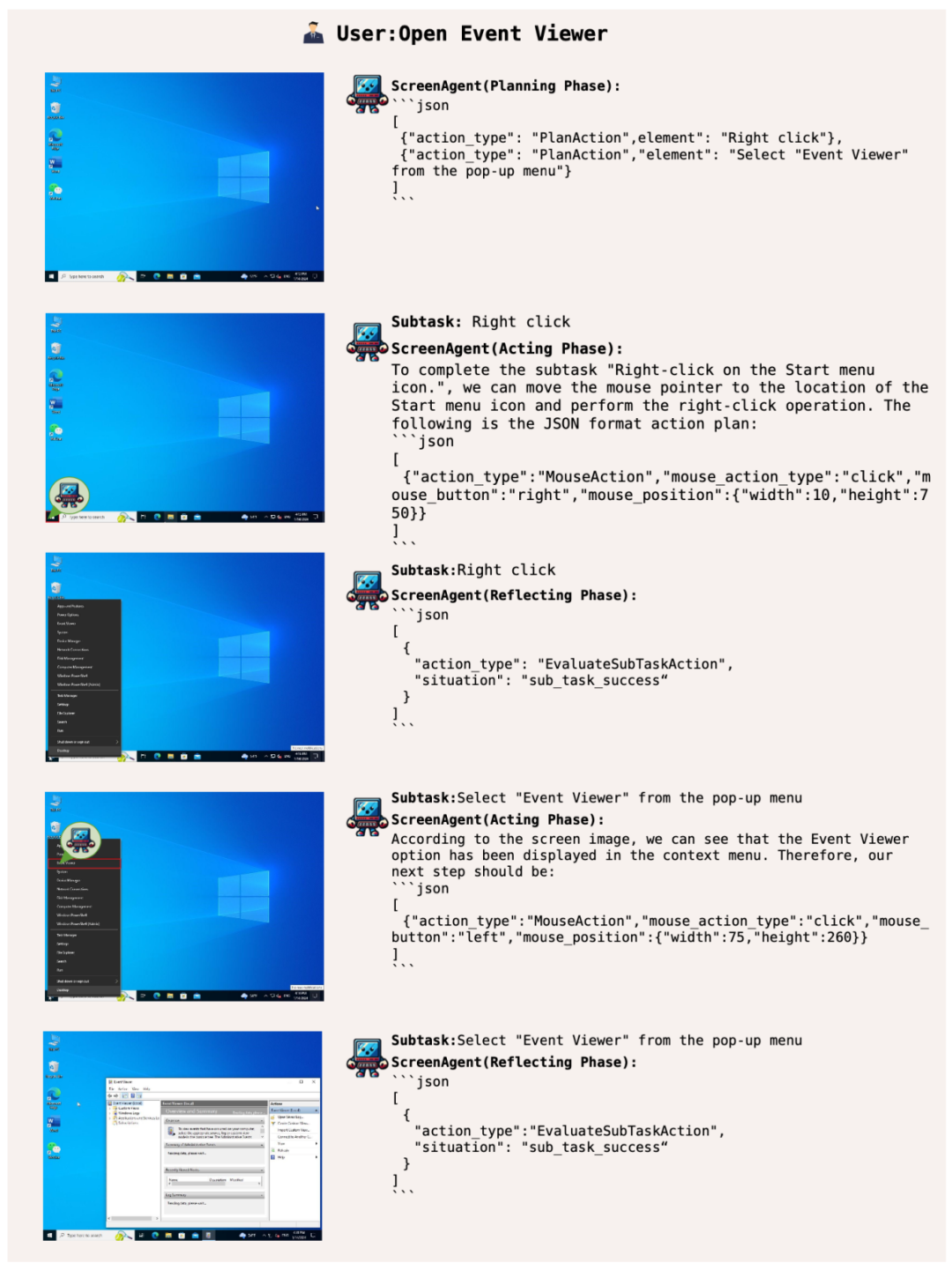
#系統操作管家,賦予使用者高階技能
#讓ScreenAgent 開啟Windows 的事件檢視器:
掌握辦公室技能,輕鬆玩office
此外,ScreenAgent 可以使用office 辦公室軟體。例如根據使用者文字描述,刪除所開啟的第二頁PPT:
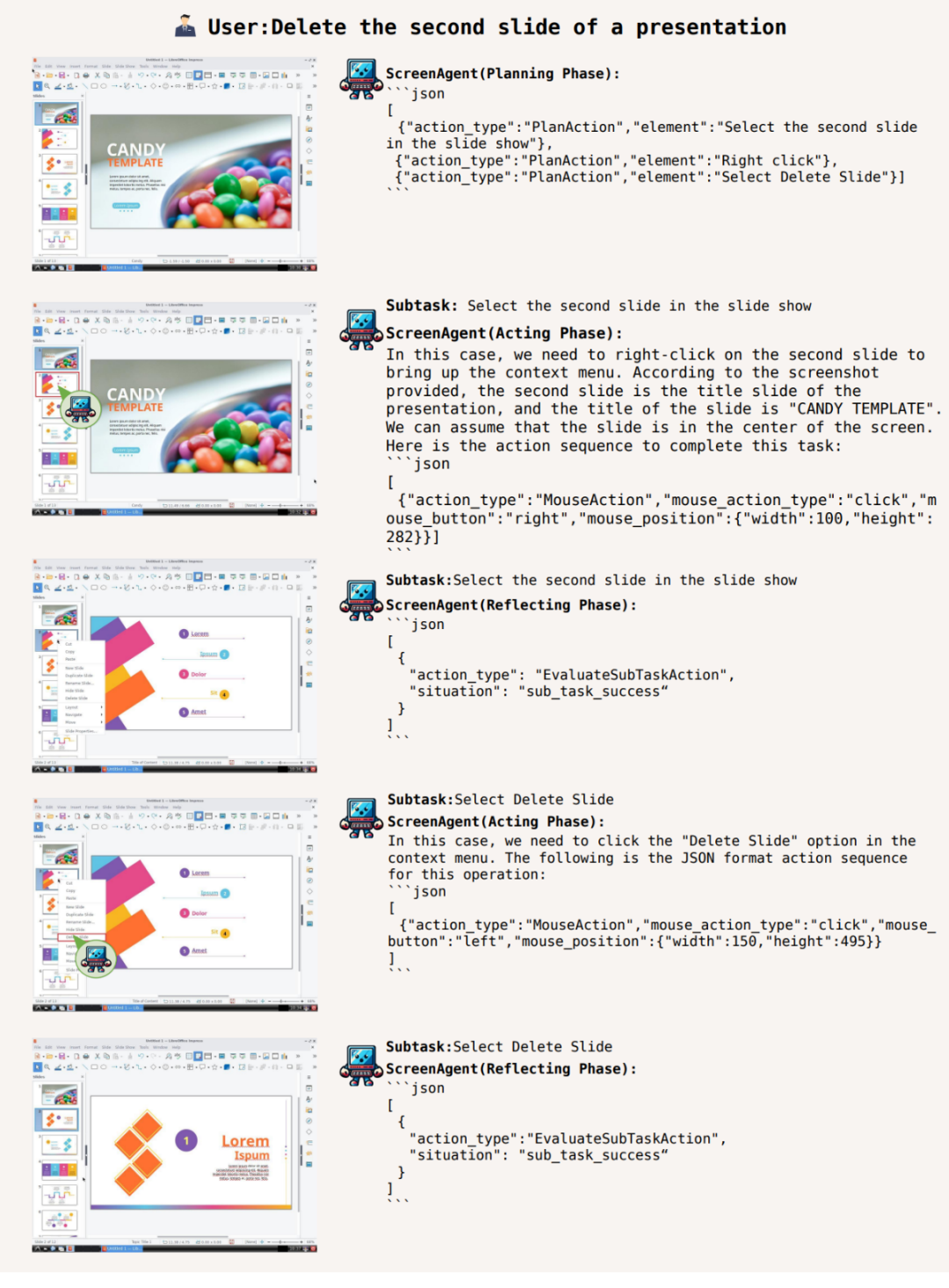
謀定而後動,知止而有得
對於要完成某一任務,在任務執行前必須要做好規劃活動。 ScreenAgent 可以在任務開始前,根據觀測到的圖像和用戶需求,進行規劃,例如:
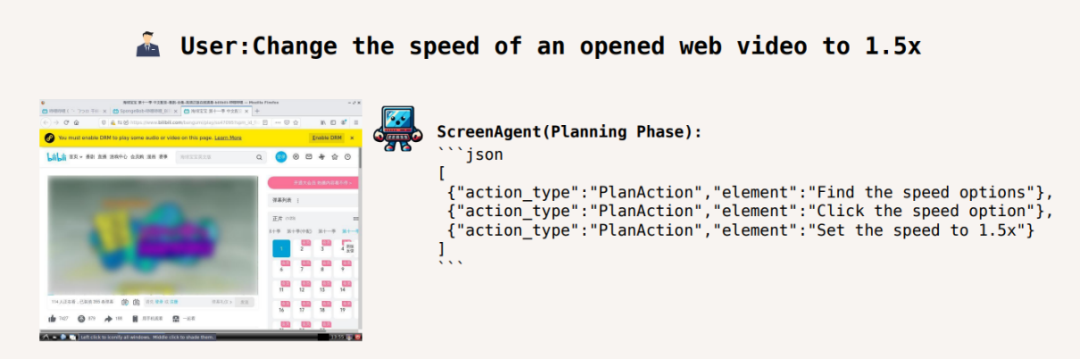
將影片播放速度調至1.5 倍速:

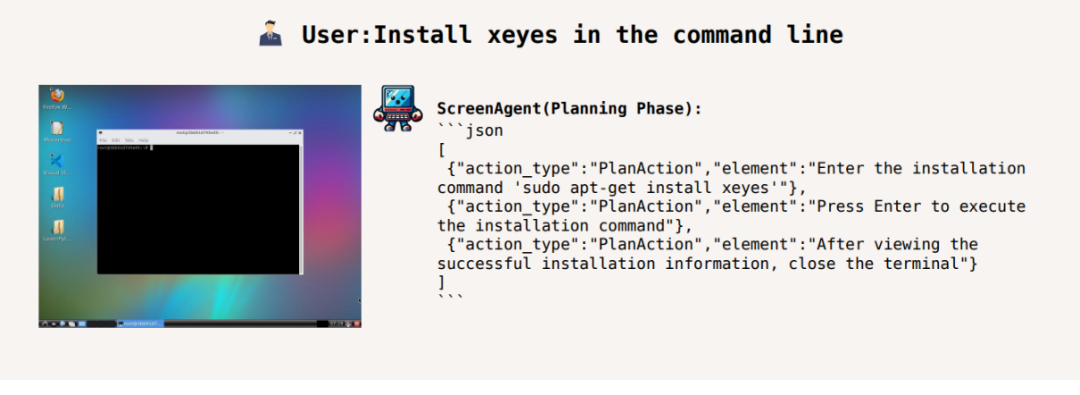
####################################### #############在58 同城網站上搜尋二手邁騰車的價格:#####################在命令列裡安裝xeyes:########################視覺定位能力遷移,滑鼠選取無壓力#########
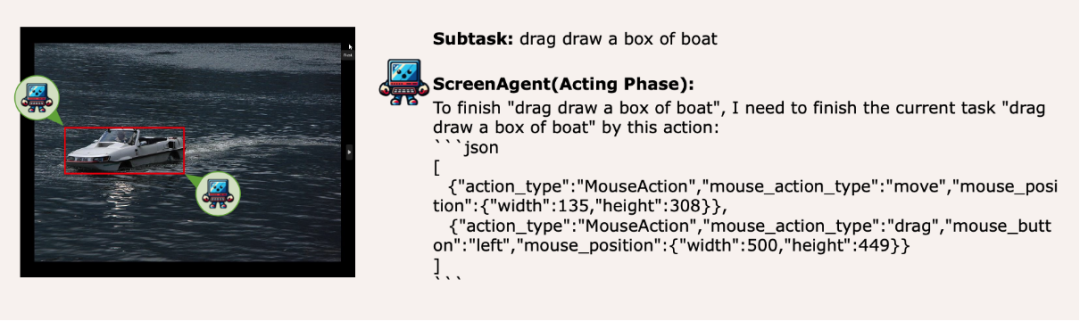
ScreenAgent также сохраняет возможность визуально находить природные объекты и может рисовать рамку выделения объекта путем перетаскивания мыши:

#Метод
На самом деле, научить Агента напрямую взаимодействовать с графическим интерфейсом пользователя – дело не простое, для этого нужен Агент иметь задачи одновременно Комплексные способности, такие как планирование, понимание изображений, визуальное позиционирование и использование инструментов. Существуют определенные компромиссы в существующих моделях или решениях взаимодействия. Получите точные координаты. Существующие решения требуют ручного аннотирования дополнительных цифровых меток на изображениях и позволяют модели выбирать элементы пользовательского интерфейса, на которые необходимо щелкнуть, например Mobile-Agent, UFO и другие проекты; кроме того, такие модели, как CogAgent и Fuyu-8B, могут поддерживать изображения с высоким разрешением. Он имеет возможности ввода и точного визуального позиционирования, но CogAgent не имеет полных возможностей вызова функций, а Fuyu-8B не имеет языковых возможностей.
Для решения вышеперечисленных проблем в статье предлагается построить новую среду для взаимодействия агента модели визуального языка (VLM Agent) с реальным экраном компьютера. В этой среде агент может просматривать снимки экрана и манипулировать графическим интерфейсом пользователя, выводя действия мыши и клавиатуры. Чтобы направлять агента VLM на постоянное взаимодействие с экраном компьютера, в статье строится рабочий процесс, включающий в себя «планирование-исполнение-рефлексия». На этапе планирования агенту предлагается разбить пользовательские задачи на подзадачи. На этапе выполнения агент будет просматривать снимки экрана и выполнять определенные действия с помощью мыши и клавиатуры для выполнения подзадачи. Контроллер выполнит эти действия и отправит результат выполнения агенту. На этапе отражения агент наблюдает за результатами выполнения, определяет текущий статус и решает продолжить выполнение, повторить попытку или скорректировать план. Этот процесс продолжается до тех пор, пока задача не будет выполнена. Стоит отметить, что ScreenAgent не требует использования каких-либо модулей распознавания текста или распознавания значков и использует сквозной подход для обучения всех возможностей модели.
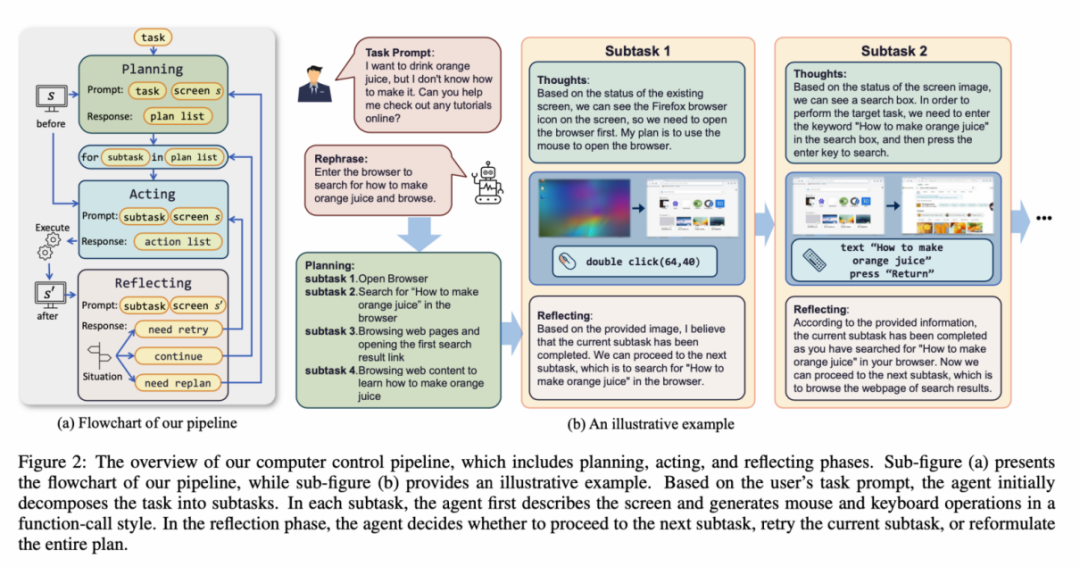
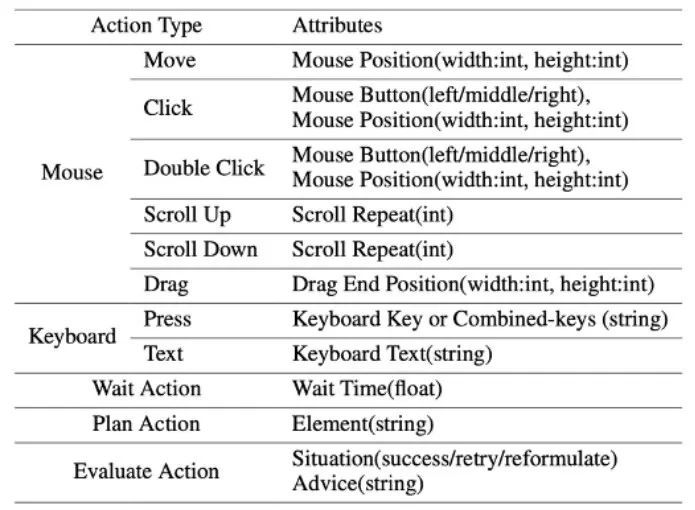
Среда ScreenAgent относится к протоколу подключения к удаленному рабочему столу VNC для проектирования пространства действий агента, включая самые основные операции с мышью и клавиатурой, а также щелчок мышью. Все операции требуют от агента указания точных координат на экране. По сравнению с вызовом конкретных API для выполнения задач, этот метод является более общим и может применяться к различным настольным операционным системам и приложениям, таким как Windows и Linux Desktop.
##Набор данных ScreenAgent
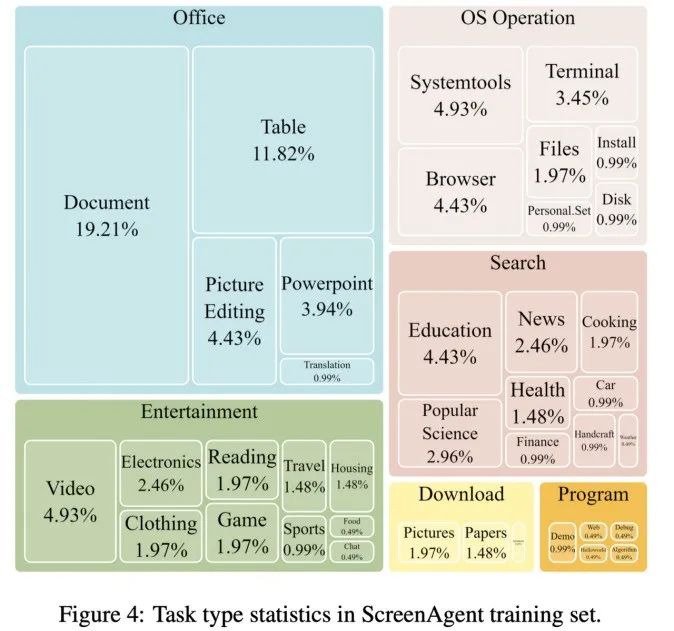
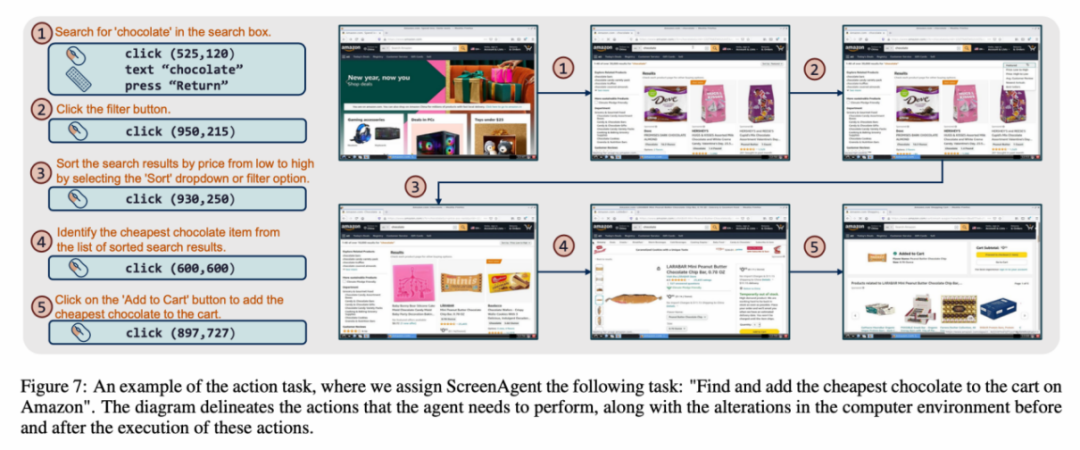
Каждый образец в наборе данных представляет собой полный процесс выполнения задачи, включая описания действий, снимки экрана и конкретные выполняемые действия. Например, в случае «добавления самого дешевого шоколада в корзину» на сайте Amazon вам нужно сначала выполнить поиск по ключевым словам в окне поиска, затем использовать фильтры для сортировки цен и, наконец, добавить в покупки самые дешевые товары. тележка. Весь набор данных содержит 273 полные записи задач.
Результаты экспериментов#В части экспериментального анализа автор объединил ScreenAgent с несколькими существующими моделями VLM Сравнения проводятся с разных точек зрения, в основном включая два уровня, способность следовать инструкциям и точность детального прогнозирования действий. Способность, следующая за инструкциями, в основном проверяет, может ли модель правильно выводить последовательность действий и тип действия в формате JSON. Точность прогнозирования атрибута действия сравнивает, правильно ли предсказано значение атрибута каждого действия, например положение щелчка мыши, клавиши клавиатуры и т. д.
#########Инструкции следуют###############Что касается следования командам, первая задача агента — вывести правильный вызов функции инструмента в соответствии со словом подсказки, то есть вывести правильный формат JSON. В этом отношении как ScreenAgent, так и GPT -4V очень хорошо выполняет команды, однако оригинальный CogAgent потерял возможность вывода JSON из-за отсутствия поддержки данных в виде вызовов API во время обучения визуальной тонкой настройке.
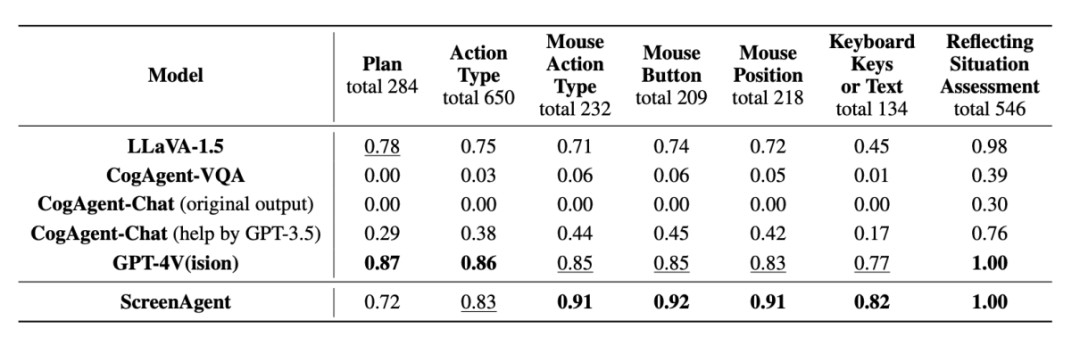
##Точность прогнозирования атрибута действия
От точности действия Атрибуты По производительности ScreenAgent также достиг уровня, сравнимого с GPT-4V. Примечательно, что ScreenAgent значительно превосходит существующие модели по точности щелчков мышью. Это показывает, что точная визуальная настройка эффективно повышает точность позиционирования модели. Кроме того, мы также наблюдаем явный разрыв между ScreenAgent и GPT-4V в планировании миссий, что подчеркивает здравый смысл GPT-4V и возможности планирования миссий.
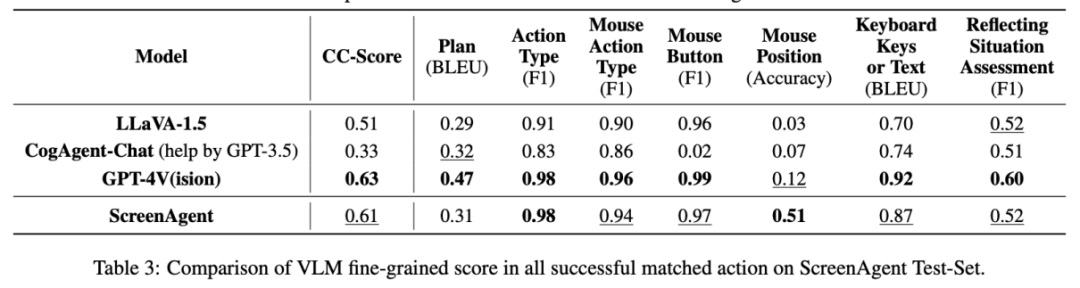
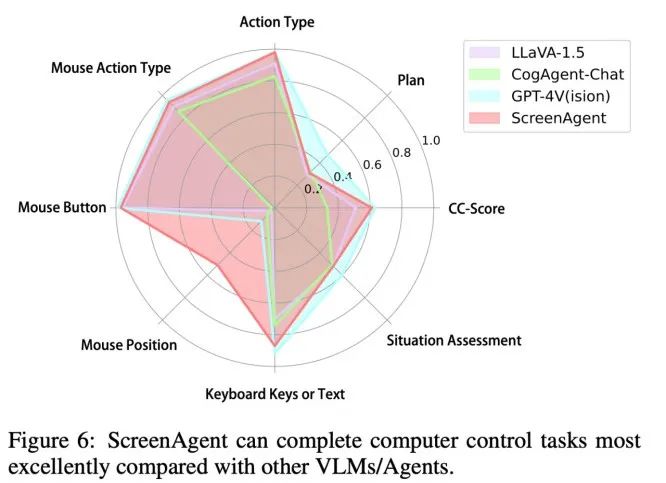
#Предложено командой Школы Искусственного интеллекта Университета Цзилинь. ScreenAgent может управлять компьютерами так же, как люди, не полагается на другие API или модели оптического распознавания символов и может широко использоваться в различном программном обеспечении и операционных системах. ScreenAgent может автономно выполнять поставленные пользователем задачи под контролем процесса «план-выполнение-рефлексия». Таким образом, пользователи могут видеть каждый этап выполнения задачи и лучше понимать поведенческие мысли Агента.
В статье открыты исходные коды управляющего программного обеспечения, кода обучения модели и набора данных. На этой основе вы можете изучить более передовые разработки в области общего искусственного интеллекта, такие как обучение с подкреплением с учетом обратной связи с окружающей средой, активное исследование агентом открытого мира, построение моделей мира, библиотек навыков агента и т. д.
Кроме того, персональные помощники, управляемые агентом ИИ, имеют огромную социальную ценность, например, помогая людям с ограниченными конечностями использовать компьютеры, сокращая рутинную цифровую работу человека и популяризируя компьютерное образование. В будущем, возможно, не каждый сможет стать таким супергероем, как Железный Человек, но у всех нас может быть эксклюзивный Джарвис, умный партнер, который сможет сопровождать, помогать и направлять нас в нашей жизни и работе, принося больше удобства и возможностей.
以上是Windows、Office直接上手,大模型智慧體操作電腦太6了的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 vscode怎麼查看word文件 vscode檢視word文件的方法
May 09, 2024 am 09:37 AM
vscode怎麼查看word文件 vscode檢視word文件的方法
May 09, 2024 am 09:37 AM
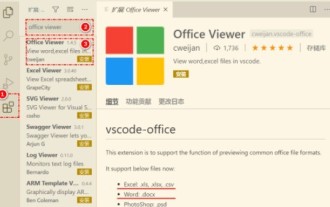
首先,在電腦上開啟vscode軟體,點選左邊的【Extension】(擴充)圖標,如圖中①所示然後,在擴充介面的搜尋框中輸入【officeviewer】,如圖中②所示接著,從搜尋結果中選擇【officeviewer】安裝,如圖中③所示最後,開啟文件,如docx,pdf等,如下圖
 WPS和Office沒有中文字體,中文字體名稱顯示為英文
Jun 19, 2024 am 06:56 AM
WPS和Office沒有中文字體,中文字體名稱顯示為英文
Jun 19, 2024 am 06:56 AM
小夥伴電腦,WPS和OFFICE中字體仿宋、楷體、行楷、微軟雅黑等所有中文字體都找不到,下面小編來說說如何解決這個問題。系統中字體正常,WPS字體選項中所有字體都沒有,只有雲端字體。 OFFICE只有英文字體,中文字體一個都沒有。 WPS安裝不同版本後,英文字體有了,但同樣一個中文字體都沒有。解決方法:控制台→類別→時鐘、語言和區域→更改顯示語言→(區域和語言)管理→(非Unicode程式的語言)更改系統區域設定→中文(簡體,中國)→重新啟動。控制面板,右上角查看方式改為“類別”,時鐘、語言和區域,更改
 3d渲染,電腦配置?做設計3D渲染需要配置什麼樣的電腦?
May 06, 2024 pm 06:25 PM
3d渲染,電腦配置?做設計3D渲染需要配置什麼樣的電腦?
May 06, 2024 pm 06:25 PM
3d渲染,電腦配置? 1電腦配置對於3D渲染非常重要,需要足夠的硬體效能才能確保渲染效果和速度。 23D渲染需要大量的運算和影像處理,因此需要高效能的CPU、顯示卡和記憶體。 3建議配置至少一台搭載至少6核心12執行緒的CPU、16GB以上的記憶體和一張高效能顯示卡的電腦,才能滿足較高的3D渲染需求。同時,也需要注意電腦的散熱和電源等方面的配置,以確保電腦的穩定運作。做設計3D渲染需要配置什麼樣的電腦?本人也是做設計的,給你一套配置吧(本人再用)CPU:amd960t開6核心(或1090t直接超頻)記憶體:1333
 iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
在iPhone上面臨滯後,緩慢的行動數據連線?通常,手機上蜂窩互聯網的強度取決於幾個因素,例如區域、蜂窩網絡類型、漫遊類型等。您可以採取一些措施來獲得更快、更可靠的蜂窩網路連線。修復1–強制重啟iPhone有時,強制重啟設備只會重置許多內容,包括蜂窩網路連線。步驟1–只需按一次音量調高鍵並放開即可。接下來,按降低音量鍵並再次釋放它。步驟2–過程的下一部分是按住右側的按鈕。讓iPhone完成重啟。啟用蜂窩數據並檢查網路速度。再次檢查修復2–更改資料模式雖然5G提供了更好的網路速度,但在訊號較弱
 特斯拉機器人進廠打工,馬斯克:手的自由度今年將達到22個!
May 06, 2024 pm 04:13 PM
特斯拉機器人進廠打工,馬斯克:手的自由度今年將達到22個!
May 06, 2024 pm 04:13 PM
特斯拉機器人Optimus最新影片出爐,已經可以在工廠裡打工了。正常速度下,它分揀電池(特斯拉的4680電池)是這樣的:官方還放出了20倍速下的樣子——在小小的「工位」上,揀啊揀啊揀:這次放出的影片亮點之一在於Optimus在廠子裡完成這項工作,是完全自主的,全程沒有人為的干預。而且在Optimus的視角之下,它還可以把放歪了的電池重新撿起來放置,主打一個自動糾錯:對於Optimus的手,英偉達科學家JimFan給出了高度的評價:Optimus的手是全球五指機器人裡最靈巧的之一。它的手不僅有觸覺
 福昕PDF編輯器怎麼將PDF轉換成PPT_福昕PDF編輯器將PDF轉換成PPT教程
Apr 30, 2024 pm 03:13 PM
福昕PDF編輯器怎麼將PDF轉換成PPT_福昕PDF編輯器將PDF轉換成PPT教程
Apr 30, 2024 pm 03:13 PM
1.先開啟福昕PDF編輯器軟體。 2.然後用福昕PDF編輯器開啟PDF文檔,如圖所示:3、頂部工具列切換到【轉換】標籤頁。 4.接著選擇【到MSOffice】下拉式選單裡的【PowerPoint】。 5.最後將轉換後的PPT文件儲存到所需的位置即可。
 快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
什麼?瘋狂動物城被國產AI搬進現實了?與影片一同曝光的,是一款名為「可靈」全新國產影片生成大模型。 Sora利用了相似的技術路線,結合多項自研技術創新,生產的影片不僅運動幅度大且合理,還能模擬物理世界特性,具備強大的概念組合能力與想像。數據上看,可靈支持生成長達2分鐘的30fps的超長視頻,分辨率高達1080p,且支援多種寬高比。另外再劃個重點,可靈不是實驗室放出的Demo或影片結果演示,而是短影片領域頭部玩家快手推出的產品級應用。而且主打一個務實,不開空頭支票、發布即上線,可靈大模型已在快影
 超級智能體生命力覺醒!可自我更新的AI來了,媽媽再也不用擔心資料瓶頸難題
Apr 29, 2024 pm 06:55 PM
超級智能體生命力覺醒!可自我更新的AI來了,媽媽再也不用擔心資料瓶頸難題
Apr 29, 2024 pm 06:55 PM
哭死啊,全球狂煉大模型,一網路的資料不夠用,根本不夠用。訓練模型搞得跟《飢餓遊戲》似的,全球AI研究者,都在苦惱怎麼才能餵飽這群資料大胃王。尤其在多模態任務中,這問題尤其突出。一籌莫展之際,來自人大系的初創團隊,用自家的新模型,率先在國內把「模型生成數據自己餵自己」變成了現實。而且還是理解側和生成側雙管齊下,兩側都能產生高品質、多模態的新數據,對模型本身進行數據反哺。模型是啥?中關村論壇上剛露面的多模態大模型Awaker1.0。團隊是誰?智子引擎。由人大高瓴人工智慧學院博士生高一鑷創立,高
