
B站我想大家都熟悉吧,其實 B 站的爬蟲網上一搜一大堆。不過紙上得來終覺淺,絕知此事要躬行,我碼故我在。最終爬取到資料總量為 760萬 條。
準備工作
先打開 B 站,隨便在首頁找一個影片點擊進去。常規操作,開啟開發者工具。這次是目標是透過爬取 B 站提供的 api 來獲取視頻信息,不去解析網頁,解析網頁的速度太慢了而且容易被封 ip。
勾選 JS 選項,F5 刷新
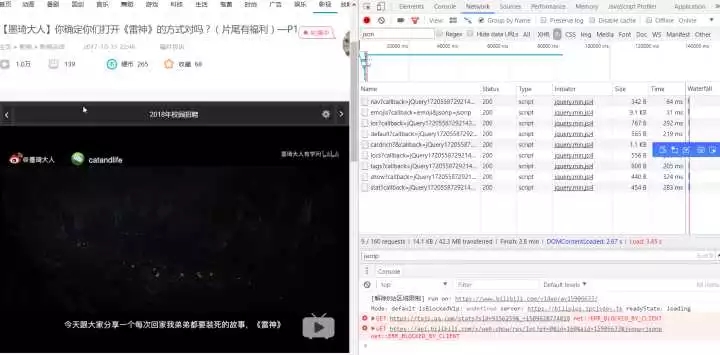
#找到了 api 的位址
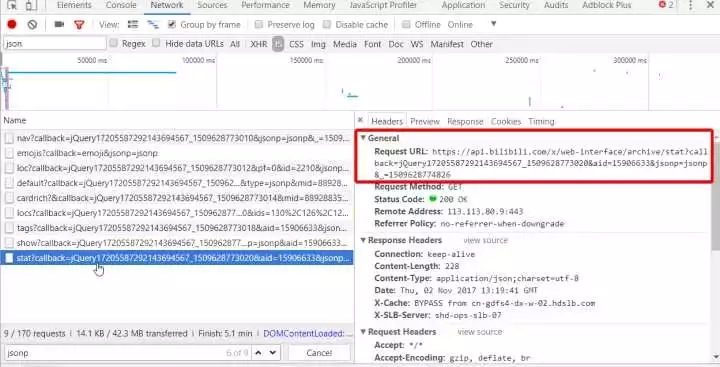
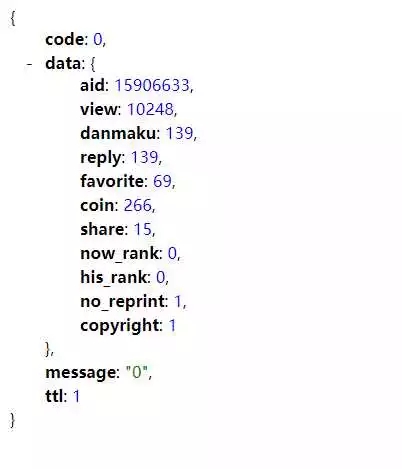
#複製下來,去掉沒必要的內容,得到https://api.bilibili.com/x/web-interface/archive/stat?aid=15906633 ,用瀏覽器打開,會得到如下的json 資料
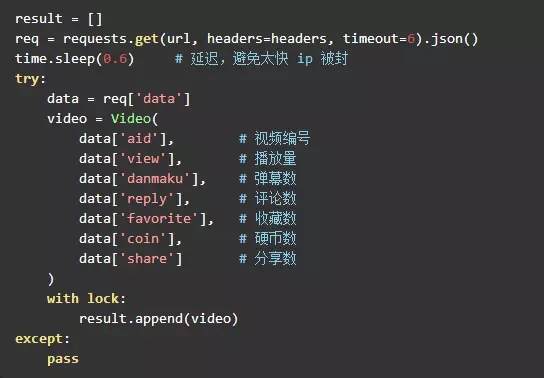
#動手寫碼
#好了,到這裡程式碼就可以碼起來了,透過 request 不斷的迭代獲取數據,為了讓爬蟲更有效率,可以利用多線程。
核心程式碼
#迭代爬取

##整個專案的最主要部分的程式碼也就是 20 行左右,挺簡潔的。
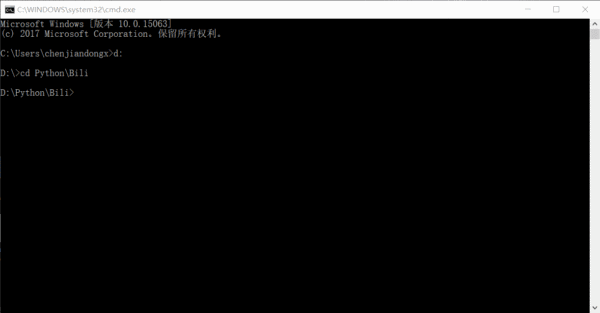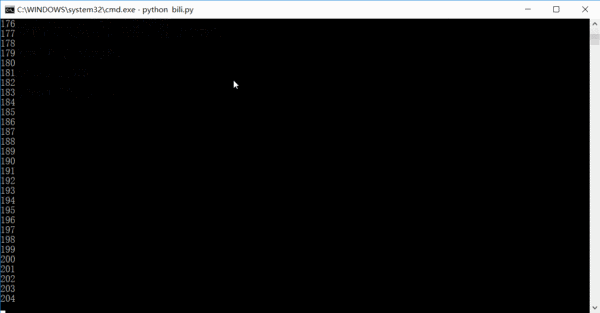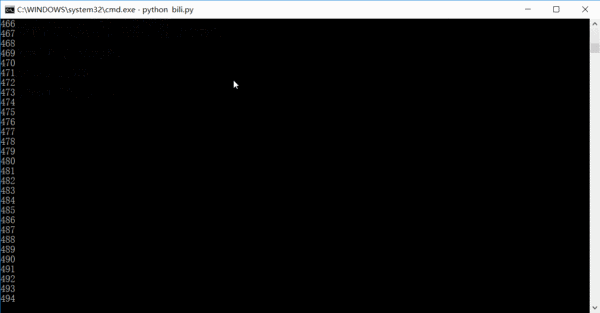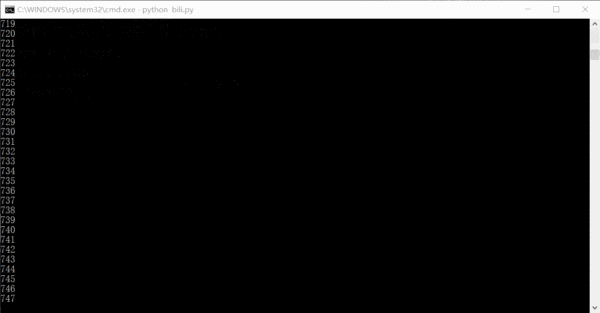
運行的效果大概是這樣的,數字是已經已經爬取了多少條鏈接,其實完全可以在一天或者兩天內就把全站信息爬完的。
#至於爬取後要怎麼處理就看自己愛好了,我是先儲存為 csv 文件,然後再匯總插入到資料庫。
資料庫表格
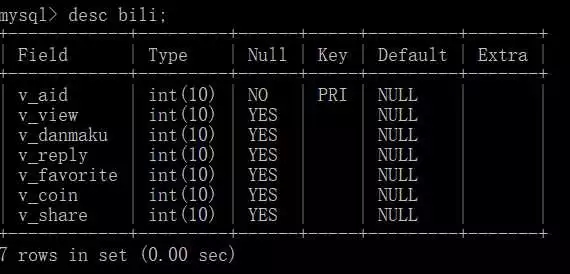
#由於這些內容是我在幾個月前爬取的,所以數據其實有些落後了。
資料總量
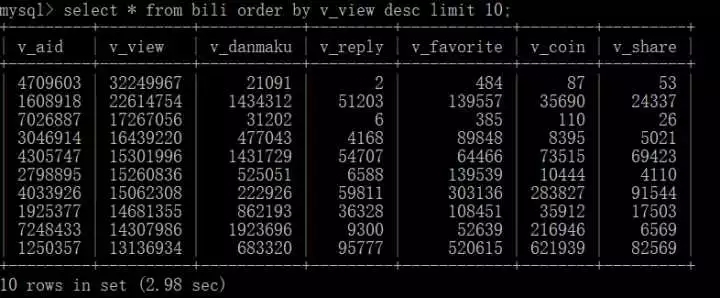
##查詢播放量前十名的影片
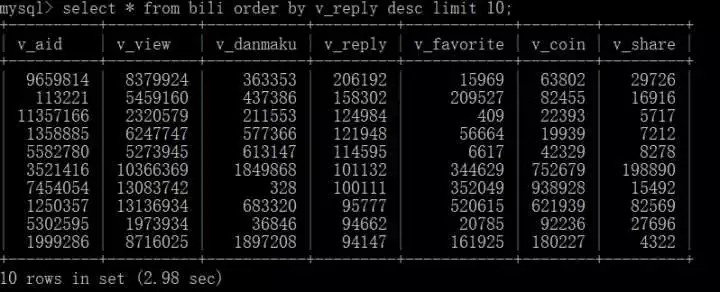
#查詢回覆量前十名的影片
以上是使用Python爬取B站全站視訊訊息的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















