

NLP大模型如何應用到時間序列?五類方法大總結!

最近,加州大學發布了一篇綜述文章,探討了將自然語言處理領域的預訓練大語言模型應用於時間序列預測的方法。文章總結了5種不同的NLP大模型在時間序列領域的應用方式。接下來,我們將簡要介紹這篇綜述中提及的這5種方法。
 圖片
圖片
論文標題:Large Language Models for Time Series: A Survey
下載網址:https://arxiv.org /pdf/2402.01801.pdf
 圖片
圖片
1、基於Prompt的方法
透過直接利用prompt的方法,模型可以針對時間序列資料進行預測輸出。先前的prompt方法中,基本想法是預先訓練一個prompt文本,將時間序列資料填入其中,讓模型產生預測結果。例如,在建構描述時間序列任務的文字時,填入時間序列數據,讓模型直接輸出預測結果。
 圖片
圖片
在處理時間序列時,數字經常被視為文字的一部分,數字的tokenize問題也備受關注。有些方法特別在數字之間加入空格,以便更清晰地區分數字,避免字典中對數字的不合理區分。
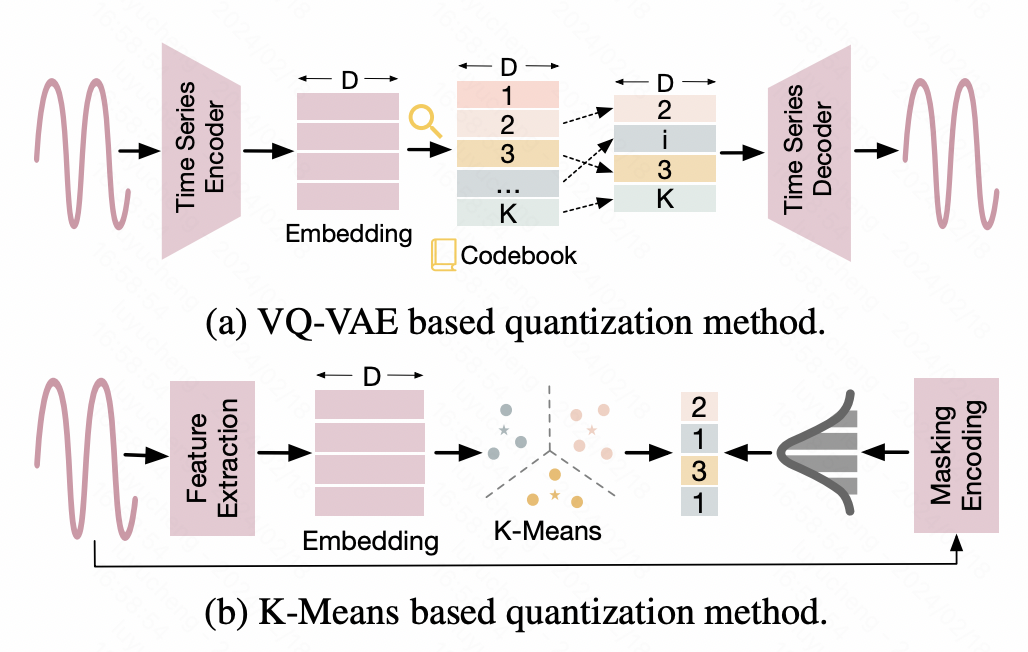
2、離散化
這類方法將時間序列離散化處理,將連續的數值轉換為離散的id化結果,以適配NLP大模型的輸入形式。例如,一種方法是藉助Vector Quantized-Variational AutoEncoder(VQ-VAE)技術,將時間序列映射成離散的表徵。 VQ-VAE是一種VAE基礎上的autoencoder結構,VAE透過Encoder將原始輸入映射成表徵向量,再透過Decoder還原原始資料。而VQ-VAE則保證了中間產生的表徵向量是離散化的。根據這個離散化表徵向量建構成一個詞典,實現時間序列資料離散化的映射。另一種方法是基於K-means的離散化,利用Kmeans生成的質心將原始的時間序列離散化。另外再一些工作中,也將時間序列直接轉換成文本,例如在一些金融場景中,將每天的漲價、降價等信息直接轉換成相應的字母符號作為NLP大模型的輸入。
 圖片
圖片
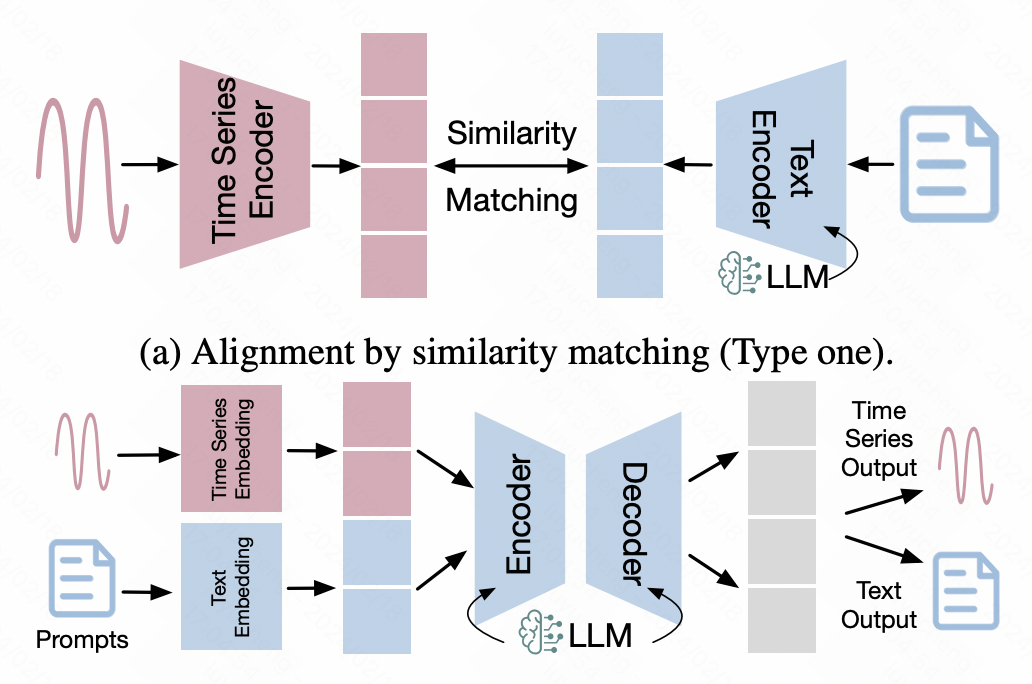
3、時間序列-文字對齊
這類方法借助到多模態領域的對齊技術,將時間序列的表徵對齊到文字空間,以此實現時間序列資料直接輸入到NLP大模型的目標。
在這類方法中,一些多模態對齊的方法被廣泛地應用其中。一種最典型的就是基於對比學習的多模態對齊,類似CLIP,使用時間序列編碼器和大模型分別輸入時間序列和文本的表示向量,然後使用對比學習拉近正樣本對之間的距離,在隱空間對齊時間序列資料和文字資料的表徵。
另一種方法是基於時間序列資料的finetune,以NLP大模型作為backbone,在此基礎上引入額外的網路適配時間序列資料。這其中,LoRA等跨模態finetune的高效方法比較常見,凍結backbone的大部分參數,只對小部分參數進行finetune,或者引入少量的adaptor參數進行finetune,以達到多模態對齊的效果。
 圖片
圖片
4、引入視覺訊息
這種方法比較少見,一般是將時間序列和視覺訊息建立聯繫,再將利用圖像和文字已經經過比較深入研究的多模態能力引入進來,為下游任務提取有效的特徵。例如ImageBind中對6個模態的數據進行統一的對齊,其中就包括時間序列類型的數據,實現多模態的大模型統一。一些金融領域的模型,將股票的價格轉換成圖表數據,再配合CLIP進行圖文對齊,產生圖表相關的特徵用於下游的時間序列任務。
5、大模型工具
這類方法不再對NLP大模型進行模型上的改進,或是改造時間序列資料形式進行大模型適配,而是直接將NLP大模型當成一個工具,解決時間序列問題。例如,讓大模型產生解決時間序列預測的程式碼,應用到時間序列預測上;或是讓大模型呼叫開源的API解決時間序列問題。當然這類方式就比較偏向實際應用了。
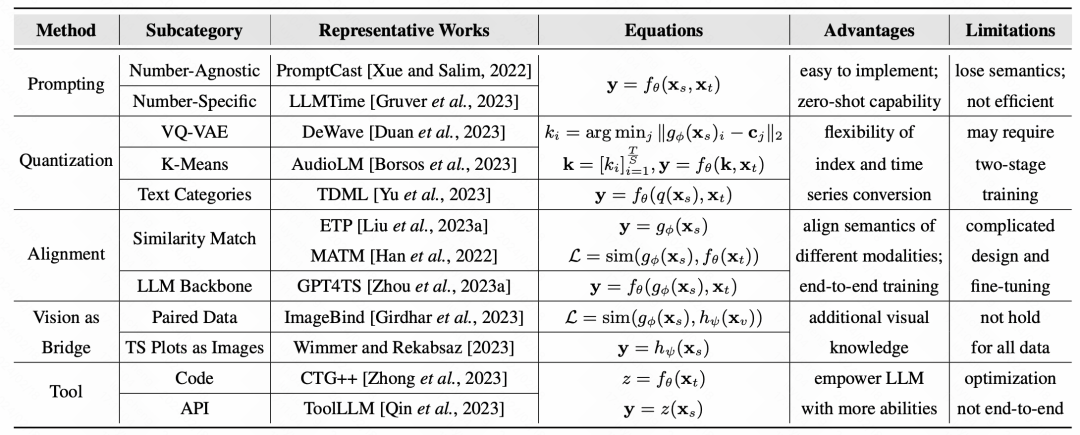
最後,文中總結了各類別方法的代表工作以及代表資料集:
 #圖片
#圖片
以上是NLP大模型如何應用到時間序列?五類方法大總結!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 大模型App騰訊元寶上線!混元再升級,打造可隨身攜帶的全能AI助理
Jun 09, 2024 pm 10:38 PM
大模型App騰訊元寶上線!混元再升級,打造可隨身攜帶的全能AI助理
Jun 09, 2024 pm 10:38 PM
5月30日,騰訊宣布旗下混元大模型全面升級,基於混元大模型的App「騰訊元寶」正式上線,蘋果及安卓應用程式商店皆可下載。相較於先前測試階段的混元小程式版本,面向工作效率場景,騰訊元寶提供了AI搜尋、AI總結、AI寫作等核心能力;面向日常生活場景,元寶的玩法也更加豐富,提供了多個特色AI應用,並新增了創建個人智能體等玩法。 「騰訊做大模型不爭一時之先。」騰訊雲副總裁、騰訊混元大模型負責人劉煜宏表示:「過去的一年,我們持續推進騰訊混元大模型的能力爬坡,在豐富、海量的業務場景中打磨技術,同時洞察用戶的真實需求
 位元組跳動豆包大模型發布,火山引擎全端 AI 服務協助企業智慧轉型
Jun 05, 2024 pm 07:59 PM
位元組跳動豆包大模型發布,火山引擎全端 AI 服務協助企業智慧轉型
Jun 05, 2024 pm 07:59 PM
火山引擎總裁譚待企業要做好大模型落地,面臨模型效果、推理成本、落地難度的三大關鍵挑戰:既要有好的基礎大模型做支撐,解決複雜難題,也要有低成本的推理服務讓大模型廣泛應用,還要更多工具、平台和應用程式幫助企業做好場景落地。 ——譚待火山引擎總裁01.豆包大模型首次亮相大使用量打磨好模型模型效果是AI落地最關鍵的挑戰。譚待指出,只有大的使用量,才能打磨出好模型。目前,豆包大模型日均處理1,200億tokens文字、生成3,000萬張圖片。為助力企業做好大模型場景落地,位元組跳動自主研發的豆包大模型將透過火山
 時間序列預測 NLP大模型新作:為時序預測自動產生隱式Prompt
Mar 18, 2024 am 09:20 AM
時間序列預測 NLP大模型新作:為時序預測自動產生隱式Prompt
Mar 18, 2024 am 09:20 AM
今天我想分享一個最新的研究工作,這項研究來自康乃狄克大學,提出了一種將時間序列資料與自然語言處理(NLP)大模型在隱空間上對齊的方法,以提高時間序列預測的效果。此方法的關鍵在於利用隱空間提示(prompt)來增強時間序列預測的準確性。論文標題:S2IP-LLM:SemanticSpaceInformedPromptLearningwithLLMforTimeSeriesForecasting下載網址:https://arxiv.org/pdf/2403.05798v1.pdf1、問題背景大模型
 揭露NVIDIA大模型推理架構:TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
揭露NVIDIA大模型推理架構:TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
一、TensorRT-LLM的產品定位TensorRT-LLM是NVIDIA為大型語言模型(LLM)所開發的可擴展推理方案。它基於TensorRT深度學習編譯框架建構、編譯和執行計算圖,並藉鑒了FastTransformer中高效的Kernels實作。此外,它還利用NCCL實現設備間的通訊。開發者可以根據技術發展和需求差異,客製化算子以滿足特定需求,例如基於cutlass開發客製化的GEMM。 TensorRT-LLM是NVIDIA官方推理方案,致力於提供高效能並不斷完善其實用性。 TensorRT-LL
 工業知識圖譜進階實戰
Jun 13, 2024 am 11:59 AM
工業知識圖譜進階實戰
Jun 13, 2024 am 11:59 AM
一、背景簡介首先來介紹雲問科技的發展歷程。雲問科技公...2023年,正是大模型盛行的時期,很多企業認為已經大模型之後圖譜的重要性大大降低了,之前研究的預置的資訊化系統也都不重要了。不過隨著RAG的推廣、資料治理的盛行,我們發現更有效率的資料治理和高品質的資料是提升私有化大模型效果的重要前提,因此越來越多的企業開始重視知識建構的相關內容。這也推動了知識的建構和加工開始向更高層次發展,其中有許多技巧和方法可以挖掘。可見一個新技術的出現,並不是將所有的舊技術打敗,也有可能將新技術和舊技術相互融合後
 對標GPT-4!中國移動九天大模型通過雙備案
Apr 04, 2024 am 09:31 AM
對標GPT-4!中國移動九天大模型通過雙備案
Apr 04, 2024 am 09:31 AM
4月4日消息,日前,國家網信辦公佈已備案大模型清單,中國移動「九天自然語言交互大模型」名列其中,標誌著中國移動九天AI大模型可正式對外提供生成式人工智慧服務。中國移動表示,這是同時透過國家「生成式人工智慧服務備案」和「境內深度合成服務演算法備案」雙備案的首個央企研發的大模型。據介紹,九天自然語言交互大模型具有產業能力增強、安全可信、支援全端國產化等特點,已形成90億、139億、570億、千億等多種參數量版本,可靈活部署於雲、邊、端不同場
 GPT Store都開不下去,這家國產平台怎麼敢走這條路的? ?
Apr 19, 2024 pm 09:30 PM
GPT Store都開不下去,這家國產平台怎麼敢走這條路的? ?
Apr 19, 2024 pm 09:30 PM
注意看,這個男人把超1000種大模型接入,讓你可插拔無縫切換使用。最近也上線了可視化的AI工作流程:給你一個直覺的拖放介面,拖拖、拉拉、拽拽,就能在無限畫布上編排自己個兒的Workflow。正所謂兵貴神速,量子位聽說,這個AIWorkflow上線不到48小時,就已經有用戶配出了100多個節點的個人工作流程。不賣關子,今天要聊的是LLMOps公司Dify,及其CEO張路宇。張路宇也是Dify的創辦人。投入創業前,有11年的網路經驗。搞產品設計,懂專案管理,也對SaaS有點自己的獨到見解。後來他
 新測試基準發布,最強開源Llama 3尷尬了
Apr 23, 2024 pm 12:13 PM
新測試基準發布,最強開源Llama 3尷尬了
Apr 23, 2024 pm 12:13 PM
如果試題太簡單,學霸和學渣都能考90分,拉不開差距……隨著Claude3、Llama3甚至之後GPT-5等更強模型發布,業界急需一款更難、更有區分度的基準測試。大模型競技場背後組織LMSYS推出下一代基準測試Arena-Hard,引起廣泛關注。 Llama3的兩個指令微調版本實力到底如何,也有了最新參考。與先前大家分數都相近的MTBench相比,Arena-Hard區分度從22.6%提升到87.4%,孰強孰弱一目了然。 Arena-Hard利用競技場即時人類數據構建,與人類偏好一致率也高達89.1%
