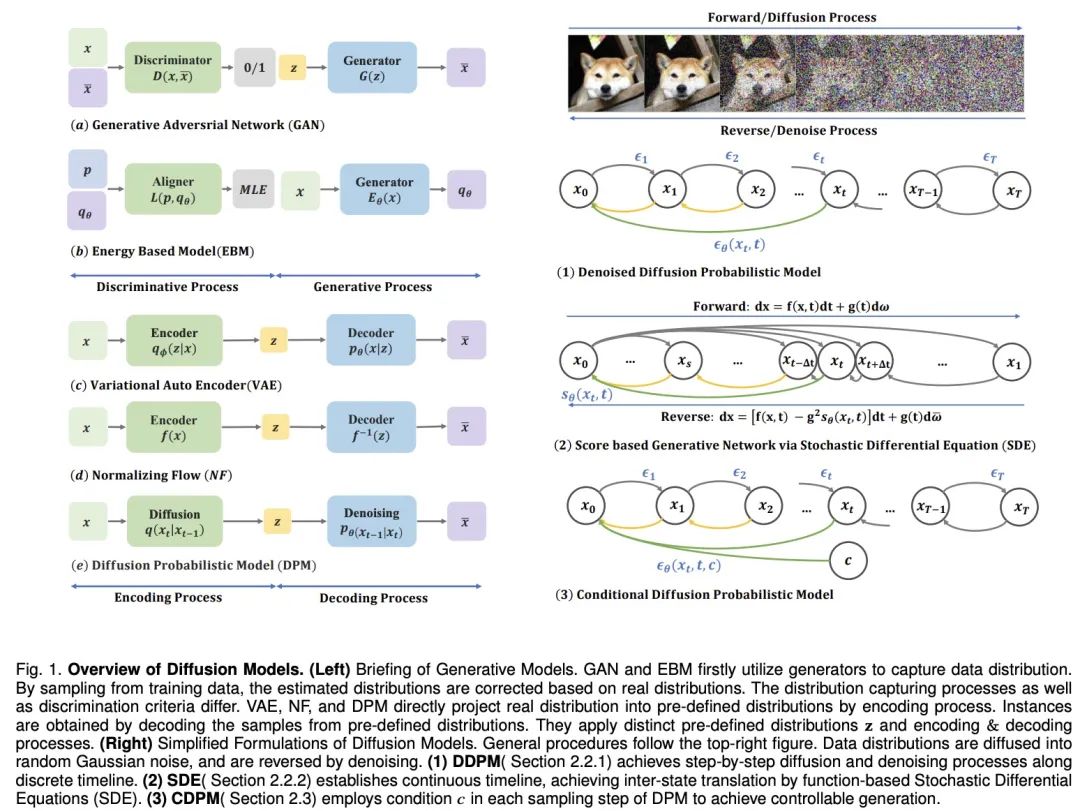
機械が人間の想像力を模倣できるようにするために、深い 生成モデル が大幅に進歩しました。これらのモデルは、現実的なサンプル、特に複数の領域で適切に機能する拡散モデルを作成できます。拡散モデルは、VAE の事後分布整列問題、GAN の不安定性、EBM の計算の複雑さ、NF のネットワーク制約問題など、他のモデルの制限を解決します。そのため、拡散モデルはコンピュータビジョンや自然言語処理などの面で大きな注目を集めています。 #拡散モデルは、順方向プロセスと逆方向プロセスの 2 つのプロセスで構成されます。順方向プロセスではデータが単純な事前分布に変換され、逆方向プロセスではこの変更が逆に行われ、訓練されたニューラル ネットワークを使用して微分方程式をシミュレートしてデータが生成されます。他のモデルと比較して、拡散モデルはより安定したトレーニング ターゲットとより良い生成結果を提供します。

ただし、拡散モデルのサンプリングプロセスには推論と評価の繰り返しが伴います。このプロセスは、不安定性、高次元の計算要件、複雑な尤度の最適化などの課題に直面しています。研究者らは、この目的のために、ODE/SDE ソルバーの改善やサンプリングを高速化するためのモデル蒸留戦略の採用、安定性の向上と次元削減のための新しい前方プロセスなど、さまざまなソリューションを提案してきました。
最近、香港中国語文学、ウェストレイク大学、MIT、志江研究所は、IEEE TKDE に「生成拡散モデルに関する調査」というタイトルのレビュー論文を発表しました。拡散モデルの進歩については、サンプリングの高速化、プロセス設計、尤度の最適化、分布のブリッジングという 4 つの側面から説明します。このレビューでは、画像合成、ビデオ生成、3D モデリング、医療分析、テキスト生成などのさまざまなアプリケーション分野における拡散モデルの成功についても詳しく説明します。これらの応用事例を通じて、現実世界における普及モデルの実用性と可能性が実証されています。
- 論文網址:https://arxiv.org/pdf/2209.02646.pdf
- 計畫網址:https://github.com/chq1155/ A-Survey-on-Generative-Diffusion-Model?tab=readme-ov-file
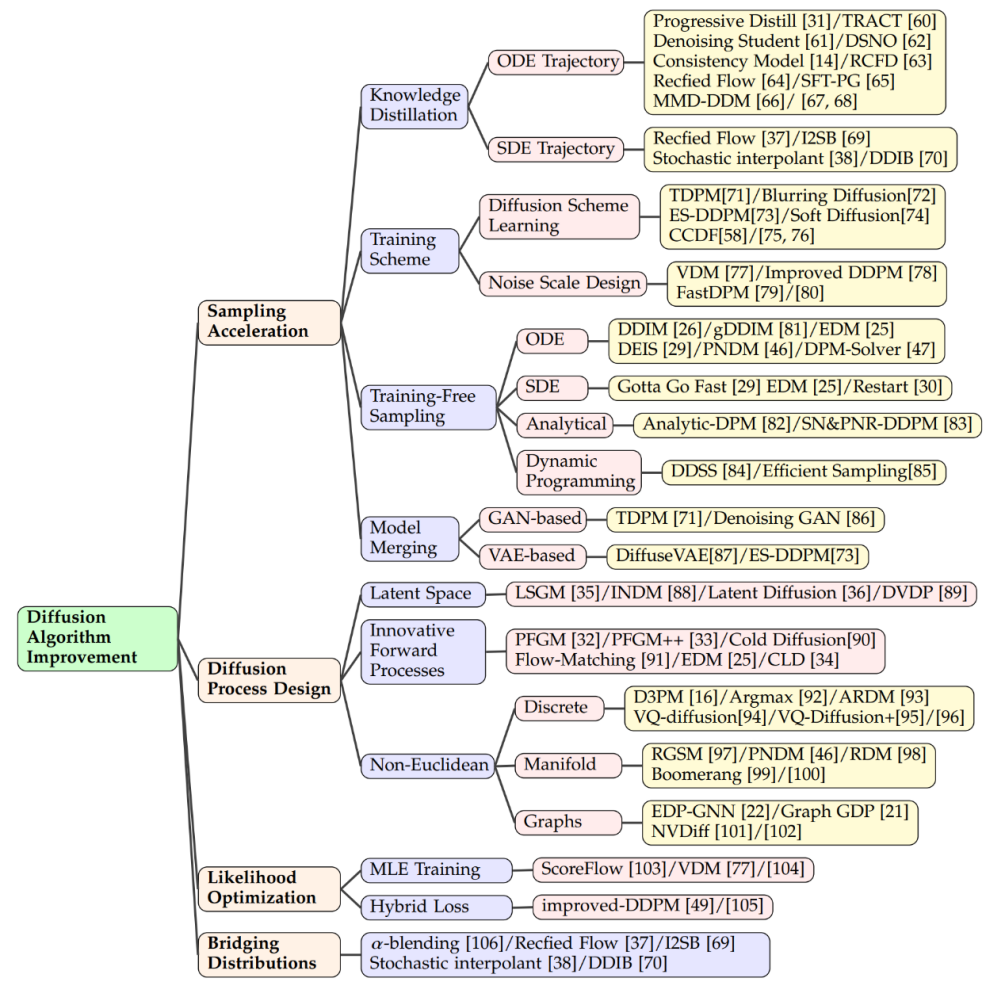
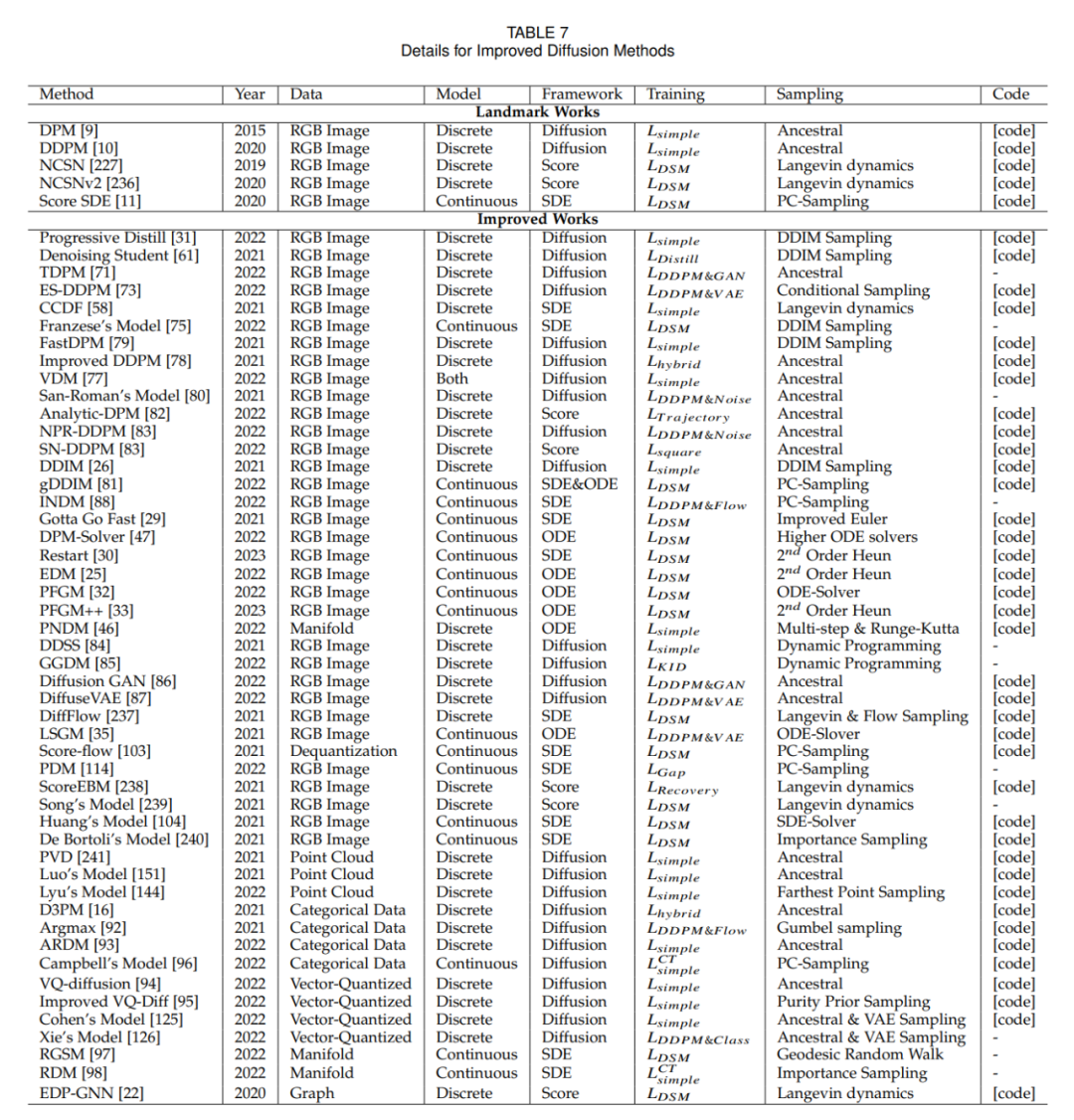
#在擴散模型領域,提高取樣速度的關鍵技術之一是知識蒸餾。這個過程涉及從一個大型、複雜的模型中提取知識,並將其轉移到一個更小、更有效率的模型中。例如,透過使用知識蒸餾,我們可以簡化模型的採樣軌跡,使得在每個步驟中以更高的效率逼近目標分佈。 Salimans 等人採用了一種基於常微分方程(ODE)的方法來優化這些軌跡,而其他研究者則發展了直接從雜訊樣本估計乾淨資料的技術,從而在時間點 T 上加速了這個過程。
改進訓練方式也是提升取樣效率的一種方法。一些研究專注於學習新的擴散方案,其中數據不再簡單地加入高斯噪聲,而是透過更複雜的方法映射到潛在空間。在這些方法中,有些著重於優化逆向解碼過程,例如調整編碼的深度,而其他則探索了新的噪音規模設計,使噪音的加入不再是靜態的,而是變成了一個可以在訓練過程中學習的參數。
除了訓練新的模型以提高效率,還有一些技術致力於加速已經預先訓練好的擴散模型的採樣過程。 ODE 加速是其中的一種技術,它利用 ODE 來描述擴散過程,從而使得採樣可以更快地進行。例如,DDIM 是一種利用 ODE 進行取樣的方法,後續的研究則引入了更有效率的 ODE 求解器,如 PNDM 和 EDM,以進一步提升取樣速度。
此外,還有研究者提出了解析方法來加速取樣,這些方法試圖找到一個無需迭代就能從雜訊資料中直接恢復乾淨資料的解析解。這些方法包括 Analytic-DPM 及其改良版本 Analytic-DPM ,它們提供了一種快速且精確的取樣策略。
擴散過程設計
潛在空間擴散模型如LSGM 和INDM 結合了VAE 或歸一化流模型,透過共用的加權去噪分數匹配損失來最佳化編解碼器和擴散模型,使得ELBO 或對數似然的最佳化旨在建立易於學習和產生樣本的潛在空間。例如,Stable Diffusion 首先使用 VAE 學習潛在空間,然後訓練擴散模型以接受文字輸入。 DVDP 則在影像擾動過程中動態調整像素空間的正交組件。
為了提高生成模型的效率和強度,研究人員探索了新的前向過程設計。泊松場產生模型將資料視為電荷,沿著電場線將簡單分佈引向資料分佈,與傳統擴散模型相比,它提供了更強大的反向取樣。 PFGM 進一步將此概念納入高維度變數。 Dockhorn 等人的臨界阻尼朗之萬擴散模型利用哈密頓動力學中的速度變數簡化了條件速度分佈的分數函數學習。
在離散在空間資料(如文字、分類資料)的擴散模型中,D3PM 定義了離散空間的前向過程。基於這種方法,已有研究擴展到語言文本生成、圖分割和無損壓縮等。在多模態挑戰中,向量量化資料轉換為程式碼,顯示出卓越的結果。在黎曼流形中的流形數據,如機器人技術和蛋白質建模,要求擴散採樣納入黎曼流形。圖神經網路和擴散理論的結合,如 EDP-GNN 和 GraphGDP,處理圖資料來捕捉排列不變性。
似然優化
#######儘管擴散模型優化了ELBO,但似然優化仍是一個挑戰,特別是對於連續時間擴散模型。 ScoreFlow 和變分擴散模型(VDM)等方法建立了 MLE 訓練與 DSM 目標的聯繫,Girsanov 定理在此中扮演了關鍵角色。改進的去噪擴散機率模型(DDPM)提出了一種結合變分下界和 DSM 的混合學習目標,以及簡單的重新參數化技術。#擴散模型在將高斯分佈轉換為複雜分佈時表現出色,但在連接任意分佈時存在挑戰。 α- 混合方法透過迭代混合和解混來創建確定性橋樑。矯正流加入額外步驟來矯正橋樑路徑。另一種方法是透過 ODE 實現兩個分佈之間的連接,而薛丁格橋或高斯分佈作為中間連接點的方法也在研究之中。
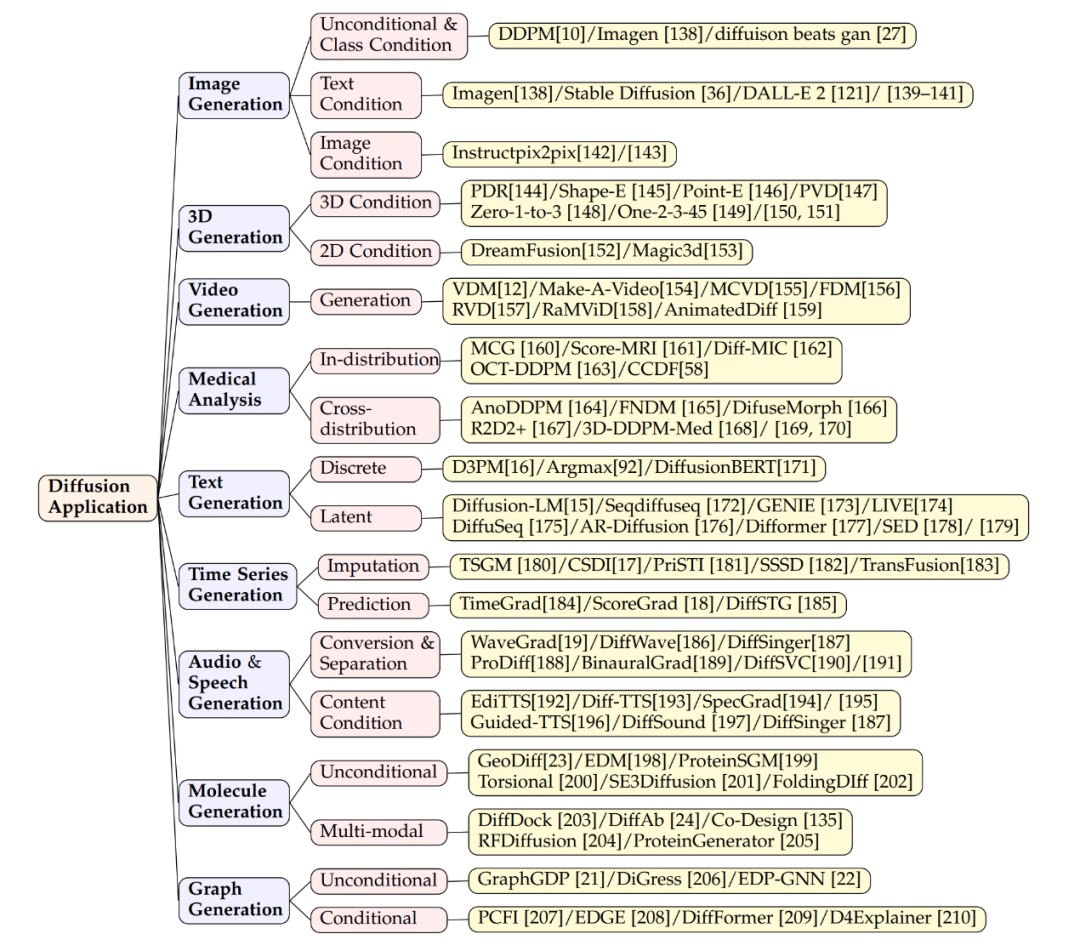
##擴散模型在圖像生成中非常成功,不僅能產生普通圖像,還能完成複雜任務,例如把文字轉換成圖像。模型如 Imagen、Stable Diffusion 和 DALL-E 2 在這方面展示了高超技術。它們使用擴散模型結構,結合跨注意力層的技術,把文字資訊整合進生成影像。除了產生新圖像,這些模型還能編輯圖像而不需再訓練。編輯是透過調整跨注意力層(鍵、值、注意力矩陣)來實現的。例如,透過調整特徵圖改變圖像元素或引入新文字嵌入來加入新概念。有研究確保模型生成時能專注於文本的所有關鍵字,以確保圖像準確反映描述。擴散模型還能處理基於影像的條件輸入,例如來源影像、深度圖或人體骨架等,透過編碼並整合這些特徵來引導影像生成。有些研究把來源影像編碼特徵加入模型開始層,實現影像到影像編輯,也適用於深度圖、邊緣偵測或骨架作為條件的場景。
#在3D 產生方面,透過擴散模型的方法主要有兩種。第一種是直接在 3D 資料上訓練模型,這些模型已有效應用於多種 3D 表示形式,如 NeRF、點雲或體素等。例如,研究者已經展示瞭如何直接產生 3D 物件的點雲。為了提高取樣的效率,一些研究引入了混合點 - 體素表示,或將影像合成作為點雲生成的額外條件。另一方面,有研究使用擴散模型來處理 3D 物件的 NeRF 表示,並透過訓練視角條件擴散模型來合成新穎視圖,優化 NeRF 表示。第二種方法強調使用 2D 擴散模型的先驗知識來產生 3D 內容。例如,Dreamfusion 專案使用得分蒸餾採樣目標,從預先訓練的文字到影像模型中提取出 NeRF,並透過梯度下降最佳化過程來實現低損失的渲染影像。這一過程也被進一步擴展,以加快生成速度。
#影片擴散模型是對2D 影像擴散模型的擴展,它們透過添加時間維度來產生影片序列。這種方法的基本概念是在現有的 2D 結構中添加時間層,以此模擬視訊幀之間的連續性和依賴關係。相關的工作展示如何利用視訊擴散模型來產生動態內容,例如 Make-A-Video、AnimatedDiff 等模型。更具體地,RaMViD 模型使用 3D 卷積神經網路擴展圖像擴散模型到視頻,並開發了一系列視頻特定的條件技術。
#擴散模型幫助解決了醫學分析中獲取高品質數據集的挑戰,尤其在醫學影像方面表現出色。這些模型憑藉其強大的影像捕捉能力,在提升影像的解析度、進行分類和雜訊處理方面取得了成功。例如,Score-MRI 和 Diff-MIC 使用先進的技術加速 MRI 影像的重建和實現更精確的分類。 MCG 在 CT 影像超解析度中採用流形校正,提高了重建速度和準確性。在產生稀有影像方面,透過特定技術,模型能在不同類型的影像間進行轉換。例如,FNDM 和 DiffuseMorph 分別用於腦部異常檢測和 MR 影像配準。一些新方法透過少量高品質樣本合成訓練資料集,如一個使用 31,740 個樣本的模型合成了一個包含 100,000 個實例的資料集,取得了非常低的 FID 得分。
#文字產生技術是連結人類和AI 的重要橋樑,能製造流暢自然的語言。自回歸語言模型雖然產生連貫性強的文本但速度慢,而擴散模型能夠快速生成文本但連貫性相對較弱。兩種主流的方法是離散生成和潛在生成。離散生成依賴先進技術和預訓練模型;例如,D3PM 和 Argmax 視詞彙為分類向量,而 DiffusionBERT 將擴散模型與語言模型結合提昇文本生成。潛在生成則在令牌的潛在空間中產生文本,例如,LM-Diffusion 和 GENIE 等模型在各種任務中表現出色,顯示了擴散模型在文本生成中的潛力。擴散模型預計將在自然語言處理中提升效能,與大型語言模型結合,並支援跨模態生成。
#時間序列資料的建模是在金融、氣候科學、醫療等領域中進行預測與分析的關鍵技術。擴散模型由於其能夠產生高品質的資料樣本,已經被用於時間序列資料的產生。在這個領域,擴散模型通常被設計為考慮時間序列資料的時序依賴性和週期性。例如,CSDI(Conditional Sequence Diffusion Interpolation)是一種模型,它利用了雙向卷積神經網路結構來產生或插補時間序列資料點。它在醫療數據生成和環境數據生成方面表現出色。其他模型如 DiffSTG 和 TimeGrad 透過結合時空卷積網絡,能夠更好地捕捉時間序列的動態特性,並產生更真實的時間序列樣本。這些模型透過自我條件指導的方式,逐漸從高斯雜訊中恢復出有意義的時間序列資料。
#音訊產生涉及從語音合成到音樂生成等多個應用場景。由於音訊資料通常包含複雜的時間結構和豐富的頻譜訊息,擴散模型在此領域同樣表現出潛能。例如,WaveGrad 和 DiffSinger 是兩種擴散模型,它們利用條件生成過程來產生高品質的音訊波形。 WaveGrad 使用 Mel 頻譜作為條件輸入,而 DiffSinger 則在這個基礎上添加了額外的音樂訊息,如音高和節奏,從而提供更精細的風格控制。在文字轉語音(TTS)的應用中,Guided-TTS 和 Diff-TTS 將文字編碼器和聲學分類器的概念結合起來,產生既符合文字內容又遵循特定聲音風格的語音。 Guide-TTS2 進一步展現如何在沒有明確分類器的情況下產生語音,透過模型自身學習到的特徵引導聲音產生。 #在藥物設計、材料科學和化學生物學等領域,分子設計是發現和合成新化合物的重要環節。擴散模型在這裡作為一個強大的工具,能夠有效率地探索化學空間,產生具有特定性質的分子。在無條件的分子生成中,擴散模型不依賴任何先驗知識,自發性地產生分子結構。而在跨模態生成中,模型可能會結合特定的功能條件,例如藥效或目標蛋白的結合傾向,來產生具有所需性質的分子。基於序列的方法可能會考慮蛋白質序列來引導分子的生成,而基於結構的方法則可能使用蛋白質的三維結構資訊。這樣的結構資訊可以在分子對接或抗體設計中被用作先驗知識,從而提高生成分子的品質。 #使用擴散模型產生圖,旨在更好地理解和模擬現實世界的網路結構和傳播過程。這種方法幫助研究人員挖掘複雜系統中的模式和交互作用,預測可能的結果。應用包括社交網路、生物網路分析以及圖資料集的創建。傳統方法依賴產生鄰接矩陣或節點特徵,但這些方法可擴展性差,實用性有限。因此,現代圖生成技術更傾向於根據特定條件產生圖。例如,PCFI 模型使用圖的一部分特徵和最短路徑預測來引導生成過程;EDGE 和 DiffFormer 分別以節點度和能量約束來優化生成;D4Explainer 則透過結合分佈和反事實損失來探索圖的不同可能性。這些方法提高了圖生成的精確度和實用性。
#除了推理速度低外,擴散模型在從低品質資料中辨識模式和規律時也常常遇到困難,導致它們無法泛化到新的場景或資料集。此外,處理大規模資料集時也會出現計算上的挑戰,例如延長的訓練時間、過度的記憶體使用,或無法收斂到期望的狀態,從而限制了模型的規模和複雜性。更重要的是,有偏差或不均勻的數據採樣會限制模型產生適應不同領域或人群的輸出的能力。 #提高模型理解和產生特定分佈內樣本的能力對於在有限數據情況下實現更好的泛化至關重要。透過專注於識別資料中的模式和相關性,模型可以產生與訓練資料高度匹配並滿足特定要求的樣本。這需要有效的資料採樣、利用技術以及優化模型參數和結構。最終,這種增強的理解能力允許更控制和精確的生成,從而改善泛化性能。 擴散模型的未來發展方向涉及透過整合大型語言模型(LLMs)來推進多模態生成。這種整合使模型能夠產生包含文字、圖像和其他模態組合的輸出。透過納入 LLMs,模型對不同模態間相互作用的理解得到增強,產生的輸出更加多樣化和真實。此外,LLMs 顯著提高了基於提示的生成效率,透過有效利用文字與其他模態之間的連結。另外,LLMs 作為催化劑,提高了擴散模型的生成能力,擴大了它可以產生模態的領域範圍。 #將擴散模型與傳統的機器學習理論結合,為提高各種任務的表現提供了新的機會。半監督學習在解決擴散模型的固有挑戰,例如泛化問題,以及在數據有限的情況下實現有效的條件生成方面特別有價值。透過利用未標記數據,它加強了擴散模型的泛化能力,並在特定條件下生成樣本時實現了理想的性能。 此外,強化學習透過使用精調演算法,在模型的取樣過程中提供針對性的指導,起著至關重要的作用。這種指導確保了專注的探索並促進了受控生成。另外,透過整合額外的回饋,豐富了強化學習,進而改善了模型的可控條件生成能力。
以上是爆火Sora背後的技術,一文綜述擴散模型的最新發展方向的詳細內容。更多資訊請關注PHP中文網其他相關文章!



















 Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
 c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
 網頁批註如何實現Y軸位置的自適應佈局?
Apr 04, 2025 pm 11:30 PM
網頁批註如何實現Y軸位置的自適應佈局?
Apr 04, 2025 pm 11:30 PM
 wordpress文章列表怎麼調
Apr 20, 2025 am 10:48 AM
wordpress文章列表怎麼調
Apr 20, 2025 am 10:48 AM
 Bootstrap如何讓圖片在容器中居中
Apr 07, 2025 am 09:12 AM
Bootstrap如何讓圖片在容器中居中
Apr 07, 2025 am 09:12 AM

 如何讓Element UI中同一行相鄰列的高度自動適應內容?
Apr 05, 2025 am 06:12 AM
如何讓Element UI中同一行相鄰列的高度自動適應內容?
Apr 05, 2025 am 06:12 AM
 oracle數據庫怎麼學
Apr 11, 2025 pm 02:54 PM
oracle數據庫怎麼學
Apr 11, 2025 pm 02:54 PM
