

GoogleAI影片再出王炸!全能通用視覺編碼器VideoPrism,效能刷新30項SOTA

AI視訊模型Sora爆紅之後,Meta、Google等大廠紛紛下場做研究,追趕OpenAI的步伐。
最近,來自Google團隊的研究人員提出了一種通用視訊編碼器——VideoPrism。
它能夠透過單一凍結模型,處理各種影片理解任務。
 圖片
圖片
論文網址:https://arxiv.org/pdf/2402.13217.pdf
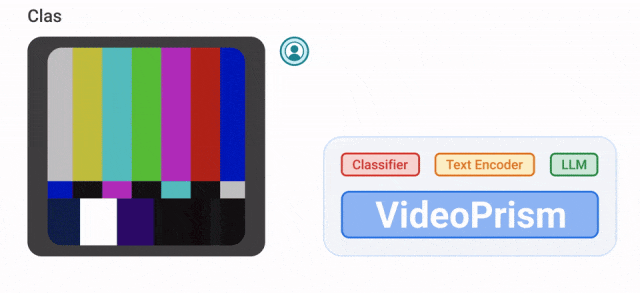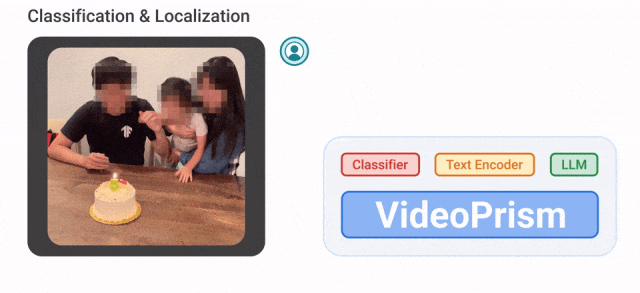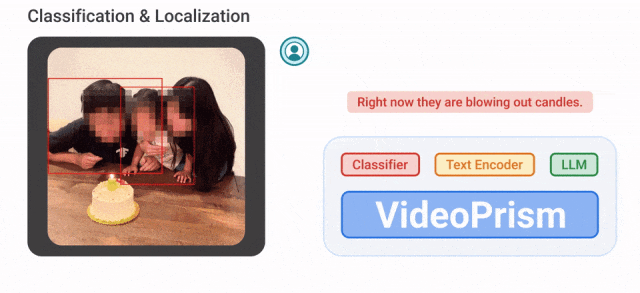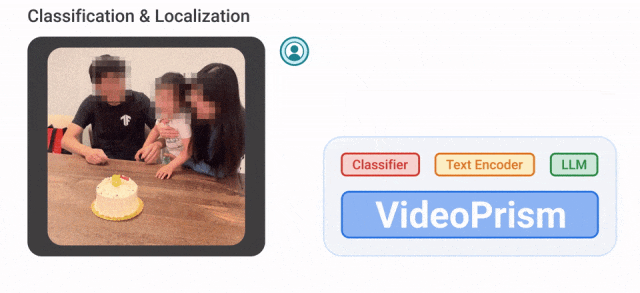
例如,VideoPrism能夠將下面影片中吹蠟燭的人分類、定位出來。
 圖片
圖片
影片-文字檢索,根據文字內容,可以檢索影片中對應的內容。
 圖片
圖片
再比如,描述下面影片-一個小女孩正在玩積木。
也可以進行QA問答。
- 她放在綠色積木塊上方積木的是什麼顏色?
- 紫。
 圖片
圖片
研究人員在一個異構語料庫對VideoPrism進行了預訓練,包含3600萬高品質視訊字幕對和5.82億個影片剪輯,並附有雜訊並行文字(如ASR轉錄文字)。
值得一提的是,VideoPrism在33項視訊理解基準測試中,刷新了30項SOTA。
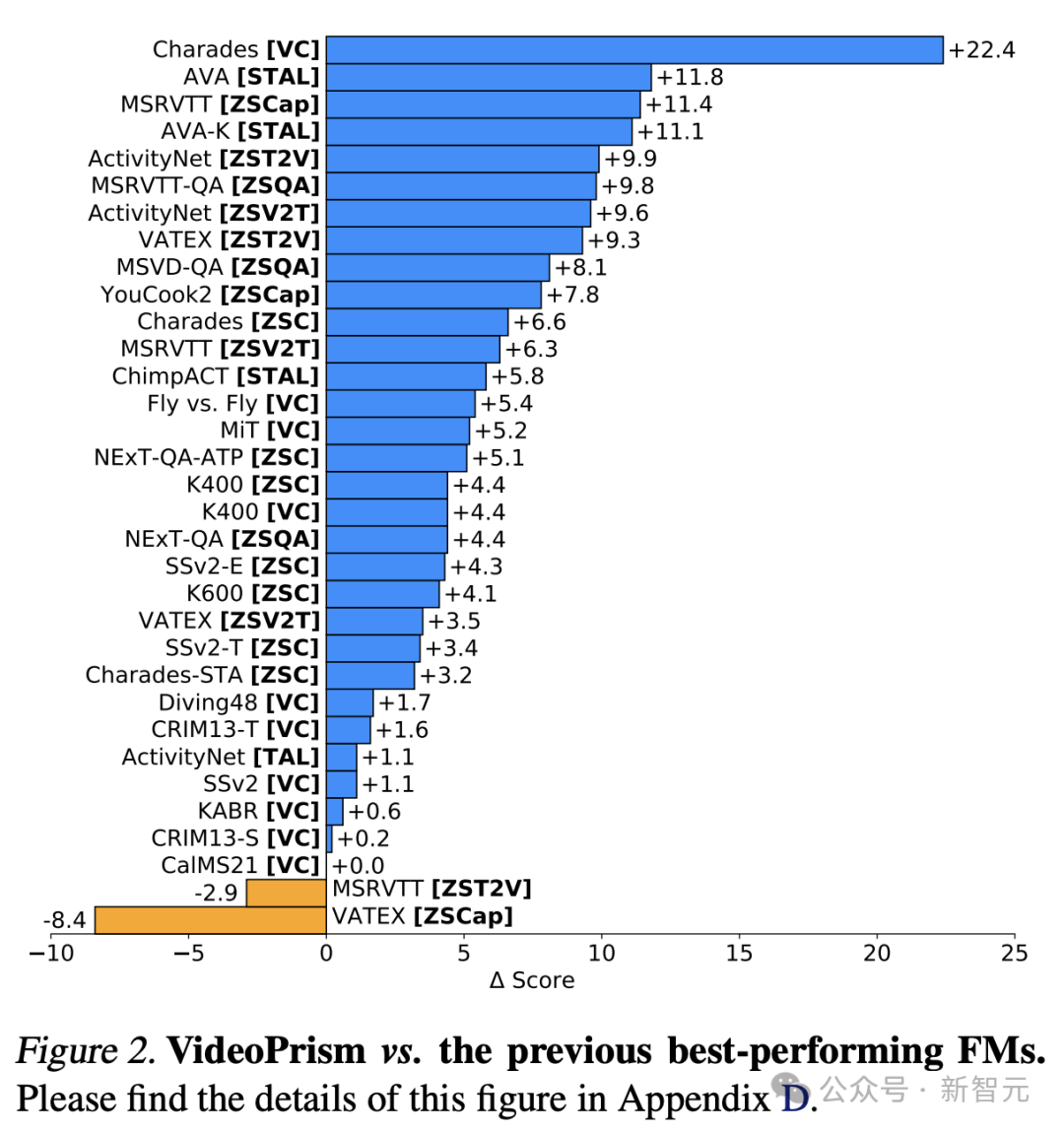 圖片
圖片
通用視覺編碼器VideoPrism
目前,視訊基礎模型(ViFM)有巨大的潛力,可以在龐大的語料庫中解鎖新的能力。
雖然先前的研究在一般視訊理解方面取得了很大進展,但建立真正的「基礎視訊模型」仍然是一個難以實現的目標。
對此,Google推出了一種通用視覺編碼器——VideoPrism,旨在解決廣泛的視訊理解任務,包括分類、在地化、檢索、字幕和問答(QA)。
VideoPrism對CV資料集,以及神經科學和生態學等科學領域的CV任務進行了廣泛評估。
透過使用單一凍結模型,以最小的適應度實現了最先進的性能。
另外,Google研究人員稱,這種凍結編碼器設定同時遵循先前研究,並考慮了其實際實用性,以及高計算和微調視訊模型的成本。
 圖片
圖片
設計架構,兩階段訓練法
VideoPrism背後的設計概念如下。
預訓練資料是基礎模型(FM)的基礎,ViFM的理想預訓練數據,是世界上所有影片的代表性樣本。
這個樣本中,大多數影片都沒有描述內容的平行文字。
然而,如果訓在這樣的文本,它就能提供有關視頻空間的無價語義線索。
因此,Google的預訓練策略應主要專注於視訊模式,同時充分利用任何可用的視訊文字對。
在資料方面,Google研究人員透過匯集3,600萬高品質視訊字幕對,以及5.82億視訊剪輯與雜訊並行文字(如ASR轉錄、產生的字幕和檢索到的文字)來近似建立所需的預訓練語料庫。
 圖片
圖片
 圖片
圖片
在建模方面,作者首先從所有不同品質的影片-文字對中對比學習語義影片嵌入。
隨後,利用廣泛的純視訊數據,對語義嵌入進行全局和標記提煉,改進了下文所述的遮罩視訊建模。
儘管在自然語言方面取得了成功,但由於原始視覺訊號缺乏語義,掩碼資料建模對於CV來說仍然具有挑戰性。
現有研究透過借用間接語意(如使用CLIP引導模型或分詞器,或隱含語意來應對這項挑戰)或隱性推廣它們(例如標記視覺patches),將高遮罩率和輕量級解碼器結合。
在上述想法的基礎上,Google團隊根據預訓練資料採用了兩階段方法。
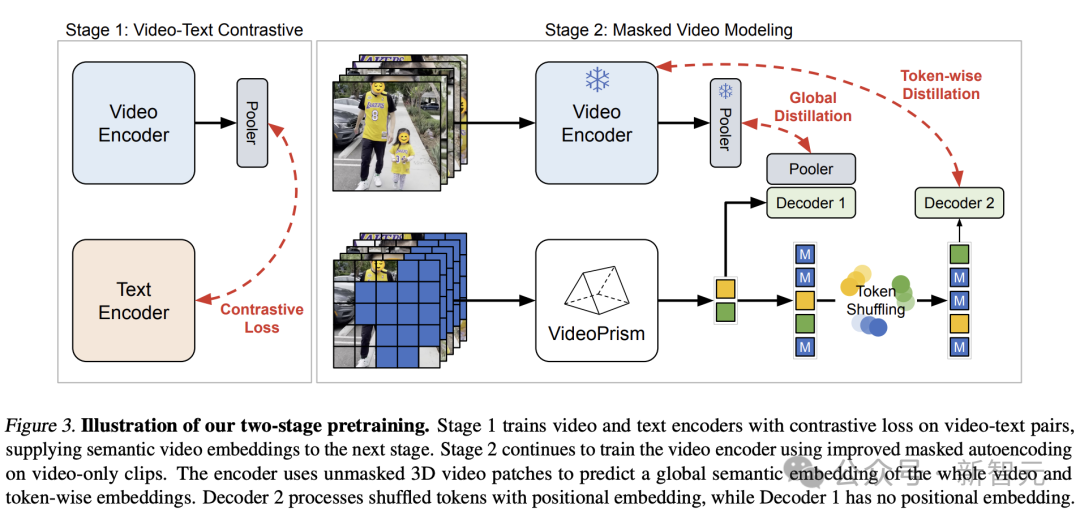 圖片
圖片
在第一階段,進行對比學習,使用所有視訊文字對,將視訊編碼器與文字編碼器對齊。
根據先前的研究,Google團隊最小化批次中所有視訊文字對的相似性得分,進行對稱交叉熵損失最小化。
並使用 CoCa 的圖像模型初始化空間編碼模組,並將WebLI納入預訓練中。
在計算損失之前,視訊編碼器的特徵會透過多頭注意力匯集池(MAP)進行聚合。
這一階段允許視訊編碼器從語言監督中學習豐富的視覺語義,由此產生的模型為第二階段訓練提供語義視訊嵌入。
 圖片
圖片
第二階段,繼續訓練編碼器,並進行了兩個改進:
- 模型需要根據未掩碼碼的輸入視訊patches,來預測第一階段的視訊級全域嵌入和token式嵌入
- 編碼器的輸出token在傳給解碼器之前,要進行隨機洗牌,以避免學習捷徑。
值得注意的是,研究人員的預訓練利用了兩個監督訊號:影片的文字描述,以及上下文自監督,使VideoPrism能夠在以外觀和動作為中心的任務上表現出色。
事實上,先前的研究表明,視訊字幕主要揭示外觀線索,而上下文我監督有助於學習動作。
 圖片
圖片
實驗結果
接下來,研究人員在廣泛的以視訊為中心的理解任務上評估VideoPrism,展現其能力和通用性。
主要分為以下四類:
(1) 一般僅視訊理解,包括分類和時空定位
(2) 零樣本視訊文字擷取
(3) 零樣本視訊字幕和品質檢查
(4) 科學領域的CV任務
分類和時空定位
表2顯示了VideoGLUE上的凍結骨幹的結果。
在所有資料集上,VideoPrism都大幅優於基準。此外,將VideoPrism的底層模型大小從ViT-B增加到ViT-g可以顯著提高效能。
值得注意的是,沒有基線方法能在所有基準測試中取得第二好的成績,這表明先前的方法可能是針對影片理解的某些方面而開發的。
而VideoPrism在這一廣泛的任務上持續改進。
這一結果表明,VideoPrism將各種視訊訊號整合到了一個編碼器中:多種粒度的語義、外觀與運動線索、時空資訊以及對不同視訊來源(如網路視訊與腳本表演)的魯棒性。
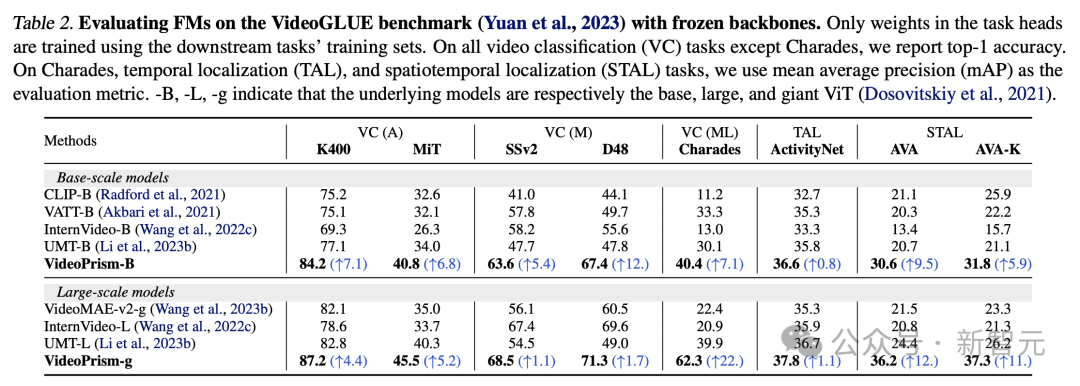 图片
图片
零样本视频文本检索和分类
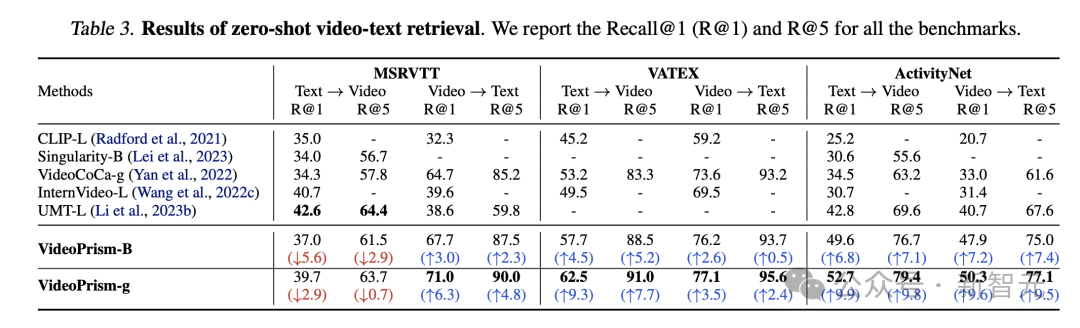
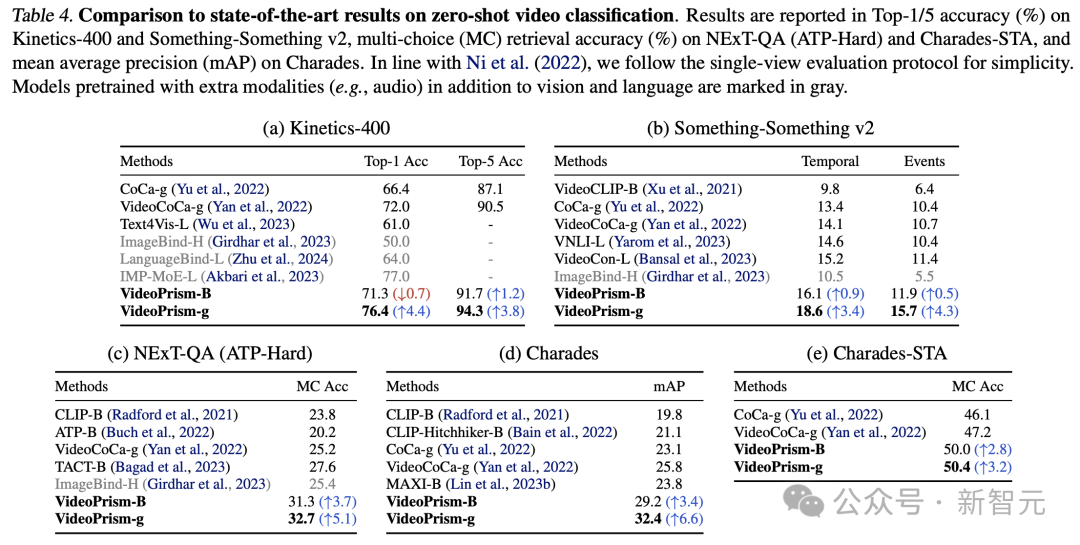
表3和表4分别总结了视频文本检索和视频分类的结果。
VideoPrism的性能刷新多项基准,而且在具有挑战性的数据集上,VideoPrism 与之前的技术相比取得了非常显著的进步。
 图片
图片
基础模型VideoPrism-B 的大多数结果,实际上优于现有的更大规模模型。
此外,VideoPrism与表4中使用域内数据和额外模态(例如音频)预训练的模型相当,甚至更好。这些在零样本检索和分类任务中的改进体现了VideoPrism强大的泛化能力。
 图片
图片
零样本视频字幕和质量检查
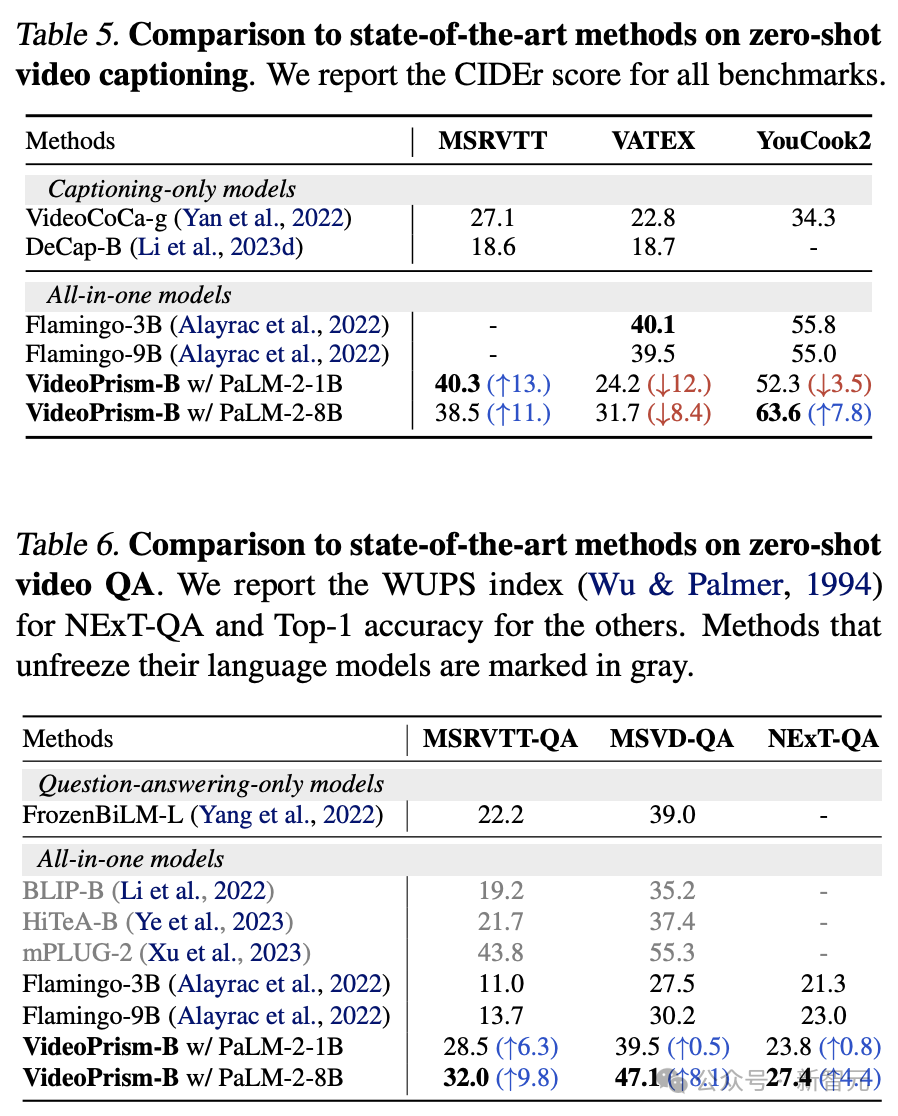
表5和表6分别显示了,零样本视频字幕和QA的结果。
尽管模型架构简单且适配器参数数量较少,但最新模型仍具有竞争力,除VATEX外,在冻结视觉和语言模型的方法中名列前茅。
结果表明,VideoPrism编码器能够很好地推广到视频到语言的生成任务。
 图片
图片
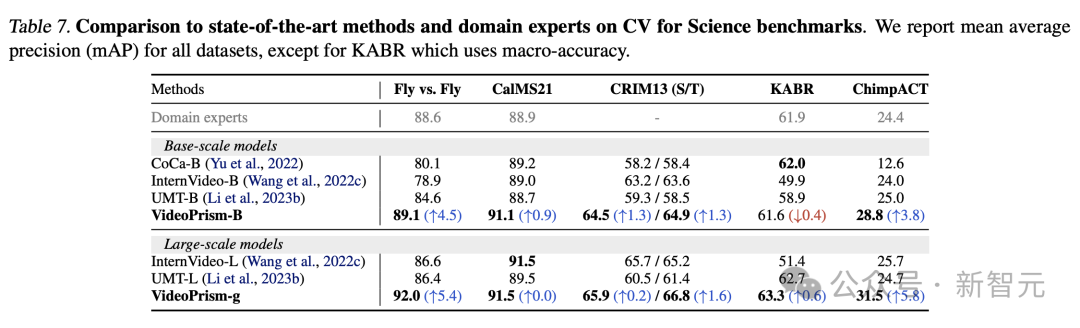
科学领域的CV任务
通用ViFM在所有评估中使用共享的冻结编码器,其性能与专门用于单个任务的特定领域模型相媲美。
尤其是,VideoPrism通常表现最好,并超越了具有基本规模模型的领域专家模型。
扩展到大规模模型可以进一步提高所有数据集的性能。这些结果表明ViFM有潜力显著加速不同领域的视频分析。
消融研究
图4显示了消融结果。值得注意的是,VideoPrism在SSv2上的持续改进表明,数据管理和模型设计工作在促进视频中的运动理解方面的有效性。
尽管对比基线已经在K400上取得了有竞争力的结果,但所提出的全局蒸馏和token洗牌进一步提高了准确性。
 图片
图片
参考资料:
https://arxiv.org/pdf/2402.13217.pdf
https://blog.research.google/2024/02/videoprism-foundational-visual-encoder.html
以上是GoogleAI影片再出王炸!全能通用視覺編碼器VideoPrism,效能刷新30項SOTA的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 給MySQL表添加和刪除字段的操作步驟
Apr 29, 2025 pm 04:15 PM
給MySQL表添加和刪除字段的操作步驟
Apr 29, 2025 pm 04:15 PM
在MySQL中,添加字段使用ALTERTABLEtable_nameADDCOLUMNnew_columnVARCHAR(255)AFTERexisting_column,刪除字段使用ALTERTABLEtable_nameDROPCOLUMNcolumn_to_drop。添加字段時,需指定位置以優化查詢性能和數據結構;刪除字段前需確認操作不可逆;使用在線DDL、備份數據、測試環境和低負載時間段修改表結構是性能優化和最佳實踐。
 量化交易所排行榜2025 數字貨幣量化交易APP前十名推薦
Apr 30, 2025 pm 07:24 PM
量化交易所排行榜2025 數字貨幣量化交易APP前十名推薦
Apr 30, 2025 pm 07:24 PM
交易所內置量化工具包括:1. Binance(幣安):提供Binance Futures量化模塊,低手續費,支持AI輔助交易。 2. OKX(歐易):支持多賬戶管理和智能訂單路由,提供機構級風控。獨立量化策略平台有:3. 3Commas:拖拽式策略生成器,適用於多平台對沖套利。 4. Quadency:專業級算法策略庫,支持自定義風險閾值。 5. Pionex:內置16 預設策略,低交易手續費。垂直領域工具包括:6. Cryptohopper:雲端量化平台,支持150 技術指標。 7. Bitsgap:
 MySQL批量插入數據的高效方法
Apr 29, 2025 pm 04:18 PM
MySQL批量插入數據的高效方法
Apr 29, 2025 pm 04:18 PM
MySQL批量插入数据的高效方法包括:1.使用INSERTINTO...VALUES语法,2.利用LOADDATAINFILE命令,3.使用事务处理,4.调整批量大小,5.禁用索引,6.使用INSERTIGNORE或INSERT...ONDUPLICATEKEYUPDATE,这些方法能显著提升数据库操作效率。
 deepseek官網是如何實現鼠標滾動事件穿透效果的?
Apr 30, 2025 pm 03:21 PM
deepseek官網是如何實現鼠標滾動事件穿透效果的?
Apr 30, 2025 pm 03:21 PM
如何實現鼠標滾動事件穿透效果?在我們瀏覽網頁時,經常會遇到一些特別的交互設計。比如在deepseek官網上,�...
 如何使用MySQL的函數進行數據處理和計算
Apr 29, 2025 pm 04:21 PM
如何使用MySQL的函數進行數據處理和計算
Apr 29, 2025 pm 04:21 PM
MySQL函數可用於數據處理和計算。 1.基本用法包括字符串處理、日期計算和數學運算。 2.高級用法涉及結合多個函數實現複雜操作。 3.性能優化需避免在WHERE子句中使用函數,並使用GROUPBY和臨時表。
 數字虛擬幣交易平台top10 安全可靠的十大數字貨幣交易所
Apr 30, 2025 pm 04:30 PM
數字虛擬幣交易平台top10 安全可靠的十大數字貨幣交易所
Apr 30, 2025 pm 04:30 PM
數字虛擬幣交易平台top10分別是:1. Binance,2. OKX,3. Coinbase,4. Kraken,5. Huobi Global,6. Bitfinex,7. KuCoin,8. Gemini,9. Bitstamp,10. Bittrex,這些平台均提供高安全性和多種交易選項,適用於不同用戶需求。
 輕鬆協議(Easeprotocol.com)將ISO 20022消息標准直接實現為區塊鏈智能合約
Apr 30, 2025 pm 05:06 PM
輕鬆協議(Easeprotocol.com)將ISO 20022消息標准直接實現為區塊鏈智能合約
Apr 30, 2025 pm 05:06 PM
這種開創性的開發將使金融機構能夠利用全球認可的ISO20022標準來自動化不同區塊鏈生態系統的銀行業務流程。 Ease協議是一個企業級區塊鏈平台,旨在通過易用的方式促進廣泛採用,今日宣布已成功集成ISO20022消息傳遞標準,直接將其納入區塊鏈智能合約。這一開發將使金融機構能夠使用全球認可的ISO20022標準,輕鬆自動化不同區塊鏈生態系統的銀行業務流程,該標準正在取代Swift消息傳遞系統。這些功能將很快在“EaseTestnet”上進行試用。 EaseProtocolArchitectDou
 如何分析MySQL查詢的執行計劃
Apr 29, 2025 pm 04:12 PM
如何分析MySQL查詢的執行計劃
Apr 29, 2025 pm 04:12 PM
使用EXPLAIN命令可以分析MySQL查詢的執行計劃。 1.EXPLAIN命令顯示查詢的執行計劃,幫助找出性能瓶頸。 2.執行計劃包括id、select_type、table、type、possible_keys、key、key_len、ref、rows和Extra等字段。 3.根據執行計劃,可以通過添加索引、避免全表掃描、優化JOIN操作和使用覆蓋索引來優化查詢。
