
擴散模型,迎來了一個重大新應用程式-
像Sora生成影片一樣,給神經網路產生參數,直接打入了AI的底層!
這是新加坡國立大學尤洋教授團隊聯合UCB、Meta AI實驗室等機構最新開源的研究成果。

具體來說,研究團隊提出了一種用於產生神經網路參數的擴散模型p(arameter)-diff。
用它來產生網路參數,速度比直接訓練最多提高44倍,而且表現毫不遜色。
該模型一經發布後,在AI社區迅速引起了激烈的討論,圈內專家對其表現出了與普通人看到Sora時一樣的驚嘆態度。
甚至有人直接驚呼,這基本上相當於AI在創造新的AI了。

就連AI巨頭LeCun看了之後,也點讚了這一成果,表示這真的是個cute idea。
而實質上,p-diff也確實具有和Sora一樣重大的意義,對此同實驗室的Fuzhao Xue(薛復昭)博士進行了詳細解釋:
Sora產生高維度數據,即視頻,這使得Sora成為世界模擬器(從一個維度接近AGI)。
而這項工作,神經網路擴散,可以產生模型中的參數,具有成為元世界級學習器/優化器的潛力,從另一個新的重要維度向AGI邁進。

言歸正傳,p-diff到底是如何產生神經網路參數的呢?
要弄清楚這個問題,首先要了解擴散模型和神經網路各自的工作特性。
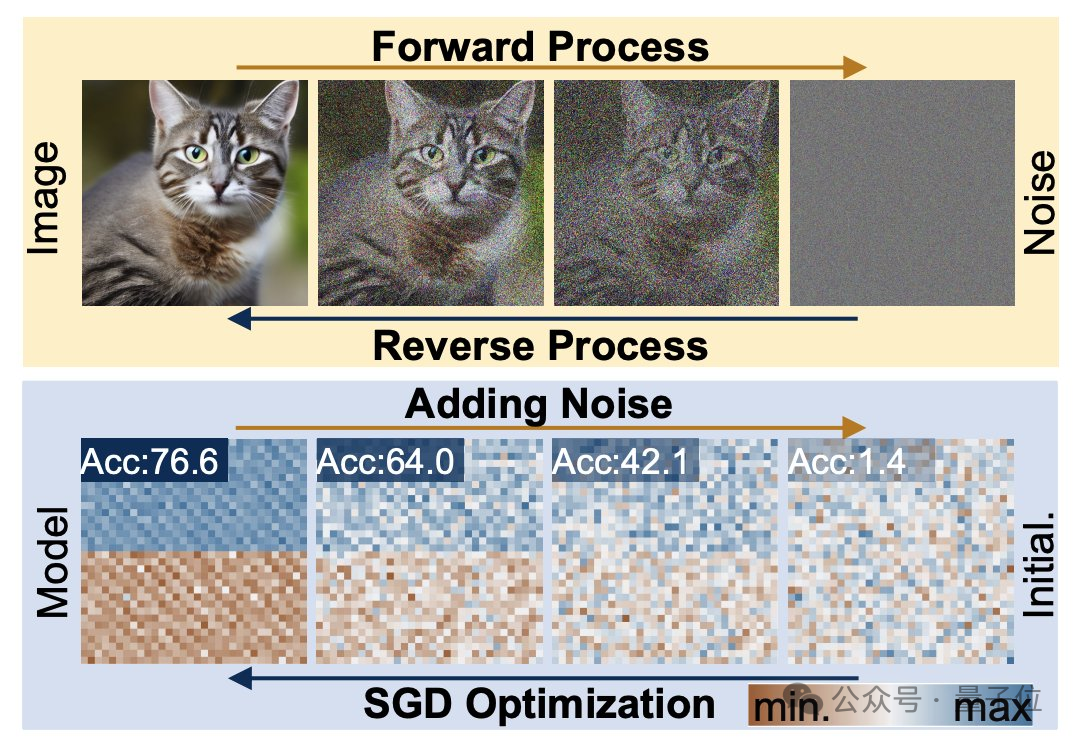
擴散生成過程,是從隨機分佈到高度特定分佈的轉變,透過複合雜訊添加,將視覺資訊降級為簡單雜訊分佈。
而神經網路訓練,同樣遵循這樣的轉變過程,也同樣可以透過添加雜訊的方式來降級,研究人員正是在這一特點的啟發之下提出p-diff方法的。
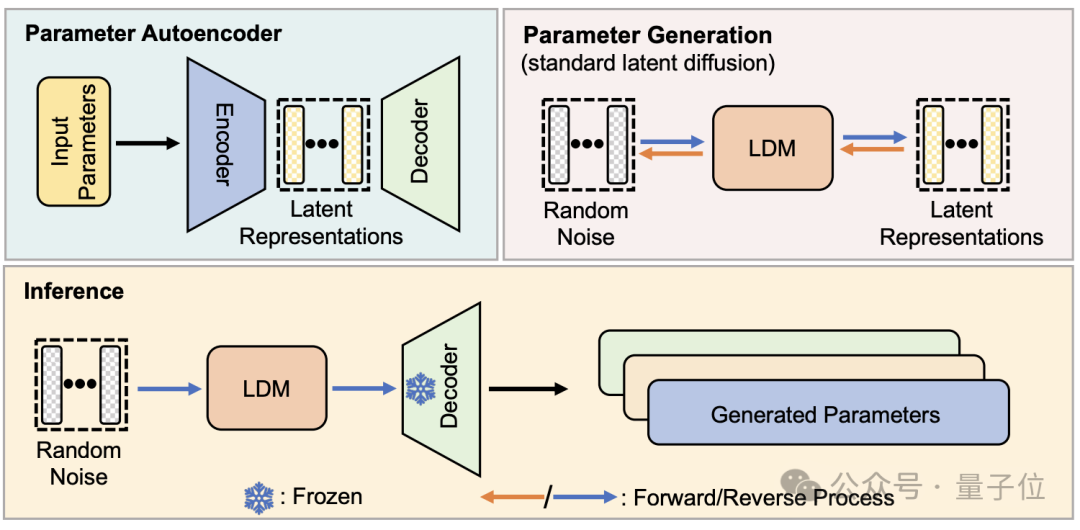
從結構上看,p-diff是研究團隊在標準潛擴散模型的基礎之上,結合自編碼器設計的。
研究者首先從訓練完成、表現較好的網路參數中選取一部分,並展開為一維向量形式。
然後用自編碼器從一維向量中提取潛在表示,作為擴散模型的訓練數據,這樣做可以捕捉到原有參數的關鍵特徵。
訓練過程中,研究人員讓p-diff透過正向和反向過程來學習參數的分佈,完成後,擴散模型像產生視覺訊息的過程一樣,從隨機噪音中合成這些潛在表示。
最後,新產生的潛在表示再被與編碼器對應的解碼器還原成網路參數,並用於建構新模型。
下圖是透過p-diff、使用3個隨機種子從頭開始訓練的ResNet-18模型的參數分佈,展示了不同層之間以及同一層不同參數之間的分佈模式。

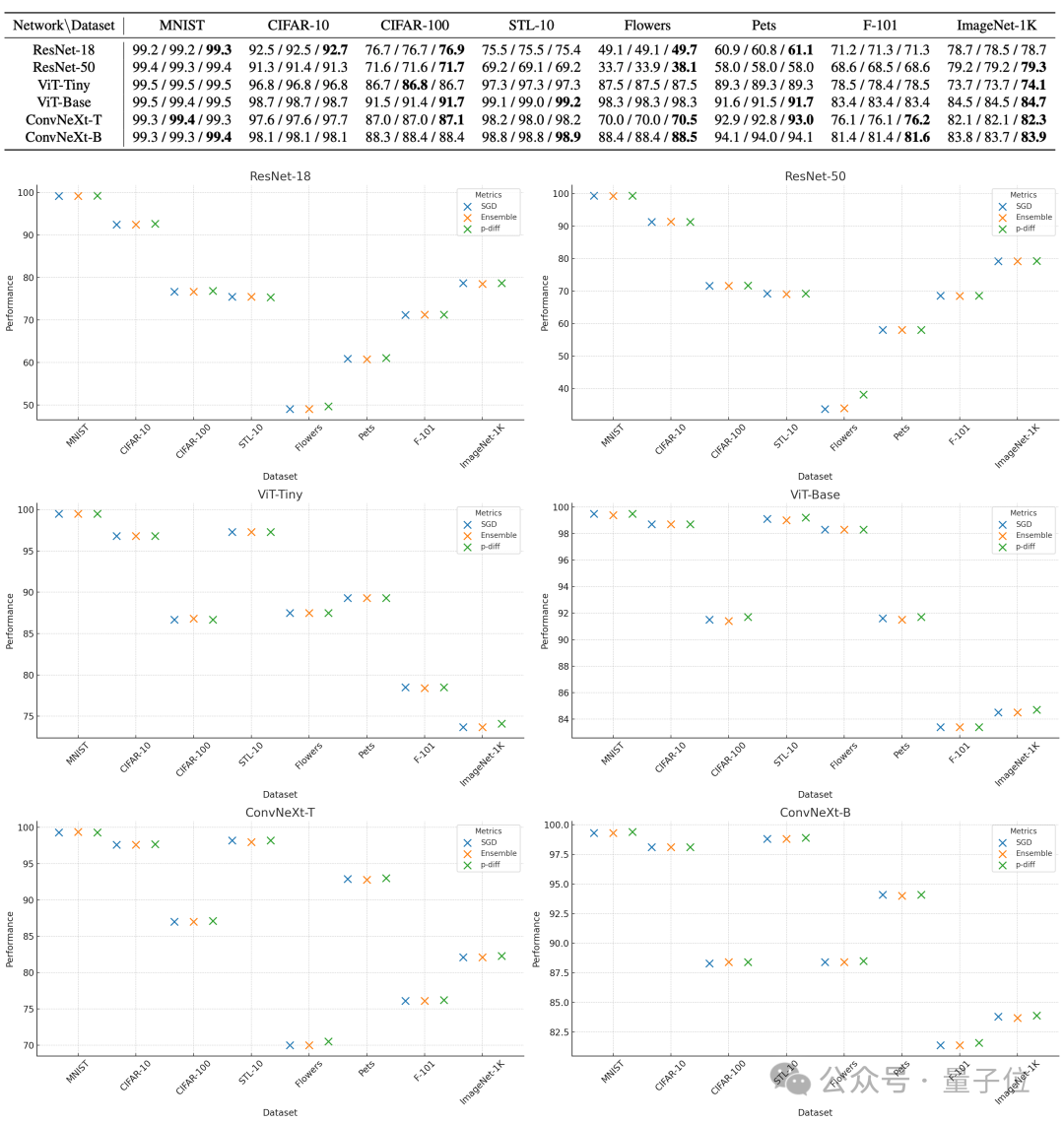
為了評估p-diff所產生參數的質量,研究人員利用3種類型、每種兩個規模的神經網絡,在8個資料集上對其進行了測試。
下表中,每組的三個數字依序表示原始模型、整合模型和p-diff產生的模型的評估成績。
結果可以看到,用p-diff產生的模型表現基本上都接近甚至超過了人工訓練的原始模型。
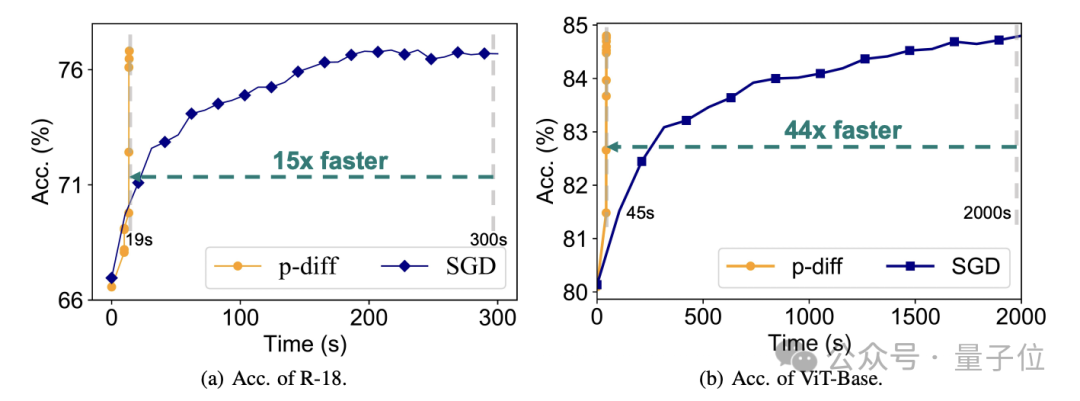
效率上,在不损失准确度的情况下,p-diff生成ResNet-18网络的速度是传统训练的15倍,生成Vit-Base的速度更是达到了44倍。
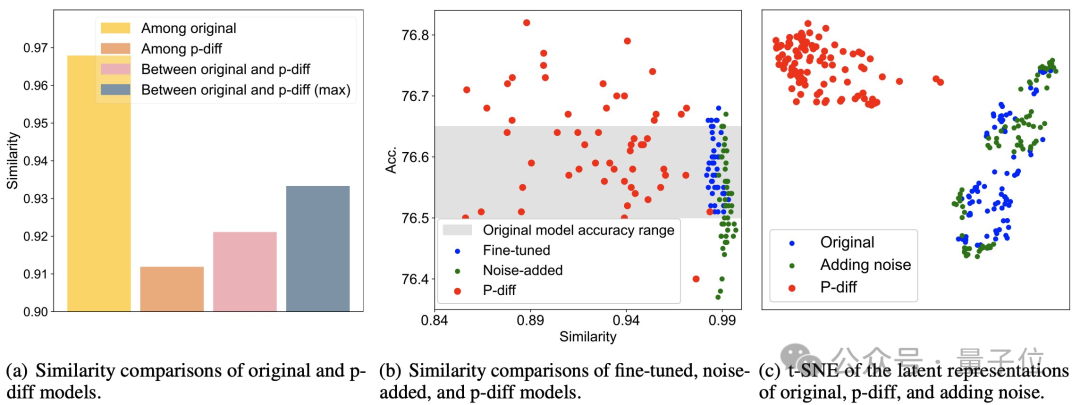
额外的测试结果证明,p-diff生成的模型与训练数据有显著差异。
从下图(a)可以看到,p-diff生成的模型之间的相似度低于各原始模型之间的相似度,以及p-diff与原始模型的相似度。
而从(b)和(c)中可知,与微调、噪声添加方式相比,p-diff的相似度同样更低。
这些结果说明,p-diff是真正生成了新的模型,而非仅仅记忆训练样本,同时也表明其具有良好的泛化能力,能够生成与训练数据不同的新模型。
目前,p-diff的代码已经开源,感兴趣的话可以到GitHub中查看。
论文地址:https://arxiv.org/abs/2402.13144
GitHub:https://github.com/NUS-HPC-AI-Lab/Neural-Network-Diffusion
以上是打入AI底層! NUS尤洋團隊以擴散模型建構神經網路參數,LeCun按讚的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















