

自動駕駛與軌跡預測看這篇就夠了!

軌跡預測在自動駕駛中承擔著重要的角色,自動駕駛軌跡預測是指透過分析車輛行駛過程中的各種數據,預測車輛未來的行駛軌跡。作為自動駕駛的核心模組,軌跡預測的品質對於下游的規劃控制至關重要。軌跡預測任務技術堆疊豐富,需熟悉自動駕駛動/靜態感知、高精地圖、車道線、神經網路架構(CNN&GNN&Transformer)技能等,入門難度很高!許多粉絲期望能夠盡快上手軌跡預測,少踩坑,今天就為大家盤點下軌跡預測常見的一些問題和入門學習方法!
入門相關知識
1.預習的論文有沒有切入順序?
A:先看survey,problem formulation, deep learning-based methods裡的sequential network,graph neural network和Evaluation。
2.行為預測是軌跡預測嗎
耦合和行為並不相同,耦合通常指目標車可能採取的動作,例如變換車道、停車、超車、加速、左轉、右轉或直行。而軌跡則指具有時間資訊的具體未來位置點。
3.請問Argoverse資料集裡提到的資料組成中,labels and targets指的是什麼呢? labels是指要預測時間段內的ground truth嗎
在右邊的表格中,OBJECT_TYPE欄通常代表自動駕駛車輛本身。資料集通常為每個場景指定一個或多個待預測的障礙物,並將這些待預測目標稱為target或focal agent。有些資料集也會為每個障礙物提供語義標籤,例如車輛、行人或自行車等。
Q2:車輛和行人的資料形式是一樣的嗎?我的意思是說,例如一個點雲點代表行人,幾十點代表車輛?
A:這種軌跡資料集裡面其實給的都是物體中心點的xyz座標,行人和車輛都是
Q3:argo1和argo2的資料集都是只指定了一個被預測的障礙物吧?那在做multi-agent prediction的時候 這兩個資料集是怎麼用的
argo1只指定了一個障礙物,而argo2卻可能指定了多達二十個。然而,即使只指定了一個障礙物,這並不會影響您模型的能力來預測多個障礙物。
4.路徑規劃一般考慮低速與靜態障礙物 軌跡預測結合的功能是? ?關鍵snapshot?
A:」預測「自車軌跡當成自車規劃軌跡,可以參考uniad
5.軌跡預測對於車輛動力學模型的要求高嗎?就是需要數學和汽車理論等來建立一個精準的車輛動力學模型麼?
A:nn網路基本上不需要哈,rule based的需要懂一些
6. 模糊的新手小白,應該從哪裡在著手拓寬一下知識面(還不會代碼撰寫)
A:先看綜述,把心智圖整理出來,例如《Machine Learning for Autonomous Vehicle's Trajectory Prediction: A comprehensive survey, Challenges, and Future Research Directions》這篇綜述去看看英文原文
7.預測與決策啥關係捏,為啥我覺得好像預測沒那麼重要?
A1(stu): 默认预测属于感知吧,或者决策中隐含预测,反正没有预测不行。A2(stu): 决策该规控做,有行为规划,高级一点的就是做交互和博弈,有的公司会有单独的交互博弈组
8.目前頭公司,一般預測是屬於感知大模組還是規控大模組?
A:預測是出他車軌跡,規控是出自車軌跡,這兩個軌跡還互相影響,所以預測一般放規控。
Q: 一些公開的資料,例如小鵬的感知xnet會同時出預測軌跡,這時候又感覺預測的工作是放在感知大模組下,還是說兩個模組都有自己的預測模組,目標不一樣?
A:是會互相影響,所以有的地方預測和決策就是一組。例如自車規劃的軌跡意圖去擠別的車,他車一般狀況是會讓道的。所以有些工作會把自車的規劃當成他車模型輸入的一部分。可以參考下M2I(M2I: From Factored Marginal Trajectory Prediction to Interactive Prediction). 這篇思路差不多,可以了解 PiP: Planning-informed Trajectory Prediction for Autonomous Driving
#9.argoverse的這種車道中線地圖,在路口裡面沒有車道線的地方是怎麼得到的呀?
A: 人工標註的
10.用軌跡預測寫論文的話,哪篇論文的程式碼可以做baseline?
A: hivt可以做baseline,蠻多人用的
11.現在軌跡預測基本上都依賴地圖,如果換一個新的地圖環境,原模型是否就不適用了,要重新訓練嗎?
A: 有一定的泛化能力,不需要重新訓練效果也還行
12.對多模態輸出而言,選擇最佳軌跡的時候是根據機率值最大的選嗎
A(stu): 选择结果最好的Q2:结果最好是根据什么来判定呢?是根据概率值大小还是根据和gt的距离A: 实际在没有ground truth的情况下,你要取“最好”的轨迹,那只能选择相信预测概率值最大的那条轨迹了Q3: 那有gt的情况下,选择最好轨迹的时候,根据和gt之间的end point或者average都可以是吗A: 嗯嗯,看指标咋定义
軌跡預測基礎模組
1.Argoverse資料集裡HD-Map怎麼用,能結合motion forecast作為輸入,建立駕駛場景圖嗎,異構圖又怎麼理解?
A:這個課程裡都有講的,可以參考第二章,後續的第四章也會講. 異構圖和同構圖的區別:同構圖中,node的種類只有一種,一個node和另一個node的連結關係只有一種,例如在社交網絡中,可以想像node只有'人'這一個種類,edge只有'認識'這一種連結。而人和人要嘛認識,要嘛不認識。但也可能細分有人,按讚,推文。則人和人可能透過認識連接,人和推文可能透過按讚連接,人和人也可能透過按讚同一篇推文連接(meta path)。這裡節點、節點之間關係的多樣性表現就需要引入異構圖了。異構圖中,有很多種node。 node之間也有很多種連結關係(edge),這些連結關係的組合則種類更多(meta-path), 而這些node之間的關係有輕重之分,不同連結關係也有輕重之分。
2.A-A互動考慮的是哪些車輛與被預測車輛的互動呢?
A:可以選擇一定半徑範圍內的車,也可以考慮K近鄰的車,你甚至可以自己提出更高級的啟發式鄰居篩選策略,甚至有可能可以讓模型自己學出來兩輛車是否是鄰居
Q2:還是考慮一定範圍內的吧,那半徑大小有什麼選取的原則嗎?另外,選取的這些車輛是在哪個時間步下的呢
A:半徑的選擇很難有標準答案,這本質上就是在問模型做預測的時候到底需要多遠程的信息,有點像在選擇卷積核的大小對於第二個問題,我個人的準則是,想要建模哪個時刻下物體之間的交互,就根據哪個時刻下的物體相對位置來選取鄰居
Q3:這樣的話對於歷史時域都要建模嗎?不同時間步下在一定範圍內的周邊車輛也會變化吧,還是說只考慮在當前時刻的周邊車輛資訊
A:都行啊,看你模型怎麼設計
3.老師uniad端對端模型中預測部分有何缺陷啊?
A:只看它motion former的操作比較常規,你在很多論文裡都會看到類似的SA和CA。現在sota的模型很多都比較重,例如decoder會有循環的refine
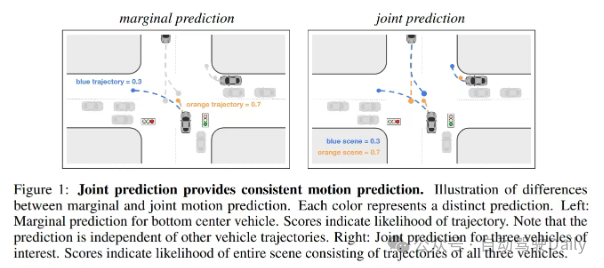
A2:做的是marginal prediction不是joint prediction;2. prediction和planning是分開來做的,沒有明確考慮ego和周圍agent的互動博弈;3.用的是scene-centric representation,沒有考慮對稱性,效果必拉
Q2:啥是marginal prediction啊
#A:具體可以參考scene transformer
Q3:關於第三點,scene centric沒有考慮對稱性,怎麼理解呢
#A:建議看HiVT, QCNet, MTR .當然對於端到端模型來說對稱性的設計也不好做就是了
A2:可以理解成輸入的是scene的數據,但在網路裡會建模成以每個目標為中心視角去看它週邊的scene,這樣你就在forward裡得到了每個目標以它自己為中心的編碼,後續可以再考慮這些編碼間的交互
4. 什麼是以agent為中心?
A:每個agent有自己的local region,local region是以這個agent為中心
5.軌跡預測裡yaw和heading是混用的嗎
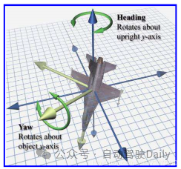
A:可以理解為車頭朝向
6.argoverse地圖中的has_traffic_control這個屬性具體代表什麼意思?
A:其實我也不知道我理解的對不對,我猜是指某個lane是否被紅綠燈/stop sign/限速標誌等所影響
7.請問Laplace loss和huber loss 對於軌跡預測所存在的優劣勢在哪裡呢?如果我只預測一條車道線的話
A:兩個都試一下,哪個效果好哪個就有優勢。 Laplace loss要效果好還是有些細節要注意的
Q2:是指參數要調的好嗎
A:Laplace loss相比L1 loss其實就是多預測了一個scale參數
Q3:對的但似乎這個我不知道有啥用如果只預測一個軌跡的話。感覺像是多餘的。我把它理解為不確定性 不知道是否正確
A:如果你从零推导过最小二乘法就会知道,MSE其实是假设了方差为常数的高斯分布的NLL。同理,L1 loss也是假设了方差为常数的Laplace分布的NLL。所以说LaplaceNLL也可以理解为方差非定值的L1 loss。这个方差是模型自己预测出来的。为了使loss更低,模型会给那些拟合得不太好的样本一个比较大的方差,而给拟合得好的样本比较小的方差
Q4:那是不是可以理解为对于非常随机的数据集【轨迹数据存在缺帧 抖动】 就不太适合Laplace 因为模型需要去拟合这个方差?需要数据集质量比较高
A:这个说法我觉得不一定成立。从效果上来看,会鼓励模型优先学习比较容易拟合的样本,再去学习难学习的样本
Q5:还想请问下这句话(Laplace loss要效果好还是有些细节要注意的)如何理解 A:主要是预测scale那里。在模型上,预测location的分支和预测scale的分支要尽量解耦,不要让他们相互干扰。预测scale的分支要保证输出结果>0,一般人会用exp作为激活函数保证非负,但是我发现用ELU +1会更好。然后其实scale的下界最好不要是0,最好让scale>0.01或者>0.1啥的。以上都是个人看法。其实我开源的代码(周梓康大佬的github开源代码)里都有这些细节,不过可能大家不一定注意到。
给出链接:https://github.com/ZikangZhou/QCNet
https://github.com/ZikangZhou/HiVT
8. 有拿VAE做轨迹预测的吗,给个链接!
https://github.com/L1aoXingyu/pytorch-beginner/tree/master/08-AutoEncoder
9. 请问大伙一个问题,就是Polyline到底是啥?另外说polyline由向量Vector组成,这些Vector是相当于节点吗?
A:Polyline就是折线,折线就是一段一段的,每一段都可以看成是一段向量Q2:请问这个折线段和图神经网络的节点之间的边有关系吗?或者说Polyline这个折现向量相当于是图神经网络当中的节点还是边呀?A:一根折线可以理解为一个节点。轨迹预测里面没有明确定义的边,边如何定义取决于你怎么理解这个问题。Q3: VectorNet里面有很多个子图,每个子图下面有很多个Polyline,把Polyline当做向量的话,就相当于把Polyline这个节点变成了向量,相当于将节点进行特征向量化对吗?然后Polyline里面有多个Vector向量,就是相当于是构成这个节点的特征矩阵么?A: 一个地图里有很多条polyline;一个Polyline就是一个子图;一个polyline由很多段比较短的向量组成,每一段向量都是子图上的一个节点
10. 有的论文,像multipath++对于地图两个点就作为一个单元,有的像vectornet是一条线作为一个单元,这两种有什么区别吗?
A: 节点的粒度不同,要说效果的话那得看具体实现;速度的话,显然粒度越粗效率越高Q2:从效果角度看,什么时候选用哪种有没有什么原则?A: 没有原则,都可以尝试
11.有什麼可以判斷score的平滑性嗎? 如果一定要做的話
A: 這個需要你輸入是流動的輸入例如0-19和1-20幀接著比較兩幀之間的對應軌跡的score的差的平方,統計下就可以了
Q2: Thomas老師有哪些指標推薦呢,我目前用一階導數和二階導數。但好像不是很明顯,絕大多數一階導和二階導都集中在0附近。
A: 我感覺連續影格的對應軌跡的score的差值平方就可以了呀,例如你有連續n個輸入,求和再除以n。但是scene是即時變化的,發生互動或從非路口到路口的時候score就應該是突變的
12.hivt裡的軌跡沒有進行縮放嗎,就比如×0.01 10這種。分佈盡量在0附近。我看有的方法就用了,有的方法就沒有。取捨該如何界定?
A:就是把資料標準化歸一化唄。可能有點用 但應該不多
13.HiVT裡地圖的類別屬性經過embedding之後為什麼和數值屬性是相加的,而不是concat?
A:相加和concat區別不大,而對於類別embedding和數值embedding融合來說,實際上完全等價
Q2: 完全等價應該怎麼理解?
A: 兩者Concat之後再過一層線性層,實際上等價於把數值embedding過一層線性層以及把類別embedding過一層線性層後,兩者再相加起來.把類別embedding過一層線性層其實沒啥意義,理論上這一層線性層可以跟nn.Embeddding裡面的參數融合起來
14.作為用戶可能更關心的是,HiVT如果要實際部署的話,最小的硬體需求是多少?
A:我不知道,但根據我了解到的信息,不知道是NV還是哪家車廠是拿HiVT來預測行人的,所以實際部署肯定是可行的
15. 基於occupancy network的預測有什麼特別嗎?有沒有論文推薦?
A:目前基於occupancy的未來預測的方案裡面最有前途的應該是這個:https://arxiv.org/abs/2308.01471
#16.考慮規劃軌跡的預測有什麼論文推薦嗎?就是預測其他障礙物的時候,考慮自車的規劃軌跡?
A:這個可能公開的資料集比較困難,一般不會提供自車的規劃軌跡。上古時期有一篇叫做PiP的,港科Haoran Song。我感覺那種做conditional prediction的文章都可以算是你想要的,例如M2I
#17.有沒有適合預測演算法進行效能測試的模擬專案可以學習參考的呢
A(stu):這篇論文有討論:Choose Your Simulator Wisely A Review on Open-source Simulators for Autonomous Driving
18.請問如何估計GPU顯存需要多大,如果使用Argoverse資料集的話,怎麼算
A:和怎麼用有關係,之前跑hivt我1070都可以,現在一般電腦應該都可以
原文連結:https:/ /mp.weixin.qq.com/s/EEkr8g4w0s2zhS_jmczUiA
以上是自動駕駛與軌跡預測看這篇就夠了!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 微信刪除的人如何找回(簡單教學告訴你如何恢復被刪除的聯絡人)
May 01, 2024 pm 12:01 PM
微信刪除的人如何找回(簡單教學告訴你如何恢復被刪除的聯絡人)
May 01, 2024 pm 12:01 PM
而後悔莫及、人們常常會因為一些原因不小心刪除某些聯絡人、微信作為一款廣泛使用的社群軟體。幫助用戶解決這個問題,本文將介紹如何透過簡單的方法找回被刪除的聯絡人。 1.了解微信聯絡人刪除機制這為我們找回被刪除的聯絡人提供了可能性、微信中的聯絡人刪除機制是將其從通訊錄中移除,但並未完全刪除。 2.使用微信內建「通訊錄恢復」功能微信提供了「通訊錄恢復」節省時間和精力,使用者可以透過此功能快速找回先前刪除的聯絡人,功能。 3.進入微信設定頁面點選右下角,開啟微信應用程式「我」再點選右上角設定圖示、進入設定頁面,,
 自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
昨天面試被問到了是否做過長尾相關的問題,所以就想著簡單總結一下。自動駕駛長尾問題是指自動駕駛汽車中的邊緣情況,即發生機率較低的可能場景。感知的長尾問題是目前限制單車智慧自動駕駛車輛運行設計域的主要原因之一。自動駕駛的底層架構和大部分技術問題已經解決,剩下的5%的長尾問題,逐漸成了限制自動駕駛發展的關鍵。這些問題包括各種零碎的場景、極端的情況和無法預測的人類行為。自動駕駛中的邊緣場景"長尾"是指自動駕駛汽車(AV)中的邊緣情況,邊緣情況是發生機率較低的可能場景。這些罕見的事件
 nuScenes最新SOTA | SparseAD:稀疏查詢協助高效端對端自動駕駛!
Apr 17, 2024 pm 06:22 PM
nuScenes最新SOTA | SparseAD:稀疏查詢協助高效端對端自動駕駛!
Apr 17, 2024 pm 06:22 PM
寫在前面&出發點端到端的範式使用統一的框架在自動駕駛系統中實現多任務。儘管這種範式具有簡單性和清晰性,但端到端的自動駕駛方法在子任務上的表現仍然遠遠落後於單任務方法。同時,先前端到端方法中廣泛使用的密集鳥瞰圖(BEV)特徵使得擴展到更多模態或任務變得困難。這裡提出了一種稀疏查找為中心的端到端自動駕駛範式(SparseAD),其中稀疏查找完全代表整個駕駛場景,包括空間、時間和任務,無需任何密集的BEV表示。具體來說,設計了一個統一的稀疏架構,用於包括檢測、追蹤和線上地圖繪製在內的任務感知。此外,重
 聊聊端到端與下一代自動駕駛系統,以及端到端自動駕駛的一些迷思?
Apr 15, 2024 pm 04:13 PM
聊聊端到端與下一代自動駕駛系統,以及端到端自動駕駛的一些迷思?
Apr 15, 2024 pm 04:13 PM
最近一個月由於眾所周知的一些原因,非常密集地和業界的各種老師同學進行了交流。交流中必不可免的一個話題自然是端到端與火辣的特斯拉FSDV12。想藉此機會,整理當下這個時刻的一些想法和觀點,供大家參考和討論。如何定義端到端的自動駕駛系統,應該期望端到端解決什麼問題?依照最傳統的定義,端到端的系統指的是一套系統,輸入感測器的原始訊息,直接輸出任務關心的變數。例如,在影像辨識中,CNN相對於傳統的特徵提取器+分類器的方法就可以稱之為端到端。在自動駕駛任務中,輸入各種感測器的資料(相機/LiDAR
 FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
目標偵測在自動駕駛系統當中是一個比較成熟的問題,其中行人偵測是最早得以部署演算法之一。在多數論文當中已經進行了非常全面的研究。然而,利用魚眼相機進行環視的距離感知相對來說研究較少。由於徑向畸變大,標準的邊界框表示在魚眼相機當中很難實施。為了緩解上述描述,我們探索了擴展邊界框、橢圓、通用多邊形設計為極座標/角度表示,並定義一個實例分割mIOU度量來分析這些表示。所提出的具有多邊形形狀的模型fisheyeDetNet優於其他模型,並同時在用於自動駕駛的Valeo魚眼相機資料集上實現了49.5%的mAP
 自動駕駛第一性之純視覺靜態重建
Jun 02, 2024 pm 03:24 PM
自動駕駛第一性之純視覺靜態重建
Jun 02, 2024 pm 03:24 PM
純視覺的標註方案,主要利用視覺加上一些GPS、IMU和輪速感測器的資料進行動態標註。當然面向量產場景的話,不一定要純視覺,有些量產的車輛裡面,會有像固態雷達(AT128)這樣的感測器。如果從量產的角度做資料閉環,把這些感測器都用上,可以有效解決動態物體的標註問題。但是我們的方案裡面,是沒有固態雷達的。所以,我們就介紹這個最通用的量產標註方案。純視覺的標註方案的核心在於高精度的pose重建。我們採用StructurefromMotion(SFM)的pose重建方案,來確保重建精確度。但是傳
 2024年5月值得關注的六個空投項目盤點
May 05, 2024 am 09:04 AM
2024年5月值得關注的六個空投項目盤點
May 05, 2024 am 09:04 AM
2024.5還有哪些空投項目值得大家關注呢?六個值得關注的空投項目盤點!五月有幾個空投追逐者正在轉向其他目標——沒有原生代幣的DeFi協議。當用戶為空投做好準備時,這種期望往往會導致流動性湧入平台。儘管當前市場放緩阻礙了今年稍早加密代幣的價格上漲,但以下是一些吸引希望的項目。今天本站小編給大家詳細介紹六款值得大家關注的空投項目,預祝大家早賺錢!空投希望者繼續開發無代幣項目。加密貨幣正在推動投資者存款。空投接受者並沒有被專案團隊試圖否認代幣分配的可能性所動搖。四月是空投的重要月
 一覽Occ與自動駕駛的前世今生!首篇綜述全面總結特徵增強/量產部署/高效標註三大主題
May 08, 2024 am 11:40 AM
一覽Occ與自動駕駛的前世今生!首篇綜述全面總結特徵增強/量產部署/高效標註三大主題
May 08, 2024 am 11:40 AM
寫在前面&筆者的個人理解近年來,自動駕駛因其在減輕駕駛員負擔和提高駕駛安全方面的潛力而越來越受到關注。基於視覺的三維佔用預測是一種新興的感知任務,適用於具有成本效益且對自動駕駛安全全面調查的任務。儘管許多研究已經證明,與基於物體為中心的感知任務相比,3D佔用預測工具具有更大的優勢,但仍存在專門針對這一快速發展領域的綜述。本文首先介紹了基於視覺的3D佔用預測的背景,並討論了這項任務中遇到的挑戰。接下來,我們從特徵增強、部署友善性和標籤效率三個面向全面探討了目前3D佔用預測方法的現況和發展趨勢。最後
