

全面剖析PHP 數組底層實現邏輯

前言
php小編香蕉全面剖析PHP陣列底層實作邏輯。 PHP中的陣列是一種靈活且強大的資料結構,背後的實作邏輯卻是相當複雜的。在本文中,我們將深入探討PHP數組的底層原理,包括數組的內部結構、索引與雜湊表的關係,以及數組的增刪改查操作的實作方式。透過了解PHP數組的底層實現邏輯,可以幫助開發者更好地理解並利用數組這一重要的資料結構。
陣列的結構
一個陣列在 PHP 核心裡是長什麼樣子的呢?我們可以從PHP 的原始碼裡看到其結構如下:
<code>// 定义结构体别名为 HashTable
typedef struct _zend_array HashTable;
struct _zend_array {
// <strong class="keylink">GC</strong> 保存引用计数,内存管理相关;本文不涉及
zend_refcounted_h gc;
// u 储存辅助信息;本文不涉及
u<strong class="keylink">NIO</strong>n {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar consistency)
} v;
uint32_t flags;
} u;
// 用于散列函数
uint32_t nTableMask;
// arData 指向储存元素的数组第一个 Bucket,Bucket 为统一的数组元素类型
Bucket *arData;
// 已使用 Bucket 数
uint32_t nNumUsed;
// 数组内有效元素个数
uint32_t nNumOfElements;
// 数组总容量
uint32_t nTableSize;
// 内部指针,用于遍历
uint32_t nInternalPointer;
// 下一个可用数字<strong class="keylink">索引</strong>
zend_long nNextFreeElement;
// 析构函数
dtor_func_t pDestructor;
};</code>nNumUsed和nNumOfElements的差異:nNumUsed指的是arData陣列中已使用的Bucket數,因為陣列在刪除元素後只是將該元素Bucket對應值的類型設定為IS_UNDEF(因為如果每次刪除元素都要將陣列移動並重新索引太浪費時間),而nNumOfElements對應的是陣列中真正的元素個數。nTableSize陣列的容量,值為 2 的冪次方。 PHP 的陣列是不定長度但C 語言的陣列定長的,為了實現PHP 的不定長數組的功能,採用了「擴容」的機制,就是在每次插入元素的時候判斷nTableSize是否足以儲存。如果不足則重新申請2 倍nTableSize大小的新數組,並將原始數組複製過來(此時正是清除原始數組中類型為IS_UNDEF元素的時機)並且重新索引。nNextFreeElement儲存下一個可用數字索引,例如在PHP 中$a[] = 1;這種用法會插入一個索引為nNextFreeElement的元素,然後nNextFreeElement自增1。
_zend_array 這個結構先講到這裡,有些結構體成員的角色在下文會解釋,不用緊張O(∩_∩)O哈哈~。下面來看看作為數組成員的Bucket 結構:
<code>typedef struct _Bucket {
// 数组元素的值
zval val;
// key 通过 Time 33 <strong class="keylink">算法</strong>计算得到的哈希值或数字索引
zend_ulong h;
// 字符键名,数字索引则为 NULL
zend_string *key;
} Bucket;</code>數組存取
我們知道PHP 數組是基於哈希表實現的,而與一般哈希表不同的是PHP 的陣列也實現了元素的有序性,就是插入的元素從記憶體上來看是連續的而不是亂序的,為了實現這個有序性PHP 採用了「映射表」技術。以下就透過圖例說明我們是如何存取 PHP 陣列的元素 :-D。
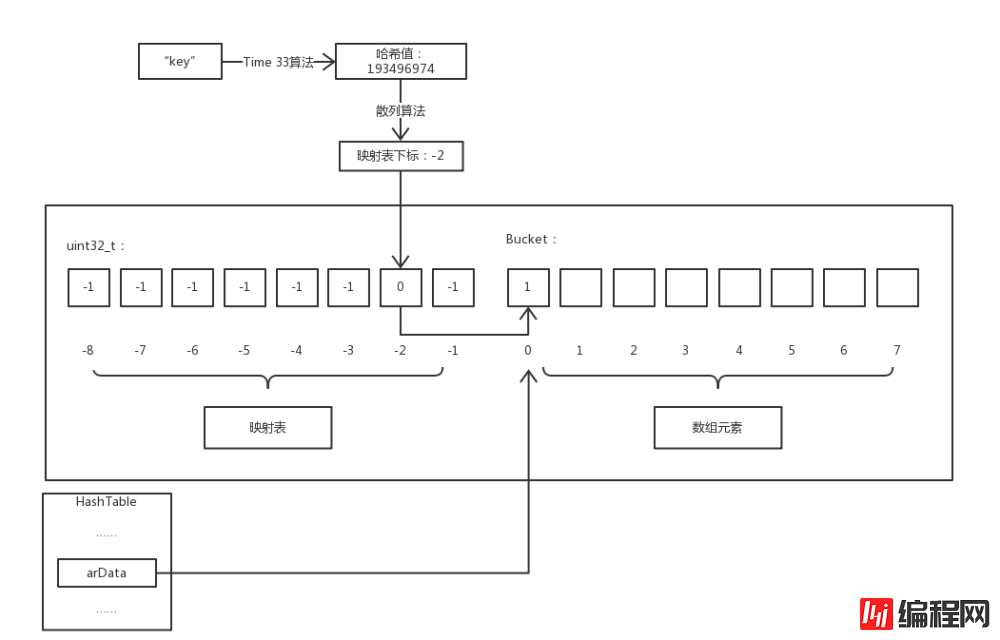
注意:因為鍵名到映射表下標經過了兩次散列運算,為了區分本文用哈希特指第一次散列,散列即為第二次散列。
由圖可知,映射表和數組元素在同一片連續的內存中,映射表是一個長度與存儲元素相同的整數數組,它默認值為-1 ,有效值為Bucket 陣列的下標。而 HashTable->arData 指向的是這片記憶體中 Bucket 陣列的第一個元素。
舉例$a['key'] 存取陣列$a 中鍵名為key 的成員,流程介紹:先透過Time 33 演算法計算出key 的雜湊值,然後透過雜湊演算法計算出該雜湊值對應的映射表下標,因為映射表中保存的值就是Bucket陣列中的下標值,所以就能取得到Bucket 陣列中對應的元素。
現在我們來聊聊雜湊演算法,就是透過鍵名的雜湊值映射到「映射表」的下標的演算法。其實很簡單就一行程式碼:
<code>nIndex = h | ht->nTableMask;</code>
將雜湊值和nTableMask 進行或運算即可得出映射表的下標,其中nTableMask 數值為nTableSize 的負數。且由於 nTableSize 的值為2 的冪次方,所以h | ht->nTableMask 的值範圍在[-nTableSize, -1]之間,正好在映射表的下標範圍內。至於為何不用簡單的「取餘」運算而是費盡周折的採用「位元或」運算?因為「位元或」運算的速度比「取餘」運算快很多,我覺得對於這種頻繁使用的操作來說,複雜一點的實現帶來的時間上的優化是值得的。
雜湊衝突
不同鍵名的雜湊值透過雜湊計算得到的「映射表」下標有可能相同,此時便發生了雜湊衝突。對於這種情況 PHP 使用了「鏈結位址法」解決。下圖是存取發生雜湊衝突的元素的情況:
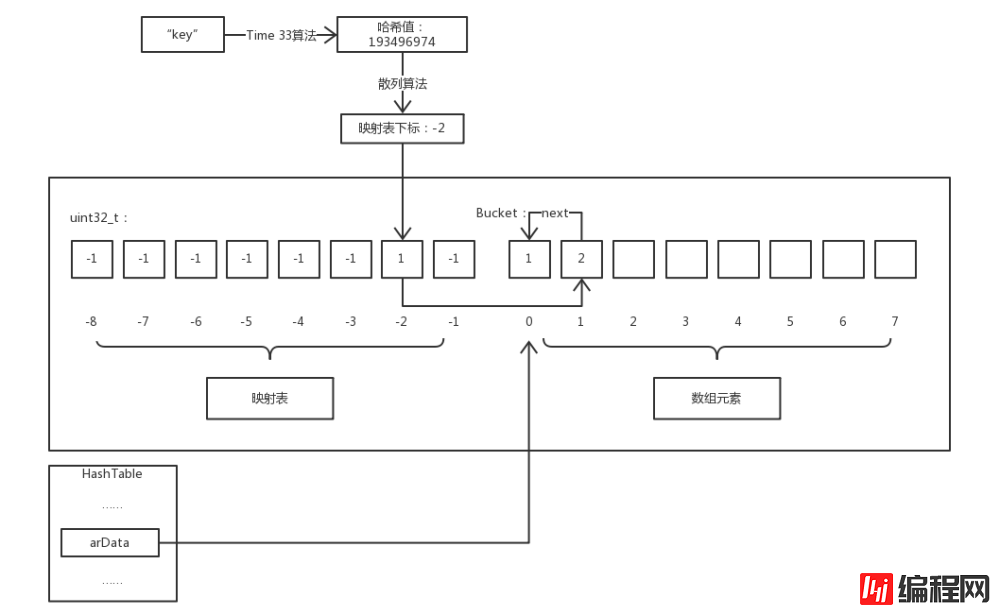
这看似与第一张图差不多,但我们同样访问 $a['key'] 的过程多了一些步骤。首先通过散列运算得出映射表下标为 -2 ,然后访问映射表发现其内容指向 arData 数组下标为 1 的元素。此时我们将该元素的 key 和要访问的键名相比较,发现两者并不相等,则该元素并非我们所想访问的元素,而元素的 val.u2.next 保存的值正是下一个具有相同散列值的元素对应 arData 数组的下标,所以我们可以不断通过 next 的值遍历直到找到键名相同的元素或查找失败。
插入元素
插入元素的函数 _zend_hash_add_or_update_i ,基于 PHP 7.2.9 的代码如下:
<code>static zend_always_inline zval *_zend_hash_add_or_update_i(HashTable *ht, zend_string *key, zval *pData, uint32_t flag ZEND_FILE_LINE_DC)
{
zend_ulong h;
uint32_t nIndex;
uint32_t idx;
Bucket *p;
IS_CONSISTENT(ht);
HT_ASSERT_RC1(ht);
if (UNEXPECTED(!(ht->u.flags & HASH_FLAG_INITIALIZED))) { // 数组未初始化
// 初始化数组
CHECK_INIT(ht, 0);
// 跳转至插入元素段
goto add_to_hash;
} else if (ht->u.flags & HASH_FLAG_PACKED) { // 数组为连续数字索引数组
// 转换为关联数组
zend_hash_packed_to_hash(ht);
} else if ((flag & HASH_ADD_NEW) == 0) { // 添加新元素
// 查找键名对应的元素
p = zend_hash_find_bucket(ht, key);
if (p) { // 若相同键名元素存在
zval *data;
if (flag & HASH_ADD) { // 指定 add 操作
if (!(flag & HASH_UPDATE_INDIRECT)) { // 若不允许更新间接类型变量则直接返回
return NULL;
}
// 确定当前值和新值不同
ZEND_ASSERT(&p->val != pData);
// data 指向原数组成员值
data = &p->val;
if (Z_TYPE_P(data) == IS_INDIRECT) { // 原数组元素变量类型为间接类型
// 取间接变量对应的变量
data = Z_INDIRECT_P(data);
if (Z_TYPE_P(data) != IS_UNDEF) { // 该对应变量存在则直接返回
return NULL;
}
} else { // 非间接类型直接返回
return NULL;
}
} else { // 没有指定 add 操作
// 确定当前值和新值不同
ZEND_ASSERT(&p->val != pData);
// data 指向原数组元素值
data = &p->val;
// 允许更新间接类型变量则 data 指向对应的变量
if ((flag & HASH_UPDATE_INDIRECT) && Z_TYPE_P(data) == IS_INDIRECT) {
data = Z_INDIRECT_P(data);
}
}
if (ht->pDestructor) { // 析构函数存在
// 执行析构函数
ht->pDestructor(data);
}
// 将 pData 的值复制给 data
ZVAL_COPY_VALUE(data, pData);
return data;
}
}
// 如果哈希表已满,则进行扩容
ZEND_HASH_IF_FULL_DO_RESIZE(ht);
add_to_hash:
// 数组已使用 Bucket 数 +1
idx = ht->nNumUsed++;
// 数组有效元素数目 +1
ht->nNumOfElements++;
// 若内部指针无效则指向当前下标
if (ht->nInternalPointer == HT_INVALID_IDX) {
ht->nInternalPointer = idx;
}
zend_hash_iterators_update(ht, HT_INVALID_IDX, idx);
// p 为新元素对应的 Bucket
p = ht->arData + idx;
// 设置键名
p->key = key;
if (!ZSTR_IS_INTERNED(key)) {
zend_string_addref(key);
ht->u.flags &= ~HASH_FLAG_STATIC_KEYS;
zend_string_hash_val(key);
}
// 计算键名的哈希值并赋值给 p
p->h = h = ZSTR_H(key);
// 将 pData 赋值该 Bucket 的 val
ZVAL_COPY_VALUE(&p->val, pData);
// 计算映射表下标
nIndex = h | ht->nTableMask;
// 解决冲突,将原映射表中的内容赋值给新元素变量值的 u2.next 成员
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
// 将映射表中的值设为 idx
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx);
return &p->val;
}</code>扩容
前面将数组结构的时候我们有提到扩容,而在插入元素的代码里有这样一个宏 ZEND_HASH_IF_FULL_DO_RESIZE,这个宏其实就是调用了 zend_hash_do_resize 函数,对数组进行扩容并重新索引。注意:并非每次 Bucket 数组满了都需要扩容,如果 Bucket 数组中 IS_UNDEF 元素的数量占较大比例,就直接将 IS_UNDEF 元素删除并重新索引,以此节省内存。下面我们看看 zend_hash_do_resize 函数:
重新索引的逻辑在 zend_hash_rehash 函数中,代码如下:
总结
嗯哼,本文就到此结束了,因为自身水平原因不能解释的十分详尽清楚。这算是我写过最难写的内容了,写完之后似乎觉得这篇文章就我自己能看明白/(ㄒoㄒ)/~~因为文笔太辣鸡。想起一句话「如果你不能简单地解释一样东西,说明你没真正理解它。」PHP 的源码里有很多细节和实现我都不算熟悉,这篇文章只是一个我的 PHP 底层学习的开篇,希望以后能够写出真正深入浅出的好文章。
以上是全面剖析PHP 數組底層實現邏輯的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 適用於 Ubuntu 和 Debian 的 PHP 8.4 安裝和升級指南
Dec 24, 2024 pm 04:42 PM
適用於 Ubuntu 和 Debian 的 PHP 8.4 安裝和升級指南
Dec 24, 2024 pm 04:42 PM
PHP 8.4 帶來了多項新功能、安全性改進和效能改進,同時棄用和刪除了大量功能。 本指南介紹如何在 Ubuntu、Debian 或其衍生版本上安裝 PHP 8.4 或升級到 PHP 8.4
 如何設定 Visual Studio Code (VS Code) 進行 PHP 開發
Dec 20, 2024 am 11:31 AM
如何設定 Visual Studio Code (VS Code) 進行 PHP 開發
Dec 20, 2024 am 11:31 AM
Visual Studio Code,也稱為 VS Code,是一個免費的原始碼編輯器 - 或整合開發環境 (IDE) - 可用於所有主要作業系統。 VS Code 擁有大量針對多種程式語言的擴展,可以輕鬆編寫
 您如何在PHP中解析和處理HTML/XML?
Feb 07, 2025 am 11:57 AM
您如何在PHP中解析和處理HTML/XML?
Feb 07, 2025 am 11:57 AM
本教程演示瞭如何使用PHP有效地處理XML文檔。 XML(可擴展的標記語言)是一種用於人類可讀性和機器解析的多功能文本標記語言。它通常用於數據存儲
 在PHP API中說明JSON Web令牌(JWT)及其用例。
Apr 05, 2025 am 12:04 AM
在PHP API中說明JSON Web令牌(JWT)及其用例。
Apr 05, 2025 am 12:04 AM
JWT是一種基於JSON的開放標準,用於在各方之間安全地傳輸信息,主要用於身份驗證和信息交換。 1.JWT由Header、Payload和Signature三部分組成。 2.JWT的工作原理包括生成JWT、驗證JWT和解析Payload三個步驟。 3.在PHP中使用JWT進行身份驗證時,可以生成和驗證JWT,並在高級用法中包含用戶角色和權限信息。 4.常見錯誤包括簽名驗證失敗、令牌過期和Payload過大,調試技巧包括使用調試工具和日誌記錄。 5.性能優化和最佳實踐包括使用合適的簽名算法、合理設置有效期、
 php程序在字符串中計數元音
Feb 07, 2025 pm 12:12 PM
php程序在字符串中計數元音
Feb 07, 2025 pm 12:12 PM
字符串是由字符組成的序列,包括字母、數字和符號。本教程將學習如何使用不同的方法在PHP中計算給定字符串中元音的數量。英語中的元音是a、e、i、o、u,它們可以是大寫或小寫。 什麼是元音? 元音是代表特定語音的字母字符。英語中共有五個元音,包括大寫和小寫: a, e, i, o, u 示例 1 輸入:字符串 = "Tutorialspoint" 輸出:6 解釋 字符串 "Tutorialspoint" 中的元音是 u、o、i、a、o、i。總共有 6 個元
 解釋PHP中的晚期靜態綁定(靜態::)。
Apr 03, 2025 am 12:04 AM
解釋PHP中的晚期靜態綁定(靜態::)。
Apr 03, 2025 am 12:04 AM
靜態綁定(static::)在PHP中實現晚期靜態綁定(LSB),允許在靜態上下文中引用調用類而非定義類。 1)解析過程在運行時進行,2)在繼承關係中向上查找調用類,3)可能帶來性能開銷。
 什麼是PHP魔術方法(__ -construct,__destruct,__call,__get,__ set等)並提供用例?
Apr 03, 2025 am 12:03 AM
什麼是PHP魔術方法(__ -construct,__destruct,__call,__get,__ set等)並提供用例?
Apr 03, 2025 am 12:03 AM
PHP的魔法方法有哪些? PHP的魔法方法包括:1.\_\_construct,用於初始化對象;2.\_\_destruct,用於清理資源;3.\_\_call,處理不存在的方法調用;4.\_\_get,實現動態屬性訪問;5.\_\_set,實現動態屬性設置。這些方法在特定情況下自動調用,提升代碼的靈活性和效率。
 說明匹配表達式(PHP 8)及其與開關的不同。
Apr 06, 2025 am 12:03 AM
說明匹配表達式(PHP 8)及其與開關的不同。
Apr 06, 2025 am 12:03 AM
在PHP8 中,match表達式是一種新的控制結構,用於根據表達式的值返回不同的結果。 1)它類似於switch語句,但返回值而非執行語句塊。 2)match表達式使用嚴格比較(===),提升了安全性。 3)它避免了switch語句中可能的break遺漏問題,增強了代碼的簡潔性和可讀性。
