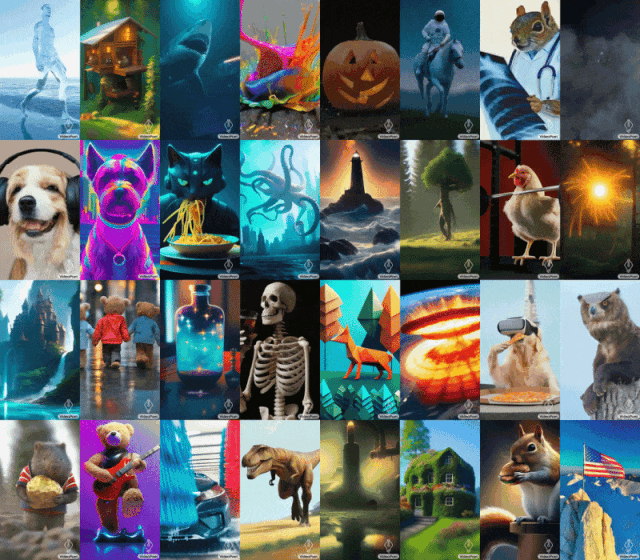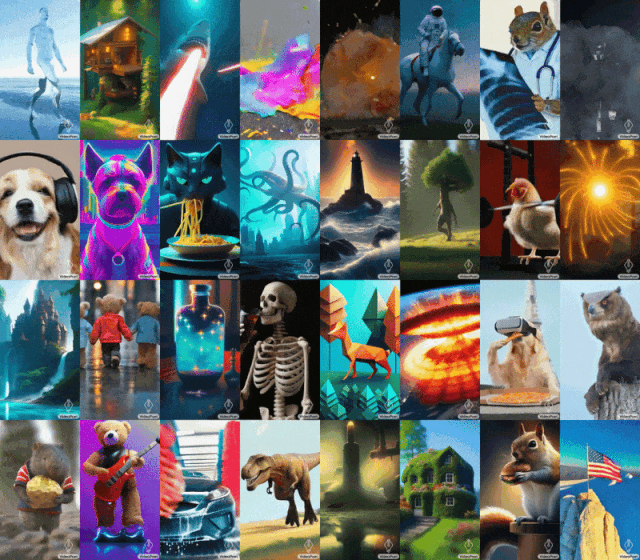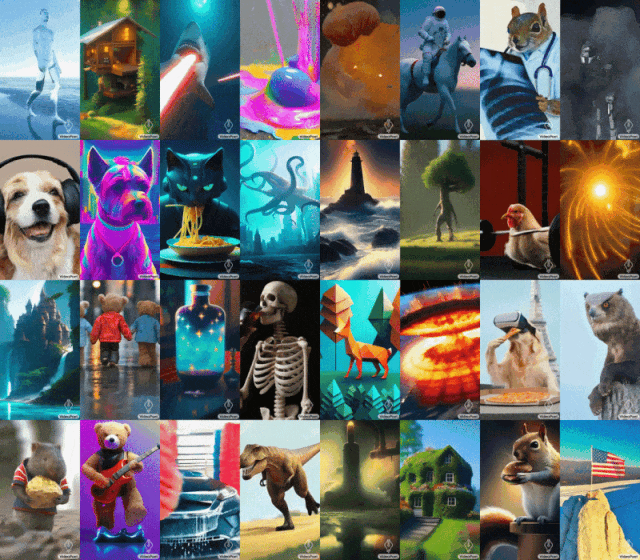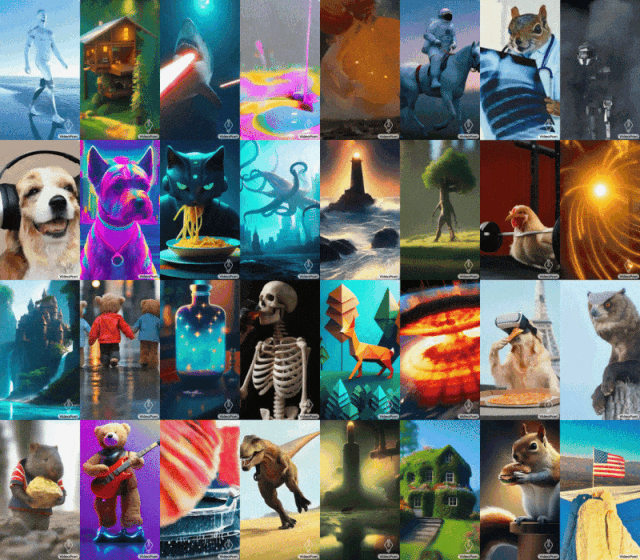蒙娜麗莎打哈欠,小雞學會舉鐵…GoogleVideoPoet大模型表現很亮眼。
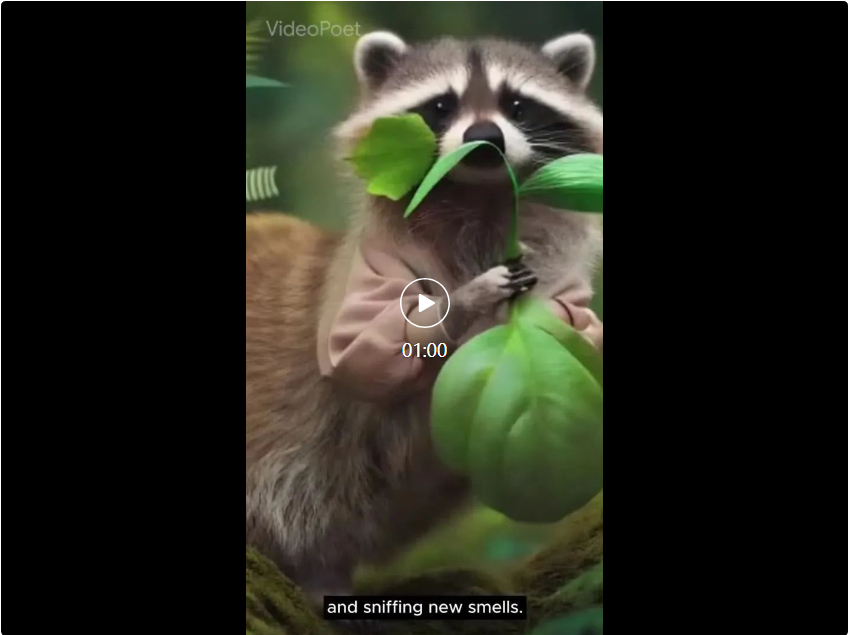
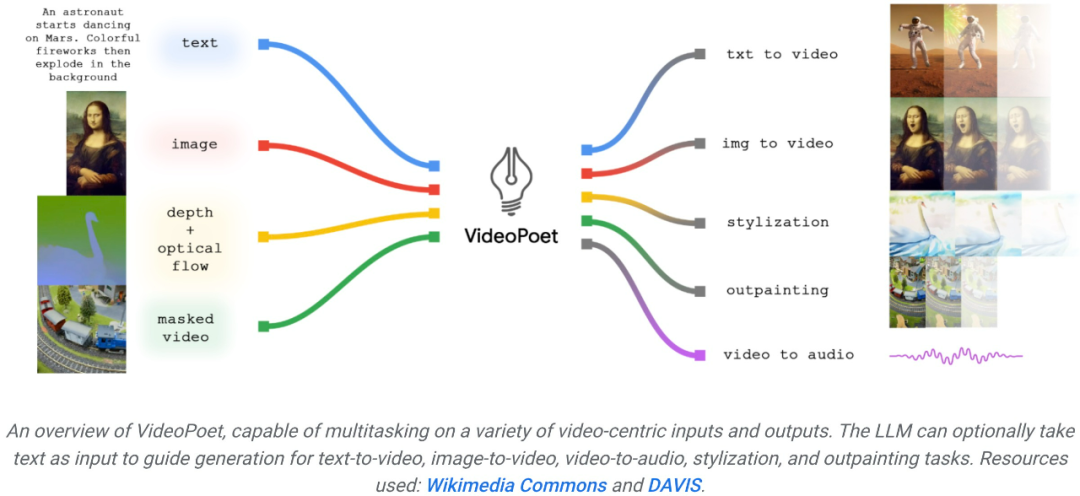
2023 年底,科技公司都在衝擊生成式 AI 的最後一個關卡 —— 影片產生。 本週二,Google提出的影片產生大模型上線,立刻獲得了人們的關注。這款名為 VideoPoet 的大語言模型,被人們認為是革命性的 zero-shot 視訊生成工具。 VideoPoet 既可以文生視頻、圖像生視頻,又能風格遷移,視訊轉語音。從效果來看,它可以建立多樣化且流暢的運動。 
消息一出,有很多人表示歡迎:看看目前的幾個成品效果不錯,大模型技術發展的速度也太快了。
來源:https://twitter.com/cybersphere_ai/status/1737257729167966353
也有人呼籲,Google要趕緊把 VideoPoet 開源了,大趨勢不等人。 隨著生成式 AI 的發展,最近出現了一波新的影片生成模型,這些模型展示了令人驚嘆的畫面品質。目前影片產生的瓶頸之一是產生連貫的大動作。但在許多情況下,即使是領先的模型也只能產生較小的運動,或者當產生較大的運動時,會表現出明顯的偽影。 為了探索語言模型在視訊生成中的應用,來自Google的研究者引入了一種大語言模型(LLM)VideoPoet,能夠執行各種視訊生成任務,包括文字到視訊、圖像到視訊、視訊風格化、 視訊修復和擴展,以及視訊轉音訊。
提示(從左到右):一條從嘴裡射出激光束的鯊魚;泰迪熊手牽著手走在雨天的第五大道上;舉鐵的小雞。
提示(從左到右):黃色蒲公英花瓣製成的獅子在咆哮;地球表面發生大規模爆炸;一匹馬在梵谷的星夜中馳騁;穿著盔甲的松鼠騎著鵝;熊貓在自拍。
#對於圖像到視頻,VideoPoet 可以獲取輸入圖像並透過提示將其動畫化。 蒙娜麗莎開始打哈欠,只要輸入一張圖片,外加一句提示:一個女人打哈欠。就會得到下面的效果。
提示(從左到右):一艘船在波濤洶湧的大海上航行,有雷暴和閃電,油畫風格;飛過有許多閃爍星星的星雲;大風天,一個拄著拐杖站在懸崖上的流浪者,俯視著底下浮動的雲海。
#VideoPoet 也能夠根據文字提示對輸入視訊進行風格化。 提示(從左到右):泰迪熊在乾淨的冰湖上滑冰;一隻金屬色的獅子在熔爐的光芒下咆哮。
#VideoPoet 也能夠產生音訊。首先讓模型產生 2 秒的剪輯,然後嘗試在沒有任何文字指導的情況下預測畫面的音訊。這樣一來,VideoPoet 能夠從單一模型產生視訊和音訊。 #VideoPoet 還能產生長視頻,預設是 2 秒。透過調節影片的最後 1 秒並預測接下來的 1 秒,這個過程可以無限地重複,以產生任意時長的影片。以下是 VideoPoet 從文字輸入產生長影片的範例展示。提示:FPV 鏡頭展示了叢林中非常鋒利的精靈石城,有明亮的藍色河流、瀑布和大而陡峭的垂直懸崖面。
#使用者可以改變提示,進而擴充影片。原始影片是兩隻浣熊騎著摩托車在松樹環繞的山路上行駛,8k。擴展後的影片是兩隻浣熊騎著摩托車,浣熊身後落下流星,流星撞擊地球並爆炸。
#對於提供的輸入影片(最左邊),使用者可以改變物體的運動來執行不同的動作。如下所示,中間三個沒有文字提示,最後一個文字提示為:煙霧背景下啟動。
#VideoPoet 可以在影片被遮住的部分加入細節,也可以選擇透過文字引導進行修復。
為了展示 VideoPoet 的功能,Google也製作了一部由 VideoPoet 產生的多個短片組成的小短片。劇本是 Bard 編寫的,是關於一隻旅行浣熊的短篇故事,並附有逐個場景的分解和附帶的提示列表。然後,谷歌為每個提示生成視訊剪輯,並將所有生成的剪輯拼接在一起以產生下面的最終影片。 #如下圖所示,VideoPoet 可以將輸入影像動畫化以產生一段視頻,並且可以編輯視頻或擴展視頻。
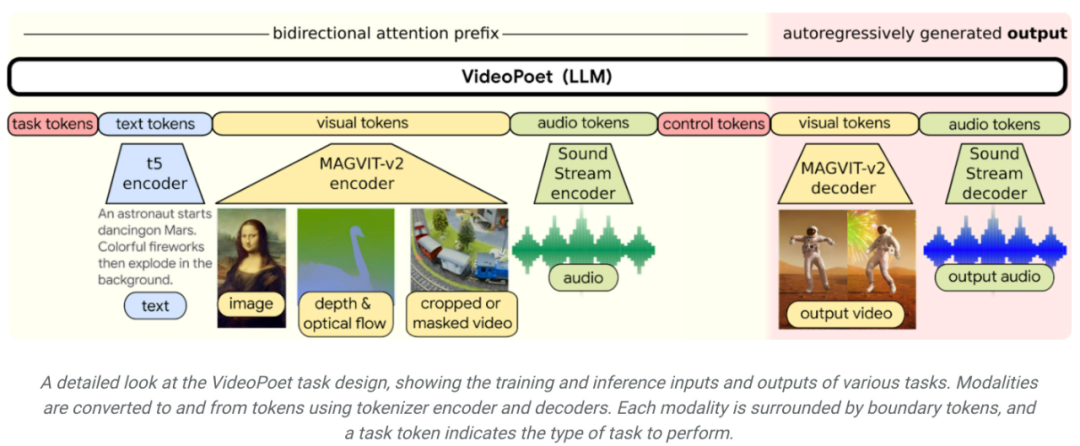
在風格化方面,該模型接收表徵深度和光流的視頻,以文字指導的風格繪製內容。 #使用LLM 進行訓練的一個關鍵優勢是,可以重複使用現有LLM 訓練基礎設施中引入的許多可擴展的效率改進。然而,LLM 是在離散 token 上運行的,這使得視訊生成具有挑戰性。而視訊和音訊 tokenizer 可以用來將視訊和音訊剪輯編碼為離散 token 序列,並且也可以轉換回原始表徵形式。 透過使用多個tokenizer(用於視訊和圖像的MAGVIT V2 和用於音訊的SoundStream),VideoPoet 訓練自回歸語言模型來學習跨視訊、圖像、音訊和文字的多個模態。一旦模型產生以某些上下文為條件的 token,就可以使用 tokenizer 解碼器將它們轉換回視覺化的表徵形式。
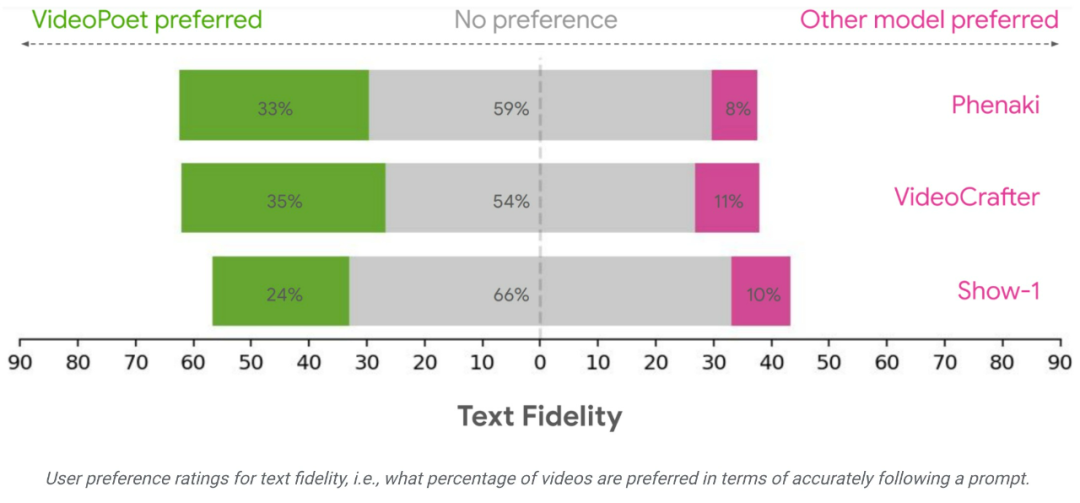
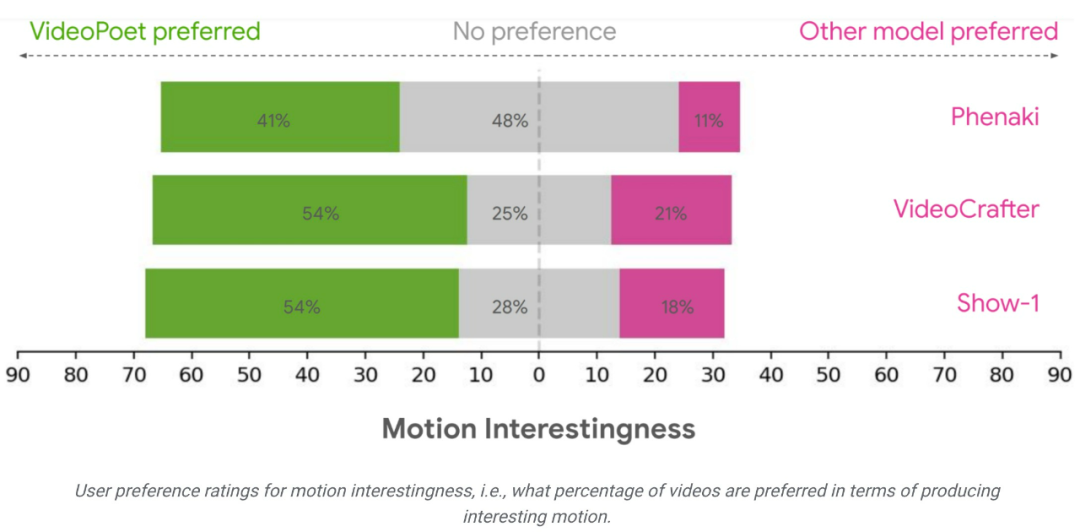
#研究團隊使用各種基準來評估VideoPoet 在文本到影片產生方面的表現,以將結果與其他方法進行比較。為了確保中立的評估,該研究在各種不同的 prompt 下運行了所有模型,沒有挑選示例,並要求人類評估者進行偏好評分。
#平均而言,在遵循prompt 方面,人們認為VideoPoet 中24-35% 的範例比競爭模型更好,而競爭模型的比例為8-11%。評分者也喜歡 VideoPoet 中 41-54% 的範例,因為產生影片的動作更有趣,而其他模型的比例為 11-21%。 https://blog.research. google/2023/12/videopoet-large-language-model-for-zero.htmlhttps://sites.research.google/videopoet/stylization /以上是影片生成可以無限長?谷歌VideoPoet大模型上線,網友:革命性技術的詳細內容。更多資訊請關注PHP中文網其他相關文章!