

可視化FAISS向量空間並調整RAG參數提高結果精度

隨著開源大型語言模型的效能不斷提高,編寫和分析程式碼、推薦、文字摘要和問答(QA)對的效能都有了很大的提高。但當涉及QA時,LLM通常會在未訓練資料的相關的問題上有所欠缺,許多內部文件都保存在公司內部,以確保合規性、商業機密或隱私。當查詢這些文件時,會使得LLM產生幻覺,產生不相關、捏造或不一致的內容。

一種處理這項挑戰的可行技術是檢索增強生成(RAG)。它涉及透過引用訓練資料來源以外的權威知識庫來增強回應的過程,以提升生成的品質和準確性。 RAG系統包括一個檢索系統,用於從語料庫中檢索相關文檔片段,以及一個LLM模型,利用檢索到的片段作為上下文來產生回應。因此,語料庫的品質和嵌入在向量空間中的表示對RAG的表現至關重要。
在本文中,我們將使用視覺化庫renumics-spotlight在2-D中可視化FAISS向量空間的多維嵌入,並透過改變某些關鍵的向量化參數來尋找提高RAG響應精度的可能性。對於我們選擇的LLM,將採用TinyLlama 1.1B Chat,這是一個緊湊的模型,與Llama 2相同的架構。它的優點是具有較小的資源佔用和更快的運行時間,但其準確性沒有成比例的下降,這使它成為快速實驗的理想選擇。
系統設計
QA系統有兩個模組,如圖所示。
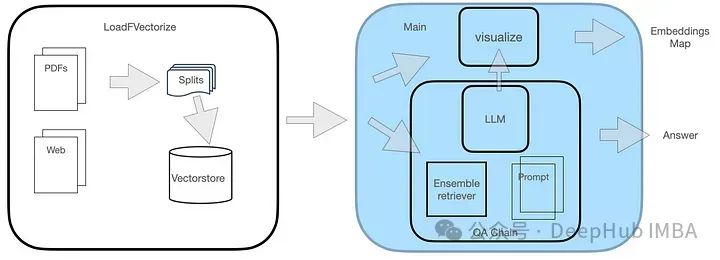
LoadFVectorize模組用於載入PDF或Web文檔,並進行初步測試和視覺化。另一個模組負責載入LLM並實例化FAISS檢索器,然後建構一個包含LLM、檢索器和自訂查詢提示的檢索鏈。最後,我們對向量空間進行視覺化處理。
程式碼實作
1、安裝必要的函式庫
renumics-spotlight函式庫採用類似於umap的可視化方法,將高維嵌入減少為易於管理的2D視覺化,同時保留關鍵屬性。我們之前曾簡單介紹過umap的用法,但僅限於基本功能介紹。這次,我們將其作為系統設計的一部分,將其整合到一個實際專案中。首先,需要安裝必要的庫。
pip install langchain faiss-cpu sentence-transformers flask-sqlalchemy psutil unstructured pdf2image unstructured_inference pillow_heif opencv-python pikepdf pypdf pip install renumics-spotlight CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir
上面的最後一行是安裝帶有Metal支援的llama- pcp -python庫,該庫將用於在M1處理器上加載帶有硬體加速的TinyLlama。
2、LoadFVectorize模組
模組包含3個功能:
##load_doc處理線上pdf文檔的加載,每個區塊分割512個字符,重疊100個字符,返回文檔列表。
vectorize呼叫上面的函數load_doc來取得文件的區塊列表,建立嵌入並儲存到本機目錄opdf_index,同時傳回FAISS實例。
load_db檢查FAISS庫是否在目錄opdf_index中的磁碟上並嘗試加載,最終傳回FAISS物件。
此模組程式碼的完整程式碼如下:
# LoadFVectorize.py from langchain_community.embeddings import HuggingFaceEmbeddings from langchain_community.document_loaders import OnlinePDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.vectorstores import FAISS # access an online pdf def load_doc() -> 'List[Document]':loader = OnlinePDFLoader("https://support.riverbed.com/bin/support/download?did=7q6behe7hotvnpqd9a03h1dji&versinotallow=9.15.0")documents = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100)docs = text_splitter.split_documents(documents)return docs # vectorize and commit to disk def vectorize(embeddings_model) -> 'FAISS':docs = load_doc()db = FAISS.from_documents(docs, embeddings_model)db.save_local("./opdf_index")return db # attempts to load vectorstore from disk def load_db() -> 'FAISS':embeddings_model = HuggingFaceEmbeddings()try:db = FAISS.load_local("./opdf_index", embeddings_model)except Exception as e:print(f'Exception: {e}\nNo index on disk, creating new...')db = vectorize(embeddings_model)return db3、主模組
主模組最初定義了以下模板的TinyLlama提示符模板:
{context}{question}另外採用來自TheBloke的量化版本的TinyLlama可以極大的減少內存,我們選擇以GGUF格式載入量化LLM。
接著使用LoadFVectorize模組傳回的FAISS對象,建立一個FAISS檢索器,實例化RetrievalQA,並將其用於查詢。
# main.py from langchain.chains import RetrievalQA from langchain.prompts import PromptTemplate from langchain_community.llms import LlamaCpp from langchain_community.embeddings import HuggingFaceEmbeddings import LoadFVectorize from renumics import spotlight import pandas as pd import numpy as np # Prompt template qa_template = """ You are a friendly chatbot who always responds in a precise manner. If answer is unknown to you, you will politely say so. Use the following context to answer the question below: {context} {question} """ # Create a prompt instance QA_PROMPT = PromptTemplate.from_template(qa_template) # load LLM llm = LlamaCpp(model_path="./models/tinyllama_gguf/tinyllama-1.1b-chat-v1.0.Q5_K_M.gguf",temperature=0.01,max_tokens=2000,top_p=1,verbose=False,n_ctx=2048 ) # vectorize and create a retriever db = LoadFVectorize.load_db() faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000) # Define a QA chain qa_chain = RetrievalQA.from_chain_type(llm,retriever=faiss_retriever,chain_type_kwargs={"prompt": QA_PROMPT} ) query = 'What versions of TLS supported by Client Accelerator 6.3.0?' result = qa_chain({"query": query}) print(f'--------------\nQ: {query}\nA: {result["result"]}') visualize_distance(db,query,result["result"])向量空間視覺化本身是由上面程式碼中的最後一行visualize_distance處理的:
visualize_distance存取FAISS物件的屬性__dict__,index_to_docstore_id本身是值docstore-ids的關鍵索引字典,用於向量化的總文檔計數由索引物件的屬性ntotal表示。
vs = db.__dict__.get("docstore")index_list = db.__dict__.get("index_to_docstore_id").values()doc_cnt = db.index.ntotal呼叫物件索引的方法reconstruct_n,可以實作向量空間的近似重建
embeddings_vec = db.index.reconstruct_n()
#有了docstore-id列表作為index_list,就可以找到相關的文檔對象,並使用它來創建一個包括docstore-id、文檔元數據、文檔內容以及它在所有id的向量空間中的嵌入的列表:
doc_list = list() for i,doc-id in enumerate(index_list):a_doc = vs.search(doc-id)doc_list.append([doc-id,a_doc.metadata.get("source"),a_doc.page_content,embeddings_vec[i]])然後使用清單建立一個包含列標題的DF,我們最後使用這個DF進行視覺化
df = pd.DataFrame(doc_list,columns=['id','metadata','document','embedding'])
在继续进行可视化之前,还需要将问题和答案结合起来,我们创建一个单独的问题以及答案的DF,然后与上面的df进行合并,这样能够显示问题和答案出现的地方,在可视化时我们可以高亮显示:
# add rows for question and answerembeddings_model = HuggingFaceEmbeddings()question_df = pd.DataFrame({"id": "question","question": question,"embedding": [embeddings_model.embed_query(question)],})answer_df = pd.DataFrame({"id": "answer","answer": answer,"embedding": [embeddings_model.embed_query(answer)],})df = pd.concat([question_df, answer_df, df])这里使用使用np.linalg.norm在文件和问题嵌入上的进行距离大小的计算:
question_embedding = embeddings_model.embed_query(question)# add column for vector distancedf["dist"] = df.apply( lambda row: np.linalg.norm(np.array(row["embedding"]) - question_embedding),axis=1,)
因为spotlight可以对df进行可视化,所有我们直接调用即可
spotlight.show(df)
這一步驟將在瀏覽器視窗中啟動spotlight。
運行測試
1、基本測試
以下是我們選擇的樣本問題:
What versions of TLS supported by Client Accelerator 6.3.0?
正確答案是:
Client Accelerator 6.3.0 supports TLS 1.1 或 1.2.
以下額外資訊可能包含在回應中。
You must enable this capability using the following CLI command on the Client Accelerator:(config) # policy id
ssl backend client-tls-1.2Even though TLS 1.1 is not mentioned in the syntax of this command, using this command automatically enables support for both TLS 1.1 and 1.2.
#水平回答:instead.Client Accelerator 6.3.0 supports TLS 1.1 or 1.2 as the default supported TLS versions with Client Accelerator. You must enable this capability wingusing the follo Client Accelerator. You must enable this capability wingusing the follo Client Accelcommand the mustLIability wingus the follo the Client. Accelerator:```(config) # policy id
1.2. If you need to support older TLS versions,# 1.2. If you need to support older TLS versions,# 1.2. If you need to support older TLS versions,# 1.2. If you need to support older TLS versions,# 1.2. If you need to support older TLS versions,# 1.2. you can use the ssl backend command with the client-tlss1.0 or client-tlss1.1 option# ssl backend client -tlss1.2```Note that this command only applies to TLS 1.1 or TLS
看起來與實際答案非常相似,但它並不完全正確,因為這些TLS版本不是其預設值。
那我們來看看他是從哪些段落中找到的答案呢? 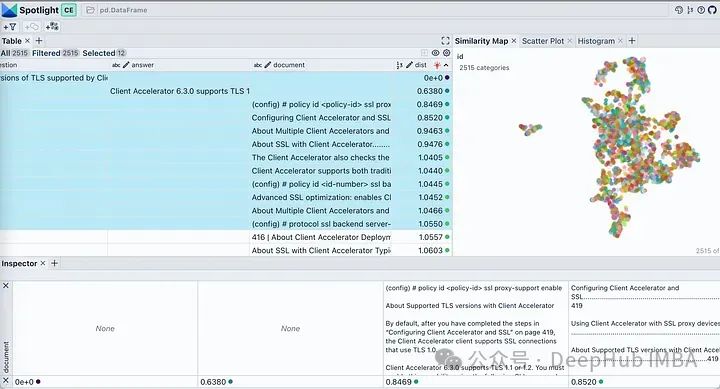
在可以spotlight中使用visible 按鈕來控制顯示的欄位。依照「dist」對表格進行排序,在頂部顯示問題、答案和最相關的文件片段。查看我們文件的嵌入,它將幾乎所有文件區塊描述為單一簇。這是合理的,因為我們原始pdf是針對特定產品的部署指南,所以被認為是一個簇是沒有問題的。
點擊Similarity Map選項卡中的過濾器圖標,它只突出顯示所選的文件列表,該列表是緊密聚集的,其餘的顯示為灰色,如圖下所示。 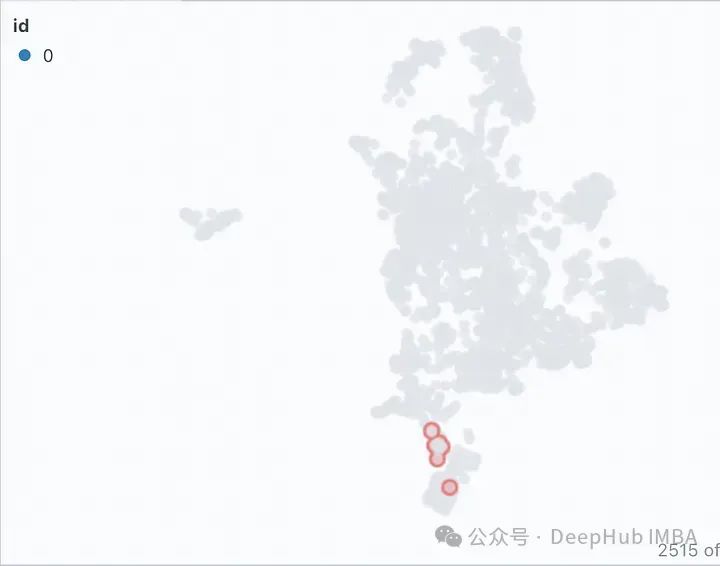
2、測試區塊大小和重疊參數
由於檢索器是影響RAG效能的關鍵因素,讓我們來看看影響嵌入空間的幾個參數。 TextSplitter的區塊大小chunk size(1000,2000)和/或重疊overlap (100,200)參數在文件分割期間是不同的。 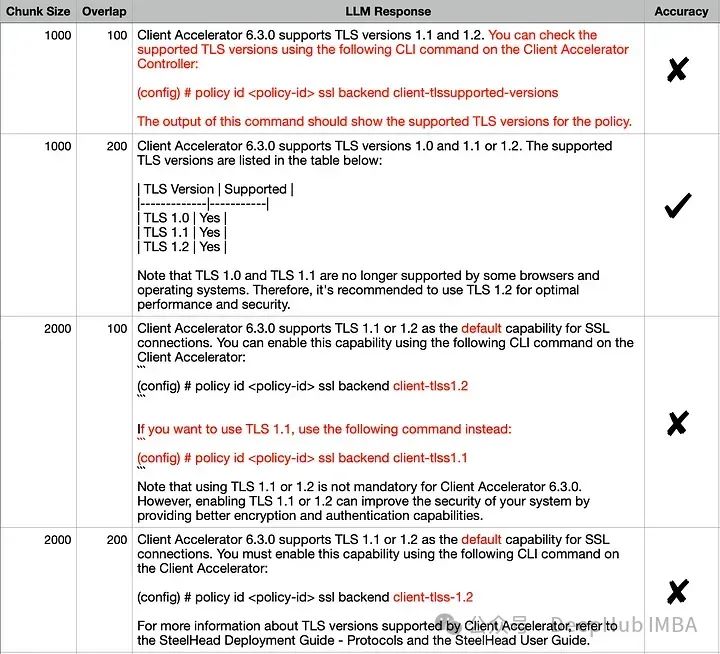
對所有組合的對於輸出似乎相似,但是如果我們仔細比較正確答案和每個回答,準確答案是(1000,200) 。其他答案中不正確的細節已經用紅色突出顯示。我們來嘗試使用視覺化嵌入來解釋這一行為: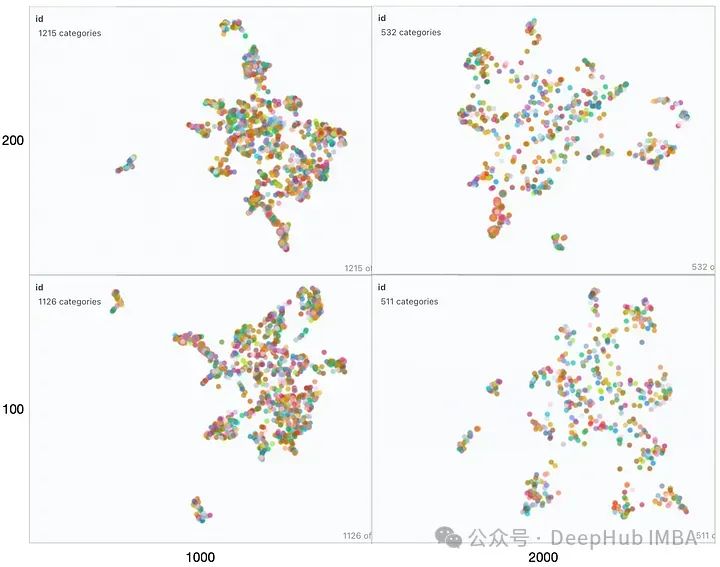
####從左到右觀察,隨著區塊大小的增加,我們可以觀察到向量空間變得稀疏且區塊更小。從底部到頂部,重疊逐漸增多,向量空間特徵沒有明顯變化。在所有這些映射中整個集合仍然或多或少地呈現為一個單一的簇,並且只有幾個異常值存在。這種情況在產生的回應中是可以看到的因為產生的回應都非常相似。 ######
如果查询位于簇中心等位置时由于最近邻可能不同,在这些参数发生变化时响应很可能会发生显著变化。如果RAG应用程序无法提供预期答案给某些问题,则可以通过生成类似上述可视化图表并结合这些问题进行分析,可能找到最佳划分语料库以提高整体性能方面优化方法。
为了进一步说明,我们将两个来自不相关领域(Grammy Awards和JWST telescope)的维基百科文档的向量空间进行可视化展示。
def load_doc():loader = WebBaseLoader(['https://en.wikipedia.org/wiki/66th_Annual_Grammy_Awards','https://en.wikipedia.org/wiki/James_Webb_Space_Telescope'])documents = loader.load()...
只修改了上面代码其余的代码保持不变。运行修改后的代码,我们得到下图所示的向量空间可视化。
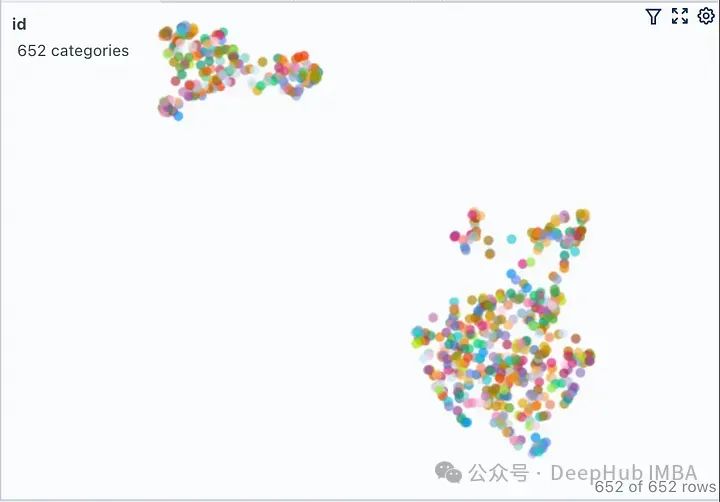
这里有两个不同的不重叠的簇。如果我们要在任何一个簇之外提出一个问题,那么从检索器获得上下文不仅不会对LLM有帮助,而且还很可能是有害的。提出之前提出的同样的问题,看看我们LLM产生什么样的“幻觉”
Client Accelerator 6.3.0 supports the following versions of Transport Layer Security (TLS):
- TLS 1.2\2. TLS 1.3\3. TLS 1.2 with Extended Validation (EV) certificates\4. TLS 1.3 with EV certificates\5. TLS 1.3 with SHA-256 and SHA-384 hash algorithms
这里我们使用FAISS用于向量存储。如果你正在使用ChromaDB并想知道如何执行类似的可视化,renumics-spotlight也是支持的。
总结
检索增强生成(RAG)允许我们利用大型语言模型的能力,即使LLM没有对内部文档进行训练也能得到很好的结果。RAG涉及从矢量库中检索许多相关文档块,然后LLM将其用作生成的上下文。因此嵌入的质量将在RAG性能中发挥重要作用。
在本文中,我们演示并可视化了几个关键矢量化参数对LLM整体性能的影响。并使用renumics-spotlight,展示了如何表示整个FAISS向量空间,然后将嵌入可视化。Spotlight直观的用户界面可以帮助我们根据问题探索向量空间,从而更好地理解LLM的反应。通过调整某些矢量化参数,我们能够影响其生成行为以提高精度。
以上是可視化FAISS向量空間並調整RAG參數提高結果精度的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 chrome瀏覽器閃退怎麼回事?如何解決Google瀏覽器一開啟閃退的問題?
Mar 13, 2024 pm 07:28 PM
chrome瀏覽器閃退怎麼回事?如何解決Google瀏覽器一開啟閃退的問題?
Mar 13, 2024 pm 07:28 PM
谷歌瀏覽器安全性高、穩定性強,受到廣大用戶的喜歡。但是有用戶發現自己一打開谷歌瀏覽器就閃退,這是怎麼回事?可能是打開了過多的標籤頁,也可能是瀏覽器版本過舊,下面就來看看詳細的解決方法。 如何解決Google瀏覽器閃退問題? 1、關閉一些不必要的標籤頁 如果打開的標籤頁過多,嘗試關閉一些不必要的標籤頁,可以有效地緩解谷歌瀏覽器的資源壓力,減少閃退的可能性。 2、更新Google瀏覽器 如果Google瀏覽器版本太舊,那也會導致閃退等錯誤,建議大家將Chrome更新到最新版。點選右上角【自訂及控制】-【設
 Windows on Ollama:本地運行大型語言模型(LLM)的新利器
Feb 28, 2024 pm 02:43 PM
Windows on Ollama:本地運行大型語言模型(LLM)的新利器
Feb 28, 2024 pm 02:43 PM
近期,OpenAITranslator和NextChat都開始支援Ollama本地運行的大型語言模型了,這對「新手上路」的愛好者來說,又多了一種新玩法。而且OllamaonWindows(預覽版)的推出,完全顛覆了在Windows裝置上進行AI開發的方式,它為AI領域的探索者和普通的「試水玩家」指引了一條明確的道路。什麼是Ollama? Ollama是一款開創性的人工智慧(AI)和機器學習(ML)工具平台,它大大簡化了AI模型的開發和使用過程。在科技社群裡,AI模型的硬體配置和環境建構一直是個棘
 pycharm閃退怎麼解決
Apr 25, 2024 am 05:09 AM
pycharm閃退怎麼解決
Apr 25, 2024 am 05:09 AM
PyCharm 閃退的解決方法包括:檢查記憶體使用情況並增加PyCharm 的記憶體限制;更新PyCharm 至最新版本;檢查插件並停用或卸載不必要的插件;重置PyCharm 設定;停用硬體加速;重新安裝PyCharm;聯繫支持人員尋求協助。
 為什麼大型語言模型都在使用 SwiGLU 作為激活函數?
Apr 08, 2024 pm 09:31 PM
為什麼大型語言模型都在使用 SwiGLU 作為激活函數?
Apr 08, 2024 pm 09:31 PM
如果你一直在關注大型語言模型的架構,你可能會在最新的模型和研究論文中看到「SwiGLU」這個詞。 SwiGLU可以說是在大語言模型中最常使用的激活函數,我們這篇文章就來對它進行詳細的介紹。 SwiGLU其實是2020年Google提出的激活函數,它結合了SWISH和GLU兩者的特徵。 SwiGLU的中文全名為“雙向門控線性單元”,它將SWISH和GLU兩種激活函數進行了優化和結合,以提高模型的非線性表達能力。 SWISH是一種非常普遍的激活函數,它在大語言模型中得到廣泛應用,而GLU則在自然語言處理任務中表現出
 WPS某個表格反應很慢怎麼辦? wps表格卡頓反應慢怎麼回事?
Mar 14, 2024 pm 02:43 PM
WPS某個表格反應很慢怎麼辦? wps表格卡頓反應慢怎麼回事?
Mar 14, 2024 pm 02:43 PM
WPS某個表格反應很慢怎麼辦?使用者可以嘗試關閉其他的程式或是更新軟體來進行操作,以下就讓本站來為使用者來仔細的介紹一下wps表格卡頓反應慢怎麼回事。 wps表格卡頓反應慢怎麼回事 1、關閉其他程序:關閉其他正在運行的程序,特別是佔用大量系統資源的程序。這樣可以為WPSOffice提供更多的運算資源,減少卡頓和延遲。 2、更新WPSOffice:確保你使用的是最新版本的WPSOffice。在WPSOffice官方網站上下載並安裝最新版可以解決一些已知的效能問題。 3、減少文件大
 比較流暢的安卓模擬器推薦(選用的安卓模擬器)
Apr 21, 2024 pm 06:01 PM
比較流暢的安卓模擬器推薦(選用的安卓模擬器)
Apr 21, 2024 pm 06:01 PM
它能夠提供使用者更好的遊戲體驗和使用體驗,安卓模擬器是一種可以在電腦上模擬安卓系統運作的軟體。市面上的安卓模擬器種類繁多,品質參差不齊,然而。幫助讀者選擇最適合自己的模擬器、本文將重點放在一些流暢且好用的安卓模擬器。一、BlueStacks:運行速度快速具有出色的運行速度和流暢的用戶體驗、BlueStacks是一款備受歡迎的安卓模擬器。使用戶能夠暢玩各類行動遊戲和應用,它能夠在電腦上以極高的性能模擬安卓系統。二、NoxPlayer:支援多開,玩遊戲更爽可以同時在多個模擬器中運行不同的遊戲、它支援
 本地使用Groq Llama 3 70B的逐步指南
Jun 10, 2024 am 09:16 AM
本地使用Groq Llama 3 70B的逐步指南
Jun 10, 2024 am 09:16 AM
譯者|布加迪審校|重樓本文介紹如何使用GroqLPU推理引擎在JanAI和VSCode中產生超快速反應。每個人都致力於建立更好的大語言模型(LLM),例如Groq專注於AI的基礎設施方面。這些大模型的快速響應是確保這些大模型更快捷響應的關鍵。本教學將介紹GroqLPU解析引擎以及如何在筆記型電腦上使用API和JanAI本地存取它。本文也將把它整合到VSCode中,以幫助我們產生程式碼、重構程式碼、輸入文件並產生測試單元。本文將免費創建我們自己的人工智慧程式設計助理。 GroqLPU推理引擎簡介Groq
 加州理工華人用AI顛覆數學證明!提速5倍震驚陶哲軒,80%數學步驟全自動化
Apr 23, 2024 pm 03:01 PM
加州理工華人用AI顛覆數學證明!提速5倍震驚陶哲軒,80%數學步驟全自動化
Apr 23, 2024 pm 03:01 PM
LeanCopilot,讓陶哲軒等眾多數學家讚不絕口的這個形式化數學工具,又有超強進化了?就在剛剛,加州理工學院教授AnimaAnandkumar宣布,團隊發布了LeanCopilot論文的擴展版本,更新了程式碼庫。圖片論文地址:https://arxiv.org/pdf/2404.12534.pdf最新實驗表明,這個Copilot工具,可以自動化80%以上的數學證明步驟了!這個紀錄,比以前的基線aesop還要好2.3倍。並且,和以前一樣,它在MIT許可下是開源的。圖片他是一位華人小哥宋沛洋,他是
