
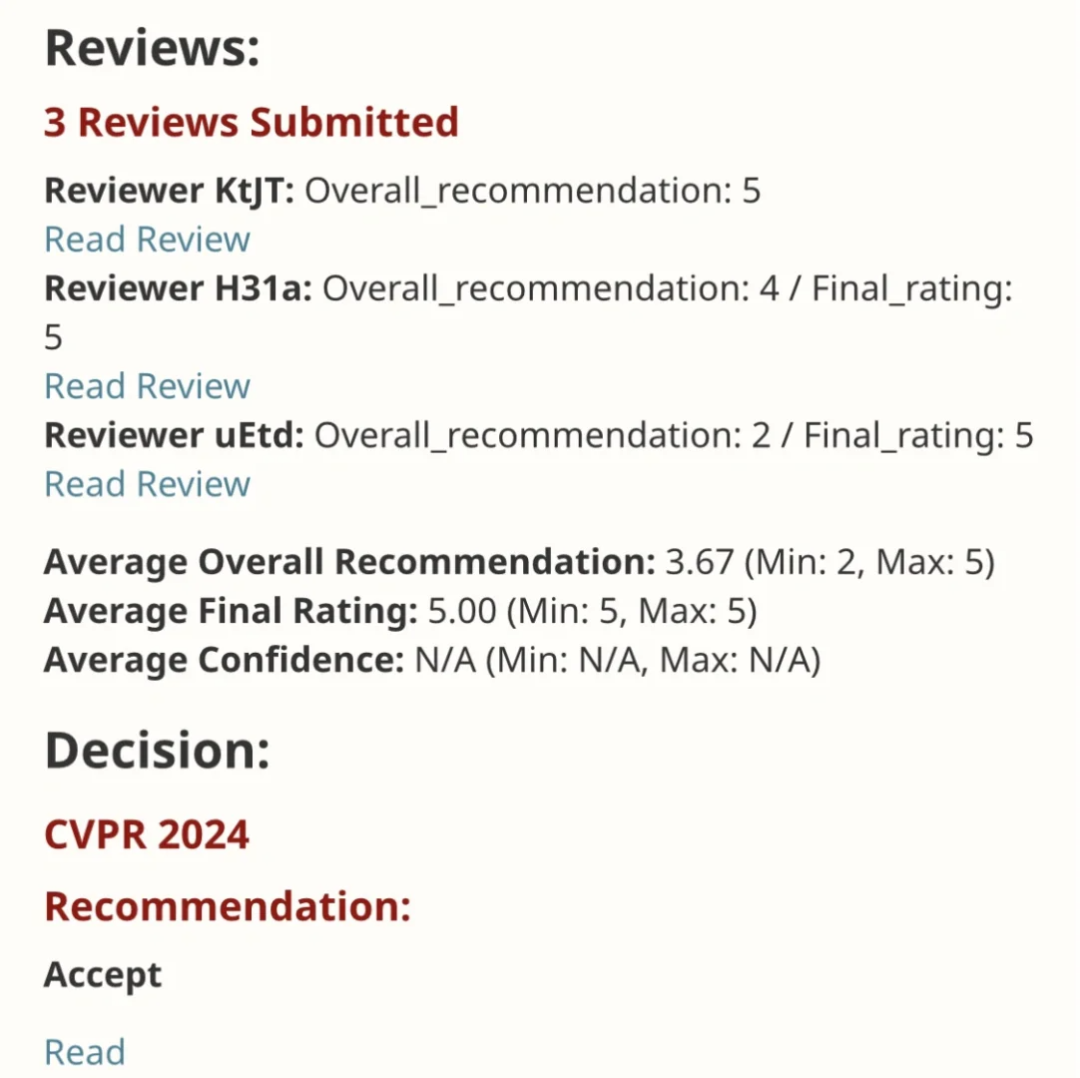
EfficientSAM 這篇工作以5/5/5滿分收錄於CVPR 2024!作者在某社群媒體上分享了這個結果,如下圖所示:
#LeCun 圖靈獎得主也強烈推薦了這項工作!

在近期的研究中,Meta 研究者提出了一種新的改進方法,即使用SAM 的掩碼圖像預訓練(SAMI)。此方法結合了 MAE 預訓練技術和 SAM 模型,旨在實現高品質的預訓練 ViT 編碼器。透過 SAMI,研究者試圖提高模型的表現和效率,為視覺任務提供更好的解決方案。這項方法的提出為進一步探索和發展電腦視覺和深度學習領域帶來了新的思路和機會。透過結合不同的預訓練技術和模型結構,研究者們不斷

#此方法降低了SAM 的複雜性,同時能夠保持良好的效能。具體來說,SAMI 利用SAM 編碼器ViT-H 生成特徵嵌入,並用輕量級編碼器訓練遮罩圖像模型,從而從SAM 的ViT-H 而不是圖像補丁重建特徵,產生的通用ViT 骨幹可用於下游任務,如影像分類、物件偵測和分割等。然後,研究者利用 SAM 解碼器對預先訓練的輕量級編碼器進行微調,以完成任何分割任務。
為了驗證這種方法的有效性,研究人員使用了掩碼影像預先訓練的遷移學習設定。具體來說,他們首先在影像解析度為224×224的ImageNet資料集上,透過重構損失對模型進行了預訓練。隨後,他們利用目標任務的監督資料對模型進行微調。這種遷移學習方法可以幫助模型在新任務上快速學習並提高效能,因為模型已經透過預訓練階段學會了從原始資料中提取特徵。這種遷移學習策略有效地利用了在大規模資料集上學到的知識,使模型更容易適應不同的任務,同時
透過SAMI 預訓練,可以在ImageNet- 1K 上訓練ViT-Tiny/-Small/-Base 等模型,並提升泛化效能。對於 ViT-Small 模型,研究者在 ImageNet-1K 上進行 100 次微調後,其 Top-1 準確率達到 82.7%,優於其他最先進的影像預訓練基線。
研究者在目標偵測、實例分割和語意分割上對預訓練模型進行了微調。在所有這些任務中,本文方法都取得了比其他預訓練基線更好的結果,更重要的是在小模型上獲得了顯著效益。
論文作者Yunyang Xiong 表示:本文提出的EfficientSAM 參數減少了20 倍,但運行時間快了20 倍,只與原始SAM 模型的差距在2 個百分點以內,大大優於MobileSAM/FastSAM。

在demo 示範中,點擊圖片中的動物,EfficientSAM 就能快速分割物件:

EfficientSAM 也能準確地標定圖片中的人:
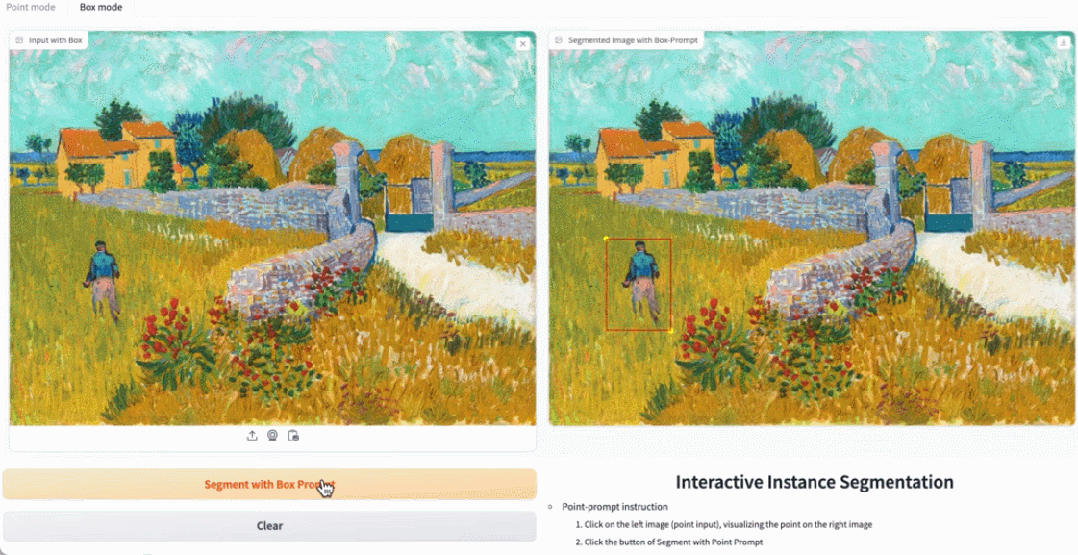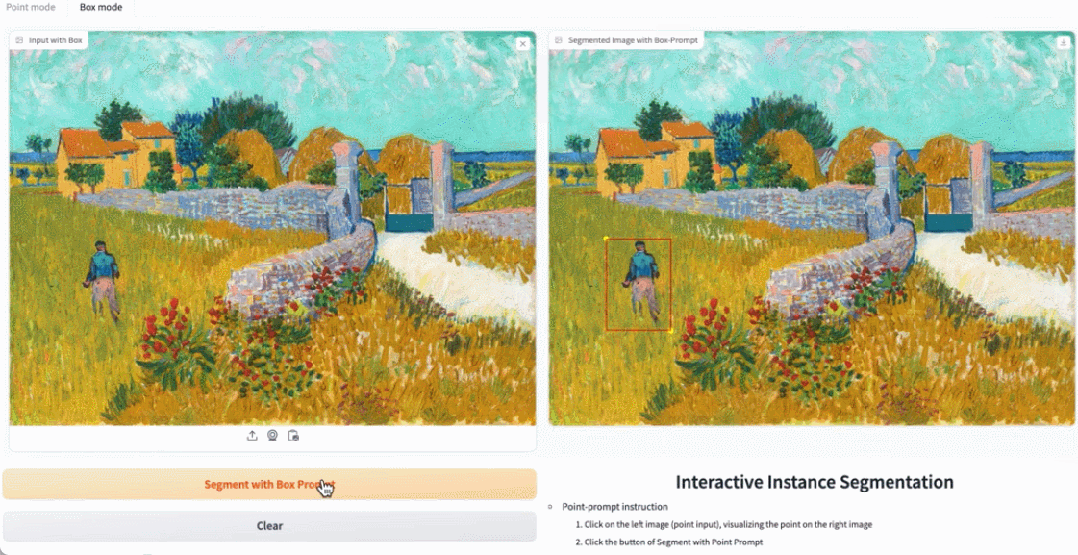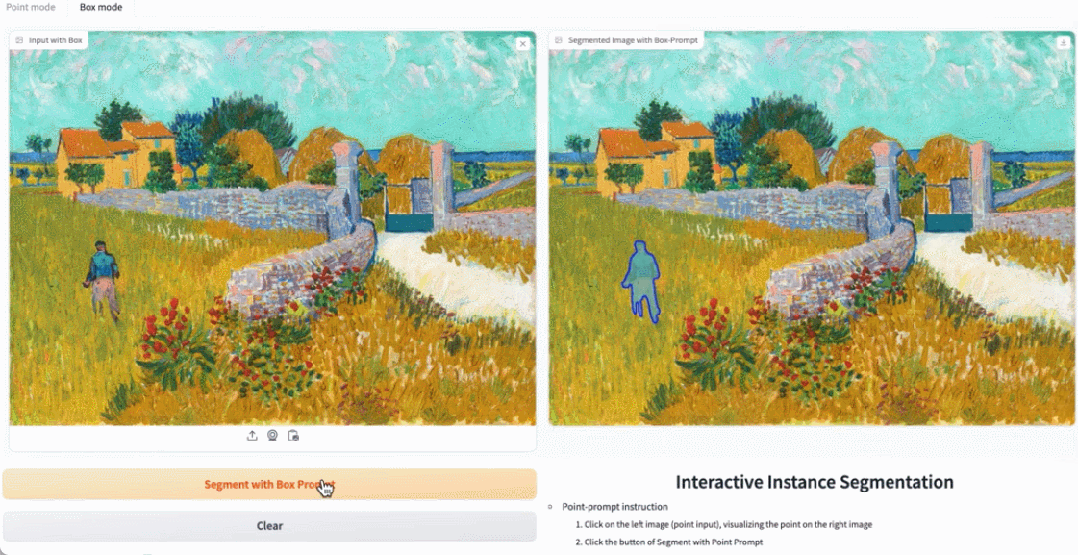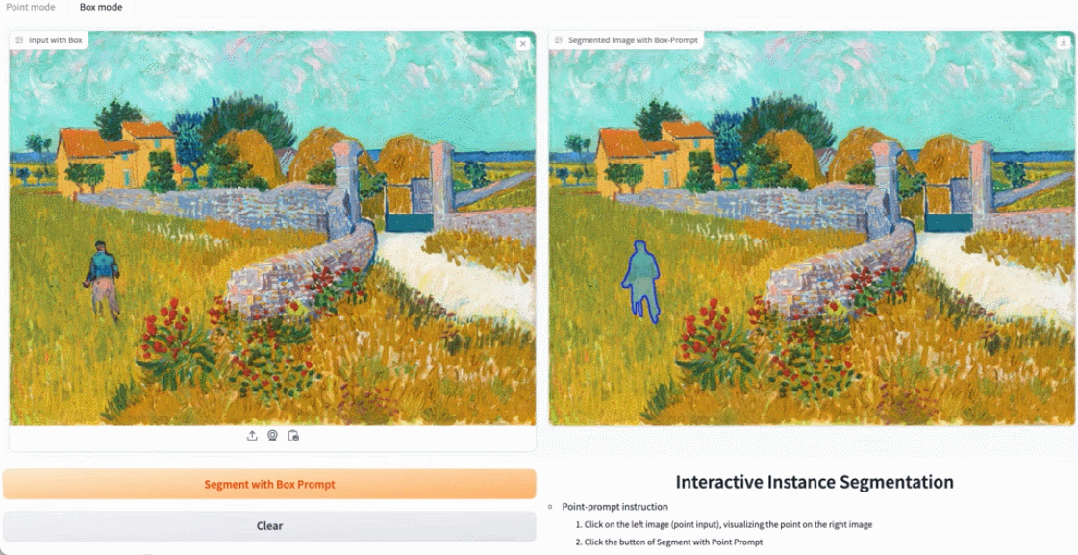
試用網址:https: //ab348ea7942fe2af48.gradio.live/
EfficientSAM 包含兩個階段:1)在ImageNet 上對SAMI 進行預訓練(上);2)在SA-1B 上微調SAM(下)。
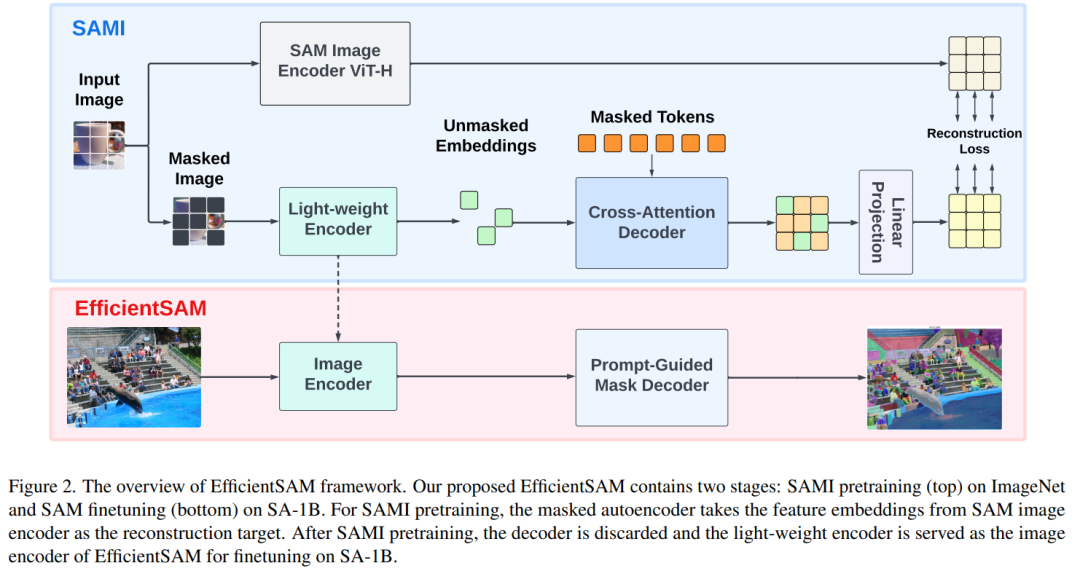
EfficientSAM 主要包含以下元件:
交叉注意力解碼器:在SAM 特徵的監督下,本文觀察到只有掩碼token 需要透過解碼器重建,而編碼器的輸出可以在重建過程中充當錨點(anchors)。在交叉注意力解碼器中,查詢來自於遮罩 token,鍵和值源自編碼器的未遮罩特徵和遮罩特徵。本文將來自交叉注意力解碼器遮罩 token 的輸出特徵和來自編碼器的未遮罩 token 的輸出特徵進行合併,以進行 MAE 輸出嵌入。然後,這些組合特徵將被重新排序到最終 MAE 輸出的輸入影像 token 的原始位置。
線性投影頭。研究者透過編碼器和交叉注意力解碼器所獲得的影像輸出,接下來將這些特徵輸入到一個小型專案頭(project head)中,以對齊 SAM 影像編碼器中的特徵。為簡單起見,本文僅使用線性投影頭來解決 SAM 影像編碼器和 MAE 輸出之間的特徵維度不匹配問題。
重建損失。在每次訓練迭代中,SAMI 包括來自 SAM 影像編碼器的前向特徵提取以及 MAE 的前向和反向傳播過程。來自 SAM 影像編碼器和 MAE 線性投影頭的輸出會進行比較,從而計算重建損失。
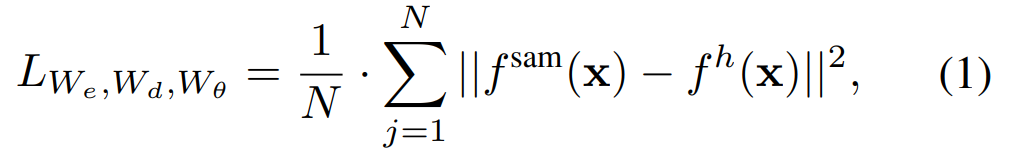
經過預訓練,編碼器可以對各種視覺任務的特徵表示進行提取,而且解碼器也會被廢棄。特別是,為了建構用於分割任何任務的高效SAM 模型,本文採用SAMI 預訓練的輕量級編碼器(例如ViT-Tiny 和ViT-Small)作為EfficientSAM 的圖像編碼器和SAM 的預設掩碼解碼器,如圖所示2(底部)。本文在 SA-1B 資料集上對 EfficientSAM 模型進行微調,以實現分割任何任務。
#圖片分類。為了評估本文方法在影像分類任務上的有效性,研究者將 SAMI 想法應用於 ViT 模型,並比較它們在 ImageNet-1K 上的表現。
如表 1 將 SAMI 與 MAE、iBOT、CAE 和 BEiT 等預訓練方法以及 DeiT 和 SSTA 等蒸餾方法進行了比較。
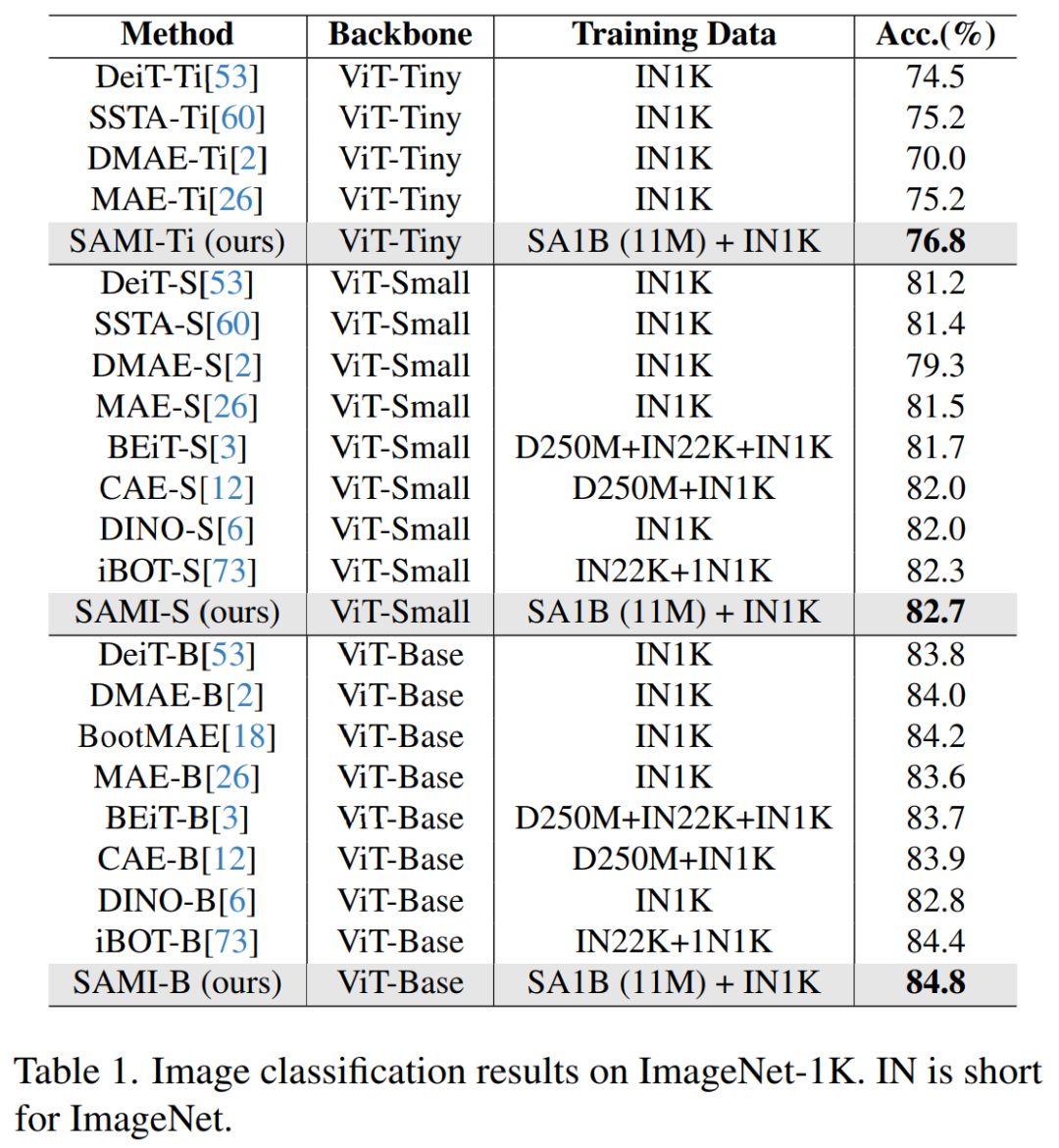
SAMI-B 的 top1 準確率達到 84.8%,比預訓練基準、MAE、DMAE、iBOT、CAE 和 BEiT 都高。與 DeiT 和 SSTA 等蒸餾方法相比,SAMI 也顯示出較大的改進。對於 ViT-Tiny 和 ViT-Small 等輕量級模型,SAMI 結果與 DeiT、SSTA、DMAE 和 MAE 相比有顯著的增益。
目標偵測與實例分割。本文也將經過 SAMI 預訓練的 ViT 主幹擴展到下游目標偵測和實例分割任務上,並將其與在 COCO 資料集上經過預訓練的基線進行比較。如表 2 所示, SAMI 始終優於其他基線的效能。
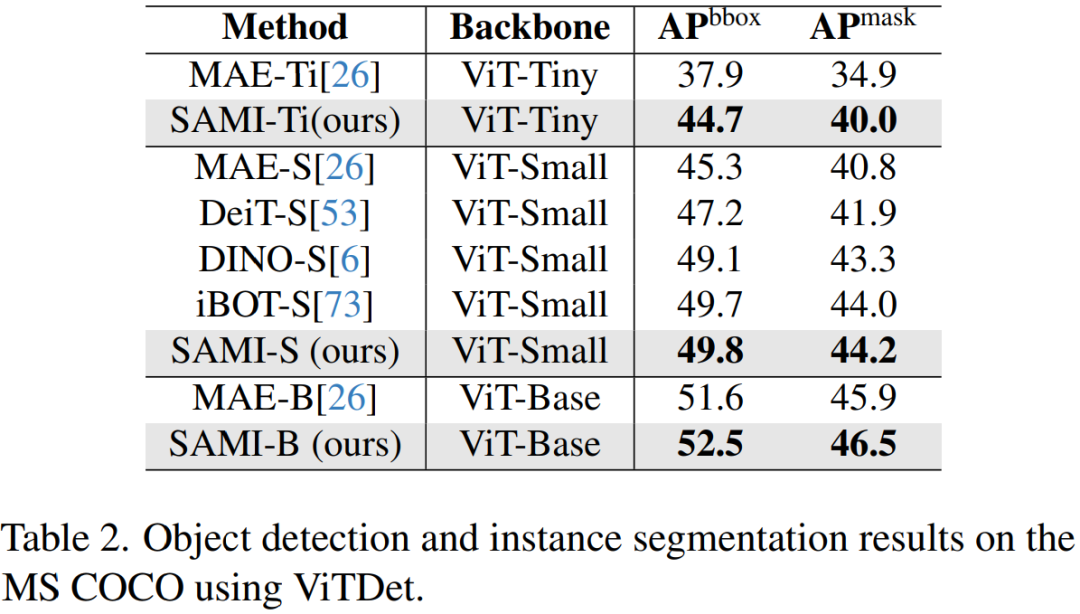
這些實驗結果表明,SAMI 在目標偵測和實例分割任務中所提供的預訓練偵測器主幹非常有效。
語意分割。本文進一步將預訓練主幹擴展到語意分割任務,以評估其有效性。結果如表 3 所示,使用 SAMI 預訓練主幹網的 Mask2former 在 ImageNet-1K 上比使用 MAE 預訓練的主幹網實現了更好的 mIoU。這些實驗結果驗證了本文提出的技術可以很好地泛化到各種下游任務。
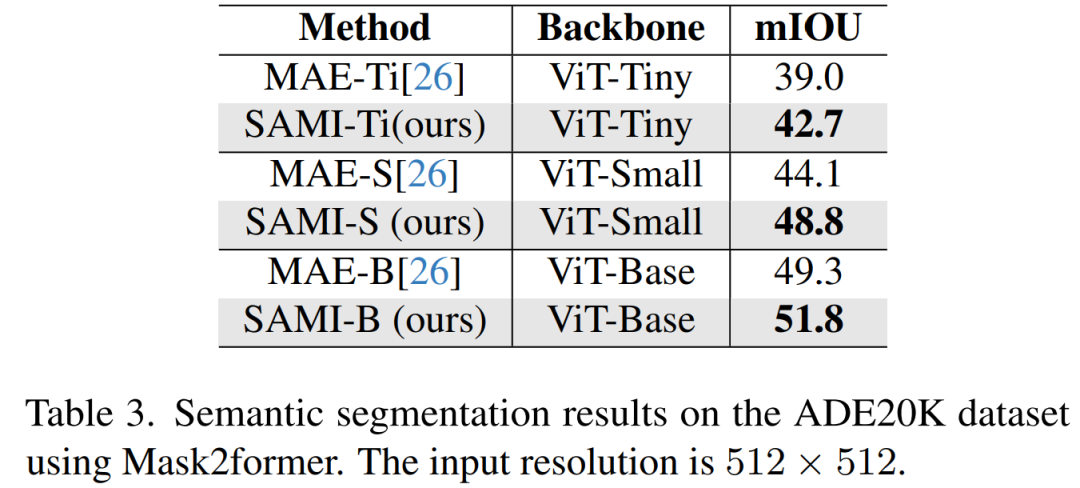
表 4 比較 EfficientSAMs 與 SAM、MobileSAM 和 SAM-MAE-Ti 進行比較。在 COCO 上,EfficientSAM-Ti 的效能優於 MobileSAM。 EfficientSAM-Ti 具有 SAMI 預訓練權重,也比 MAE 預訓練權重表現更好。
#此外, EfficientSAM-S 在 COCO box 僅比 SAM 低 1.5 mIoU,在 LVIS box 上比 SAM 低 3.5 mIoU,參數減少了 20 倍。本文也發現,與 MobileSAM 和 SAM-MAE-Ti 相比,EfficientSAM 在多次點擊(multiple click)方面也展現了良好的效能。
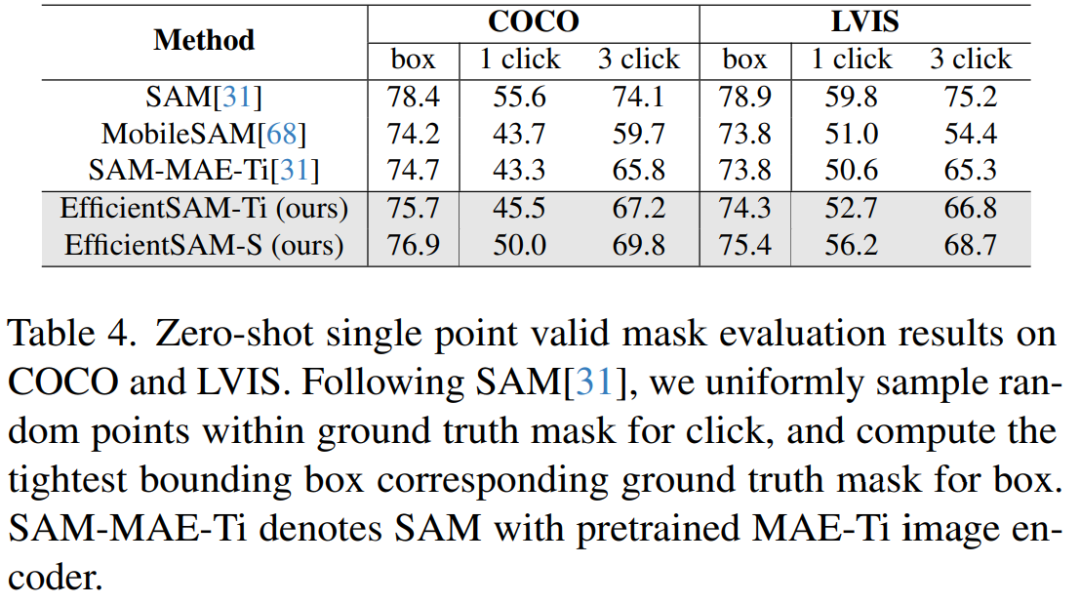
表 5 展示了零樣本實例分割的 AP、APS、APM 和 APL。研究者將 EfficientSAM 與 MobileSAM 和 FastSAM 進行了比較,可以看到,與 FastSAM 相比,EfficientSAM-S 在 COCO 上獲得了超過 6.5 個 AP,在 LVIS 上獲得了 7.8 個 AP。就 EffidientSAM-Ti 而言,仍然遠遠優於 FastSAM,在 COCO 上為 4.1 個 AP,在 LVIS 上為 5.3 個 AP,而 MobileSAM 在 COCO 上為 3.6 個 AP,在 LVIS 上為 5.5 個 AP。
而且,EfficientSAM 比 FastSAM 輕得多,efficientSAM-Ti 的參數為 9.8M,而 FastSAM 的參數為 68M。
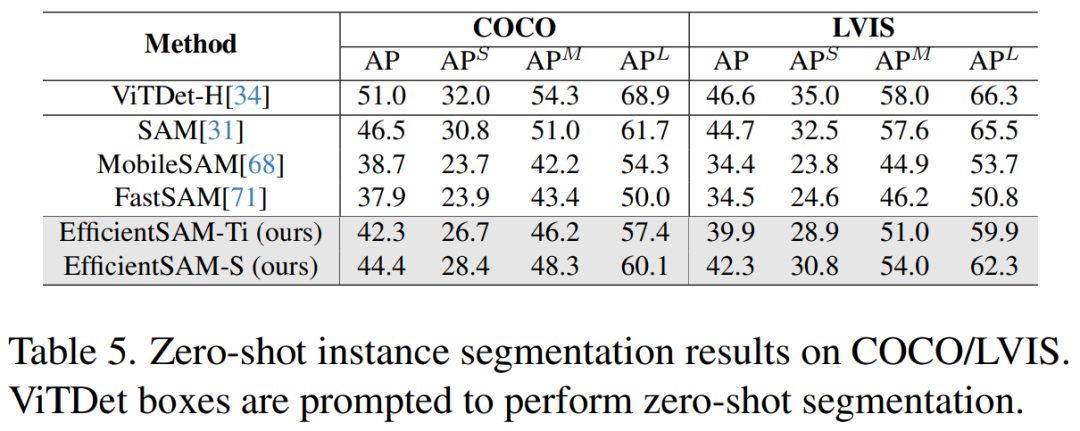
圖 3、4、5 提供了一些定性結果,以便讀者對 EfficientSAMs 的實例分割能力有一個補充性了解。



以上是VPR 2024 滿分論文! Meta提出EfficientSAM:快速分割一切!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















