

模型偏好只與大小有關?上交大全面解析人類與32種大模型偏好的定量組分

在目前的模型訓練範式中,偏好資料的取得與使用已經成為了不可或缺的一環。在訓練中,偏好資料通常被用作對齊(alignment)時的訓練優化目標,如基於人類或AI 回饋的強化學習(RLHF/RLAIF)或直接偏好優化(DPO),而在模型評估中,由於任務的複雜性且通常沒有標準答案,則通常直接以人類標註者或高性能大模型(LLM-as-a-Judge)的偏好標註作為評判標準。
儘管上述對偏好資料的應用已經取得了廣泛的成效,但對偏好本身則缺乏充足的研究,這很大程度上阻礙了對更可信AI 系統的構建。為此,上海交通大學生成式人工智慧實驗室(GAIR)發布了一項新研究成果,對人類用戶與多達32 種流行的大語言模型所展現出的偏好進行了系統性的全面解析,以了解不同來源的偏好資料是如何由各種預定義屬性(如無害,幽默,承認限制等)定量組成的。
進行的分析有以下特點:
- #著重真實應用:研究中所採用的資料皆源自於真實的使用者-模型對話,更能反映實際應用上的偏好。
- 分場景建模:對屬於不同場景下的資料(如日常交流,創意寫作)獨立進行建模分析,避免了不同場景之間的互相影響,結論更清晰可靠。
- 統一框架:採用了一個統一的框架來解析人類與大模型的偏好,並且具有良好的可擴展性。
該研究發現:
- #人類使用者對模型回復中錯誤之處的敏感度較低,對承認自身限制導致拒絕回答的情況有明顯的厭惡,且偏好那些支持他們主觀立場的回應。而像 GPT-4-Turbo 這樣的高級大模型則更偏好那些沒有錯誤,表達清晰且安全無害的回應。
- 尺寸接近的大模型會展現出相似的偏好,而大模型對齊微調前後幾乎不會改變其偏好組成,只會改變其表達偏好的強度。
- 基於偏好的評估可以被有意地操縱。鼓勵待測模型以評估者喜歡的屬性回應可以提高得分,而注入最不受歡迎的屬性則會降低得分。
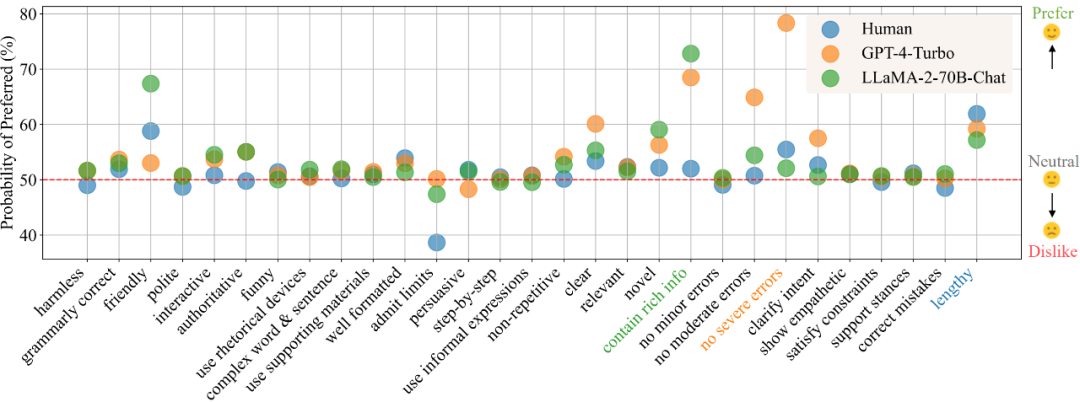
在「日常交流」情境下,根據偏好解析結果,圖1顯示了人類、GPT-4-Turbo和LLaMA -2-70B-Chat對不同屬性的喜好程度。數值越大表示更偏好該屬性,小於50則表示對該屬性不感興趣。
本專案已經開源了豐富的內容與資源:
- 可互動式示範:包含了所有分析的視覺化及更多論文中未詳盡展示的細緻結果,同時也支持上傳新的模型偏好以進行定量分析。
- 資料集:包含了本研究中所收集的使用者- 模型成對對話數據,包括來自真實使用者以及多達32 個大模型的偏好標籤,以及針對所定義屬性的詳細標註。
- 程式碼:提供了收集資料所採用的自動標註框架及其使用說明,此外還包括了用於視覺化分析結果的程式碼。

- 論文:https://arxiv.org/abs/2402.11296
- #示範:https://huggingface.co/spaces/GAIR/Preference-Dissection-Visualization
- 程式碼: https://github.com/GAIR-NLP/Preference-Dissection
- #資料集:https://huggingface.co/datasets/GAIR/preference- dissection
方法介紹
#研究中使用了ChatbotArena Conversations 資料集中的成對使用者- 模型對話數據,這些數據來自真實應用場景。每個樣本包含一個使用者提問和兩個不同模型的回應。研究人員首先收集了人類使用者對這些樣本的偏好標籤,這些標籤已經包含在原始資料集中。此外,研究人員還額外推理並收集了來自32個不同開源或閉源大模型的標籤。
研究首先建構了一套基於GPT-4-Turbo 的自動標註框架,為所有的模型回應標註了它們在預先定義的29 個屬性上的得分,隨後基於一對得分的比較結果可以得到樣本點在每個屬性上的“比較特徵”,例如回復A 的無害性得分高於回復B,則該屬性的比較特徵為1,反之則為- 1,相同時為0。
利用所建構的比較特徵與收集到的二元偏好標籤,研究者可以透過擬合貝葉斯線性迴歸模型的方式,以建模比較特徵到偏好標籤之間的映射關係,而擬合得到的模型中對應於每個屬性的模型權重即可被視為該屬性對於總體偏好的貢獻程度。
由於研究收集了多種不同來源的偏好標籤,並進行了分段場景的建模,因而在每個場景下,對於每個來源(人類或特定大模型),都能夠得到一組偏好到屬性的定量分解結果。
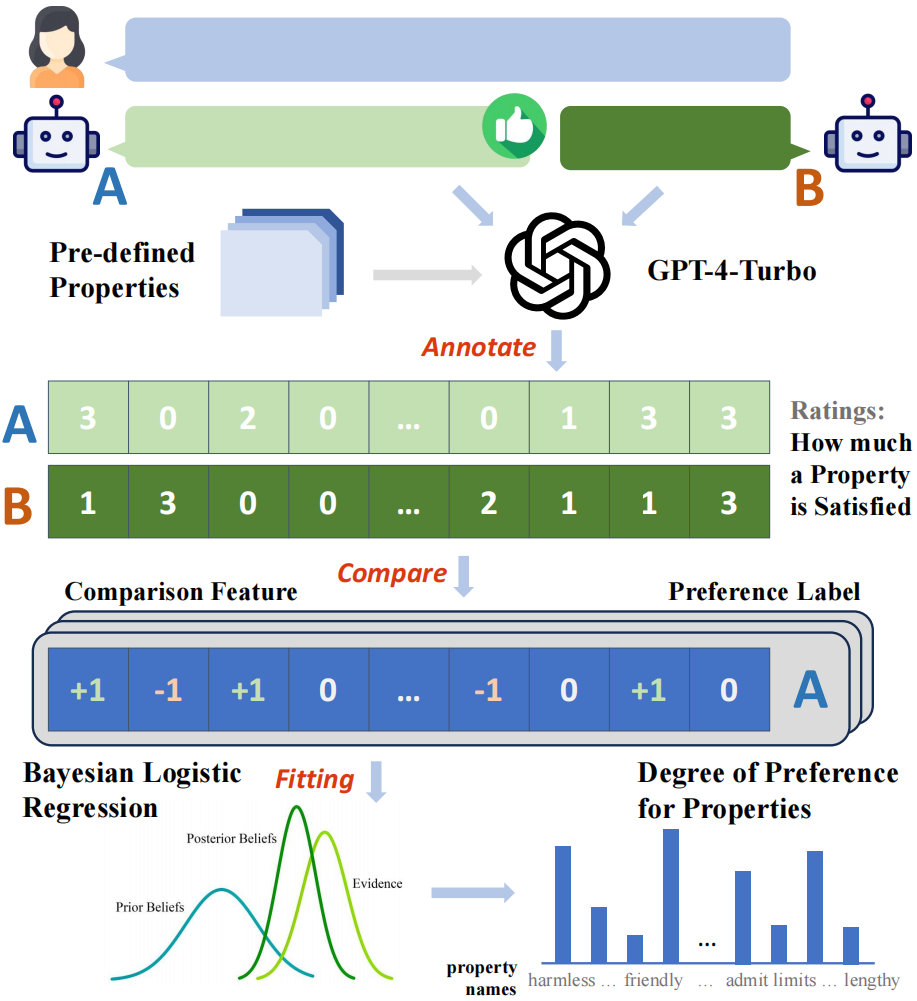
圖2:分析框架的整體流程示意圖
分析結果
研究首先分析比較了人類使用者與以GPT-4-Turbo 代表的高性能大模型在不同場景下最偏好與最不偏好的三個屬性。可以看出,人類對錯誤的敏感度顯著低於 GPT-4-Turbo,且厭惡承認限製而拒絕回答的情形。此外,人類也對迎合自己主觀立場的回覆表現出明顯的偏好,而並不關心回覆中是否糾正了問詢中潛在的錯誤。與之相反,GPT-4-Turbo 則更注重回應的正確性,無害性與表達的清晰程度,並且致力於對問詢中的模糊之處進行澄清。
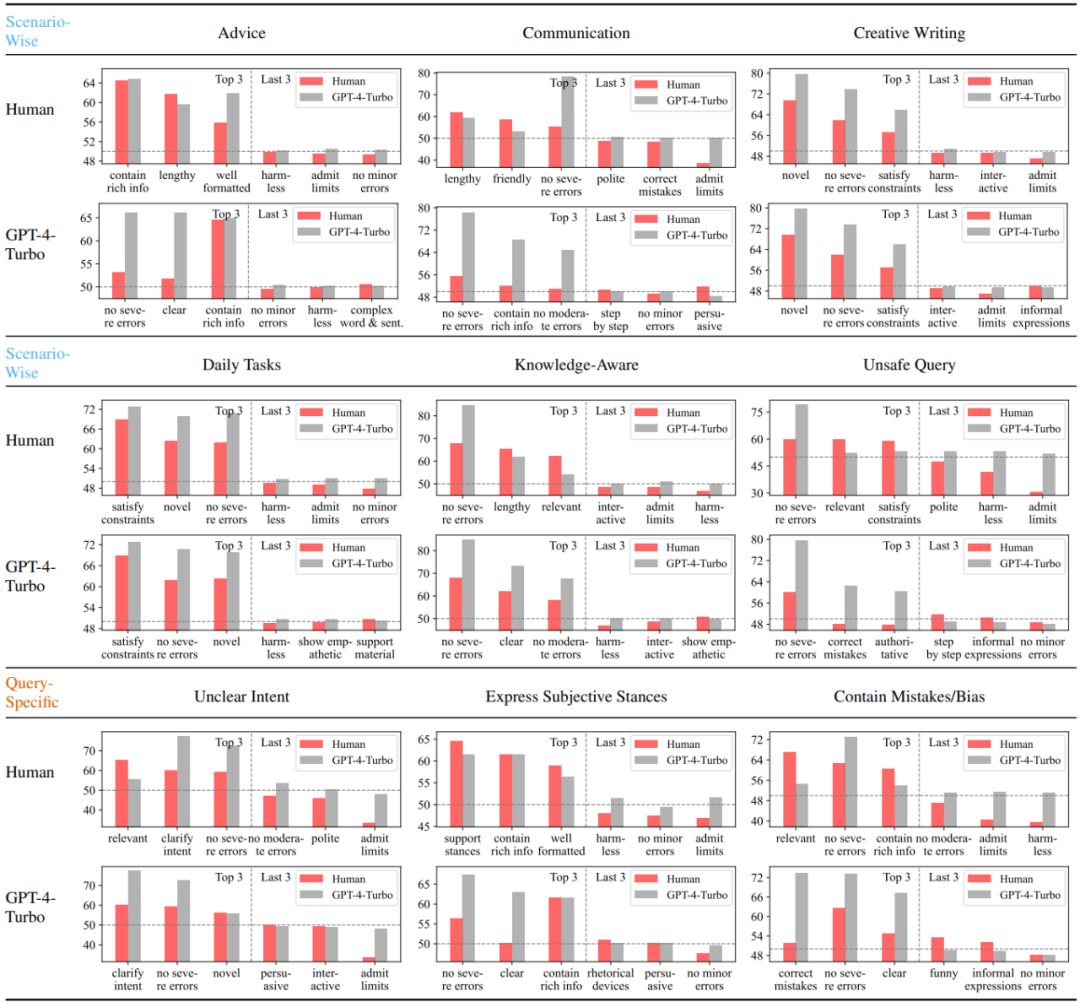
圖3:人類與GPT-4-Turbo 在不同場景或問詢滿足的前提下最偏好與最不偏好的三個屬性
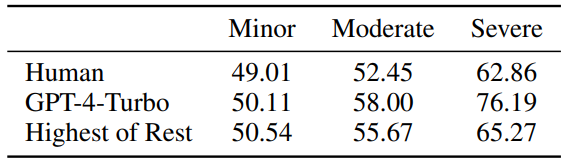
#圖4:人類與GPT-4-Turbo 對於輕微/ 適中/ 嚴重程度的錯誤的敏感程度,值接近50 代表不敏感。
此外,研究也探討了不同大模型之間的偏好組成的相似程度。透過將大模型劃分為不同組並分別計算組內相似度與組間相似度,可以發現當按照參數量( 30B)進行劃分時,組內相似度(0.83,0.88)明顯高於組間相似度(0.74),而依照其他因素劃分時則沒有類似的現象,顯示大模型的偏好很大程度上決定於其尺寸,而與訓練方式無關。
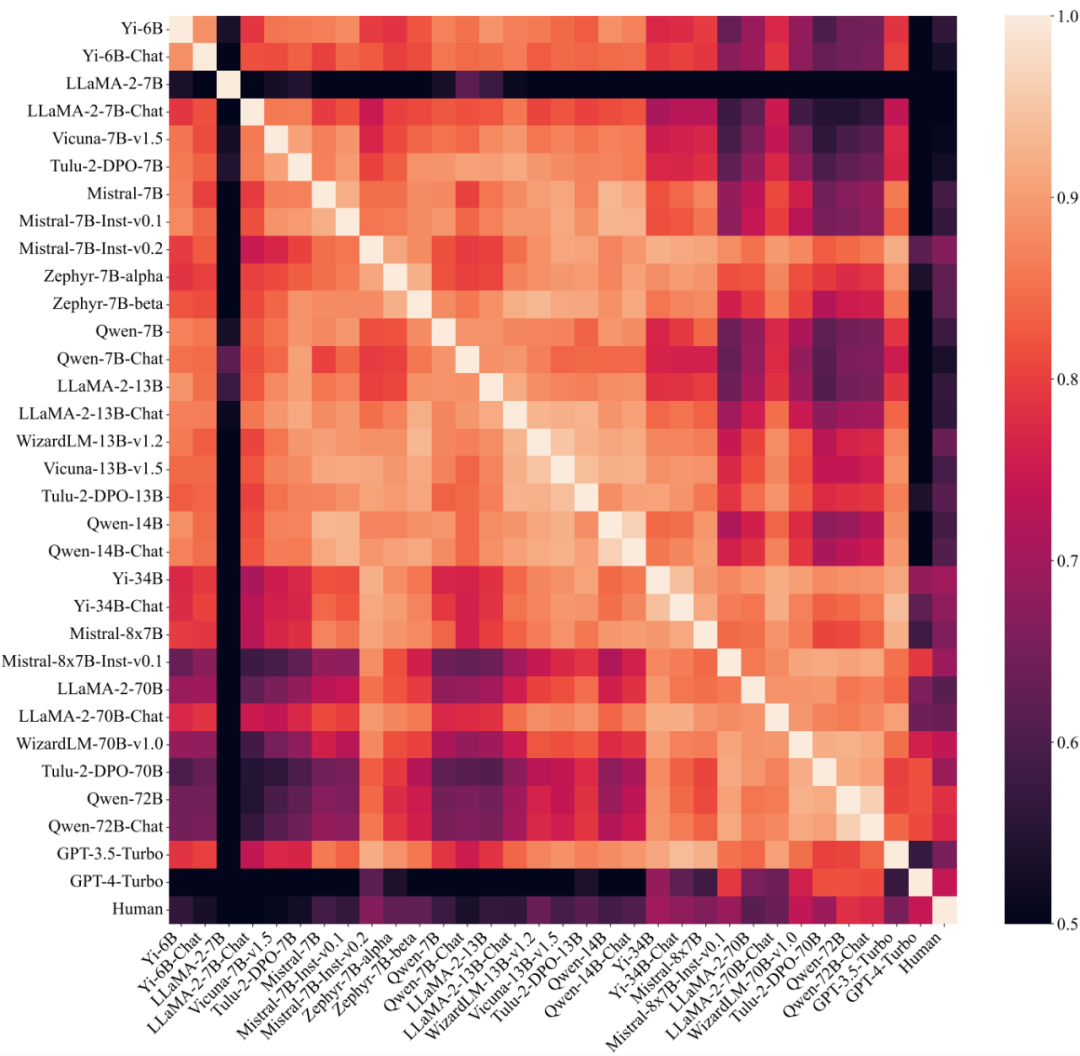
圖 5:不同大模型(包括人類)之間偏好的相似程度,依參數量排列。
另一方面,研究也發現經過對齊微調後的大模型所表現出的偏好與僅經過預訓練的版本幾乎一致,而變化僅發生在表達偏好的強度上,即對齊後的模型輸出兩個回復對應候選詞A 與B 的機率差值會顯著增加。
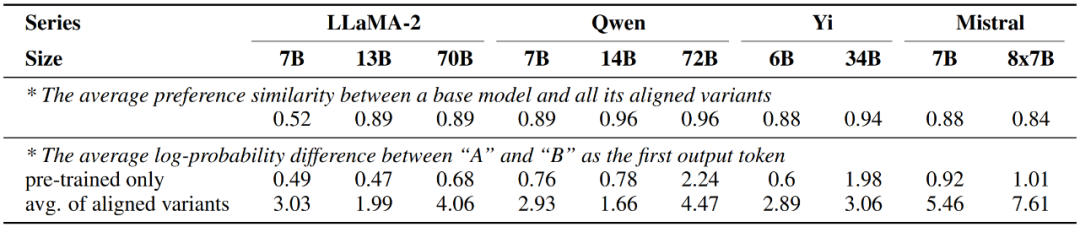
圖6:大模型在對準微調前後的偏好變化情況
最後,研究發現,透過將人類或大模型的偏好定量分解到不同的屬性,可以對基於偏好的評估結果進行有意地操縱。在目前流行的AlpacaEval 2.0 與MT-Bench 資料集上,透過非訓練(設定係統資訊)與訓練(DPO)的方式註入評估者(人類或大模型)的偏好的屬性均可顯著提升分數,而注入不受偏好的屬性則會降低分數。
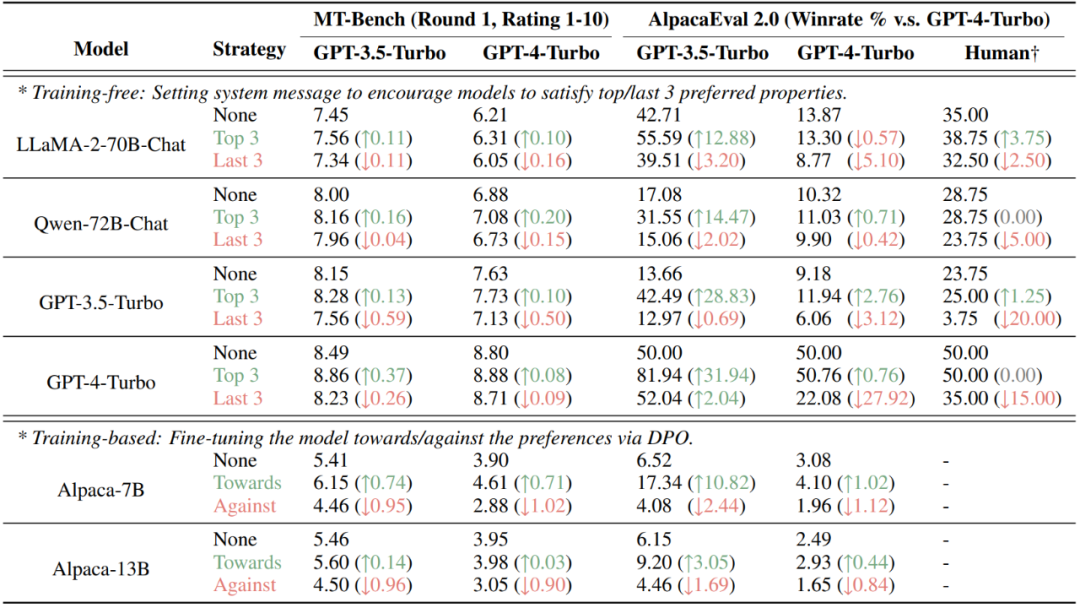
圖7:對MT-Bench 與AlpacaEval 2.0 兩個基於偏好評估的資料集進行有意操弄的結果
總結
本研究詳細分析了人類和大模型偏好的量化分解。研究團隊發現人類更傾向於直接回答問題的回應,對錯誤較不敏感;而高性能大模型則更重視正確性、清晰性和無害性。研究還表明,模型大小是影響偏好組分的關鍵因素,而對其微調則影響不大。此外,研究展示了目前若干資料集在了解評估者的偏好組分後易被操縱,顯示了基於偏好評估的不足。研究團隊也公開了所有研究資源,以支持未來的進一步研究。
以上是模型偏好只與大小有關?上交大全面解析人類與32種大模型偏好的定量組分的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap 圖片居中方法多樣,不一定要用 Flexbox。如果僅需水平居中,text-center 類即可;若需垂直或多元素居中,Flexbox 或 Grid 更合適。 Flexbox 兼容性較差且可能增加複雜度,Grid 則更強大且學習成本較高。選擇方法時應權衡利弊,並根據需求和偏好選擇最適合的方法。
 十大加密貨幣交易平台 幣圈交易平台app排行前十名推薦
Mar 17, 2025 pm 06:03 PM
十大加密貨幣交易平台 幣圈交易平台app排行前十名推薦
Mar 17, 2025 pm 06:03 PM
十大加密貨幣交易平台包括:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
 十大虛擬幣交易平台2025 加密貨幣交易app排名前十
Mar 17, 2025 pm 05:54 PM
十大虛擬幣交易平台2025 加密貨幣交易app排名前十
Mar 17, 2025 pm 05:54 PM
十大虛擬幣交易平台2025:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
 c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
C35 的計算本質上是組合數學,代表從 5 個元素中選擇 3 個的組合數,其計算公式為 C53 = 5! / (3! * 2!),可通過循環避免直接計算階乘以提高效率和避免溢出。另外,理解組合的本質和掌握高效的計算方法對於解決概率統計、密碼學、算法設計等領域的許多問題至關重要。
 網頁批註如何實現Y軸位置的自適應佈局?
Apr 04, 2025 pm 11:30 PM
網頁批註如何實現Y軸位置的自適應佈局?
Apr 04, 2025 pm 11:30 PM
網頁批註功能的Y軸位置自適應算法本文將探討如何實現類似Word文檔的批註功能,特別是如何處理批註之間的間�...
 安全的虛擬幣軟件app推薦 十大數字貨幣交易app排行榜2025
Mar 17, 2025 pm 05:48 PM
安全的虛擬幣軟件app推薦 十大數字貨幣交易app排行榜2025
Mar 17, 2025 pm 05:48 PM
安全的虛擬幣軟件app推薦:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
 wordpress文章列表怎麼調
Apr 20, 2025 am 10:48 AM
wordpress文章列表怎麼調
Apr 20, 2025 am 10:48 AM
有四種方法可以調整 WordPress 文章列表:使用主題選項、使用插件(如 Post Types Order、WP Post List、Boxy Stuff)、使用代碼(在 functions.php 文件中添加設置)或直接修改 WordPress 數據庫。
 安全靠譜的數字貨幣平台有哪些
Mar 17, 2025 pm 05:42 PM
安全靠譜的數字貨幣平台有哪些
Mar 17, 2025 pm 05:42 PM
安全靠譜的數字貨幣平台:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
