清華、哈工大把大模型壓縮到了1bit,把大模型放在手機裡跑的願望就快要實現了!

自從大模型火爆出圈後,人們對壓縮大模型的願望從未消減。這是因為,雖然大模型在許多方面表現出優秀的能力,但高昂的部署代價極大地提升了它的使用門檻。這種代價主要來自於空間佔用和計算量。 「模型量化」 透過把大模型的參數轉換成低位寬的表示,進而節省空間佔用。目前,主流方法可以在幾乎不損失模型效能的情況下將已有模型壓縮至 4bit。然而,低於 3bit 的量化像一堵不可逾越的高牆,讓研究人員望而生畏。
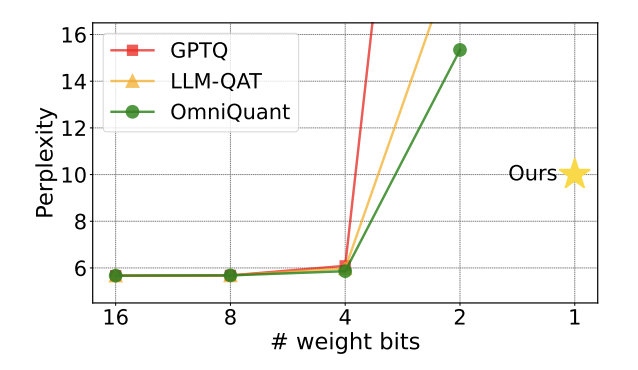
圖1 : 量化模型的困惑度在2bit 時迅速上升
## 近期,一篇由清華大學、哈爾濱工業大學合作發表在arXiv 上的論文為突破這一阻礙帶來了希望,在國內外學術圈引起了不小的關注。這篇論文也在一週前登上 huggingface 的熱點論文,並被著名論文推薦師 AK 推薦。 研究團隊直接越過 2bit 這個量化級別,大膽地進行了 1bit 量化的嘗試,這在模型量化的研究中尚屬首次。

論文標題:OneBit: Towards Extremely Low-bit Large Language Models
##論文地址:https ://arxiv.org/pdf/2402.11295.pdf作者提出的方法稱為“OneBit”,非常貼切地形容了這項工作的本質:
把預訓練大模型壓縮到真正的1bit。論文提出了模型參數 1bit 表示的新方法,以及量化模型參數的初始化方法,並透過量化感知訓練(QAT)把高精度預訓練模型的能力遷移至 1bit 量化模型。實驗表明,此方法能夠在極大幅度壓縮模型參數的同時,確保 LLaMA 模型至少 83% 的性能。
作者指出,當模型參數壓縮到1bit 後,矩陣乘法中的「元素乘」將不復存在,取而代之的是更快速的「位元賦值」操作,這將大大提升計算效率。這項研究的重要意義在於,它不僅跨越了 2bit 量化的鴻溝,也使在 PC 和智慧型手機上部署大模型成為可能。已有工作的限制
模型量化主要透過將模型的nn.Linear 層(Embedding 層和Lm_head 層除外)轉化為低精度表示實現空間壓縮。先前工作 [1,2] 的基礎是利用 Round-To-Nearest(RTN)方法把高精度浮點數近似映射到附近的整數網格。這可以被表示成
。 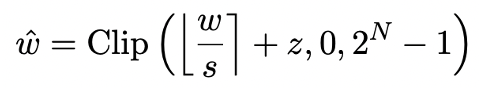
此外,先前的研究中也曾對 1bit 模型可能採用什麼結構進行過探索。幾個月前的工作 BitNet [3] 透過讓模型參數通過 Sign (・) 函數並轉換為 1/-1 來實現 1bit 表示。但這方法存在著性能損失嚴重、訓練過程不穩定的問題,限制了其實際應用。
OneBit 框架
OneBit 的方法框架包括全新的1bit 層結構、基於SVID 的參數初始化方法和基於量化感知知識蒸餾的知識遷移。
1. 新的 1bit 結構
OneBit 的終極目標是將LLMs 的權重矩陣壓縮到1bit。真正的 1bit 要求每個權重值只能用 1bit 表示,即只有兩種可能的狀態。作者認為,在大模型的參數中,有兩個重要因素都必須考慮進來,那就是浮點數的高精度和參數矩陣的高秩。因此,作者引入兩個 FP16 格式的值向量以補償由於量化而導致的精度損失。這種設計不僅保持了原始權重矩陣的高秩,而且透過值向量提供了必要的浮點精確度,有助於模型的訓練和知識遷移。 1bit 線性層的結構與FP16 高精度線性層的結構比較如下圖: 圖3 : FP16 線性層與OneBit 線性層的對比 左側的(a) 是FP16 精度模型結構,右邊的(b) 是OneBit 框架的線性層。可見,在 OneBit 框架中,只有值向量 g 和 h 保持 FP16 格式,而權重矩陣則全部由 ±1 組成。這樣的結構兼顧了精準度和秩,對保證穩定且高品質的學習過程很有意義。 OneBit 對模型的壓縮幅度究竟如何?作者在論文中給了一個計算。假設對一個 4096*4096 的線性層進行壓縮,那麼 OneBit 需要一個 4096*4096 的 1bit 矩陣,和兩個 4096*1 的 16bit 值向量。這裡面總的位數為 16,908,288,總的參數個數為 16,785,408,平均每個參數佔用僅約 1.0073 個 bit。這樣的壓縮幅度是空前的,可以說是真正的 1bit 大模型。 2. 基於SVID 初始化量化模型 為了使用充分訓練好的原始模型更好地初始化量化後的模型,進而促進更好的知識遷移效果,作者提出一種新的參數矩陣分解方法,稱為「值- 符號獨立的矩陣分解(SVID)」。這個矩陣分解方法把符號和絕對值分開,並且把絕對值進行秩- 1 近似,其逼近原矩陣參數的方式可以表示成: 這裡的秩- 1 近似可以透過常見的矩陣分解方式來實現,例如奇異值分解(SVD)和非負矩陣分解(NMF)。而後,作者在數學上給出這種 SVID 方法可以透過交換運算次序來和 1bit 模型框架相匹配,進而實現參數初始化。並且,論文也證明了符號矩陣在分解過程中確實扮演了近似原矩陣的作用。 3. 透過知識蒸餾遷移原模型能力 #作者指出,解決大模型超低位寬量化的有效途徑可能是量化感知訓練QAT。在 OneBit 模型結構下,透過知識蒸餾從未量化模型中學習,實現能力向量化模型的遷移。具體地,學生模型主要接受教師模式 logits 和 hidden state 的指導。 #
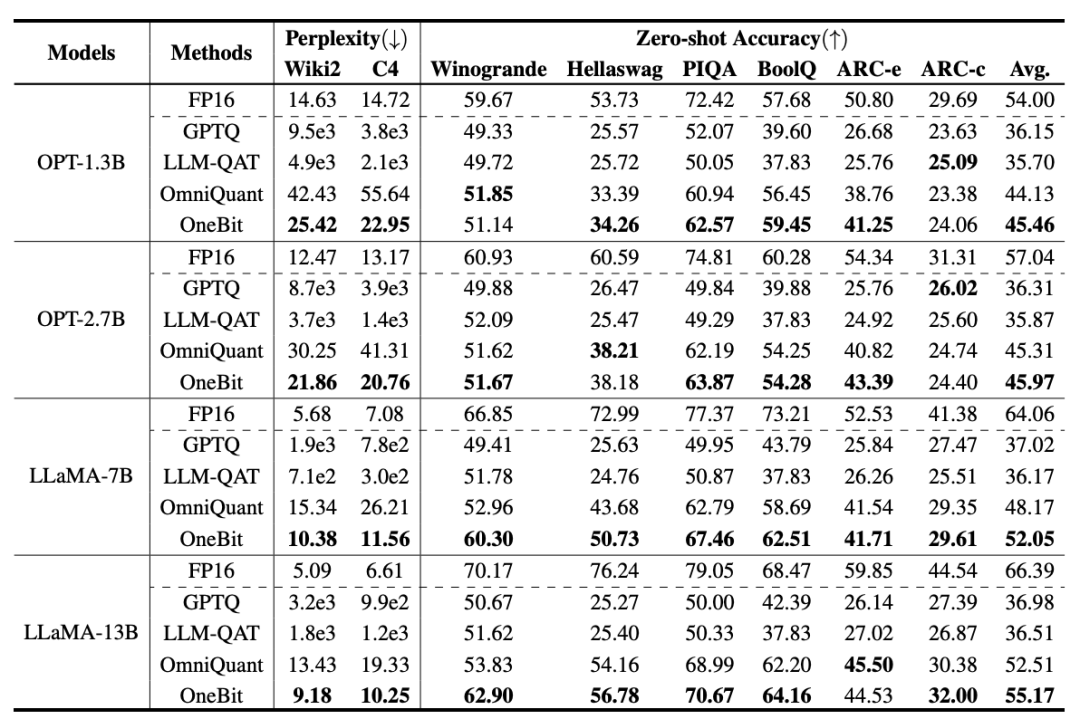
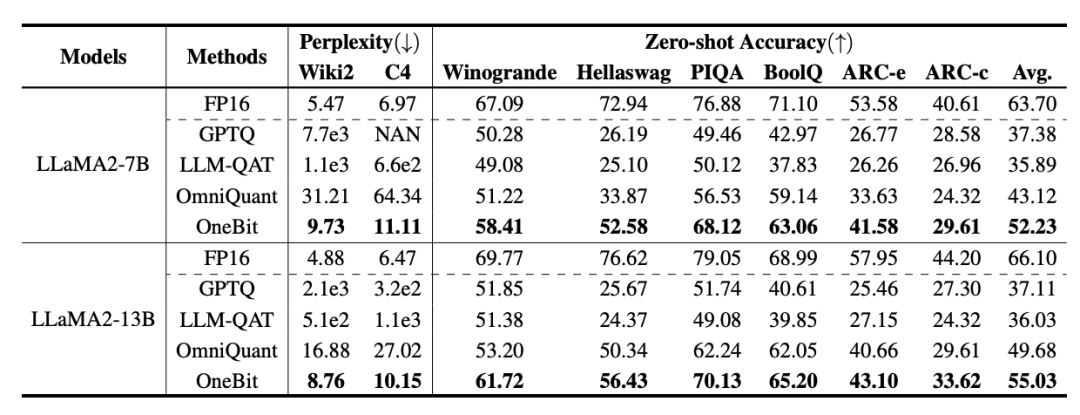
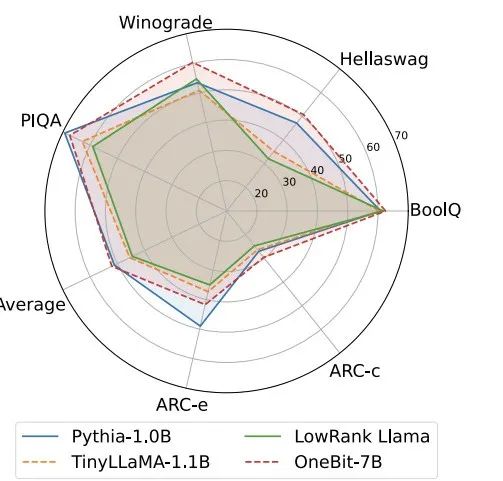
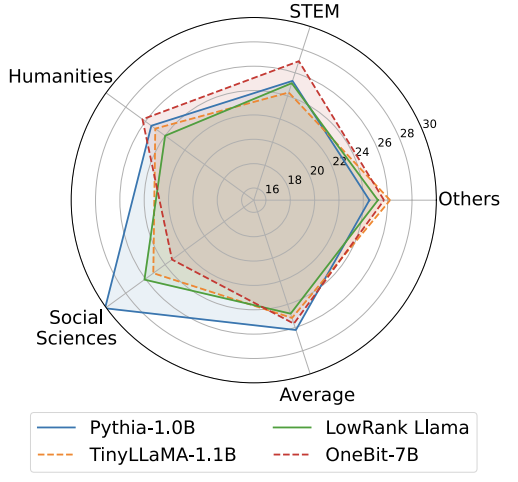
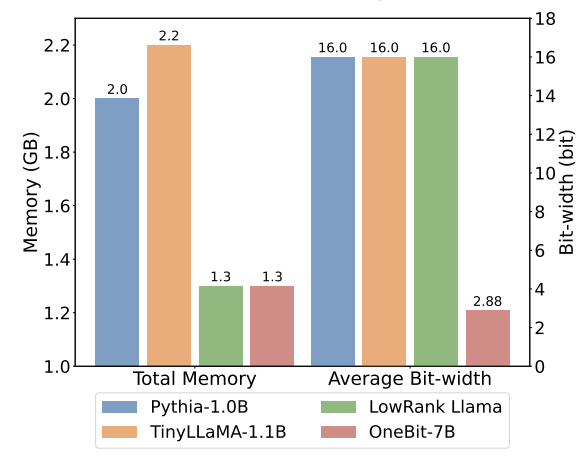
##訓練時,值向量和矩陣的值會被更新。模型量化完成後,直接把 Sign (・) 後的參數保存下來,在推理和部署時直接使用。 表1 : OneBit 與基準方法的效果比較(OPT 模型與LLaMA-1 模型) 表2 : OneBit 與基準方法的效果比較(LLaMA-2 模型) 表1 和表2 展示了OneBit 相比於其他方法在1bit 量化時的優勢。就量化模型在驗證集的困惑度而言,OneBit 與 FP16 模型最為接近。就 Zero-shot 準確度而言,除 OPT 模型的個別資料集外,OneBit 量化模型幾乎取得了最佳的效能。其餘的 2bit 量化方法在兩種評估指標上呈現較大的損失。 值得注意的是,OneBit 在模型越大時,效果往往越好。也就是說,隨著模型規模增大,FP16 精度模型在困惑度降低上收效甚微,但 OneBit 卻表現出更多的困惑度下降。此外,作者也指出量化感知訓練對於超低位寬量化或許十分必要。 圖4 : 常識推理任務比較 ##圖5 : 世界知識比較 圖6 : 幾種模型的空間佔用和平均位寬 圖4 - 圖6 也比較了幾類小模型的空間佔用和表現損失,它們是透過不同的途徑獲得的:包括兩個充分訓練的模型Pythia-1.0B 和TinyLLaMA-1.1B,以及透過低秩分解所得的LowRank Llama 和OneBit-7B。可以看出,儘管 OneBit-7B 有最小的平均位寬、佔用最小的空間,但它在常識推理能力上仍然優於不遜於其他模型。作者同時指出,模型在社會科學領域面臨較嚴重的知識遺忘。總的來說,OneBit-7B 展示了其實際應用價值。如圖 7 所展示的,OneBit 量化後的 LLaMA-7B 模型經過指令微調後,展現了流暢的文字產生能力。 圖7 : OneBit 框架量化後的LLaMA-7B 模型的能力 1. 效率
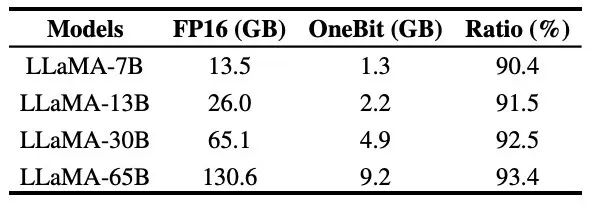
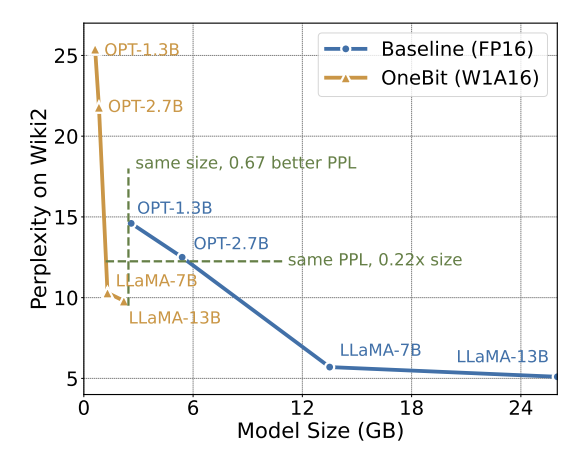
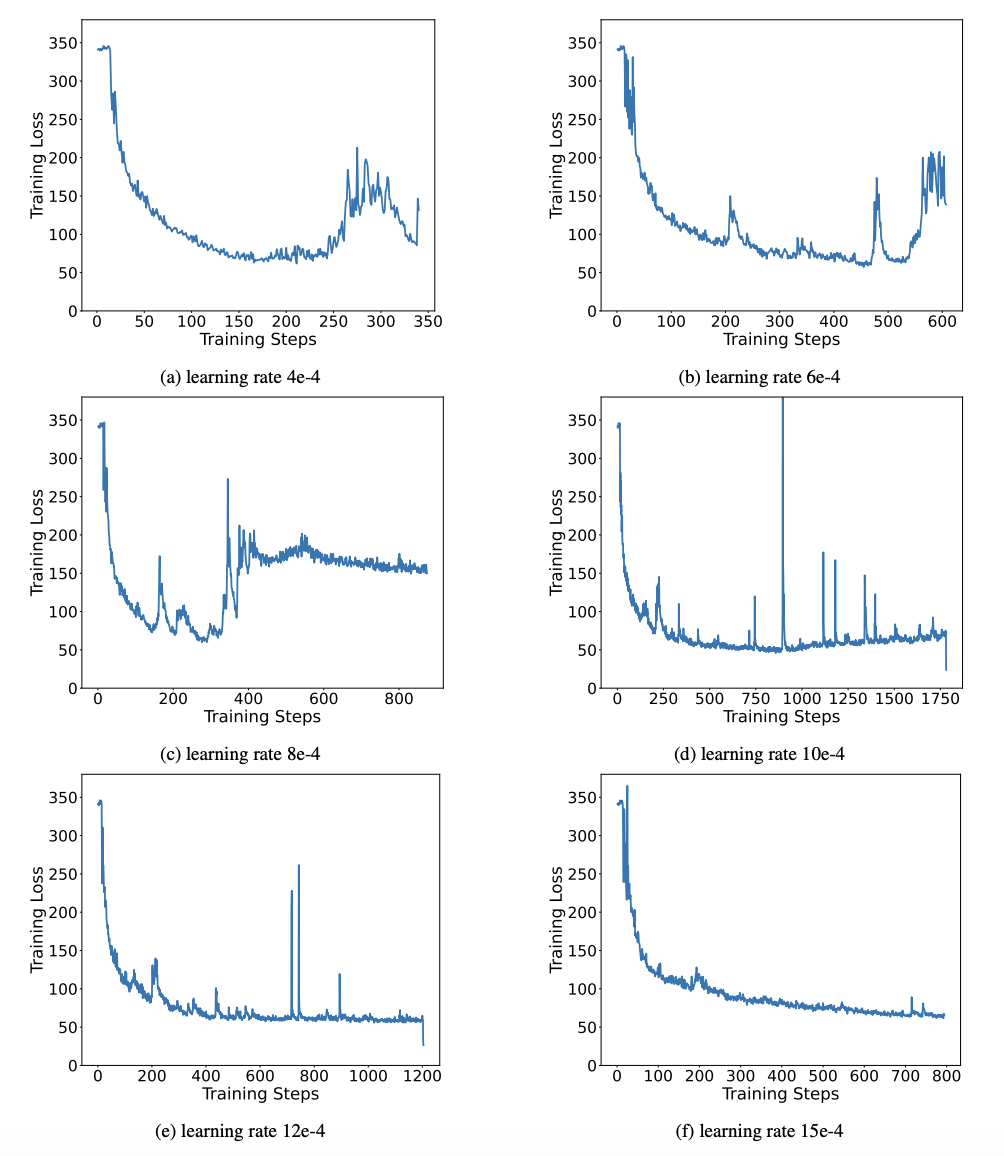
#表 3 : OneBit 在不同LLaMA 模型的壓縮比 表3 給出的是OneBit 對不同規模LLaMA 模型的壓縮比。可以看出,OneBit 對模型的壓縮比均超過 90%,而這項壓縮能力是史無前例的。其中值得注意的是,隨著模型增大,OneBit 的壓縮比越高,這是由於 Embedding 層這種不參與量化的參數佔比越來越小。前文提到,模型越大,OneBit 帶來的效能增益越大,這顯示出 OneBit 在更大模型上的優勢。 圖8 :模型大小與效能的權衡############雖然超低位元量化可能會導致一定的性能損失,但如圖8 所示,它在大小和性能之間達到了良好的平衡。作者認為,壓縮模型的大小十分重要,特別是在行動裝置上部署模型時。 ###### 此外,作者也指出了 1bit 量化模型在計算上的優點。由於參數是純二進位的,可以用 0/1 在 1bit 內表示,這毫無疑問地節省大量的空間。高精度模型中矩陣乘法的元素相乘可以變成高效率的位元運算,只要位元賦值和加法就可以完成矩陣乘積,非常有應用前景。 2. 穩健性 #二值網路普遍面臨訓練不穩定、收斂困難的問題。得益於作者引入的高精度值向量,模型訓練的前向計算和後向計算均表現的十分穩定。 BitNet 更早提出 1bit 模型結構,但該結構很難從充分訓練的高精度模型中遷移能力。如圖 9 所示,作者嘗試了多種不同的學習率來測試 BitNet 的遷移學習能力,發現在教師指導下其收斂難度較大,也在側面證明了 OneBit 的穩定訓練價值。 圖9 : BitNet 在多種不同學習率下的訓練後量化能力 論文的最後,作者也建議了超低位寬未來可能得研究方向。例如,尋找更優的參數初始化方法、更少的訓練代價,或進一步考慮激活值的量化。 更多技術細節請查看原始論文。 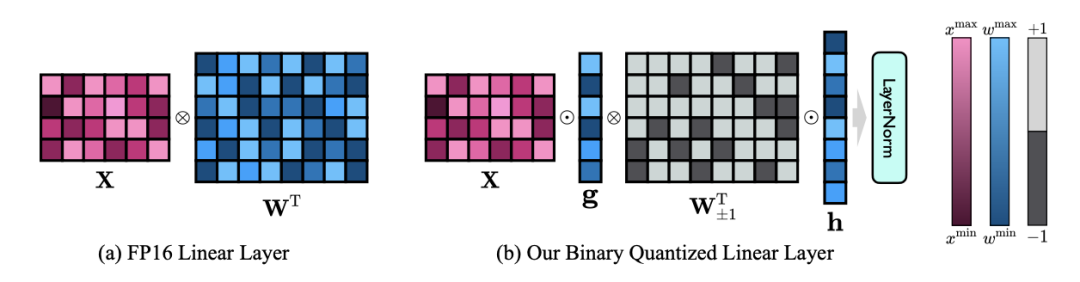
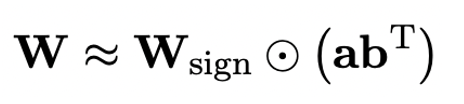
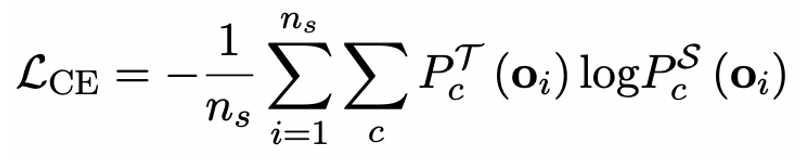
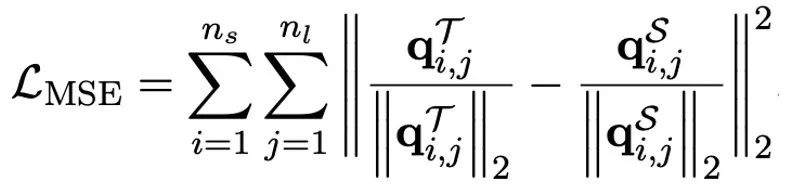
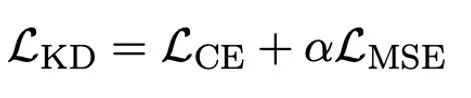

以上是清華、哈工大把大模型壓縮到了1bit,把大模型放在手機裡跑的願望就快要實現了!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一


 Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇
Apr 01, 2024 pm 07:46 PM
Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇
Apr 01, 2024 pm 07:46 PM
Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇