
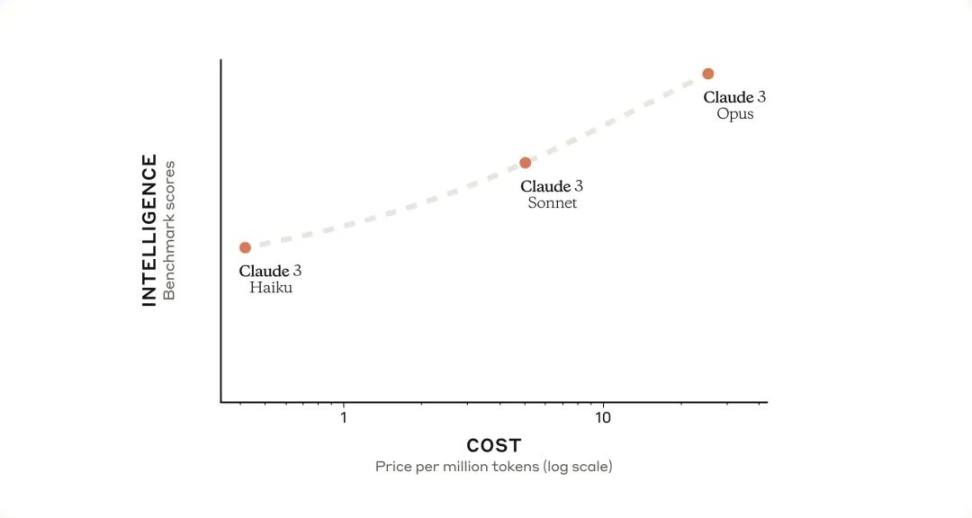
剛剛,Anthropic 宣布推出 Claude 3 模型系列,該系列在廣泛的認知任務中樹立了新的行業基準。該系列包括三種最先進的模型,按能力遞增排列:Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus。每個後續模型都提供了越來越強大的性能,允許用戶為其特定應用程式選擇最佳的智慧、速度和成本平衡。
Opus 和 Sonnet 現已可在 claude.ai 和 Claude API 中使用,後者目前已在 159 個國家 / 地區全面提供。 Haiku 很快就會推出。
Opus,Anthropic最聰明的模型,在大多數常見的AI 系統評估基準上表現優異,包括本科程度的專家知識(MMLU)、研究生程度的專家推理(GPQA)、基本數學(GSM8K)等。它在複雜任務上表現出接近人類層次的理解和流暢度,引領著通用智慧的前沿。
Claude 3 模型展現了在分析和預測、內容創建的細節性、程式碼生成以及在非英語語言如西班牙語、日語和法語等進行對話方面的強大能力。
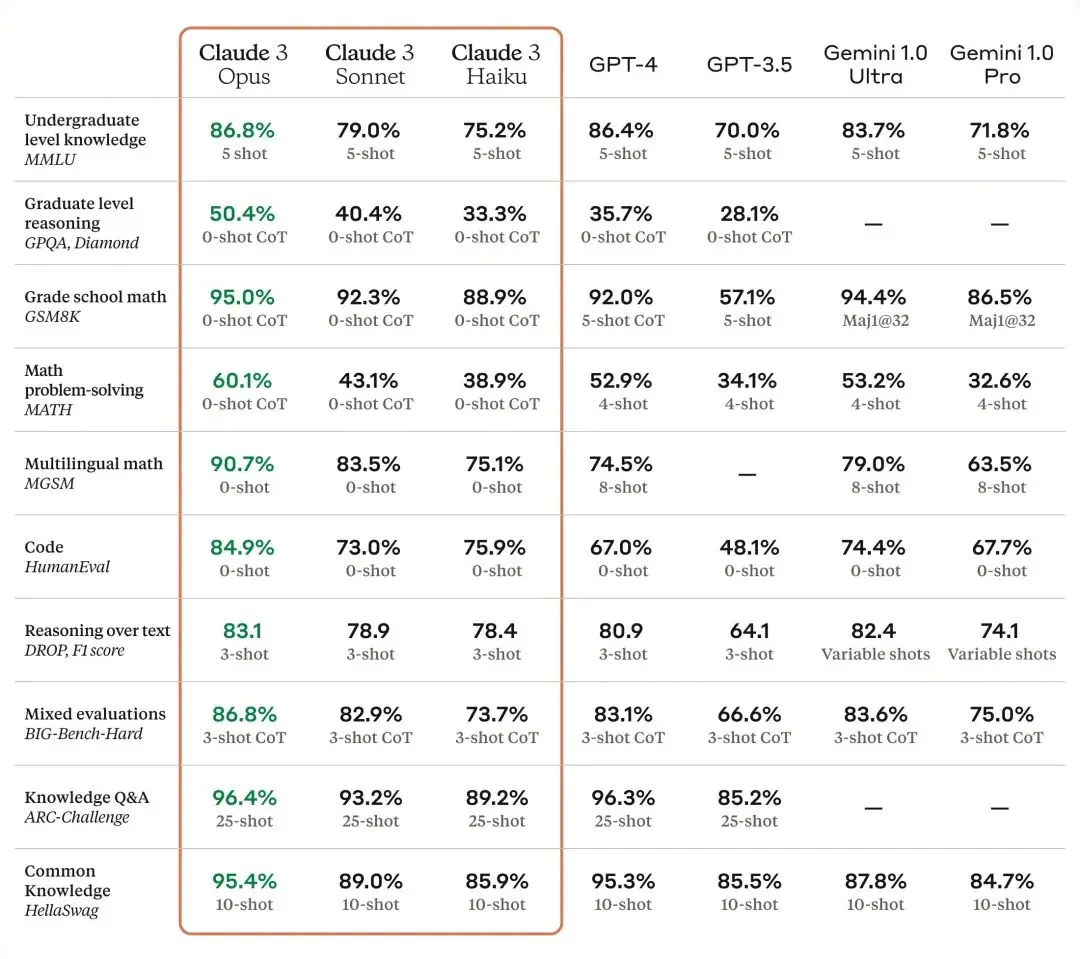
以下是Claude 3 模型與Anthropic同業在多個能力基準[1] 上的比較:
Claude 3 模型可以支援即時客戶聊天、自動完成和資料提取任務,其中回應必須是即時的和即時的。
在智慧領域中,Haiku 是一款性價比極高的模型,擁有市場上最快的速度。它能夠在不到三秒的時間內解讀一篇資訊密集的 arXiv 研究論文(約10,000個標記),其中包含圖表和圖形。 Anthropic公司在不久的將來將進一步優化其效能,Haiku的表現也將提升。
對於絕大多數工作負載而言,Sonnet 比 Claude 2 和 Claude 2.1 快 2 倍以上,並且具有更高水準的智慧。它擅長於需要快速回應的任務,如知識檢索或銷售自動化。 Opus 的速度與 Claude 2 和 2.1 相似,但具有更高水準的智慧。
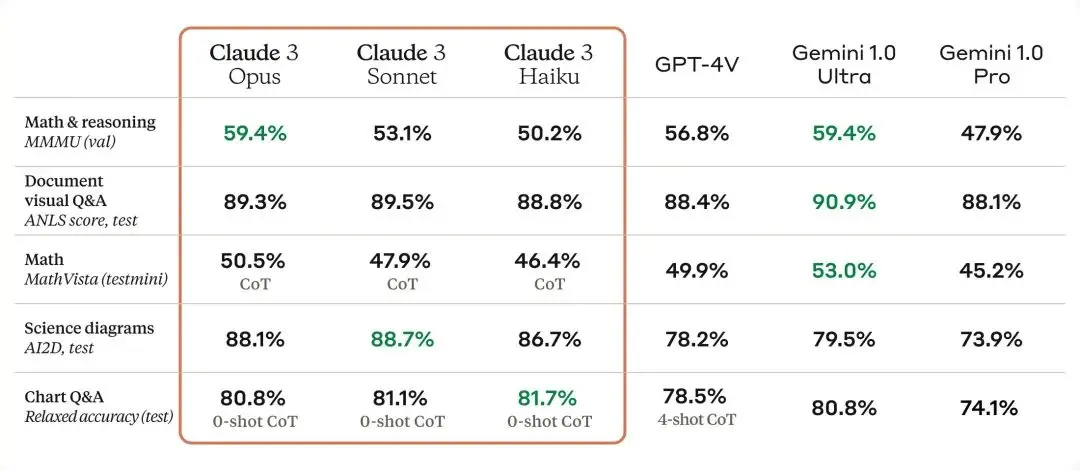
Claude 3 模型具有與其他領先模型相當的複雜視覺能力。它們可以處理各種視覺格式,包括照片、圖表、圖形和技術圖表。 Anthropic 特別興奮地向企業客戶提供這種新的模態,其中一些客戶的知識庫中有多達 50% 的內容以各種格式編碼,例如 PDF、流程圖或簡報投影片。
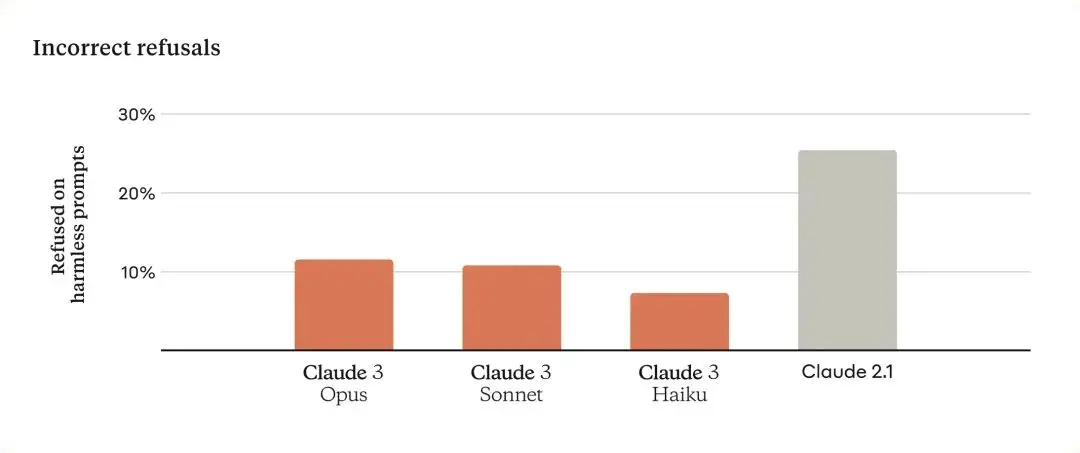
先前的 Claude 模型經常做出不必要的拒絕,表明缺乏上下文理解。在這方面Anthropic已經取得了實質進展:Opus、Sonnet 和 Haiku 拒絕回答那些接近系統警戒線的提示的可能性明顯降低,比以前的模型更少。如下圖所示,Claude 3 模型對請求有更細緻入微的理解,識別出真正的危害,並且拒絕回答無害提示的頻率明顯降低。
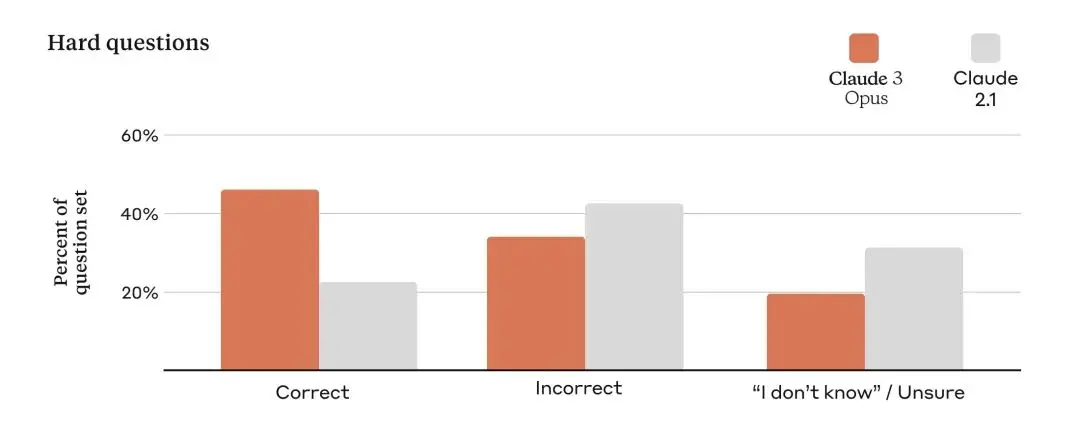
各種規模的企業都依賴Anthropic的模型為他們的客戶服務,這使得Anthropic的模型輸出在規模上保持高準確性至關重要。為了評估這一點,Anthropic使用了一套大量的複雜、事實性問題,針對目前模型的已知弱點。 Anthropic將回應分類為正確答案、錯誤答案(或幻覺)和不確定性的承認,其中模型表示不知道答案而不是提供錯誤訊息。與 Claude 2.1 相比,Opus 在這些具有挑戰性的開放式問題上的準確性(或正確答案)實現了兩倍的提高,同時也減少了錯誤答案的水平。
除了產生更可信的回應外,Anthropic很快就會在Anthropic的 Claude 3 模型中啟用引用,以便它們可以指向參考資料中的精確句子來驗證其答案。
Claude 3 系列模型在推出時將提供一個 20 萬標記的上下文視窗。但是,所有三個模型都能夠接受超過 100 萬標記的輸入,Anthropic可能會將此提供給需要增強處理能力的特定客戶。
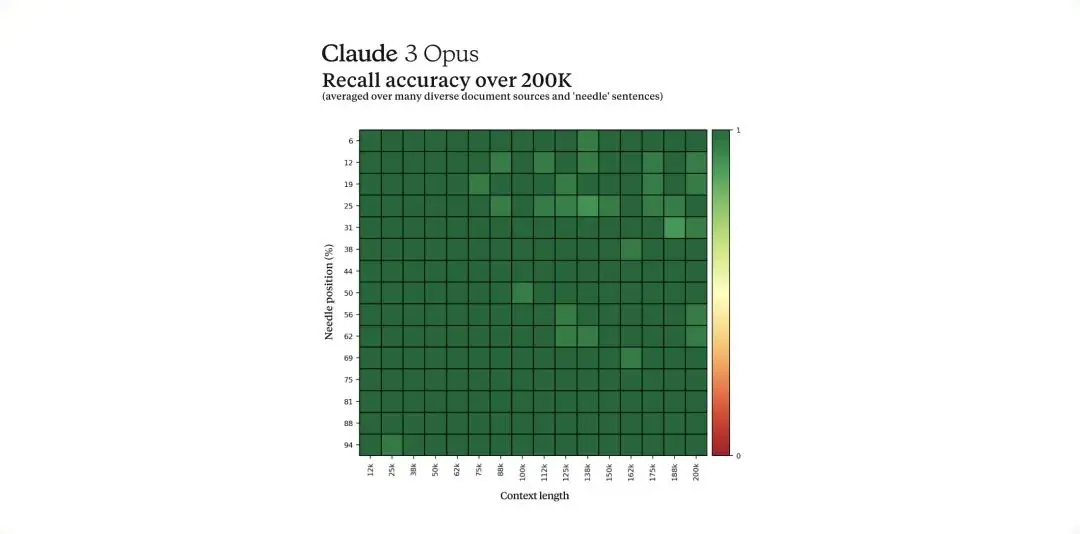
為了有效地處理長上下文提示,模型需要強大的召回能力。 「Needle In A Haystack」(NIAH)評估測量模型從大量資料語料庫中準確召回資訊的能力。 Anthropic透過對每個提示使用 30 個隨機針 / 問題對之一,並在多樣化的眾包語料庫文件上進行測試,增強了這一基準的穩健性。
Claude 3 Opus 不僅實現了近乎完美的召回,超過了99% 的準確性,而且在某些情況下,它甚至通過識別“針”句似乎是人為插入到原始文本中的來識別評估本身的局限性。
Anthropic開發了 Claude 3 系列模型,使其在能力的同時也具備了可信賴性。 Anthropic有幾個專門的團隊追蹤和減輕各種風險,從錯誤訊息和 CSAM 到生物濫用、選舉幹擾和自主複製技能等。 Anthropic不斷發展方法,例如《憲法 AI 》,以提高Anthropic模型的安全性和透明度,並調整Anthropic的模型以減輕新模態可能引發的隱私問題。
解決越來越複雜模型中的偏見是一項持續努力,Anthropic在這個新版本中取得了進展。如模型卡所示,根據問答偏誤基準(BBQ),Claude 3 顯示出比Anthropic先前的模型更少的偏見。 Anthropic始終致力於推動減少偏見並促進模型更大中立性的技術,確保它們不偏向任何特定的黨派立場。
雖然與先前的模型相比,Claude 3 模型系列在生物知識、網路相關知識和自主性方面有所進步,但根據Anthropic的負責任擴展政策,它仍然處於AI 安全等級2( ASL-2)。 Anthropic的紅隊評估(與Anthropic的白宮承諾和 2023 年美國行政命令一致進行)得出結論,目前模型對災難性風險的潛在性可以忽略不計。 Anthropic將繼續密切監視未來的模型,以評估它們與 ASL-3 門檻的接近程度。 Claude 3 模型卡中提供了更多安全細節。
Claude 3 模型在遵循複雜的多步驟指令方面表現更好。它們特別擅長遵循品牌語音和回應指南,並開發用戶可以信賴的面向客戶的體驗。此外,Claude 3 模型在產生流行結構化輸出方面表現更佳,例如 JSON 格式——這樣就更容易對 Claude 進行指導,用於自然語言分類和情感分析等用例。
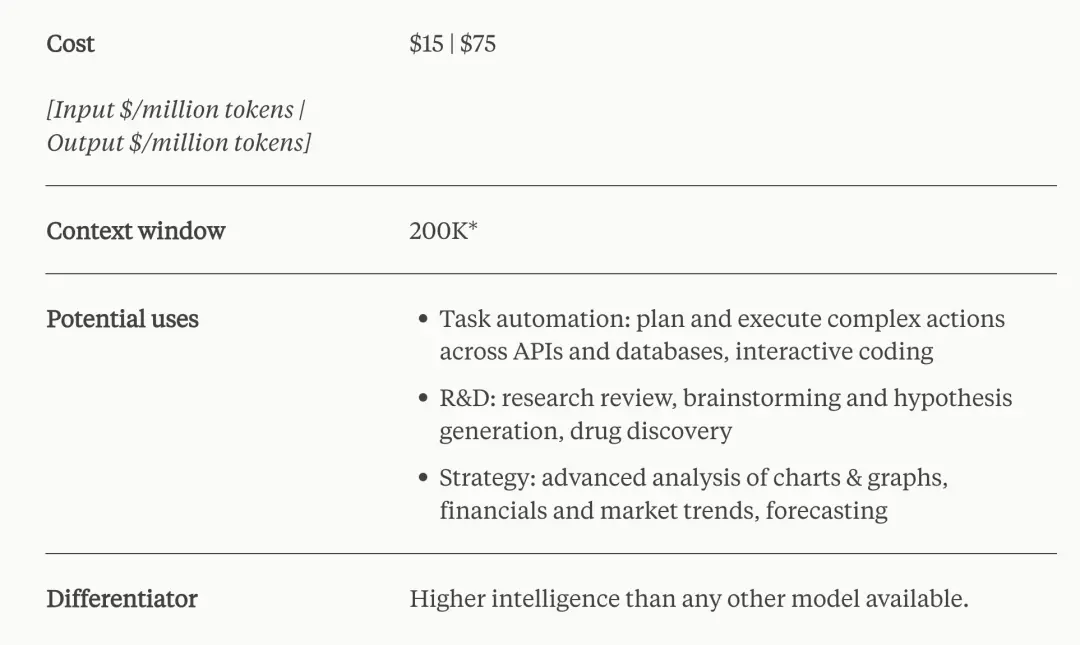
Claude 3 Opus 是Anthropic最聰明的模型,在高度複雜的任務上表現出市場最佳表現。它可以在開放式提示和未見情況下出色地流暢進行,並具有類似人類的理解能力。 Opus 向Anthropic展示了生成式 AI 所能實現的極限。
Claude 3 Sonnet 在智慧和速度之間取得了理想的平衡—特別是對於企業工作負載而言。與同行相比,它以較低的成本提供強大的性能,並且專為大規模 AI 部署的高耐用性而設計。

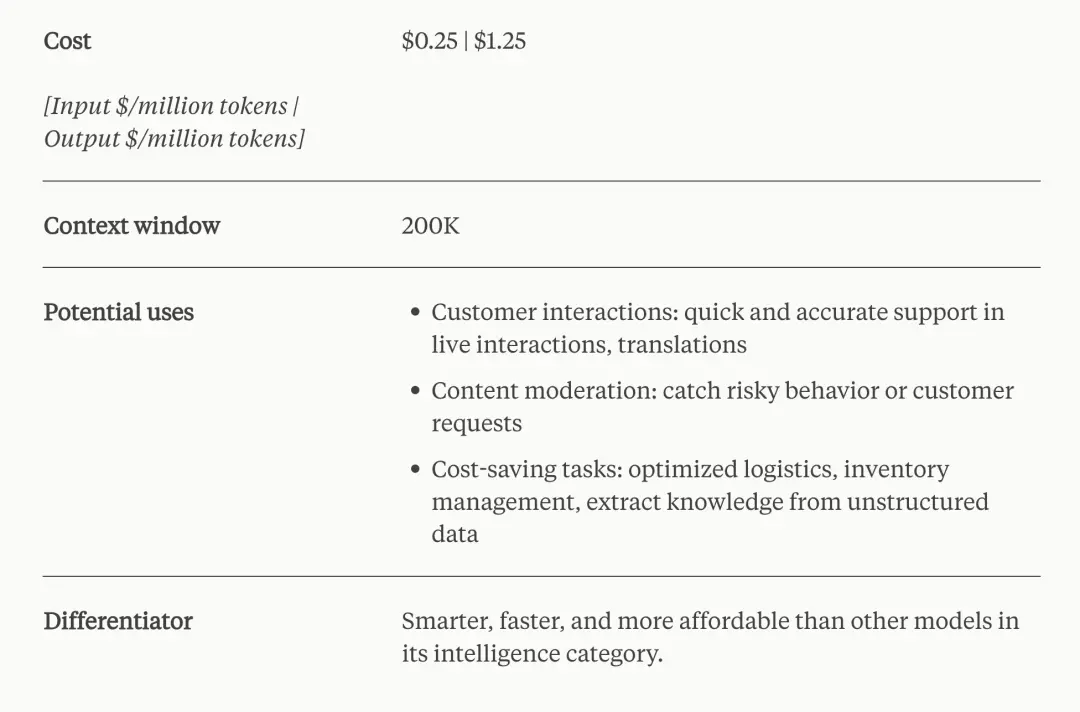
Claude 3 Haiku 是Anthropic最快、最緊湊的模型,可實現幾乎即時的回應。它以無與倫比的速度回答簡單的查詢和請求。用戶將能夠建立無縫的 AI 體驗,模擬人類互動。
Opus 和Sonnet 今天就可以在Anthropic的API 中使用,該API 現在已經普遍可用,開發人員可以立即註冊並開始使用這些模型。 Haiku 很快就會推出。 Sonnet 正在為 claude.ai 上的免費體驗提供支持,而 Opus 則適用於 Claude Pro 訂閱用戶。
Sonnet 也可以透過亞馬遜的 Bedrock 和 Google Cloud 的 Vertex AI 模型花園進行使用,Opus 和 Haiku 很快也將推出。
Anthropic認為模型智慧遠未達到極限,並計劃在接下來的幾個月內頻繁更新 Claude 3 模型系列。 Anthropic也很高興地發布了一系列功能,以增強Anthropic模型的能力,特別是針對企業用例和大規模部署。這些新功能將包括工具使用(也稱為函數呼叫)、互動式編碼(也稱為 REPL)以及更先進的代理能力等。
以上是Claude3 發布,或將全面超越 GPT-4?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















