

Anything in Any Scene:逼真物件插入(助力各類駕駛資料合成)

原標題:Anything in Any Scene: Photorealistic Video Object Insertion
論文連結:https://arxiv.org/pdf/2401.17509.pdf
#程式碼連結:https ://github.com/AnythingInAnyScene/anything_in_anyscene
作者單位:小鵬汽車

論文想法想
#逼真的(realistic)視訊模擬(video simulation)在從虛擬實境到電影製作等各種應用領域都顯示出巨大的潛力。尤其是在現實世界中捕捉影片不切實際或成本高昂的情況下。視訊模擬中的現有方法通常無法準確地建模光照環境、表示物體幾何形狀或實現高水平的照片級真實感。本文提出了 Anything in Any Scene ,這是一種新穎且通用的真實視訊模擬框架,可將任何物件無縫插入現有的動態視訊中,並強調物理真實感。本文提出的整體框架包含三個關鍵過程:1)將真實的物體整合到給定的場景影片中,並放置適當的位置以確保幾何真實感(geometric realism);2)估計天空和環境光照分佈並模擬真實陰影,增強光照真實感(light realism);3)採用風格遷移網絡來細化最終的影片輸出,以最大限度地提高照片真實感(photorealism)。本文透過實驗證明 Anything in Any Scene 框架可以產生具有出色的幾何真實感、光照真實感和照片真實感的模擬影片。透過顯著緩解與視訊資料生成相關的挑戰,本文的框架為獲取高品質影片提供了高效且經濟高效的解決方案。此外,其應用遠遠超出了視訊資料增強的範圍,在虛擬實境、視訊編輯和各種其他以視訊為中心的應用中顯示出廣泛的潛力。
主要貢獻
本文引入了一個新穎且可擴展的 Anything in Any Scene 視訊模擬框架,能夠將任何物件整合到任何動態場景影片中。
這篇文章的結構獨具特色,著重於在視訊模擬中保持幾何、光照和照片的真實感,以確保輸出結果的高品質和真實性。
經過廣泛驗證,結果顯示該框架具備製作高度逼真視訊模擬的能力,從而顯著拓展了該領域的應用範圍和發展潛力。
論文設計
影像和視訊模擬在從虛擬實境到電影製作的各種應用中都取得了成功。透過逼真的影像和視訊模擬產生多樣化和高品質的視覺內容的能力具有推動這些領域發展的潛力,能夠引入新的可能性和應用。儘管在現實世界中捕捉的影像和影片的真實性非常寶貴,但它們經常受到長尾分佈的限制。這導致常見場景的代表性過高,而罕見但關鍵的情況的代表性不足,從而提出了稱為 out-of-distribution problem 的挑戰。透過視訊擷取和編輯來解決這些限制的傳統方法被證明是不切實際的或成本過高,因為難以涵蓋所有可能的情況。視訊模擬的重要性,特別是透過將現有視訊與新插入的物體相集成,對於克服這些挑戰變得至關重要。透過產生大規模、多樣化和逼真的視覺內容,視訊模擬有助於增強虛擬實境、影片編輯和視訊資料增強方面的應用。
然而,考慮物理真實性生成逼真的模擬影片仍然是一個具有挑戰性的開放問題。現有方法通常因專注於特定設定而表現出局限性,特別是室內環境[9,26,45,46,57]。這些方法可能無法充分解決室外場景的複雜性,包括不同的光照條件和快速移動的物體。依賴 3D 模型配準的方法僅限於整合有限類別的物件 [12,32,40,42]。許多方法忽略了一些重要因素,例如光照環境建模、正確的物件放置和實現真實感 [12, 36]。失敗的案例如圖 1 所示。因此,這些限制極大地限制了它們在需要高度可擴展、幾何一致和真實場景視訊模擬的領域(例如自動駕駛和機器人)中的應用。
本文提出了一個用於解決這些挑戰的逼真視訊物件插入的綜合框架 Anything in Any Scene。此框架設計具有通用性,適用於室內和室外場景,確保幾何真實感、光照真實感和照片真實感等方面的物理準確性。本文的目標是創建視訊仿真,不僅有利於機器學習中的視覺數據增強,而且適用於各種視訊應用,例如虛擬實境和視訊編輯。
本文的 Anything in Any Scene 框架的概述如圖 2 所示。本文在第 3 節中詳細介紹了本文新穎且可擴展的流程,用於建構場景視訊和物件網格(object mesh)的多樣化資產庫。本文介紹了一種視覺資料查詢引擎,旨在利用描述性關鍵字從視覺查詢中高效檢索相關影片片段。接下來,本文提出兩種產生 3D meshes 的方法,利用現有 3D 資產以及多視圖影像重建。這允許不受限制地插入任何所需的物體,即使它非常不規則或語義較弱。在第 4 節中,本文詳細介紹了將物件整合到動態場景影片中的方法,重點是保持物理真實感。本文設計了第 4.1 節中描述的物體放置和穩定方法,確保插入的物體穩定地錨定(anchored)在連續的視頻幀上。為了解決創建逼真的光照和陰影效果的挑戰,本文估計天空和環境光照並在渲染過程中產生逼真的陰影,如第 4.2 節所述。產生的模擬視訊幀不可避免地包含與現實世界捕獲的視訊不同的不切實際的偽影,例如雜訊水平、色彩保真度和清晰度方面的成像品質差異。本文在 4.3 節中採用風格遷移網路來增強照片真實感。
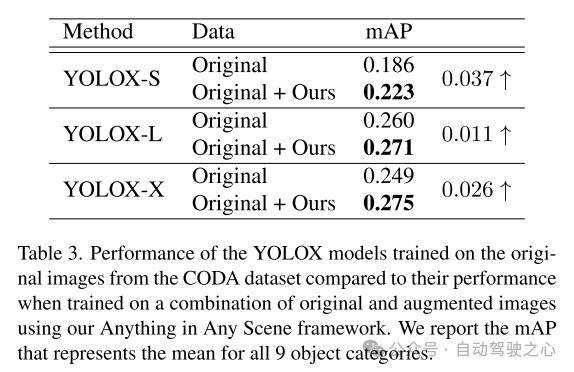
從本文提出的框架產生的模擬視頻達到了高度的光照真實感、幾何真實感和照片真實感,在質量和數量上都優於其他視頻,如第 5.3 節所示。本文在5.4節中進一步展示了本文的模擬影片在訓練感知演算法中的應用,以驗證其實用價值。 Anything in Any Scene 框架能夠創建大規模、低成本的視訊資料集,用於具有時間效率和逼真視覺品質的資料增強,從而減輕視訊資料生成的負擔,並有可能改善長尾分佈和分佈外的挑戰。憑藉其通用的框架設計,Anything in Any Scene 框架可以輕鬆整合改進的模型和新模組,例如改進的 3D mesh 重建方法,進一步增強視訊模擬性能。
 圖 1. 光照環境估計錯誤、物體擺放位置錯誤和紋理風格不真實的模擬視訊影格範例,這些問題使得影像缺乏物理真實感。
圖 1. 光照環境估計錯誤、物體擺放位置錯誤和紋理風格不真實的模擬視訊影格範例,這些問題使得影像缺乏物理真實感。 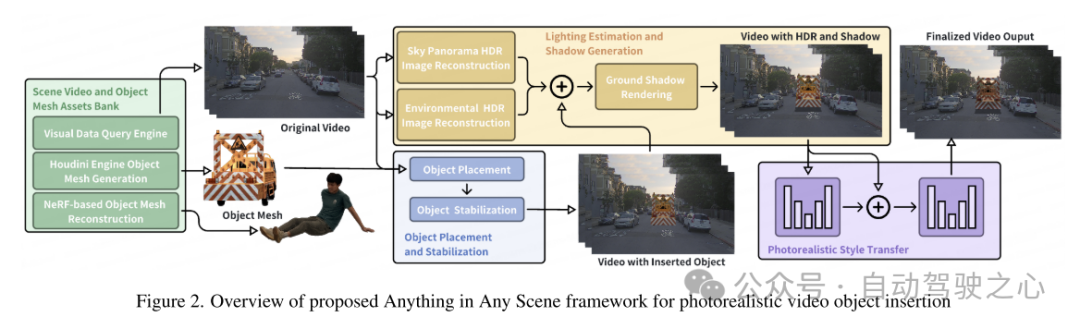 圖 2. 用於逼真視訊物件插入的 Anything in Any Scene 框架概述
圖 2. 用於逼真視訊物件插入的 Anything in Any Scene 框架概述 圖 3. 用於放置物件的駕駛場景影片範例。每幅影像中的紅點是物體插入的位置。
圖 3. 用於放置物件的駕駛場景影片範例。每幅影像中的紅點是物體插入的位置。
實驗結果


#圖4. 原始天空影像、重建的HDR 影像及其相關的太陽光照分佈圖的範例
圖5. 原始和重建的HDR 的環境全景影像範例

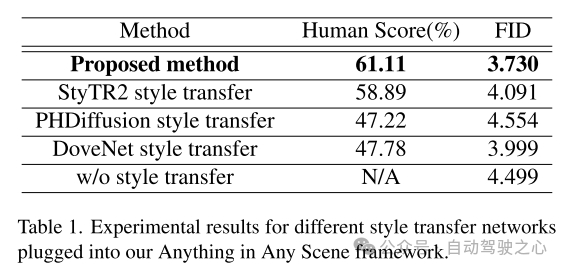
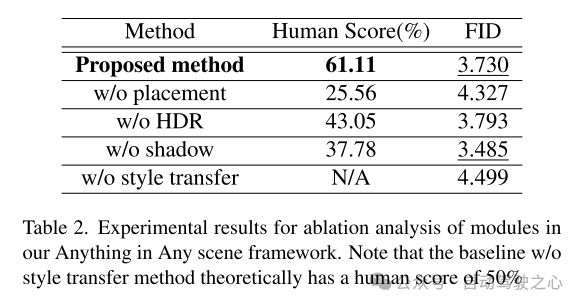 圖 8. PandaSet 資料集的模擬視訊影格在各種渲染條件下的定性比較。
圖 8. PandaSet 資料集的模擬視訊影格在各種渲染條件下的定性比較。
總結:
本文提出了一個創新且可擴展的框架,」Anything in Any Scene",專為逼真的視訊仿真而設計。本文提出的框架將各種物件無縫整合到不同的動態影片中,確保保留幾何真實感、光線真實感和照片真實感。透過廣泛的演示,本文展示了其在緩解視訊資料收集和生成相關挑戰方面的功效,提供了適用於各種場景的經濟高效且省時的解決方案。本文的框架的應用在下游感知任務中顯示出顯著的改進,特別是在解決目標檢測中的長尾分佈問題方面。本文框架的靈活性允許直接整合每個模組的改進模型,本文的框架為逼真視訊模擬領域的未來探索和創新奠定了堅實的基礎。
引用:
Bai C, Shao Z, Zhang G, et al. Anything in Any Scene: Photorealistic Video Object Insertion[J]. arXiv preprint arXiv:2401.17509 , 2024.
以上是Anything in Any Scene:逼真物件插入(助力各類駕駛資料合成)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 如何用OPPO手機錄製螢幕影片(簡單操作)
May 07, 2024 pm 06:22 PM
如何用OPPO手機錄製螢幕影片(簡單操作)
May 07, 2024 pm 06:22 PM
遊戲技巧或進行教學演示,在日常生活中,我們經常需要用手機錄製螢幕影片來展示一些操作步驟。其錄製螢幕影片的功能也非常出色,而OPPO手機作為一款功能強大的智慧型手機。讓您輕鬆快速地完成錄製任務、本文將詳細介紹如何使用OPPO手機來錄製螢幕影片。準備工作-確定錄製目標您需要明確自己的錄製目標、在開始之前。是要錄製一個操作步驟的示範影片?還是要錄製一個遊戲的精彩時刻?還是要錄製一段教學影片?才能更好地安排錄製過程、只有明確目標。開啟OPPO手機的錄影功能在快速面板中找到、錄影功能位於快速面板中,在
 全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想像一下,一個人工智慧模型,不僅擁有超越傳統運算的能力,還能以更低的成本實現更有效率的效能。這不是科幻,DeepSeek-V2[1],全球最強開源MoE模型來了。 DeepSeek-V2是一個強大的專家混合(MoE)語言模型,具有訓練經濟、推理高效的特點。它由236B個參數組成,其中21B個參數用於啟動每個標記。與DeepSeek67B相比,DeepSeek-V2效能更強,同時節省了42.5%的訓練成本,減少了93.3%的KV緩存,最大生成吞吐量提高到5.76倍。 DeepSeek是一家探索通用人工智
 替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
本月初,來自MIT等機構的研究者提出了一種非常有潛力的MLP替代方法—KAN。 KAN在準確性和可解釋性方面表現優於MLP。而且它能以非常少的參數量勝過以更大參數量運行的MLP。例如,作者表示,他們用KAN以更小的網路和更高的自動化程度重現了DeepMind的結果。具體來說,DeepMind的MLP有大約300,000個參數,而KAN只有約200個參數。 KAN與MLP一樣具有強大的數學基礎,MLP基於通用逼近定理,而KAN基於Kolmogorov-Arnold表示定理。如下圖所示,KAN在邊上具
 Adobe After Effects cs6(Ae cs6)怎麼切換語言 Ae cs6中英文切換的詳細步驟-ZOL下載
May 09, 2024 pm 02:00 PM
Adobe After Effects cs6(Ae cs6)怎麼切換語言 Ae cs6中英文切換的詳細步驟-ZOL下載
May 09, 2024 pm 02:00 PM
1.首先找到AMTLanguages這個資料夾。我們發現了在AMTLanguages資料夾中的一些文件。如果你安裝的是簡體中文,會有一個zh_CN.txt的文字文件(文字內容為:zh_CN)。如果你安裝的是英文,會有一個en_US.txt的文字文件(文字內容為:en_US)。 3.所以,如果我們要切換到中文,我們要在AdobeAfterEffectsCCSupportFilesAMTLanguages路徑下,新建zh_CN.txt的文本文檔(文字內容是:zh_CN)。 4.相反如果我們要切換到英文,
 抖音如何拍攝影片?拍攝視訊麥克風怎麼開?
May 09, 2024 pm 02:40 PM
抖音如何拍攝影片?拍攝視訊麥克風怎麼開?
May 09, 2024 pm 02:40 PM
抖音作為當今最受歡迎的短影片平台之一,其拍攝影片的品質和效果直接影響到用戶的觀看體驗。那麼,如何在抖音上拍攝出高品質的影片呢?一、抖音如何拍攝影片? 1.開啟抖音APP,點選底部中間的「+號」按鈕,進入影片拍攝頁面。 2.抖音提供了多種拍攝模式,包括正常拍攝、慢動作、短影片等。根據需要選擇合適的拍攝模式。 3.在拍攝頁面,點選螢幕下方的「濾鏡」按鈕,可以選擇不同的濾鏡效果,讓影片更有個性。 4.如果需要調整曝光度、對比等參數,可以點選螢幕左下角的「參數」按鈕進行設定。 5.拍攝過程中,可以點選螢幕左
 全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
為了將大型語言模型(LLM)與人類的價值和意圖對齊,學習人類回饋至關重要,這能確保它們是有用的、誠實的和無害的。在對齊LLM方面,一種有效的方法是根據人類回饋的強化學習(RLHF)。儘管RLHF方法的結果很出色,但其中涉及了一些優化難題。其中涉及訓練一個獎勵模型,然後優化一個策略模型來最大化該獎勵。近段時間已有一些研究者探索了更簡單的離線演算法,其中之一就是直接偏好優化(DPO)。 DPO是透過參數化RLHF中的獎勵函數來直接根據偏好資料學習策略模型,這樣就無需顯示式的獎勵模型了。此方法簡單穩定
 無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。这一创新成果在代码生成任务取得了显著突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数
 LLM全搞定! OmniDrive:集3D感知、推理規劃於一體(英偉達最新)
May 09, 2024 pm 04:55 PM
LLM全搞定! OmniDrive:集3D感知、推理規劃於一體(英偉達最新)
May 09, 2024 pm 04:55 PM
寫在前面&筆者的個人理解這篇論文致力於解決當前多模態大語言模型(MLLMs)在自動駕駛應用中存在的關鍵挑戰,即將MLLMs從2D理解擴展到3D空間的問題。由於自動駕駛車輛(AVs)需要針對3D環境做出準確的決策,這項擴展顯得格外重要。 3D空間理解對於AV來說至關重要,因為它直接影響車輛做出明智決策、預測未來狀態以及與環境安全互動的能力。目前的多模態大語言模型(如LLaVA-1.5)通常只能處理較低解析度的影像輸入(例如),這是由於視覺編碼器的分辨率限制,LLM序列長度的限制。然而,自動駕駛應用需
