
Claude 3的競技場排名終於來了:
短短3天內,20000張投票,將榜單的流量推向空前。
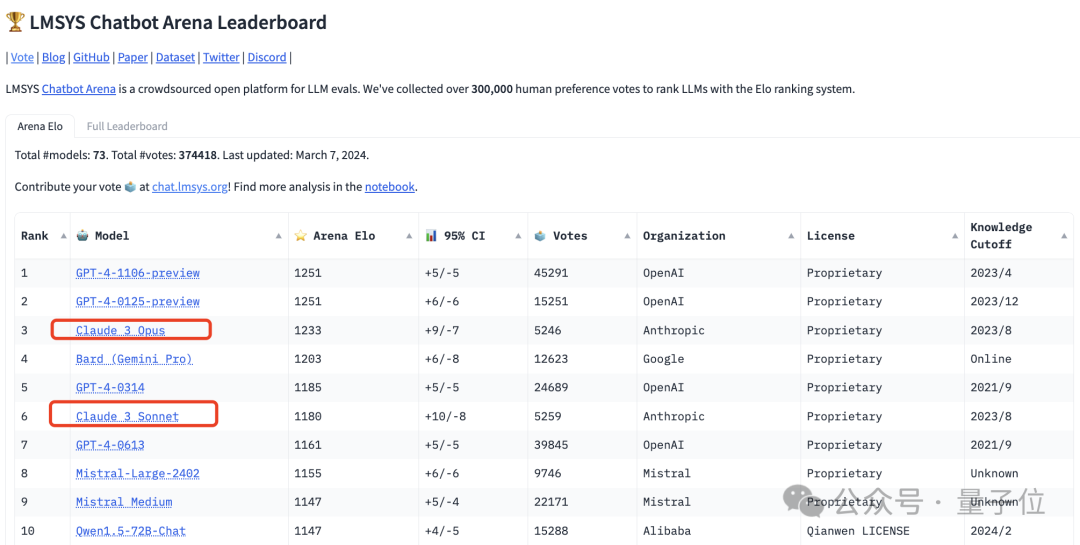
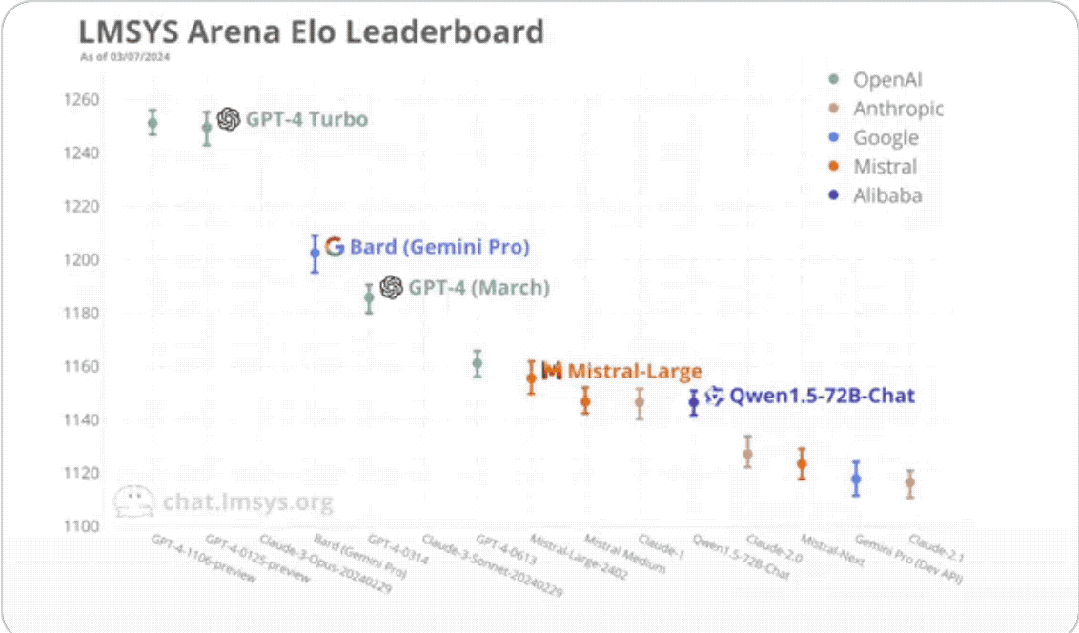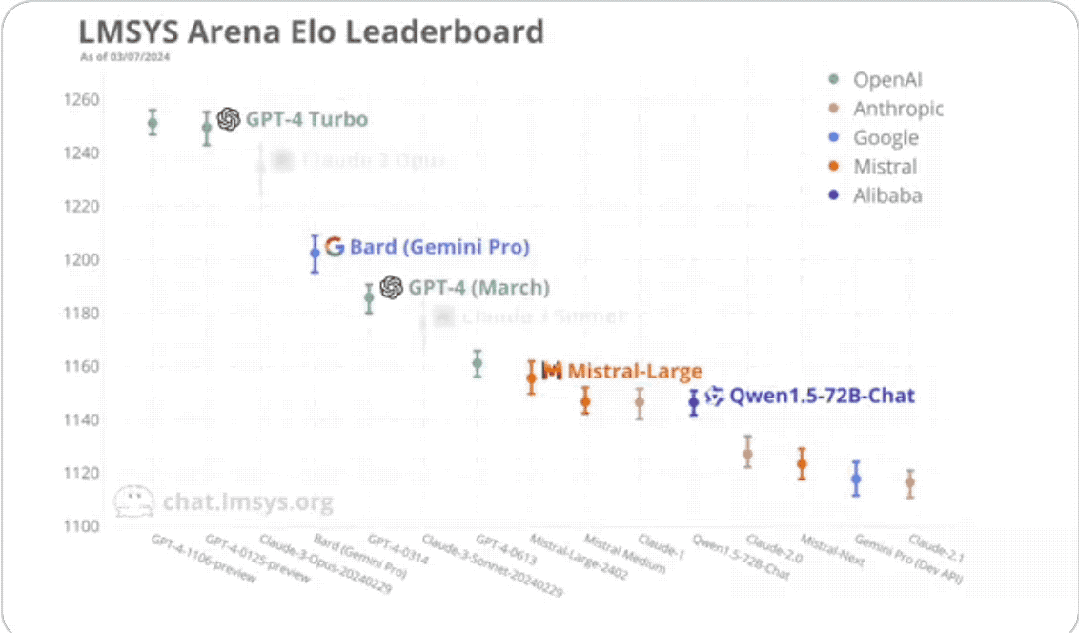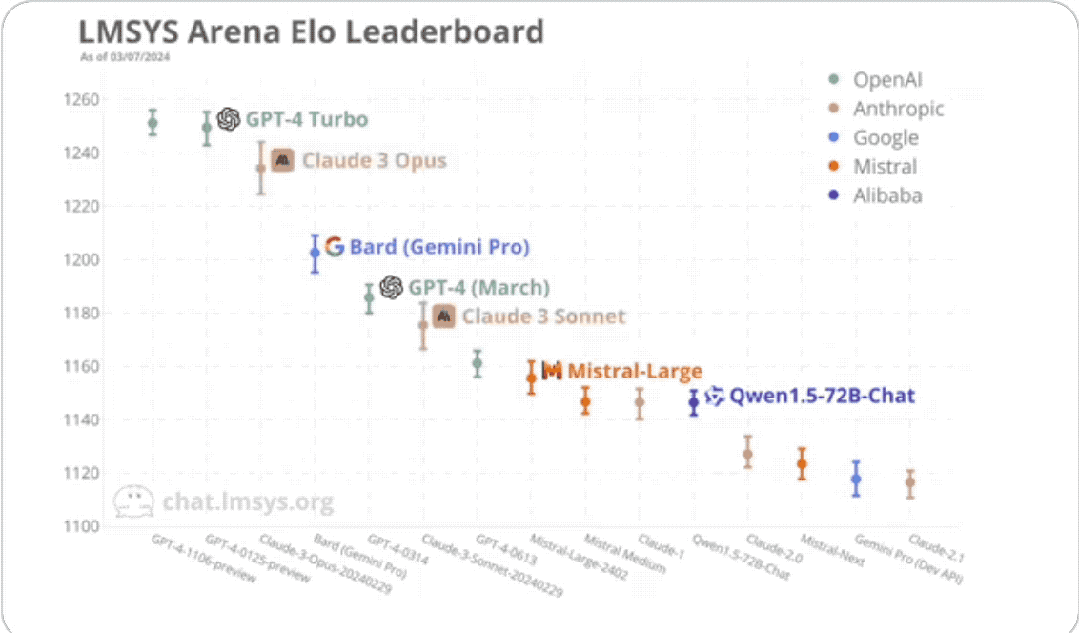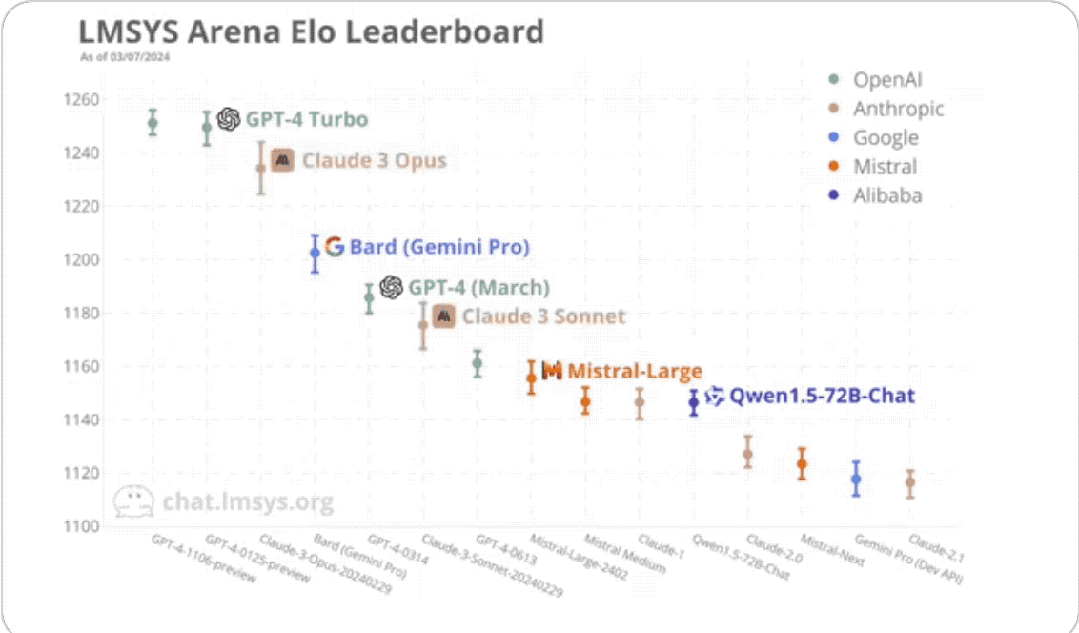
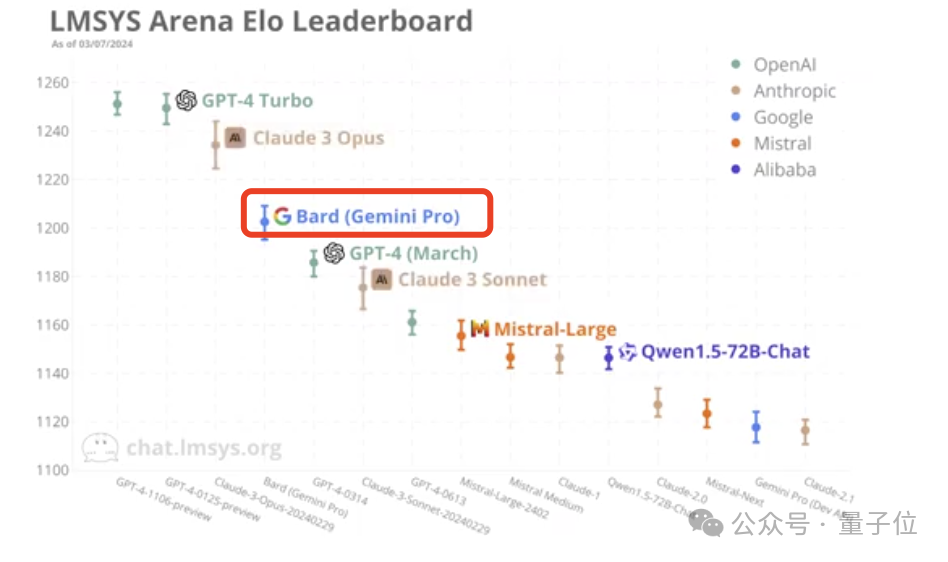
最終,Claude 3最強的「大盃」模型Opus得分1233,成為第一位能和GPT-4-Turbo一較高下的選手。
「中盃」Sonnet也還不錯,和GPT-4的兩個舊版本不相上下。
 圖片
圖片
不過總的來說,還是GPT-4系列佔上風。
Claude 3的表演和宣傳有些許出入。如網友總結:
GPT-4還是大模型之王!
但,免費的「中盃」Claude 3(Sonnet)更物超所值。
 圖片
圖片
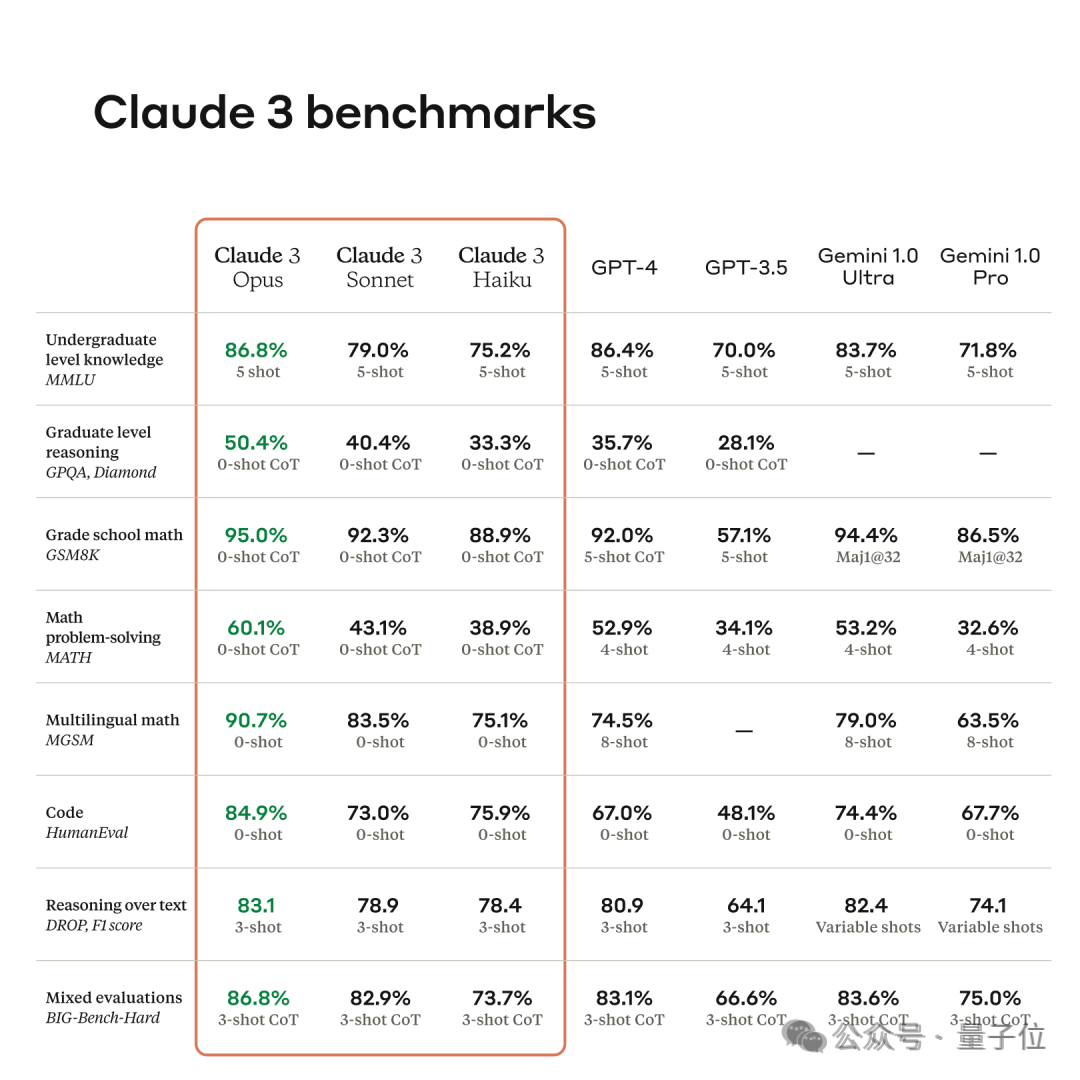
Claude 3發佈時官方的宣傳是全面超過了GPT-4,但沒提是哪個版本的GPT-4。
 圖片
圖片
競技場榜單(LMSYS Chatbot Arena Leaderboard)的最新更新,幫咱摸清了。
來看詳細情況。
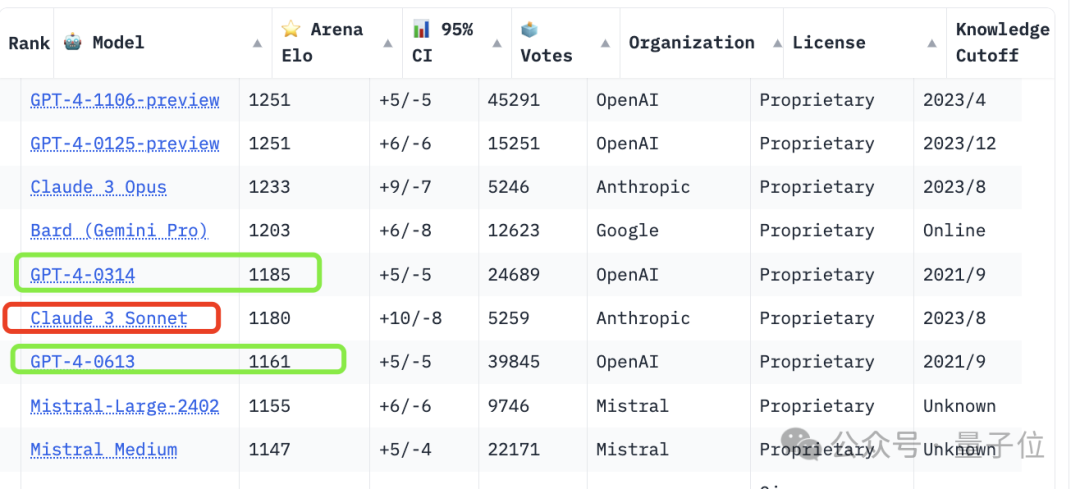
排在第一名的是OpenAI去年11月推出的GPT-4 Turbo,也就是:
GPT-4-1106-preview。
它功能更強價格也更便宜,具有128k上下文,訓練資料從先前的2021年9月更新到2023年4月。
與它並列第一的是GPT-4 Turbo最新的版本,今年一月發布的:
GPT-4-0125-preview。
它的訓練資料更廣,擴展到了2023年12月。
兩者都取得了1251的分數。
接著才是Claude 3(訓練資料截止到2023年8月)。
它的最強版本Opus得分1233,比GPT-4 Turbo低了18分。
 圖片
圖片
這個差距相比起來不算太大,畢竟再往下看:
它比GPT-4的兩個版本(0314、0613)分別高了48分、72分。
至於中等性能的Claude 3 Sonnet,則排名第6,位於GPT-4這兩個版本之間:
#不過只比0314版低5分,大有潛力一舉超越。
 圖片
圖片
所以總的來說,官方宣傳的也算沒大毛病,全面超越老版GPT-4,但離GPT-4 Turbo還有點距離,雖然不算太大。
——從此榜單的評比機制等情況來看,它的結果還是相當有業界認可的。
它是由「小羊駝」(Vicuna)的作者團隊發起。
但裁判官不是“小羊駝”,更不是GPT-4,而是基於人類偏好。
詳細來說,也就我們隨機向兩個匿名模型提出任意問題,然後評價它們各自的回答,把票投給更好的那一個。
 圖片
圖片
如果一輪投不出,咱可以選擇繼續提問。如果聊天中模型不小心透露了自己的身份,投票則作廢。
特別的,計分規則採用Elo機制來保證公平(玩王者榮耀的朋友都熟)。
舉個例子:如果某個模型輸了,但它的分數不一定低,因為它本身實力就弱,這是預料之中。
截止目前,這個榜單可以說是非常火爆,已經有全球73個模型參與挑戰,共收到了網友們37萬張 投票。
除了Claude 3,我們再看看其他表現亮眼的選手。
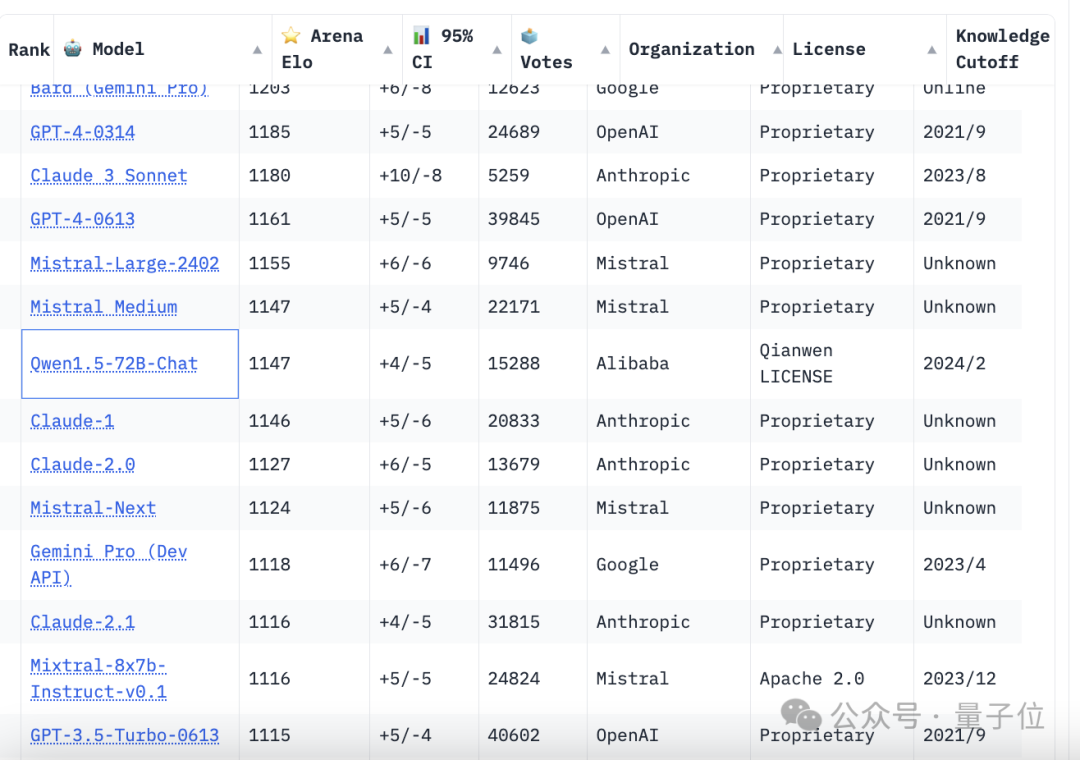
首先要提的是基於Gemini Pro的Bard,排名第四,僅次於GPT-4Turbo和Claude 3。
 圖片
圖片
可以說有點讓人驚訝。
網友戲謔:
Google這是生生在排行榜上開了個「洞」啊。
並連忙艾特JeffDean和DeepMind負責人:餵,加把勁兒啊(旺柴)
 圖片
圖片
然後要說的是阿里通義千問(1.5版本,上個月發布)。
它在本次排名中擠進了前十名、並列第九,是國內選手中表現最好的。
 圖片
圖片
被它甩在身後的,除了其他國產選手,還有Claude 2、Gemini Pro和GPT-3.5等等。
完整名單:https://www.php.cn/link/e39505ef839c38f61139ae78da3f7615
#參考連結:https://www.php.cn/link/ 30637ce29549ac951061fd211d43c3b0
以上是GPT-4王冠沒掉! Claude 3競技場人類投票成績出爐:僅居第三的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















