

田徑棟等人新作:突破記憶體瓶頸,讓一塊4090預訓練7B大模型

Meta FAIR 田徑棟參與的研究計畫在上個月獲得了廣泛好評。在他們的論文《MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases》中,他們開始探討如何優化10億以下參數的小型模型,旨在實現在行動裝置上運行大型語言模型的目標。
3 月 6 日,田徑棟團隊發布了最新的研究成果,這次專注於提高LLM記憶體的效率。除了田徑棟本人,研究團隊還包括來自加州理工學院、德州大學奧斯汀分校以及CMU的研究人員。這項研究旨在進一步優化LLM記憶體的效能,為未來的技術發展提供支援和指導。
他們共同提出了一種名為GaLore(Gradient Low-Rank Projection)的訓練策略,這種策略允許全參數學習,相較於LoRA 等常見的低秩自適應方法,GaLore具有更高的記憶體效率。
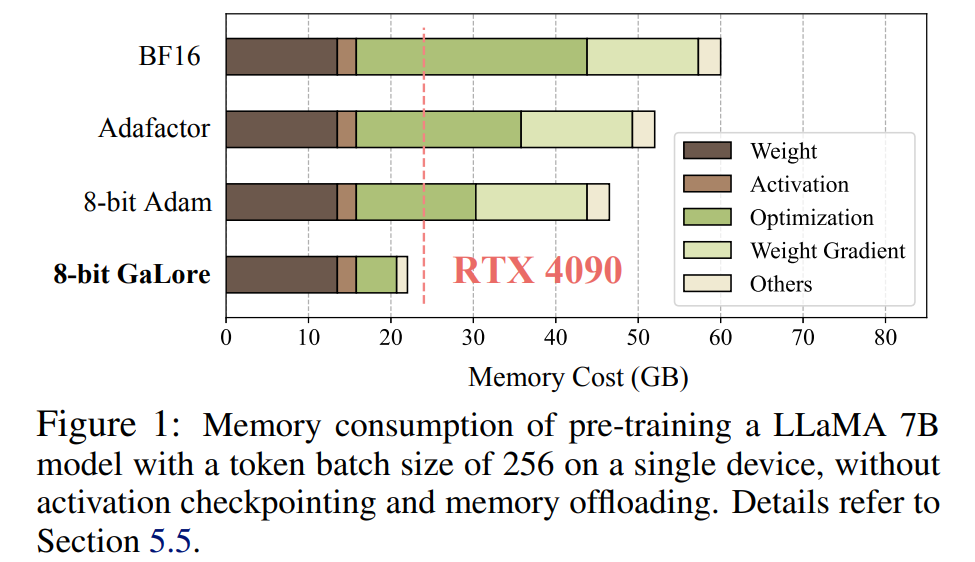
這項研究首次表明,在配備24GB 記憶體的消費級GPU(例如NVIDIA RTX 4090)上,可以成功地進行7B 模型的預訓練,而無需使用模型並行、檢查點或卸載策略。

論文網址:https://arxiv.org/abs/2403.03507
論文標題: GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
接下來我們來看看文章主要內容。
目前,大型語言模型(LLM)在多個領域展現出卓越的潛力,但我們也必須正視一個現實問題,那就是預訓練和微調LLM不僅需要大量的計算資源,還需要大量的記憶體支援。
LLM 對記憶體的需求不僅包括以億計算的參數,還包括梯度和 Optimizer States(例如 Adam 中的梯度動量和方差),這些參數可能大於儲存本身。舉例來說,使用單一批次大小且從頭開始預訓練的 LLaMA 7B ,需要至少 58 GB 記憶體(14 GB 用於可訓練參數,42 GB 用於 Adam Optimizer States 和權重梯度,2 GB 用於啟動)。這使得訓練 LLM 在消費級 GPU(例如具有 24GB 記憶體的 NVIDIA RTX 4090)上變得不可行。
為了解決上述問題,研究人員不斷開發各種最佳化技術,以減少預訓練和微調期間的記憶體使用。
該方法在Optimizer States 下將記憶體使用量減少了65.5%,同時還能保持在LLaMA 1B 和7B 架構上使用最多19.7B token 的C4 資料集進行預訓練的效率和性能,以及在GLUE 任務上微調RoBERTa 的效率和性能。與 BF16 基準相比,8-bit GaLore 進一步減少了優化器記憶體達 82.5%,總訓練記憶體減少了 63.3%。
在看到這項研究後,網友表示:「是時候忘記雲端、忘記HPC 了,有了GaLore,所有的AI4Science 都將在2000 美元的消費級GPU 上完成。」
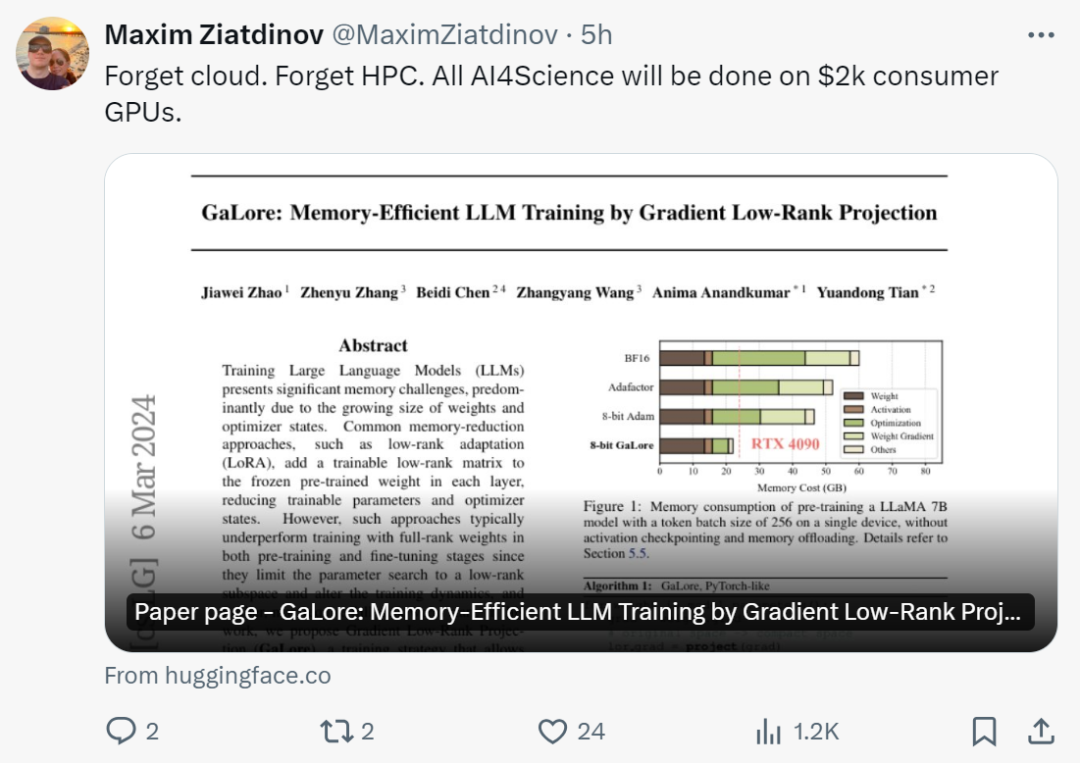
中預訓練:「有了GaLore,現在可以在具有24G 記憶體的NVidia RTX 4090s 中預訓練7B 模型了。
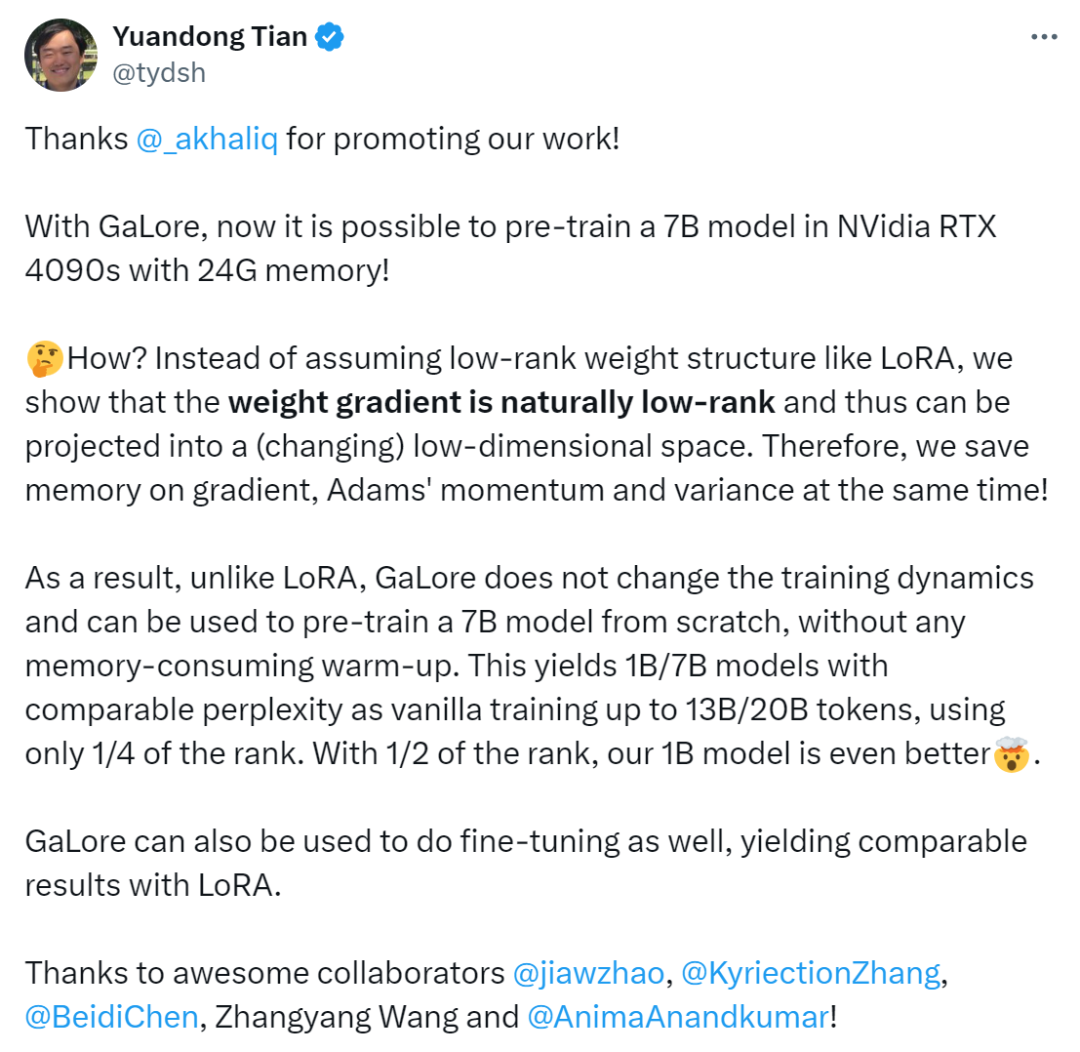
我們沒有像LoRA 那樣假設低秩權重結構,而是證明權重梯度自然是低秩的,因此可以投影到(變化的)低維空間中。因此,我們同時節省了梯度、Adam 動量和方差的記憶體。
因此,與LoRA 不同,GaLore 不會改變訓練動態,可用於從頭開始預訓練7B 模型,無需任何記憶體消耗的預熱。GaLore 也可用於進行微調,產生與LoRA 相當的結果」。
方法介紹
#前面已經提到,GaLore 是一種允許全參數學習的訓練策略,但比常見的低秩自適應方法(例如LoRA)更節省記憶體。 GaLore 關鍵思想是利用權重矩陣 W 的梯度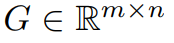 緩慢變化的低秩結構,而不是試圖將權重矩陣直接近似為低秩形式。
緩慢變化的低秩結構,而不是試圖將權重矩陣直接近似為低秩形式。
本文首先從理論上證明了梯度矩陣G 在訓練過程中會變成低秩,在理論的基礎上,本文用GaLore 來計算兩個投影矩陣 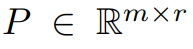 和
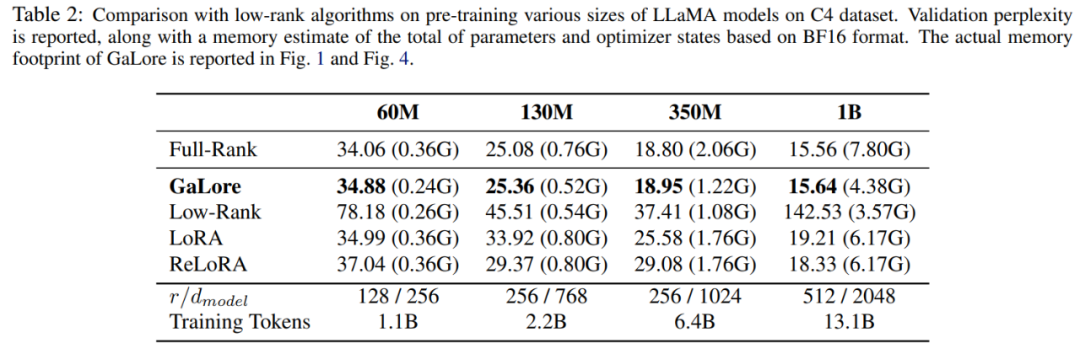
和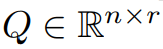 將梯度矩陣G 投影成低秩形式P^⊤GQ。在這種情況下,依賴元件梯度統計的 Optimizer States 的記憶體成本可以大幅減少。如表 1 所示,GaLore 的記憶體效率比 LoRA 更高。實際上,與 LoRA 相比,在預訓練期間,這可減少高達 30% 的記憶體。
將梯度矩陣G 投影成低秩形式P^⊤GQ。在這種情況下,依賴元件梯度統計的 Optimizer States 的記憶體成本可以大幅減少。如表 1 所示,GaLore 的記憶體效率比 LoRA 更高。實際上,與 LoRA 相比,在預訓練期間,這可減少高達 30% 的記憶體。

本文證明了 GaLore 在預訓練和微調方面表現良好。當在 C4 資料集上預先訓練 LLaMA 7B 時,8-bit GaLore 結合了 8-bit 優化器和逐層權重更新技術,實現了與全秩相當的性能,並且 optimizer state 的記憶體成本不到 10%。
值得注意的是,對於預訓練,GaLore 在整個訓練過程中保持低內存,而不需要像 ReLoRA 那樣進行全秩訓練。由於 GaLore 的記憶體效率,這是首次可以在具有 24GB 記憶體的單一 GPU(例如,在 NVIDIA RTX 4090 上)上從頭開始訓練 LLaMA 7B,而無需任何昂貴的記憶體卸載技術(圖 1)。
作為一種梯度投影方法,GaLore 與優化器的選擇無關,只需兩行程式碼即可輕鬆插入現有優化器,如演算法1 所示。

下圖為將GaLore 套用到Adam 的演算法:

##實驗及結果
研究者對GaLore 的預訓練和LLM 的微調進行了評估。所有實驗均在英偉達 A100 GPU 上進行。
為了評估其效能,研究者應用 GaLore 在 C4 資料集上訓練基於 LLaMA 的大型語言模型。 C4 資料集是 Common Crawl 網路抓取語料庫的一個巨大的淨化版本,主要用於預訓練語言模型和單字表徵。為了最好地模擬實際的預訓練場景,研究者在不重複資料的情況下,對足夠大的資料量進行訓練,模型大小範圍可達 70 億個參數。
本文沿用了 Lialin 等人的實驗設置,採用了基於 LLaMA3 的架構,帶有 RMSNorm 和 SwiGLU 激活。對於每種模型大小,除了學習率之外,他們使用了相同的超參數集,並以BF16 格式運行所有實驗,以減少記憶體使用,同時在計算預算相同的情況下調整每種方法的學習率,並報告最佳性能。
此外,研究者使用 GLUE 任務作為 GaLore 與 LoRA 進行記憶體高效微調的基準。 GLUE 是評估 NLP 模型在各種任務中表現的基準,包括情緒分析、問題解答和文字關聯。
本文首先使用 Adam 最佳化器將 GaLore 與現有的低秩方法進行了比較,結果如表 2 所示。
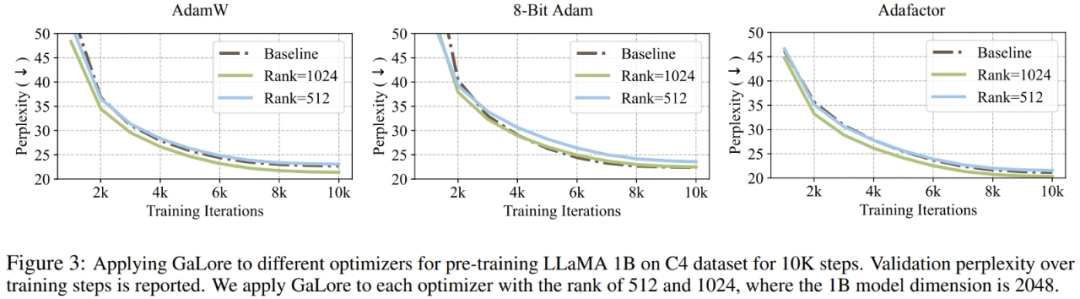
研究者證明,GaLore 可以應用於各種學習演算法,尤其是記憶體高效的最佳化器,以進一步減少記憶體佔用。研究者將 GaLore 應用於 AdamW、8 bit Adam 和 Adafactor 優化器。他們採用一階統計的 Adafactor,以避免效能下降。
實驗在具有 10K 訓練步數的 LLaMA 1B 架構上對它們進行了評估,調整了每種設定的學習率,並報告了最佳性能。如圖 3 所示,下圖表明,GaLore 可適用於流行的優化器,例如 AdamW、8-bit Adam 和 Adafactor。此外,引入極少數超參數不會影響 GaLore 的性能。
如表 4 所示,在大多數任務中,GaLore 都能以更少的記憶體佔用獲得比 LoRA 更高的效能。這表明,GaLore 可以作為一種全端記憶體高效訓練策略,用於 LLM 預訓練和微調。
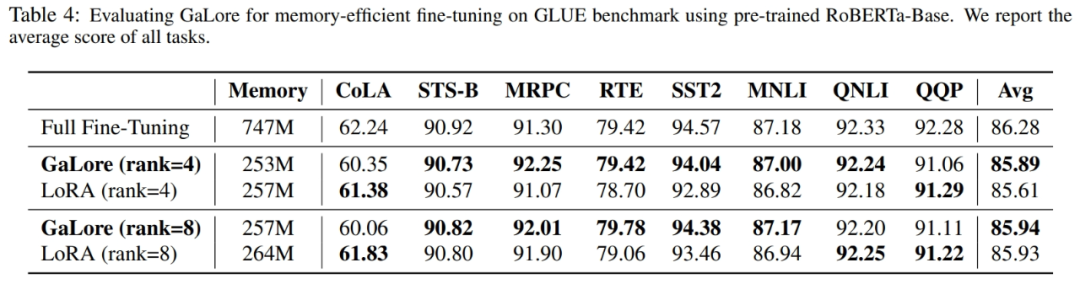
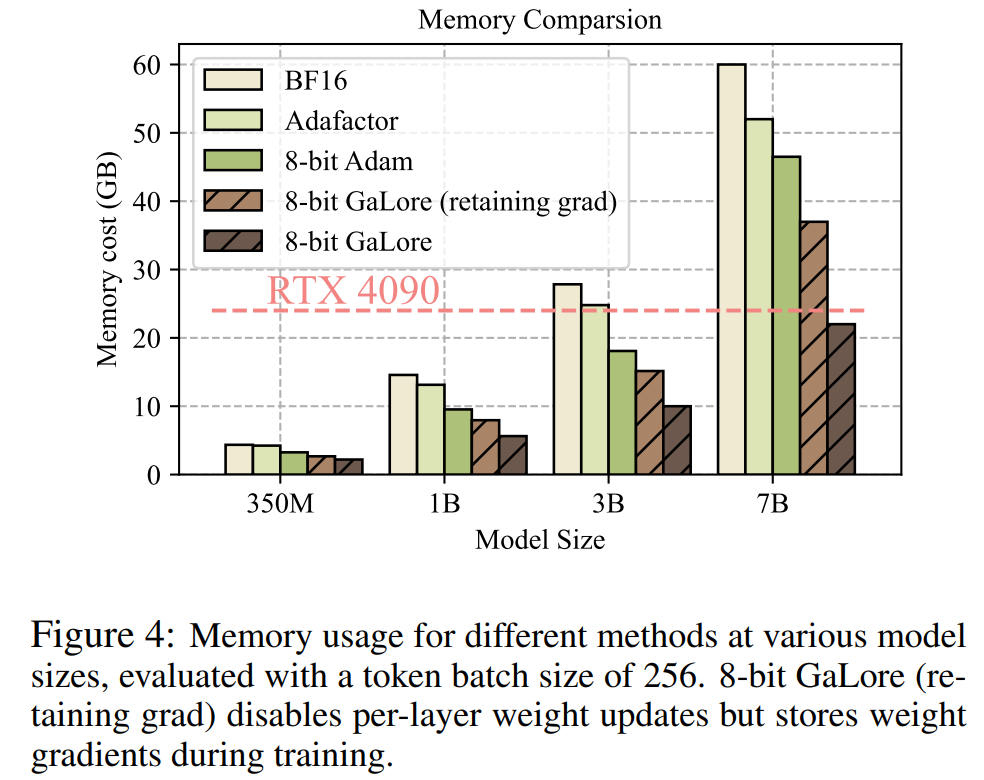
如圖4 所示,與BF16 基準和8 bit Adam 相比,8 bit GaLore 所需的記憶體要少得多,在預訓練LLaMA 7B 時僅需22.0G 內存,且每個GPU 的token 批量較小(最多500 個token)。
更多技術細節,請閱讀論文原文。
以上是田徑棟等人新作:突破記憶體瓶頸,讓一塊4090預訓練7B大模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
本月初,來自MIT等機構的研究者提出了一種非常有潛力的MLP替代方法—KAN。 KAN在準確性和可解釋性方面表現優於MLP。而且它能以非常少的參數量勝過以更大參數量運行的MLP。例如,作者表示,他們用KAN以更小的網路和更高的自動化程度重現了DeepMind的結果。具體來說,DeepMind的MLP有大約300,000個參數,而KAN只有約200個參數。 KAN與MLP一樣具有強大的數學基礎,MLP基於通用逼近定理,而KAN基於Kolmogorov-Arnold表示定理。如下圖所示,KAN在邊上具
 全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
為了將大型語言模型(LLM)與人類的價值和意圖對齊,學習人類回饋至關重要,這能確保它們是有用的、誠實的和無害的。在對齊LLM方面,一種有效的方法是根據人類回饋的強化學習(RLHF)。儘管RLHF方法的結果很出色,但其中涉及了一些優化難題。其中涉及訓練一個獎勵模型,然後優化一個策略模型來最大化該獎勵。近段時間已有一些研究者探索了更簡單的離線演算法,其中之一就是直接偏好優化(DPO)。 DPO是透過參數化RLHF中的獎勵函數來直接根據偏好資料學習策略模型,這樣就無需顯示式的獎勵模型了。此方法簡單穩定
 deepseek怎麼本地微調
Feb 19, 2025 pm 05:21 PM
deepseek怎麼本地微調
Feb 19, 2025 pm 05:21 PM
本地微調 DeepSeek 類模型面臨著計算資源和專業知識不足的挑戰。為了應對這些挑戰,可以採用以下策略:模型量化:將模型參數轉換為低精度整數,減少內存佔用。使用更小的模型:選擇參數量較小的預訓練模型,便於本地微調。數據選擇和預處理:選擇高質量的數據並進行適當的預處理,避免數據質量不佳影響模型效果。分批訓練:對於大數據集,分批加載數據進行訓練,避免內存溢出。利用 GPU 加速:利用獨立顯卡加速訓練過程,縮短訓練時間。
 Edge瀏覽器記憶體佔用太多怎麼辦 記憶體佔用太多的解決方法
May 09, 2024 am 11:10 AM
Edge瀏覽器記憶體佔用太多怎麼辦 記憶體佔用太多的解決方法
May 09, 2024 am 11:10 AM
1.首先,進入Edge瀏覽器點選右上角三個點。 2、然後,在工作列中選擇【擴充】。 3、接著,將不需要使用的插件關閉或卸載即可。
 無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。这一创新成果在代码生成任务取得了显著突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数
 LLM全搞定! OmniDrive:集3D感知、推理規劃於一體(英偉達最新)
May 09, 2024 pm 04:55 PM
LLM全搞定! OmniDrive:集3D感知、推理規劃於一體(英偉達最新)
May 09, 2024 pm 04:55 PM
寫在前面&筆者的個人理解這篇論文致力於解決當前多模態大語言模型(MLLMs)在自動駕駛應用中存在的關鍵挑戰,即將MLLMs從2D理解擴展到3D空間的問題。由於自動駕駛車輛(AVs)需要針對3D環境做出準確的決策,這項擴展顯得格外重要。 3D空間理解對於AV來說至關重要,因為它直接影響車輛做出明智決策、預測未來狀態以及與環境安全互動的能力。目前的多模態大語言模型(如LLaVA-1.5)通常只能處理較低解析度的影像輸入(例如),這是由於視覺編碼器的分辨率限制,LLM序列長度的限制。然而,自動駕駛應用需
 AI新創集體跳槽OpenAI,Ilya出走後安全團隊重整旗鼓!
Jun 08, 2024 pm 01:00 PM
AI新創集體跳槽OpenAI,Ilya出走後安全團隊重整旗鼓!
Jun 08, 2024 pm 01:00 PM
上週,在內部的離職潮和外部的口誅筆伐之下,OpenAI可謂是內憂外患:-侵權寡姐引發全球熱議-員工簽署“霸王條款”被接連曝出-網友細數奧特曼“七宗罪」闢謠:根據Vox獲取的洩漏資訊和文件,OpenAI的高級領導層,包括Altman在內,非常了解這些股權回收條款,並且簽署了它們。除此之外,還有一個嚴峻而迫切的問題擺在OpenAI面前——AI安全。最近,五名與安全相關的員工離職,其中包括兩名最著名的員工,「超級對齊」團隊的解散讓OpenAI的安全問題再次被置於聚光燈下。 《財星》雜誌報道稱,OpenA
 Yolov10:詳解、部署、應用一站式齊全!
Jun 07, 2024 pm 12:05 PM
Yolov10:詳解、部署、應用一站式齊全!
Jun 07, 2024 pm 12:05 PM
一、前言在过去的几年里,YOLOs由于其在计算成本和检测性能之间的有效平衡,已成为实时目标检测领域的主导范式。研究人员探索了YOLO的架构设计、优化目标、数据扩充策略等,取得了显著进展。同时,依赖非极大值抑制(NMS)进行后处理阻碍了YOLO的端到端部署,并对推理延迟产生不利影响。在YOLOs中,各种组件的设计缺乏全面彻底的检查,导致显著的计算冗余,限制了模型的能力。它提供了次优的效率,以及相对大的性能改进潜力。在这项工作中,目标是从后处理和模型架构两个方面进一步提高YOLO的性能效率边界。为此
