

讓大模型「瘦身」90%!清華&哈工大提出極限壓縮方案:1bit量化,能力同時保留83%

对大模型进行量化、剪枝等压缩操作,是部署时最常见不过的一环了。
不过,这个极限究竟有多大?
清华大学和哈工大的一项联合研究给出的答案是:
90%。
他们提出了大模型1bit极限压缩框架OneBit,首次实现大模型权重压缩超越90%并保留大部分(83%)能力。
可以说,玩儿的就是“既要也要”~

一起来看看。
大模型1bit量化方法来了
从剪枝、量化,到知识蒸馏、权重低秩分解,大模型已经可以实现压缩四分之一权重而几乎无损。
权重量化通常是将大型模型的参数转换为低位宽的表示形式。这可以通过对经过充分训练的模型进行转换(PTQ)或在训练过程中引入量化步骤(QAT)来实现。这种方法有助于减少模型的计算和存储需求,从而提高模型的效率和性能。通过量化权重,可以显著减少模型的大小,使其更适合在资源受限的环境中部署,同时也有
然而,现有量化方法在低于3bit时面临严重的性能损失,这主要是由于:
- 现有的参数低位宽表示方法在1bit时存在严重的精度损失。基于Round-To-Nearest方法的参数以1bit表示时,其转换的缩放系数s和零点z会失去实际意义。
- 现有的1bit模型结构没有充分考虑到浮点精度的重要性。浮点参数的缺失可能影响模型计算过程的稳定性,严重降低其本身的学习能力。
为了克服1bit超低位宽量化的阻碍,作者提出一种全新的1bit模型框架:OneBit,它包括全新的1bit线性层结构、基于SVID的参数初始化方法和基于量化感知知识蒸馏的深度迁移学习。
这种新的1bit模型量化方法能够以极大的压缩幅度、超低的空间占用和有限的计算成本,保留原模型绝大部分的能力。这对于实现大模型在PC端甚至智能手机上的部署意义非凡。
整体框架
OneBit框架总体上可以包括:全新设计的1bit模型结构、基于原模型初始化量化模型参数的方法以及基于知识蒸馏的深度能力迁移。
这种全新设计的1bit模型结构能够有效克服以往量化工作在1bit量化时严重的精度损失问题,并且在训练、迁移过程中表现出出色的稳定性。
量化模型的初始化方法能为知识蒸馏设置更好的起点,加速收敛的同时获得更加的能力迁移效果。
1、1bit模型结构
1bit要求每个权重值只能用1bit表示,所以最多只有两种可能的状态。
作者选用±1作为这两种状态,好处就是,它代表了数字系统中的两种符号、功能更加完备,同时可以通过Sign(·)函数方便地获得。
作者的1bit模型结构是通过把FP16模型的所有线性层(嵌入层和lm_head除外)替换为1bit线性层实现的。
这里的1bit线性层除通过Sign(·)函数获得的1bit权重之外,还包括另外两个关键组件—FP16精度的值向量。
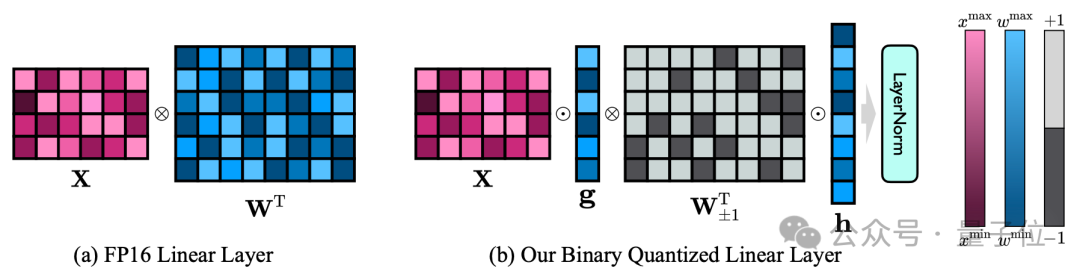
△FP16线性层与OneBit线性层的对比
这种设计不仅保持了原始权重矩阵的高秩,而且通过值向量提供了必要的浮点精度,对保证稳定且高质量的学习过程很有意义。
从上图可以看出,只有值向量g和h保持FP16格式,而权重矩阵则全部由±1组成。
作者通过一个例子可以一观OneBit的压缩能力。
假设压缩一个40964096的FP16线性层,OneBit需要一个40964096的1bit矩阵和两个4096*1的FP16值向量。
这里面总的位数为16,908,288,总的参数个数为16,785,408,平均每个参数占用仅仅约1.0073 bit。
这样的压缩幅度是空前的,可以说是真正的1bit LLM。
2、参数初始化和迁移学习
为了利用充分训练好的原模型更好地初始化量化后的模型,作者提出一种新的参数矩阵分解方法,称为“值-符号独立的矩阵分解(SVID)”。
这一矩阵分解方法把符号和绝对值分开,并把绝对值进行秩-1近似,其逼近原矩阵参数的方式可以表示成:
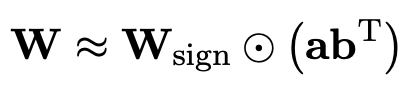
秩-1近似可以透過常用矩陣分解方法實現,例如奇異值分解(SVD)和非負矩陣分解(NMF)。
作者在數學上給出,這種SVID方法可以透過交換運算次序來和1bit模型框架相匹配,進而實現參數初始化。
此外,符號矩陣在分解過程中對近似原矩陣的貢獻也被證明,詳見論文。
作者認為,解決大模型超低位寬量化的有效途徑可能是量化感知訓練QAT。
因此,在SVID給出量化模型的參數起點後,作者把原模型當作教師模型並透過知識蒸餾從中學習。
具體而言,學生模型主要接受教師模式的logits和hidden state的指導。
訓練時,值向量和參數矩陣的值會被更新,而在部署時,則可以直接使用量化後的1bit參數矩陣來計算。
模型越大,效果越好
作者選擇的基線是FP16 Transformer、GPTQ、LLM-QAT和OmniQuant。
後三個都屬於量化領域中經典的強基線,特別是OmniQuant是自作者之前最強的2bit量化方法。
由於目前還沒有1bit權重量化的研究,作者只對OneBit框架使用1bit權重量化,而對其他方法採取2bit量化設定。
對於蒸餾數據,作者仿照LLM-QAT利用教師模型自採樣的方式產生數據。
作者從1.3B到13B不同大小、OPT和LLaMA-1/2不同系列的模型來證明OneBit的有效性。在評估指標上,使用驗證集的困惑度和常識推理的Zero-shot準確度。詳情見論文。
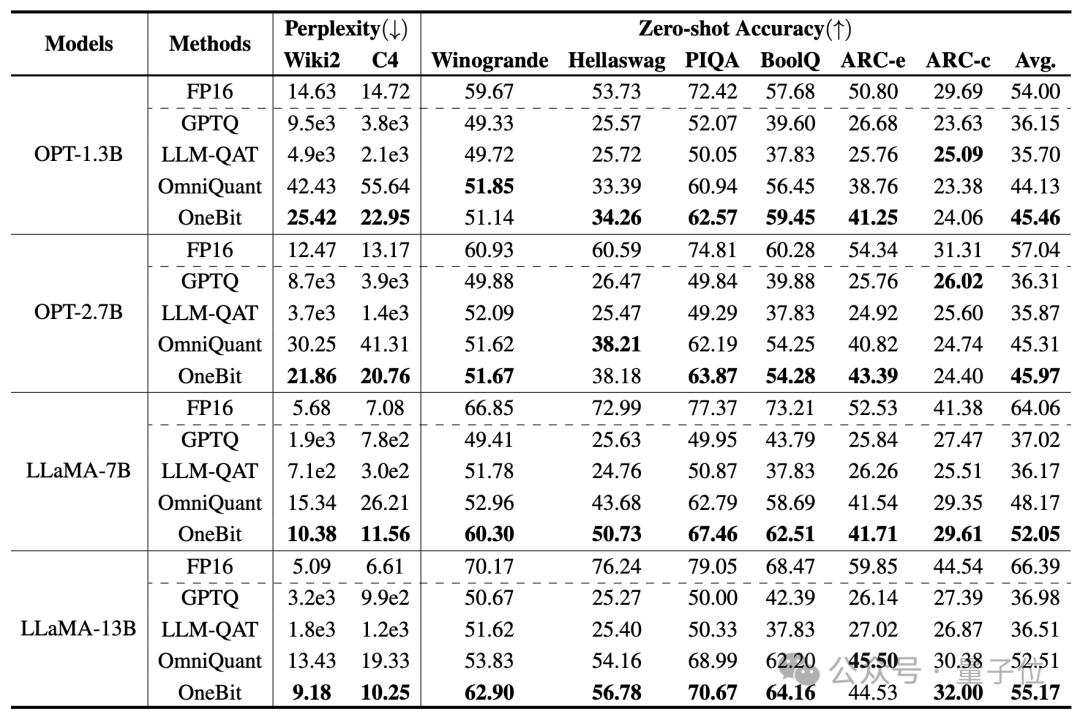
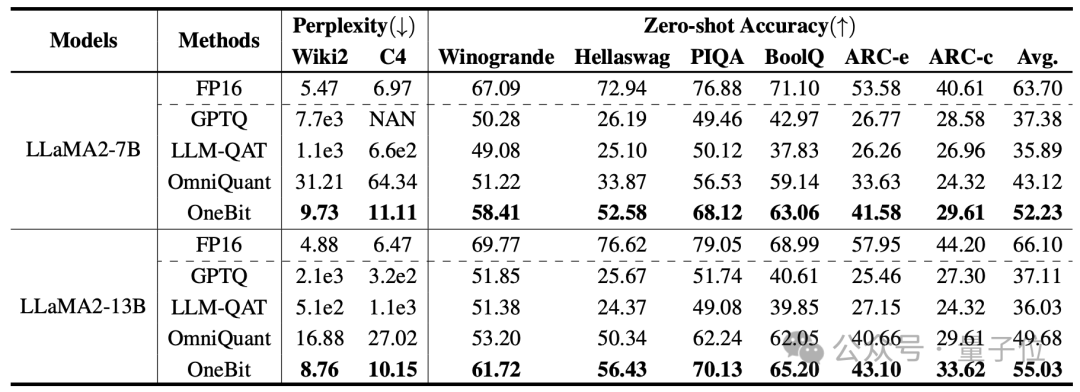
上表展示了OneBit比起其他方法在1bit量化時的優勢。 值得注意的是,模型越大時,OneBit效果往往越好。
隨著模型規模增加,OneBit量化模型降低的困惑度比FP16模型降低的困惑度要多。
以下是幾個不同小模型的常識推理、世界知識和空間佔用情況:
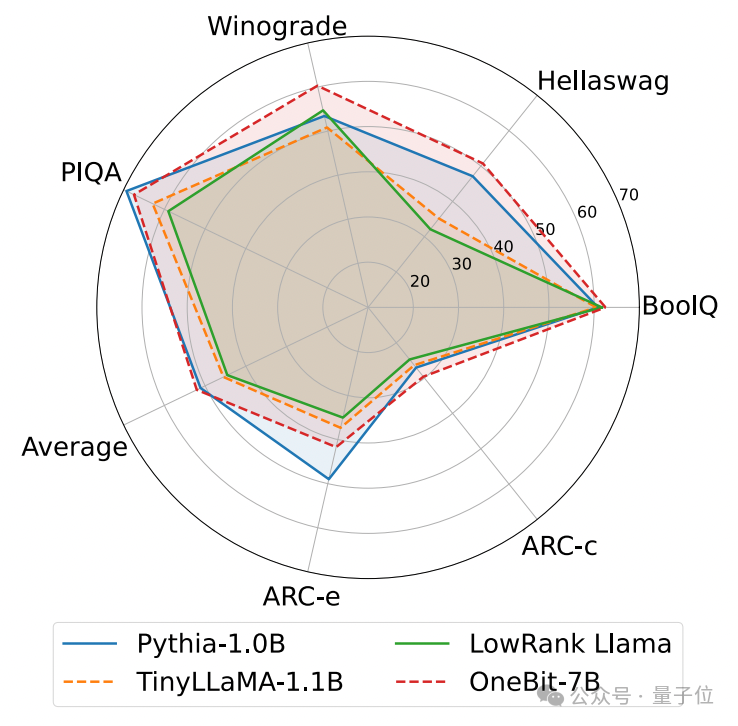
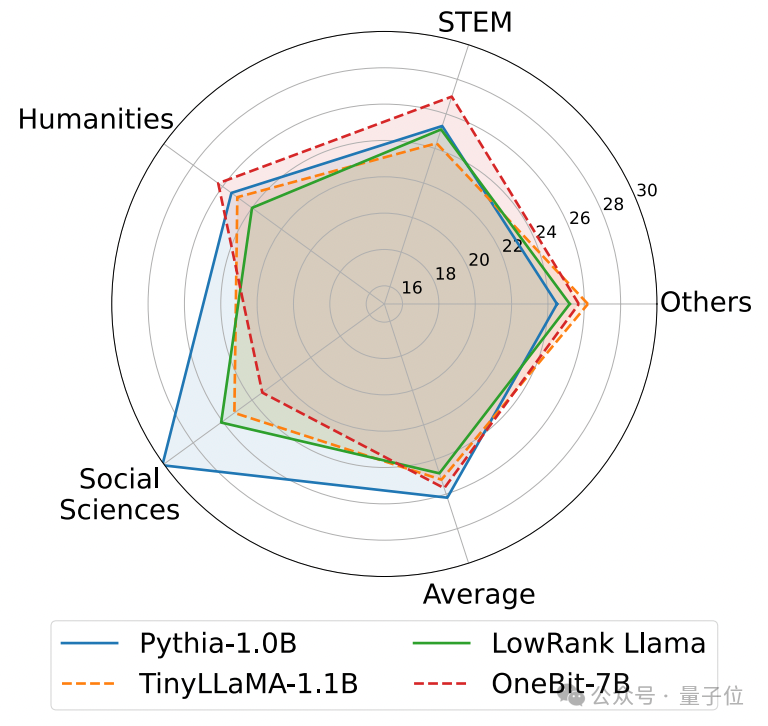
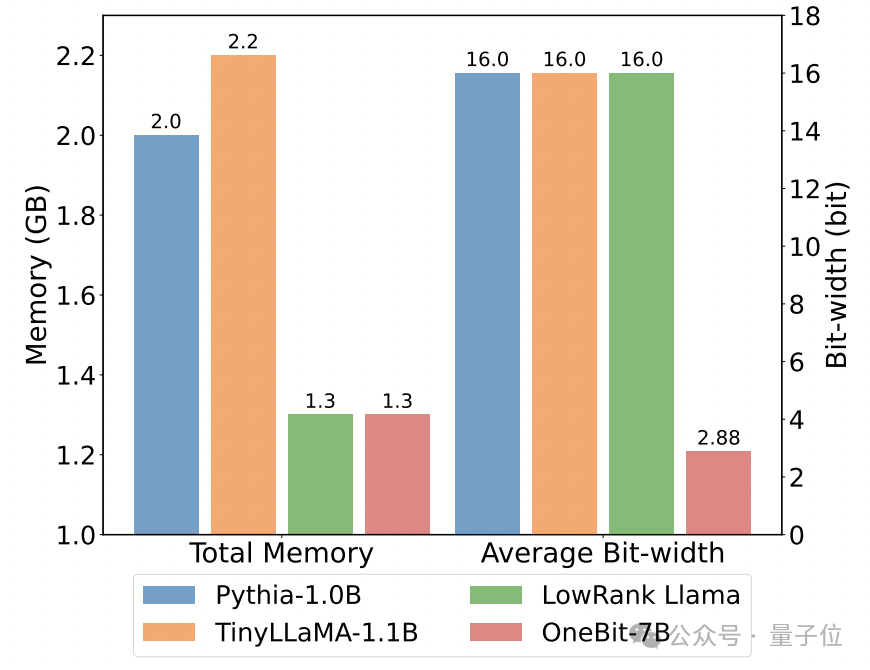
#作者也比較了幾種不同類型小模型的大小和實際能力。
作者發現,儘管OneBit-7B平均位寬最小、佔用的空間最小、訓練的步數也相對少,但它在常識推理能力上不遜於其他模型。
同時作者也發現,OneBit-7B模型在社會科學領域出現較嚴重的知識遺忘。

△FP16線性層與OneBit線性層的對比一個OneBit-7B指令微調後的文本生成範例
上圖也展示了一個OneBit- 7B指令微調後的文本生成範例。可見,OneBit-7B有效地受到了SFT階段的能力增益,可以比較流暢地生成文本,儘管總參數只有1.3GB(與FP16的0.6B模型相當)。總的來說,OneBit-7B展示了其實際應用價值。
分析與討論
作者展示了OneBit對不同規模LLaMA模型的壓縮比,可以看出,OneBit對模型的壓縮比均超過驚人的90%。
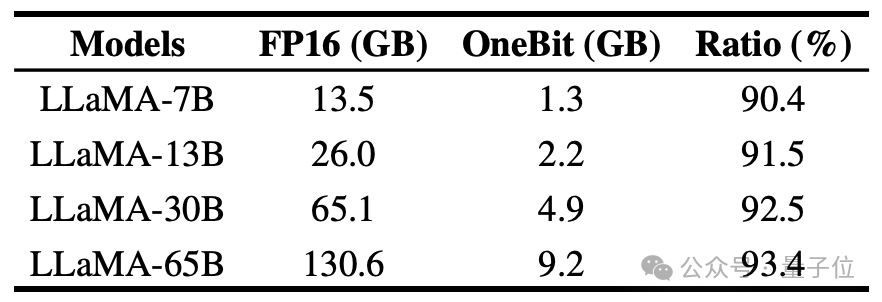
特別是,隨著模型增加,OneBit的壓縮比越高。
這顯示出作者方法在更大模型上的優勢:以更高的壓縮比獲得更大的邊際收益(困惑度)。此外,作者的方法在大小和性能之間做到了很好的權衡。 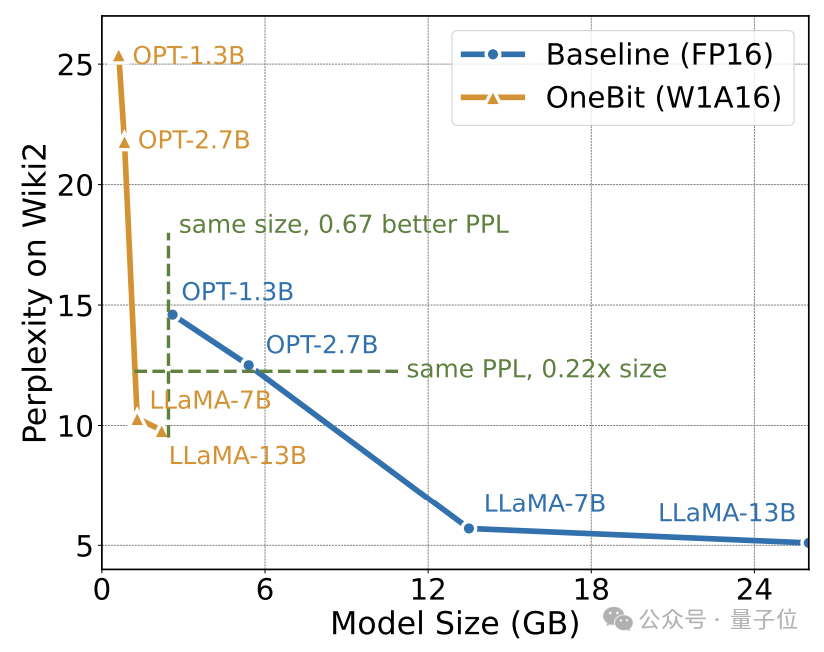
1bit量化模型在計算上有優勢,意義十分重大。參數的純二進位表示,不但可以節省大量的空間,還能降低矩陣乘法對硬體的需求。
高精度模型中矩陣乘法的元素相乘可以被變成高效率的位元運算,只需位元賦值和加法就可以完成矩陣乘積,非常有應用前景。
此外,作者的方法在訓練過程中保持了出色的穩定學習能力。
事實上,二值網路訓練的不穩定問題、對超參數的敏感度和收斂困難一直受到研究人員關注。
作者分析了高精度值向量在促進模型穩定收斂過程中的重要意義。
有前人工作提出過1bit模型架構並用於從頭訓練模型(如BitNet[1]),但它對超參數敏感且難以從充分訓練的高精度模型中遷移學習。作者也嘗試了BitNet在知識蒸餾的表現,發現其訓練還不夠穩定。
總結
作者提出了一個用於1bit權重量化的模型結構和對應的參數初始化方法。
在各種大小和系列的模型上進行的廣泛實驗表明,OneBit在代表性的強基線上具有明顯的優勢,並實現了模型大小與性能之間的良好折中。
此外,作者進一步分析了這種極低位元量化模型的能力和前景,並為未來的研究提供了指導。
論文網址: https://arxiv.org/pdf/2402.11295.pdf
以上是讓大模型「瘦身」90%!清華&哈工大提出極限壓縮方案:1bit量化,能力同時保留83%的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 C 中的chrono庫如何使用?
Apr 28, 2025 pm 10:18 PM
C 中的chrono庫如何使用?
Apr 28, 2025 pm 10:18 PM
使用C 中的chrono庫可以讓你更加精確地控制時間和時間間隔,讓我們來探討一下這個庫的魅力所在吧。 C 的chrono庫是標準庫的一部分,它提供了一種現代化的方式來處理時間和時間間隔。對於那些曾經飽受time.h和ctime折磨的程序員來說,chrono無疑是一個福音。它不僅提高了代碼的可讀性和可維護性,還提供了更高的精度和靈活性。讓我們從基礎開始,chrono庫主要包括以下幾個關鍵組件:std::chrono::system_clock:表示系統時鐘,用於獲取當前時間。 std::chron
 如何理解C 中的DMA操作?
Apr 28, 2025 pm 10:09 PM
如何理解C 中的DMA操作?
Apr 28, 2025 pm 10:09 PM
DMA在C 中是指DirectMemoryAccess,直接內存訪問技術,允許硬件設備直接與內存進行數據傳輸,不需要CPU干預。 1)DMA操作高度依賴於硬件設備和驅動程序,實現方式因係統而異。 2)直接訪問內存可能帶來安全風險,需確保代碼的正確性和安全性。 3)DMA可提高性能,但使用不當可能導致系統性能下降。通過實踐和學習,可以掌握DMA的使用技巧,在高速數據傳輸和實時信號處理等場景中發揮其最大效能。
 C 中的實時操作系統編程是什麼?
Apr 28, 2025 pm 10:15 PM
C 中的實時操作系統編程是什麼?
Apr 28, 2025 pm 10:15 PM
C 在實時操作系統(RTOS)編程中表現出色,提供了高效的執行效率和精確的時間管理。 1)C 通過直接操作硬件資源和高效的內存管理滿足RTOS的需求。 2)利用面向對象特性,C 可以設計靈活的任務調度系統。 3)C 支持高效的中斷處理,但需避免動態內存分配和異常處理以保證實時性。 4)模板編程和內聯函數有助於性能優化。 5)實際應用中,C 可用於實現高效的日誌系統。
 給MySQL表添加和刪除字段的操作步驟
Apr 29, 2025 pm 04:15 PM
給MySQL表添加和刪除字段的操作步驟
Apr 29, 2025 pm 04:15 PM
在MySQL中,添加字段使用ALTERTABLEtable_nameADDCOLUMNnew_columnVARCHAR(255)AFTERexisting_column,刪除字段使用ALTERTABLEtable_nameDROPCOLUMNcolumn_to_drop。添加字段時,需指定位置以優化查詢性能和數據結構;刪除字段前需確認操作不可逆;使用在線DDL、備份數據、測試環境和低負載時間段修改表結構是性能優化和最佳實踐。
 怎樣在C 中測量線程性能?
Apr 28, 2025 pm 10:21 PM
怎樣在C 中測量線程性能?
Apr 28, 2025 pm 10:21 PM
在C 中測量線程性能可以使用標準庫中的計時工具、性能分析工具和自定義計時器。 1.使用庫測量執行時間。 2.使用gprof進行性能分析,步驟包括編譯時添加-pg選項、運行程序生成gmon.out文件、生成性能報告。 3.使用Valgrind的Callgrind模塊進行更詳細的分析,步驟包括運行程序生成callgrind.out文件、使用kcachegrind查看結果。 4.自定義計時器可靈活測量特定代碼段的執行時間。這些方法幫助全面了解線程性能,並優化代碼。
 數字虛擬幣交易平台top10 安全可靠的十大數字貨幣交易所
Apr 30, 2025 pm 04:30 PM
數字虛擬幣交易平台top10 安全可靠的十大數字貨幣交易所
Apr 30, 2025 pm 04:30 PM
數字虛擬幣交易平台top10分別是:1. Binance,2. OKX,3. Coinbase,4. Kraken,5. Huobi Global,6. Bitfinex,7. KuCoin,8. Gemini,9. Bitstamp,10. Bittrex,這些平台均提供高安全性和多種交易選項,適用於不同用戶需求。
 量化交易所排行榜2025 數字貨幣量化交易APP前十名推薦
Apr 30, 2025 pm 07:24 PM
量化交易所排行榜2025 數字貨幣量化交易APP前十名推薦
Apr 30, 2025 pm 07:24 PM
交易所內置量化工具包括:1. Binance(幣安):提供Binance Futures量化模塊,低手續費,支持AI輔助交易。 2. OKX(歐易):支持多賬戶管理和智能訂單路由,提供機構級風控。獨立量化策略平台有:3. 3Commas:拖拽式策略生成器,適用於多平台對沖套利。 4. Quadency:專業級算法策略庫,支持自定義風險閾值。 5. Pionex:內置16 預設策略,低交易手續費。垂直領域工具包括:6. Cryptohopper:雲端量化平台,支持150 技術指標。 7. Bitsgap:
 deepseek官網是如何實現鼠標滾動事件穿透效果的?
Apr 30, 2025 pm 03:21 PM
deepseek官網是如何實現鼠標滾動事件穿透效果的?
Apr 30, 2025 pm 03:21 PM
如何實現鼠標滾動事件穿透效果?在我們瀏覽網頁時,經常會遇到一些特別的交互設計。比如在deepseek官網上,�...
