

1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT


论文地址:https://arxiv.org/abs/2307.09283
代码地址:https://github.com/THU-MIG/RepViT
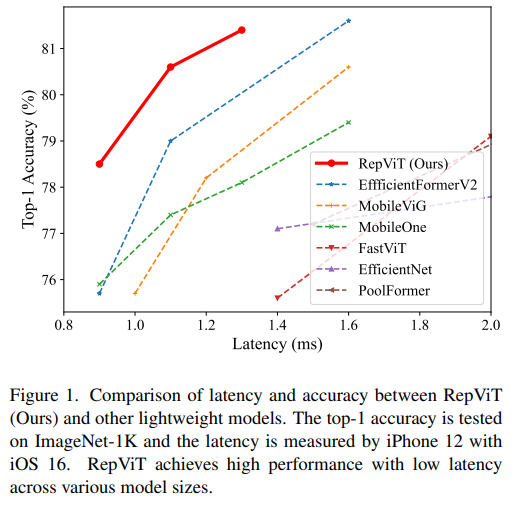
RepViT 在移动端 ViT 架构中表现出色,展现出显著的优势。接下来,我们将探讨本研究的贡献所在。
- 文中提到,轻量级 ViTs 通常比轻量级 CNNs 在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(
MSHA)可以让模型学习全局表示。然而,轻量级 ViTs 和轻量级 CNNs 之间的架构差异尚未得到充分研究。 - 在这项研究中,作者们通过整合轻量级 ViTs 的有效架构选择,逐步提升了标准轻量级 CNN(特别是
MobileNetV3的移动友好性。这便衍生出一个新的纯轻量级 CNN 家族的诞生,即RepViT。值得注意的是,尽管 RepViT 具有 MetaFormer 结构,但它完全由卷积组成。 - 实验结果表明,
RepViT超越了现有的最先进的轻量级 ViTs,并在各种视觉任务上显示出优于现有最先进轻量级ViTs的性能和效率,包括 ImageNet 分类、COCO-2017 上的目标检测和实例分割,以及 ADE20k 上的语义分割。特别地,在ImageNet上,RepViT在iPhone 12上达到了近乎 1ms 的延迟和超过 80% 的Top-1 准确率,这是轻量级模型的首次突破。
好了,接下来大家应该关心的应该时“如何设计到如此低延迟但精度还很6的模型”出来呢?
方法
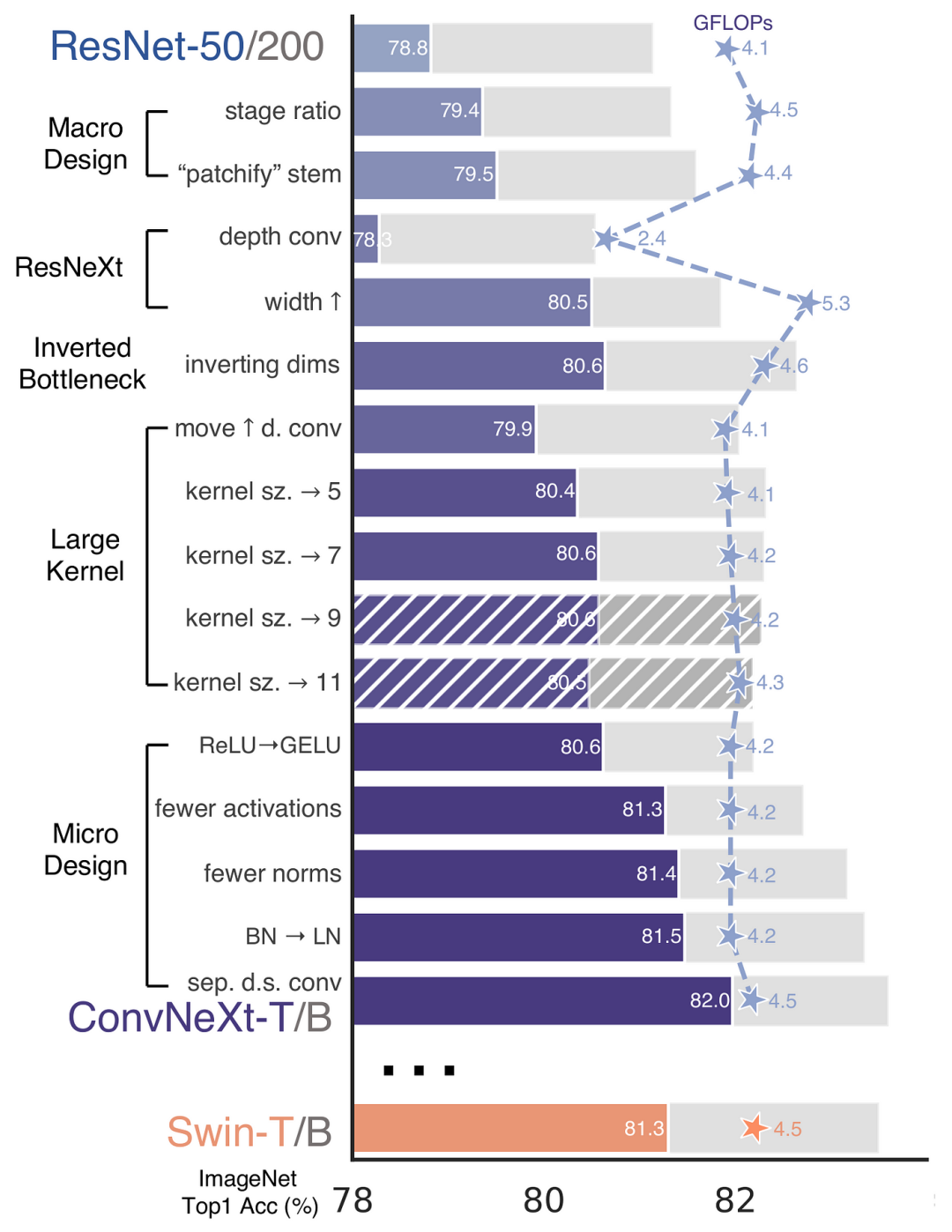
再 ConvNeXt 中,作者们是基于 ResNet50 架构的基础上通过严谨的理论和实验分析,最终设计出一个非常优异的足以媲美 Swin-Transformer 的纯卷积神经网络架构。同样地,RepViT也是主要通过将轻量级 ViTs 的架构设计逐步整合到标准轻量级 CNN,即MobileNetV3-L,来对其进行针对性地改造(魔改)。在这个过程中,作者们考虑了不同粒度级别的设计元素,并通过一系列步骤达到优化的目标。
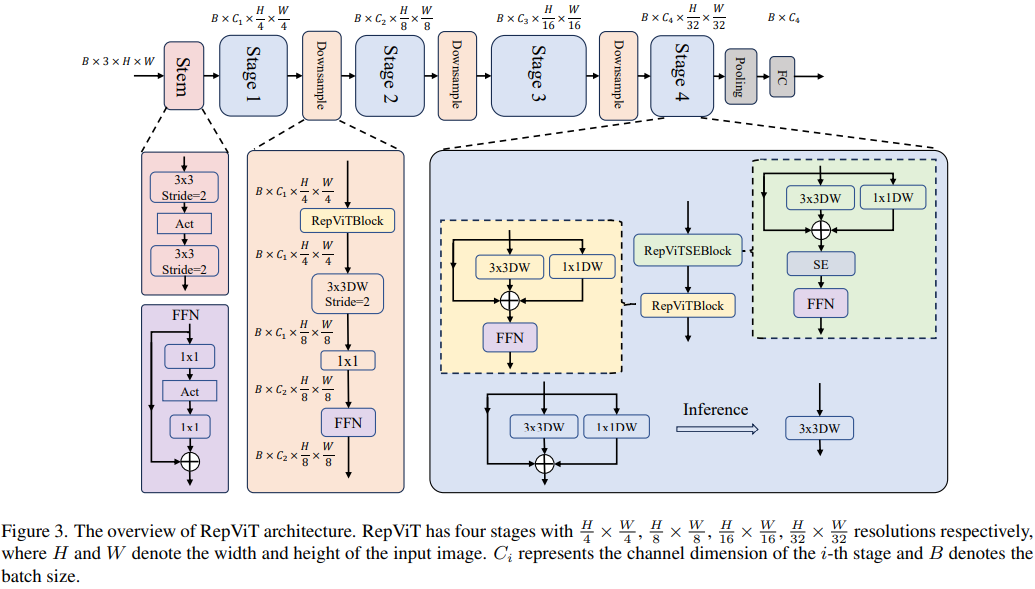
訓練配方的對齊
在論文中,新引入了一個用於衡量行動裝置上延遲的指標,並確保訓練策略與目前流行的輕量級ViTs 保持一致。這項措施的目的是為了確保模型訓練的一貫性,其中涉及延遲度量和訓練策略的調整兩個關鍵概念。
延遲度量指標
為了更準確地衡量模型在真實行動裝置上的效能,作者選擇了直接測量模型在裝置上的實際延遲,以此作為基準度量。這個度量方法不同於先前的研究,它們主要透過FLOPs或模型大小等指標來優化模型的推理速度,這些指標並不總是能很好地反映在行動應用中的實際延遲。
訓練策略的對齊
這裡,將 MobileNetV3-L 的訓練策略調整以與其他輕量級 ViTs 模型對齊。這包括使用 AdamW 優化器【ViTs 模型必備的優化器】,進行 5 個 epoch 的預熱訓練,以及使用餘弦退火學習率調度進行 300 個 epoch 的訓練。儘管這種調整導致了模型準確率的略微下降,但可以保證公平性。
區塊設計的最佳化
接下來,基於一致的訓練設置,作者們探索了最優的區塊設計。區塊設計是 CNN 架構中的重要組成部分,優化區塊設計有助於提高網路的效能。
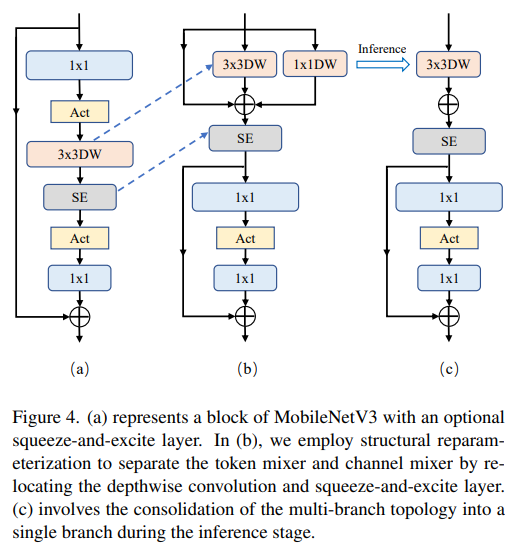
分離Token 混音器和通道混合器
這塊主要是對 MobileNetV3-L 的塊結構進行了改進,分離了令牌混合器和通道混合器。原來的 MobileNetV3 區塊結構包含一個 1x1 擴張卷積,然後是一個深度卷積和一個 1x1 的投影層,然後透過殘差連接連接輸入和輸出。在此基礎上,RepViT 將深度卷積提前,使得通道混合器和令牌混合器能夠被分開。為了提高性能,還引入了結構重參數化來在訓練時為深度濾波器引入多分支拓撲。最終,作者們成功地在 MobileNetV3 區塊中分離了令牌混合器和通道混合器,並將這種區塊命名為 RepViT 區塊。
降低擴張比例並增加寬度
在通道混合器中,原本的擴張比例是4,這表示MLP 區塊的隱藏維度是輸入維度的四倍,消耗了大量的計算資源,對推理時間有很大的影響。為了緩解這個問題,我們可以將擴張比例降低到 2,從而減少了參數冗餘和延遲,使得 MobileNetV3-L 的延遲降低到 0.65ms。隨後,透過增加網路的寬度,即增加各階段的通道數量,Top-1 準確率提高到 73.5%,而延遲只增加到 0.89ms!
宏觀架構元素的最佳化
在這一步,本文進一步優化了MobileNetV3-L在行動裝置上的效能,主要從宏觀架構元素出發,包括stem,降採樣層,分類器以及整體階段比例。透過優化這些宏觀架構元素,模型的效能可以顯著提高。
淺層網路使用卷積擷取器
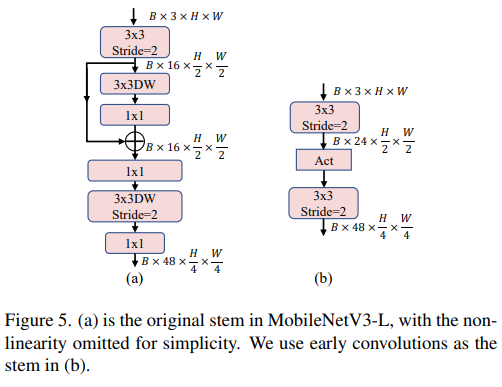 #圖片
#圖片
ViTs 通常使用一個將輸入影像分割成非重疊補丁的 "patchify" 操作作為 stem。然而,這種方法在訓練優化性和對訓練配方的敏感度上存在問題。因此,作者們採用了早期卷積來代替,這種方法已經被許多輕量級 ViTs 所採納。對比之下,MobileNetV3-L 使用了一個更複雜的 stem 進行 4x 下採樣。這樣一來,雖然濾波器的初始數量增加到24,但總的延遲降低到0.86ms,同時 top-1 準確率提高到 73.9%。
更深的下取樣層
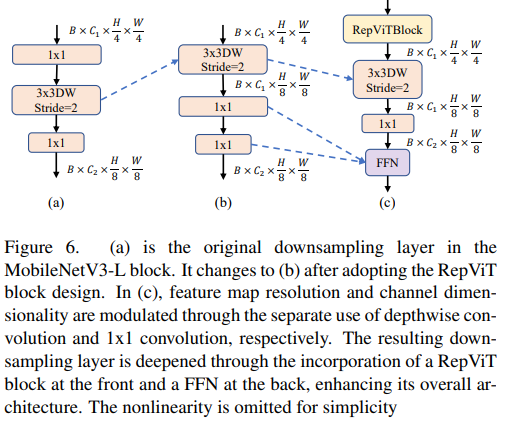
在 ViTs 中,空間下取樣通常透過一個單獨的補丁合併層來實現。因此這裡我們可以採用一個單獨且更深的下採樣層,以增加網路深度並減少因解析度降低而帶來資訊損失的程度。具體地,作者們首先使用一個 1x1 卷積來調整通道維度,然後將兩個 1x1 卷積的輸入和輸出通過殘差連接,形成一個前饋網路。此外,他們還在前面增加了 RepViT 區塊以進一步加深下取樣層,這一步提高了 top-1 準確率到 75.4%,同時延遲為 0.96ms。
更簡單的分類器
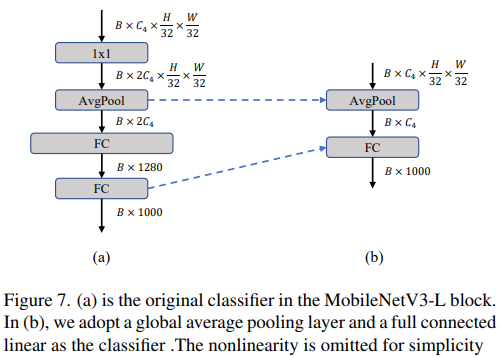
#在輕量級ViTs 中,分類器通常由一個全域平均池化層後面接一個線性層組成。相比之下,MobileNetV3-L 使用了一個更複雜的分類器。因為現在最後的階段有更多的通道,所以作者們將它替換為一個簡單的分類器,即一個全域平均池化層和一個線性層,這一步將延遲降低到0.77ms,同時top-1 準確率為74.8%。
整體階段比例
階段比例代表了不同階段中區塊數量的比例,從而表示了計算在各階段中的分佈。論文選擇了一個更優的階段比例 1:1:7:1,然後增加網路深度到 2:2:14:2,從而實現了一個更深的佈局。這一步驟將 top-1 準確率提高到 76.9%,同時延遲為 1.02 ms。
微觀設計的調整
接下來,RepViT 透過逐層微觀設計來調整輕量級CNN,這包括選擇合適的捲積核大小和優化擠壓-激勵(Squeeze- and-excitation,簡稱SE)層的位置。這兩種方法都能顯著改善模型效能。
卷積核大小的選擇
眾所周知,CNNs 的效能和延遲通常受到卷積核大小的影響。例如,為了建模像 MHSA 這樣的遠距離上下文依賴,ConvNeXt 使用了大卷積核,從而實現了顯著的效能提升。然而,大卷積核對於行動裝置並不友好,因為它的計算複雜性和記憶體存取成本。 MobileNetV3-L 主要使用 3x3 的捲積,有一部分區塊中使用 5x5 的捲積。作者們將它們替換為3x3的捲積,這導致延遲降低到 1.00ms,同時保持了76.9%的top-1準確率。
SE 層的位置
自註意力模組相對於卷積的一個優點是根據輸入調整權重的能力,這稱為資料驅動屬性。作為一個通道注意力模組,SE層可以彌補卷積在缺乏資料驅動屬性上的限制,從而帶來更好的效能。 MobileNetV3-L 在某些區塊中加入了SE層,主要集中在後兩個階段。然而,與分辨率較高的階段相比,分辨率較低的階段從SE提供的全局平均池化操作中獲得的準確率提升較小。作者們設計了一種策略,在所有階段以交叉塊的方式使用SE層,從而在最小的延遲增量下最大化準確率的提升,這一步將top-1準確率提升到77.4%,同時延遲降低到0.87ms。 【這點其實百度在很早前就已經做過實驗比對得到過這個結論了,SE 層放置在靠近深層的地方效果好】
網路架構
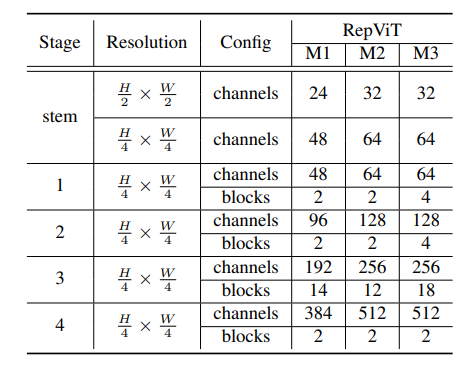
最終,透過整合上述改進策略,我們便得到了模型RepViT的整體架構,該模型有多個變種,例如RepViT-M1/ M2/M3。同樣地,不同的變種主要透過每個階段的通道數和區塊數來區分。
實驗
影像分類
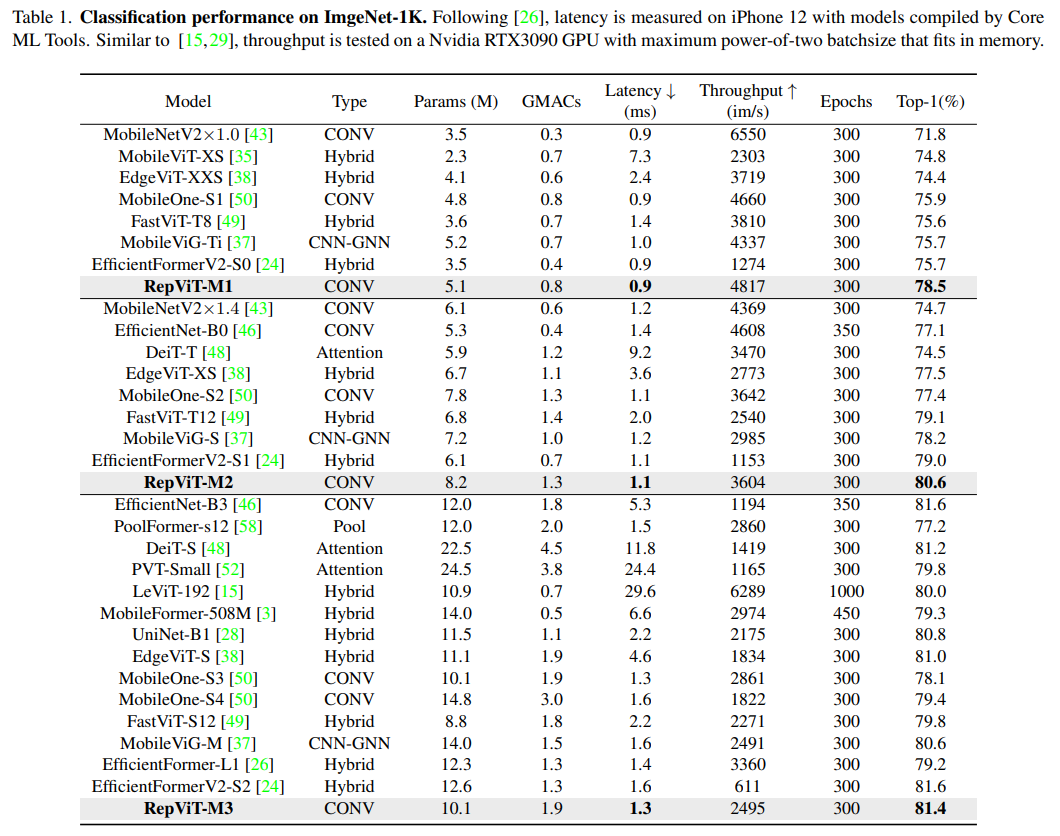
偵測與分割
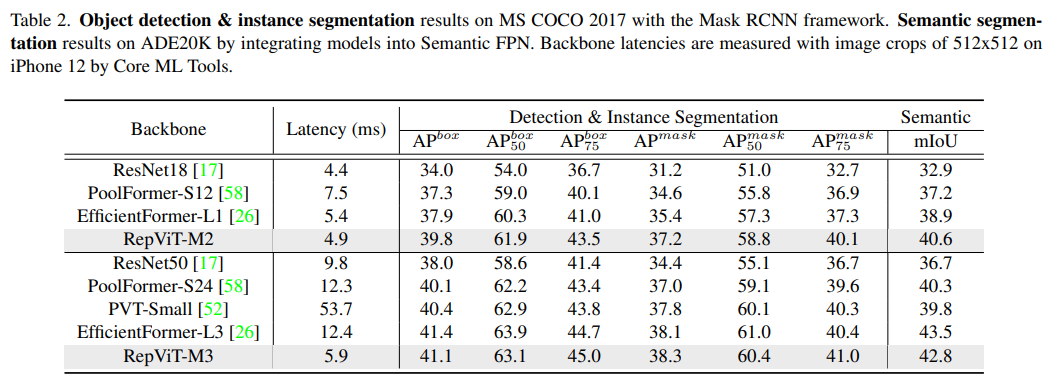
#總結
本文透過引入輕量級ViT 的架構選擇,重新審視了輕量級CNNs 的高效設計。這導致了 RepViT 的出現,這是一種新的輕量級 CNNs 家族,專為資源受限的行動裝置設計。在各種視覺任務上,RepViT 超越了現有的最先進的輕量級 ViTs 和 CNNs,顯示出優越的性能和延遲。這突顯了純粹的輕量級 CNNs 對行動裝置的潛力。
以上是1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 安幣app官方下載v2.96.2最新版安裝 安幣官方安卓版
Mar 04, 2025 pm 01:06 PM
安幣app官方下載v2.96.2最新版安裝 安幣官方安卓版
Mar 04, 2025 pm 01:06 PM
幣安App官方安裝步驟:安卓需訪官網找下載鏈接,選安卓版下載安裝;iOS在App Store搜“Binance”下載。均要從官方渠道,留意協議。
 在使用PHP調用支付寶EasySDK時,如何解決'Undefined array key 'sign'”報錯問題?
Mar 31, 2025 pm 11:51 PM
在使用PHP調用支付寶EasySDK時,如何解決'Undefined array key 'sign'”報錯問題?
Mar 31, 2025 pm 11:51 PM
問題介紹在使用PHP調用支付寶EasySDK時,按照官方提供的代碼填入參數後,運行過程中遇到報錯信息“Undefined...
 歐易ios版安裝包下載鏈接
Feb 21, 2025 pm 07:42 PM
歐易ios版安裝包下載鏈接
Feb 21, 2025 pm 07:42 PM
歐易是一款全球領先的加密貨幣交易所,其官方 iOS 應用程序可為用戶提供便捷安全的數字資產管理體驗。用戶可以通過本文提供的下載鏈接免費下載歐易iOS 版安裝包,享受以下主要功能:便捷的交易平台:用戶可以在歐易iOS 應用程序上輕鬆買賣數百種加密貨幣,包括比特幣、以太坊和Dogecoin。安全可靠的存儲:歐易採用先進的安全技術,為用戶提供安全可靠的數字資產存儲。 2FA、生物識別認證等安全措施確保用戶資產不受侵害。實時市場數據:歐易 iOS 應用程序提供實時的市場數據和圖表,讓用戶隨時掌握加密
 買虛擬幣的App蘋果怎麼安裝註冊?
Feb 21, 2025 pm 06:00 PM
買虛擬幣的App蘋果怎麼安裝註冊?
Feb 21, 2025 pm 06:00 PM
摘要:本文旨在指導用戶如何在蘋果設備上安裝和註冊虛擬貨幣交易應用程序。蘋果對於虛擬貨幣應用程序有嚴格的規定,因此用戶需要採取特殊步驟才能完成安裝過程。本文將詳細闡述所需的步驟,包括下載應用程序、創建賬戶,以及驗證身份。遵循本文的指南,用戶可以輕鬆地在蘋果設備上設置虛擬貨幣交易應用程序並開始交易。
 2018-2024年比特幣最新價格美元大全
Feb 15, 2025 pm 07:12 PM
2018-2024年比特幣最新價格美元大全
Feb 15, 2025 pm 07:12 PM
實時比特幣美元價格 影響比特幣價格的因素 預測比特幣未來價格的指標 以下是 2018-2024 年比特幣價格的一些關鍵信息:
 用iPhone手機怎麼打開XML文件
Apr 02, 2025 pm 11:00 PM
用iPhone手機怎麼打開XML文件
Apr 02, 2025 pm 11:00 PM
iPhone 上沒有內置 XML 查看器,可以使用第三方應用來打開 XML 文件,如 XML Viewer、JSON Viewer。方法:1. 在 App Store 下載並安裝 XML 查看器;2. 在 iPhone 上找到 XML 文件;3. 長按 XML 文件,選擇“共享”;4. 選擇已安裝的 XML 查看器應用;5. XML 文件將在該應用中打開。注意:1. 確保 XML 查看器兼容 iPhone iOS 版本;2. 輸入文件路徑時注意大小寫敏感;3. 謹慎處理包含外部實體的 XML 文
 如何通過CSS自定義resize符號並使其與背景色統一?
Apr 05, 2025 pm 02:30 PM
如何通過CSS自定義resize符號並使其與背景色統一?
Apr 05, 2025 pm 02:30 PM
CSS自定義resize符號的方法與背景色統一在日常開發中,我們經常會遇到需要自定義用戶界面細節的情況,比如調...
 全球十大虛擬幣交易平台app正版下載安裝教程
Mar 12, 2025 pm 05:33 PM
全球十大虛擬幣交易平台app正版下載安裝教程
Mar 12, 2025 pm 05:33 PM
本文提供Binance、OKX、Gate.io、Huobi Global(火幣)、Coinbase、KuCoin(庫幣)、Kraken和Bitfinex等主流數字貨幣交易平台的安卓和蘋果手機APP下載方法。無論是安卓用戶還是蘋果用戶,都能輕鬆找到對應平台的官方APP下載鏈接,並按照步驟完成安裝。 文章詳細指導了在各自官網或應用商店搜索下載,並針對安卓系統安裝APK文件的特殊步驟做了說明,方便用戶快速便捷地下載使用。
