

我們一起聊聊大模型的模型融合方法

在先前的實踐中,模型融合被廣泛運用,尤其在判別模型中,它被認為是一種能夠穩定提升性能的方法。然而,對於生成語言模型而言,由於其涉及解碼過程,其運作方式並不像判別模型那樣直截了當。
另外,由於大模型的參數量增大,在參數規模更大的場景,簡單的集成學習可以考慮的方法相比低參數的機器學習更受限制,比如經典的stacking,boosting等方法,因為堆疊模型的參數問題,無法簡單拓展。因此針對大模型的整合學習需要仔細考慮。
下面我們講解五種基本的整合方法,分別是 模型整合、機率整合、嫁接學習、眾包投票、MOE。
一、模型整合
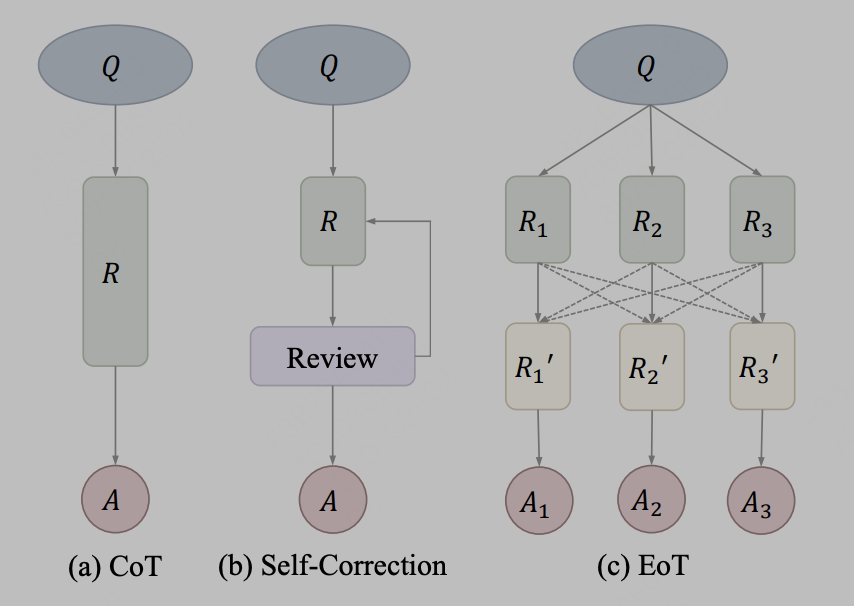
模型整合較為簡單,即大模型在輸出的文字層次進行融合,如簡單的使用3個不同的LLama模型的輸出結果,作為prompt輸入到第四個模型中進行參考。在實際中,訊息透過文字傳遞可以作為一種溝通方法,其代表性的方法為EoT,來自於文章《Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communication》,EoT提出了一個新的思想交流框架,即「交換思想」(Exchange-of-Thought),旨在促進模型之間的交叉通信,以提升問題解決過程中的集體理解。透過這個框架,模型可以吸收其他模型的推理,從而更好地協調和改進自身的解決方案。以論文中的圖示表示為:
 圖片
圖片
#作者將CoT和自修正方法視為同一概念後,EoT提供了一個新的方法,允許多個模型之間進行分層傳遞訊息。透過跨模型通信,模型可以相互借鑒推理和思考過程,有助於更有效地解決問題。這種方法有望提升模型的效能和準確性。
二、機率整合
機率整合與傳統的機器學習方法有著相似之處。例如,透過對模型預測的logit結果進行平均,可以形成一種整合方法。在大型模型中,機率整合可以在transformer模型的詞表輸出機率層次上進行融合。需要特別注意的是,這種操作要求融合的多個原始模型的詞表必須保持一致。這樣的整合方法可以提高模型的效能和穩健性,使其更適用於實際應用場景。
下面我們給一個簡單偽代碼的實作。
kv_cache = NoneWhile True:input_ids = torch.tensor([[new_token]], dtype=torch.long, device='cuda')kv_cache1, kv_cache2 = kv_cache output1 = models[0](input_ids=input_ids, past_key_values=kv_cache1, use_cache=True)output2 = models[1](input_ids=input_ids, past_key_values=kv_cache2, use_cache=True)kv_cache = [output1.past_key_values, output2.past_key_values]prob = (output1.logits + output2.logits) / 2new_token = torch.argmax(prob, 0).item()
三、嫁接學習
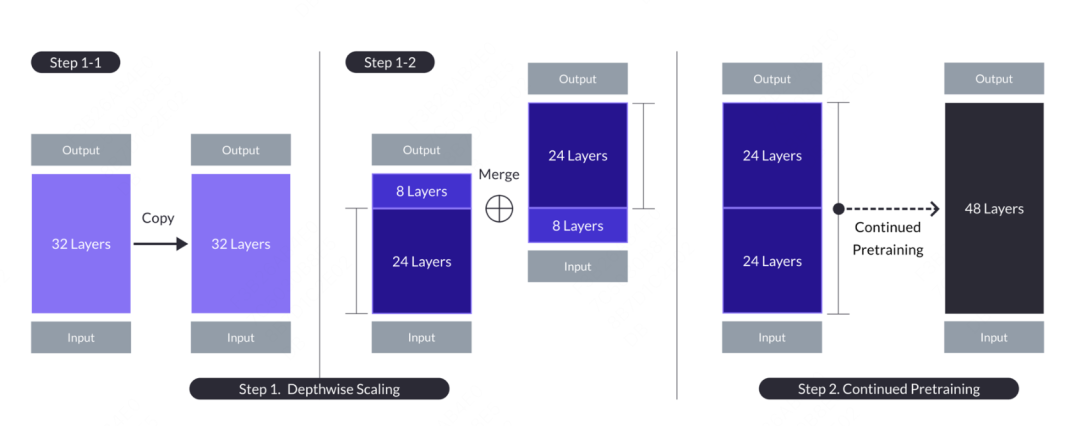
嫁接學習的概念來自於國內Kaggle Grandmaster的plantsgo,最早源自於資料探勘競賽。其本質上是一種遷移學習,一開始是用來描述將一個樹模型的輸出作為另一個樹模型的輸入的方法。此種方法與樹的繁殖中的嫁接類似,故而得名。在大模型中,也有嫁接學習的應用,其模型名字為SOLAR,文章來自《SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling》,文中提出了一個模型嫁接的一種思路,與機器學習中的嫁接學習不同的是,大模型並不會直接融合另一個模型的機率結果,而是將其中的部分結構和權重嫁接到融合模型上,並經過一定的繼續預訓練過程,使其模型參數能夠適應新的模型。具體的操作為,複製包含n層的基礎模型,以便後續修改。然後,從原始模型中移除最後的m層,並從其副本中移除最初的m層,從而形成兩個不同的n-m層模型。最後將這兩個模型連結起來,形成一個具有2*(n-m)層的縮放模型。
當需要建構一個48層的目標模型時,可以考慮從兩個32層的模型中各取前24層和後24層,將它們連接起來形成一個全新的48層模型。接著,對這個組合後的模型進行進一步的預訓練。一般來說,繼續預訓練所需的資料量和運算資源要比從零開始訓練少。
 圖片
圖片
在繼續預訓練之後,還需要進行對齊操作,包含兩個過程,分別是指令微調和DPO。指令微調採用開源instruct資料並改造出一個數學專用instruct數據,以增強模型的數學能力。 DPO是傳統的RLHF的替代,最終形成了SOLAR-chat版本。
四、眾包投票
眾包投票在今年的WSDM CUP第一名方案裡有所應用,在過往的國內生成比賽中大家也實踐過。其核心思想是:如果一個模型產生的句子,與所有模型的結果最像,那麼這個句子可以認為是所有模型的平均。這樣就把機率意義上的平均,變成了生成token結果的上的平均。假設給定一個測試樣本,我們有一個候選回答需要聚合,對於每一個候選,我們計算和)(之間的相關性分數並將它們加在一起作為的質量分數()。同樣地,相關性量化來源可以是嵌入層餘弦相似度(表示為emb_a_s)、詞級ROUGE-L(表示為word_a_f)和字元級ROUGE-L(表示為char_a_f)。這裡就是一些人工構造的相似度指標,包括字面上的和語意上的。
程式碼位址:https://github.com/zhangzhao219/WSDM-Cup-2024/tree/main
五、MoE
最後,也是最重要的大模型混合專家模型(Mixture of Experts,簡稱MoE),這是一種結合多個子模型(即「專家」)的模型架構方法,旨在透過多個專家的協同工作來提升整體的預測效果。MoE結構能夠顯著增強模型的處理能力和運行效率。典型的大模型MoE體系結構包含了一個門控機制(Gating Mechanism)和一系列專家網絡。門控機制負責依據輸入數據動態調製各個專家的權重,以此來決定每個專家對最終輸出的貢獻程度;同時,專家選擇機制會根據門控信號的指示,挑選出一部分專家來參與實際的預測計算。這種設計不僅降低了整體的運算需求,也使得模型能夠根據不同的輸入選擇最適用的專家。
混合專家模型(Mixture of Experts,MoE)並不是最近才有的新概念,混合專家模型的概念最早可以追溯到1991年發表的論文《Adaptive Mixture of Local Experts》。這種方法與集成學習有著相似之處,其核心是為由眾多獨立專家網絡構成的集合體創立一個協調融合機制。在這樣的架構下,每個獨立的網路(即「專家」)負責處理資料集中的特定子集,並且專注於特定的輸入資料區域。這個子集可能是偏向於某種話題,某種領域,某種問題分類等,並不是一個顯示的概念。
面對不同的輸入數據,一個關鍵的問題是系統如何決定由哪個專家來處理。門控網路(Gating Network)就是來解決這個問題的,它透過分配權重來確定各個專家的工作職責。在整個訓練過程中,這些專家網絡和門控網絡會被同時訓練,並不需要顯示的手動操控。
在2010年至2015年這段時間裡,有兩個研究方向對混合專家模型(MoE)的進一步發展產生了重要影響:
组件化专家:在传统的MoE框架中,系统由一个门控网络和若干个专家网络构成。在支持向量机(SVM)、高斯过程以及其他机器学习方法的背景下,MoE常常被当作模型中的一个单独部分。然而,Eigen、Ranzato和Ilya等研究者提出了将MoE作为深层网络中一个内部组件的想法。这种创新使得MoE可以被整合进多层网络的特定位置中,从而使模型在变得更大的同时,也能保持高效。
条件计算:传统神经网络会在每一层对所有输入数据进行处理。在这段时期,Yoshua Bengio等学者开始研究一种基于输入特征动态激活或者禁用网络部分的方法。
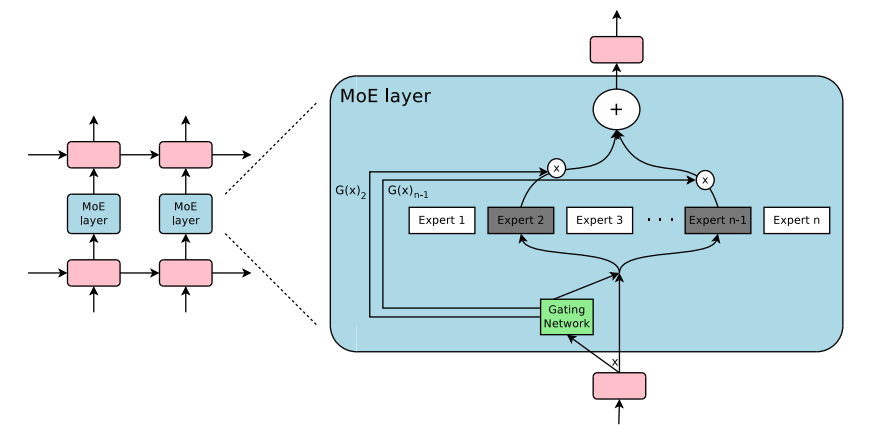
这两项研究的结合推动了混合专家模型在自然语言处理(NLP)领域的应用。尤其是在2017年,Shazeer和他的团队将这一理念应用于一个137亿参数的LSTM模型(这是当时在NLP领域广泛使用的一种模型架构,由Schmidhuber提出)。他们通过引入稀疏性来实现在保持模型规模巨大的同时,加快推理速度。这项工作主要应用于翻译任务,并且面对了包括高通信成本和训练稳定性问题在内的多个挑战。如图所示《Outrageously Large Neural Network》 中的MoE layer架构如下:
 图片
图片
传统的MoE都集中在非transfomer的模型架构上,大模型时代的transfomer模型参数量达百亿级,如何在transformer上应用MoE并且把参数扩展到百亿级别,并且解决训练稳定性和推理效率的问题,成为MoE在大模型应用上的关键问题。谷歌提出了代表性的方法Gshard,成功将Transformer模型的参数量增加至超过六千亿,并以此提升模型水平。
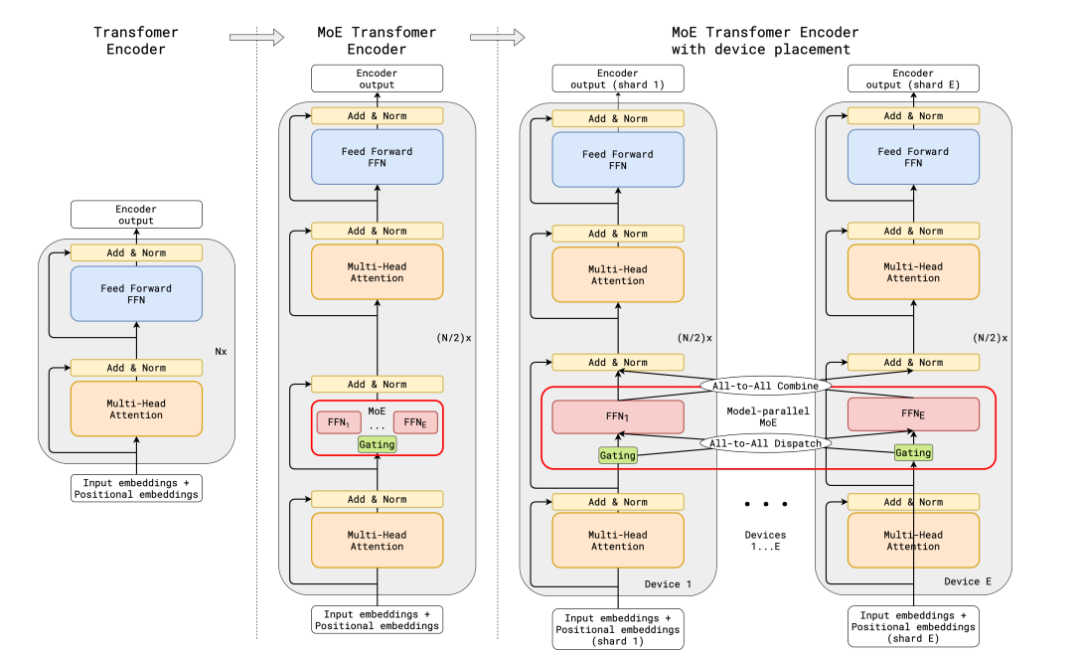
在GShard框架下,编码器和解码器中的每个前馈网络(FFN)层被一种采用Top-2门控机制的混合专家模型(MoE)层所替代。下面的图示展现了编码器的结构设计。这样的设计对于执行大规模计算任务非常有利:当模型被分布到多个处理设备上时,MoE层在各个设备间进行共享,而其他层则在每个设备上独立复制。其架构如下图所示:
 图片
图片
为了确保训练过程中的负载均衡和效率,GShard提出了三种关键的技术,分别是损失函数,随机路由机制,专家容量限制。
辅助负载均衡损失函数:损失函数考量某个专家的buffer中已经存下的token数量,乘上某个专家的buffer中已经存下的token在该专家上的平均权重,构建这样的损失函数能让专家负载保持均衡。
随机路由机制:在Top-2的机制中,我们总是选择排名第一的专家,但是排名第二的专家则是通过其权重的比例来随机选择的。
专家容量限制:我们可以设置一个阈值来限定一个专家能够处理的token数量。如果两个专家的容量都已经达到了上限,那么令牌就会发生溢出,这时token会通过残差连接传递到下一层,或者在某些情况下被直接丢弃。专家容量是MoE架构中一个非常关键的概念,其存在的原因是所有的张量尺寸在编译时都已经静态确定,我们无法预知会有多少token分配给每个专家,因此需要预设一个固定的容量限制。
需要注意的是,在推理阶段,只有部分专家会被激活。同时,有些计算过程是被所有token共享的,比如自注意力(self-attention)机制。这就是我们能够用相当于12B参数的稠密模型计算资源来运行一个含有8个专家的47B参数模型的原因。如果我们使用Top-2门控机制,模型的参数量可以达到14B,但是由于自注意力操作是专家之间共享的,实际在模型运行时使用的参数量是12B。
整个MoeLayer的原理可以用如下伪代码表示:
M = input.shape[-1] # input维度为(seq_len, batch_size, M),M是注意力输出embedding的维度reshaped_input = input.reshape(-1, M)gates = softmax(einsum("SM, ME -> SE", reshaped_input, Wg)) #输入input,Wg是门控训练参数,维度为(M, E),E是MoE层中专家的数量,输出每个token被分配给每个专家的概率,维度为(S, E)combine_weights, dispatch_mask = Top2Gating(gates) #确定每个token最终分配给的前两位专家,返回相应的权重和掩码dispatched_expert_input = einsum("SEC, SM -> ECM", dispatch_mask, reshaped_input) # 对输入数据进行排序,按照专家的顺序排列,为分发到专家计算做矩阵形状整合h = enisum("ECM, EMH -> ECH", dispatched_expert_input, Wi) #各个专家计算分发过来的input,本质上是几个独立的全链接层h = relu(h)expert_outputs = enisum("ECH, EHM -> ECM", h, Wo) #各个专家的输出outputs = enisum("SEC, ECM -> SM", combine_weights, expert_outputs) #最后,进行加权计算,得到最终MoE-layer层的输出outputs_reshape = outputs.reshape(input.shape) # 从(S, M)变成(seq_len, batch_size, M)關於在MoE的架構改進上,Switch Transformers設計了一個特殊的Switch Transformer層,該層能夠處理兩個獨立的輸入(即兩個不同的token),並配備了四個專家進行處理。與最初的top2專家的想法相反,Switch Transformers 採用了簡化的top1專家策略。如下圖所示:
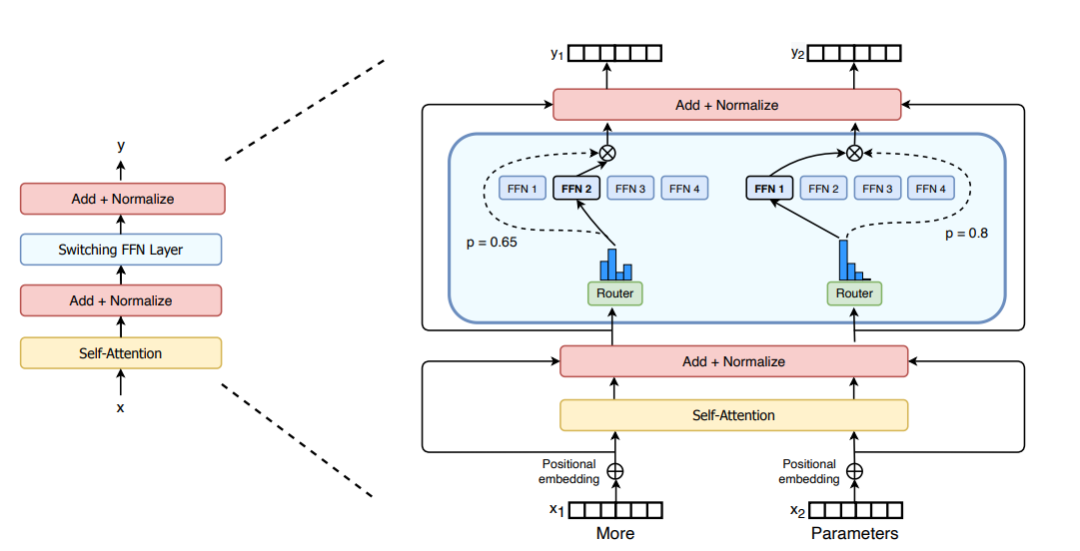 圖片
圖片
與之區別,國內知名大模型DeepSeek MoE的架構設計了一個共享專家,每次都參與激活,其設計基於這樣一個前提:某個特定的專家能夠精通特定的知識領域。透過將專家的知識領域進行細粒度的分割,可以防止單一專家需要掌握過多的知識面,從而避免知識的混雜。同時,設定共享專家能夠確保一些普遍適用的知識在每次計算時都能被利用。 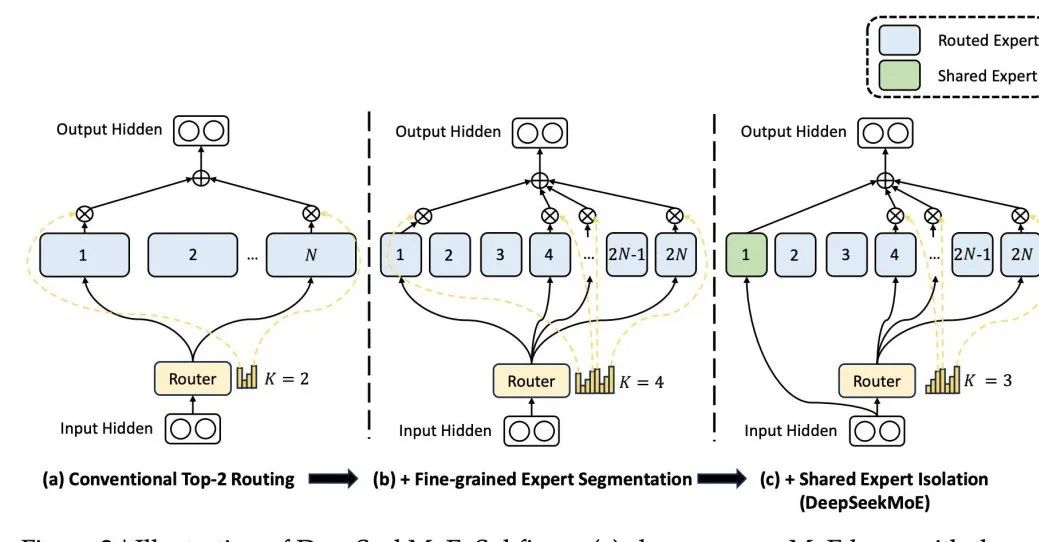 圖片
圖片
以上是我們一起聊聊大模型的模型融合方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 虛擬幣十大交易平台有哪些?全球十大虛擬幣交易平台排行
Feb 20, 2025 pm 02:15 PM
虛擬幣十大交易平台有哪些?全球十大虛擬幣交易平台排行
Feb 20, 2025 pm 02:15 PM
隨著加密貨幣的普及,虛擬幣交易平台應運而生。全球十大虛擬幣交易平台根據交易量和市場份額排名如下:幣安、Coinbase、FTX、KuCoin、Crypto.com、Kraken、Huobi、Gate.io、Bitfinex、Gemini。這些平台提供各種服務,從廣泛的加密貨幣選擇到衍生品交易,適合不同水平的交易者。
 芝麻開門交易所怎麼調成中文
Mar 04, 2025 pm 11:51 PM
芝麻開門交易所怎麼調成中文
Mar 04, 2025 pm 11:51 PM
芝麻開門交易所怎麼調成中文?本教程涵蓋電腦、安卓手機端詳細步驟,從前期準備到操作流程,再到常見問題解決,幫你輕鬆將芝麻開門交易所界面切換為中文,快速上手交易平台。
 Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap 圖片居中方法多樣,不一定要用 Flexbox。如果僅需水平居中,text-center 類即可;若需垂直或多元素居中,Flexbox 或 Grid 更合適。 Flexbox 兼容性較差且可能增加複雜度,Grid 則更強大且學習成本較高。選擇方法時應權衡利弊,並根據需求和偏好選擇最適合的方法。
 十大虛擬幣交易平台2025 加密貨幣交易app排名前十
Mar 17, 2025 pm 05:54 PM
十大虛擬幣交易平台2025 加密貨幣交易app排名前十
Mar 17, 2025 pm 05:54 PM
十大虛擬幣交易平台2025:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
 十大加密貨幣交易平台 幣圈交易平台app排行前十名推薦
Mar 17, 2025 pm 06:03 PM
十大加密貨幣交易平台 幣圈交易平台app排行前十名推薦
Mar 17, 2025 pm 06:03 PM
十大加密貨幣交易平台包括:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
 安全靠譜的數字貨幣平台有哪些
Mar 17, 2025 pm 05:42 PM
安全靠譜的數字貨幣平台有哪些
Mar 17, 2025 pm 05:42 PM
安全靠譜的數字貨幣平台:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
 c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
C35 的計算本質上是組合數學,代表從 5 個元素中選擇 3 個的組合數,其計算公式為 C53 = 5! / (3! * 2!),可通過循環避免直接計算階乘以提高效率和避免溢出。另外,理解組合的本質和掌握高效的計算方法對於解決概率統計、密碼學、算法設計等領域的許多問題至關重要。
 显著超越 SFT,o1/DeepSeek-R1 背后秘诀也能用于多模态大模型了
Mar 12, 2025 pm 01:03 PM
显著超越 SFT,o1/DeepSeek-R1 背后秘诀也能用于多模态大模型了
Mar 12, 2025 pm 01:03 PM
上海交大、上海AILab和港中文大学的研究人员推出Visual-RFT(视觉强化微调)开源项目,该项目仅需少量数据即可显著提升视觉语言大模型(LVLM)性能。Visual-RFT巧妙地将DeepSeek-R1的基于规则奖励的强化学习方法与OpenAI的强化微调(RFT)范式相结合,成功地将这一方法从文本领域扩展到视觉领域。通过为视觉细分类、目标检测等任务设计相应的规则奖励,Visual-RFT克服了DeepSeek-R1方法仅限于文本、数学推理等领域的局限性,为LVLM训练提供了新的途径。Vis
