

清華NLP組發布InfLLM:無需額外訓練,「1024K超長上下文」100%召回!

大型模型僅能記憶和理解有限的上下文,這已成為它們在實際應用中的一大製約。例如,對話型人工智慧系統常常無法持久記憶前一天的對話內容,這導致利用大型模型建構的智能體表現出前後不一致的行為和記憶。
為了讓大型模型能夠更好地處理更長的上下文,研究人員提出了一種名為InfLLM的新方法。這項方法由清華大學、麻省理工學院和人民大學的研究人員共同提出,它能夠使大型語言模型(LLM)無需額外的訓練就能夠處理超長文本。 InfLLM利用了少量的運算資源和顯存開銷,從而實現了對超長文本的高效處理。

論文網址:https://arxiv.org/abs/2402.04617
程式碼倉庫: https://github.com/thunlp/InfLLM
實驗結果表明,InfLLM能夠有效地擴展Mistral、LLaMA的上下文處理窗口,並在1024K上下文的海底撈針任務中實現100%召回。
研究背景
大規模預訓練語言模型(LLMs)近年來在眾多任務上取得了突破性的進展,成為眾多應用的基礎模型。
這些實際應用也對LLMs處理長序列的能力提出了更高的挑戰。例如,LLM驅動的智能體需要持續處理從外部環境接收的訊息,這要求它具備更強的記憶能力。同時,對話式人工智慧需要更好地記住與用戶的對話內容,以便產生更個人化的答案。
然而,目前的大型模型通常只在包含數千個Token的序列上進行預訓練,這導致將它們應用於超長文本時面臨兩大挑戰:
1. 分佈外長度:直接將LLMs應用到更長長度的文字中,往往需要LLMs處理超過訓練範圍的位置編碼,因而造成Out-of-Distribution問題,無法泛化;
#2. 注意力幹擾:##過長的上下文將使模型注意力被過度分散到無關的資訊中,因此無法有效建模上下文中遠距離語義依賴。
方法介紹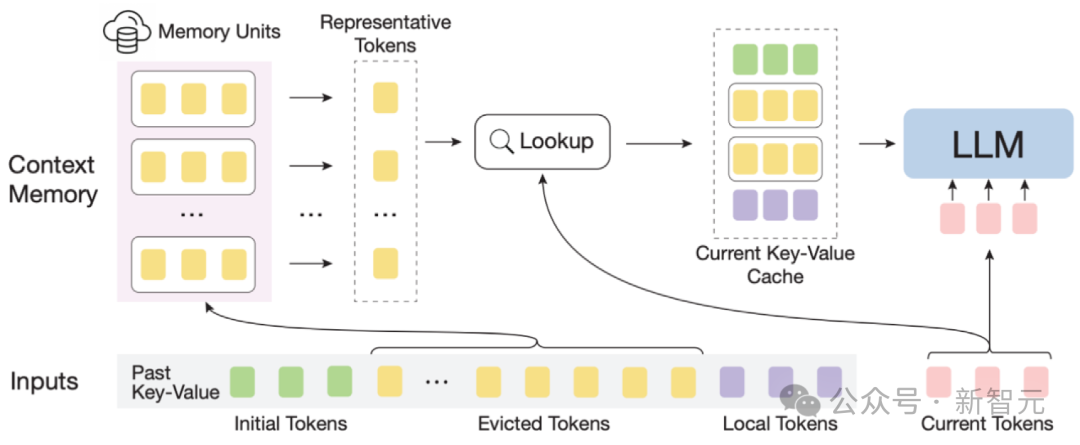
InfLLM示意圖
為了有效率地實作大模型的長度泛化能力,作者提出了一種無需訓練的記憶增強方法,InfLLM,用於流式地處理超長序列。
InfLLM旨在激發LLMs的內在能力,以有限的計算成本捕獲超長上下文中的長距離語義依賴關係,從而實現高效的長文本理解。
整體框架:考慮到長文字注意力的稀疏性,處理每個Token通常只需要其上下文的一小部分。
作者建立了一個外部記憶模組,用於儲存超長上下文資訊;採用滑動視窗機制,每個運算步驟,只有與當前Token距離相近的Tokens(Local Tokens)和外部記憶模組中的少量相關資訊參與注意力層的計算中,而忽略其他不相關的噪音。
因此,LLMs可以使用有限的視窗大小來理解整個長序列,並避免引入雜訊。
然而,超長序列中的海量上下文對於記憶模組中有效的相關資訊定位和記憶查找效率帶來了重大挑戰。
為了回應這些挑戰,上下文記憶模組中每個記憶單元由一個語意區塊構成,一個語意區塊由連續的若干Token構成。
具體而言, (1)為了有效定位相關記憶單元,每個語意區塊的連貫語意比碎片化的Token更能有效滿足相關資訊查詢的需求。
此外,作者從每個語意區塊中選擇語義上最重要的Token,即接收到注意力分數最高的Token,作為語義區塊的表示,這種方法有幫助於避免在相關性計算中不重要Token的干擾。
(2)为了高效的内存查找,语义块级别的记忆单元避免了逐Token,逐注意力的相关性计算,降低了计算复杂性。
此外,语义块级别的记忆单元确保了连续的内存访问,并减少了内存加载成本。
得益于此,作者设计了一种针对上下文记忆模块的高效卸载机制(Offloading)。
考虑到大多数记忆单元的使用频率不高,InfLLM将所有记忆单元卸载到CPU内存上,并动态保留频繁使用的记忆单元放在GPU显存中,从而显著减少了显存使用量。
可以将InfLLM总结为:
1. 在滑动窗口的基础上,加入远距离的上下文记忆模块。
2. 将历史上下文切分成语义块,构成上下文记忆模块中的记忆单元。每个记忆单元通过其在之前注意力计算中的注意力分数确定代表性Token,作为记忆单元的表示。从而避免上下文中的噪音干扰,并降低记忆查询复杂度
实验分析
作者在 Mistral-7b-Inst-v0.2(32K) 和 Vicuna-7b-v1.5(4K)模型上应用 InfLLM,分别使用4K和2K的局部窗口大小。
与原始模型、位置编码内插、Infinite-LM以及StreamingLLM进行比较,在长文本数据 Infinite-Bench 和 Longbench 上取得了显著的效果提升。
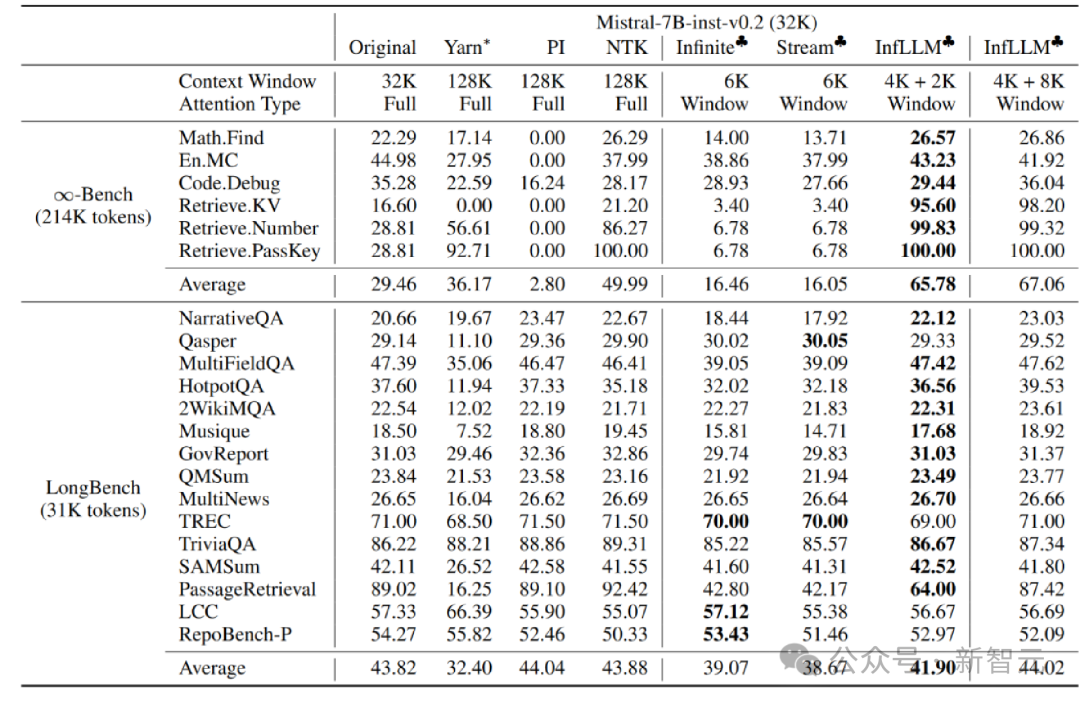
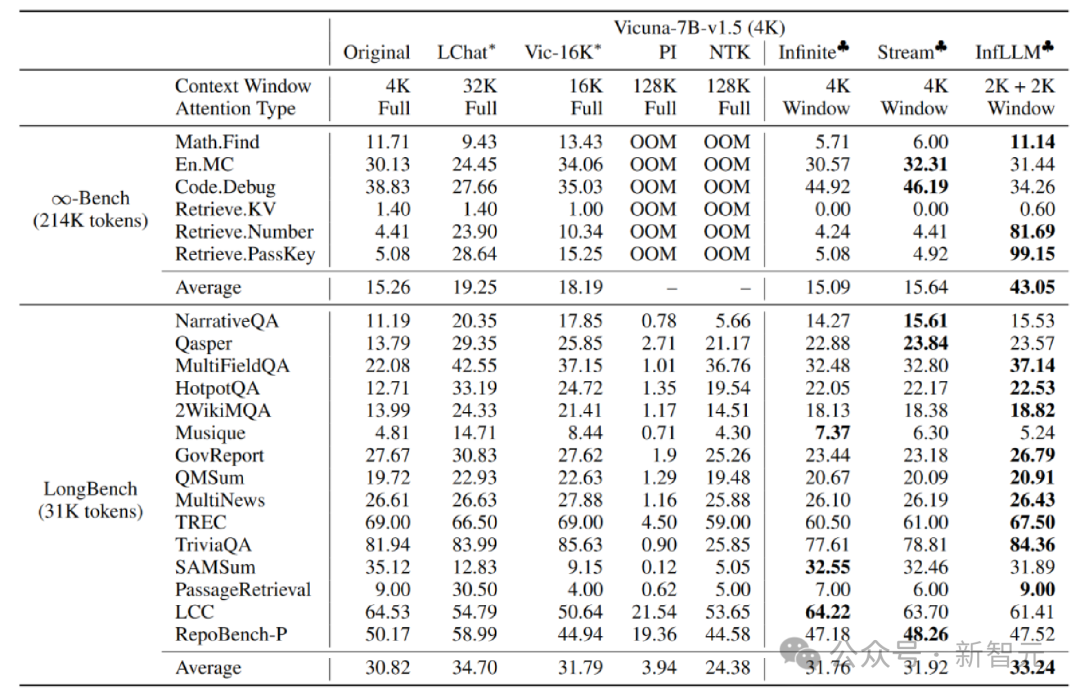
超长文本实验
此外,作者继续探索了 InfLLM 在更长文本上的泛化能力,在 1024K 长度的「海底捞针」任务中仍能保持 100% 的召回率。
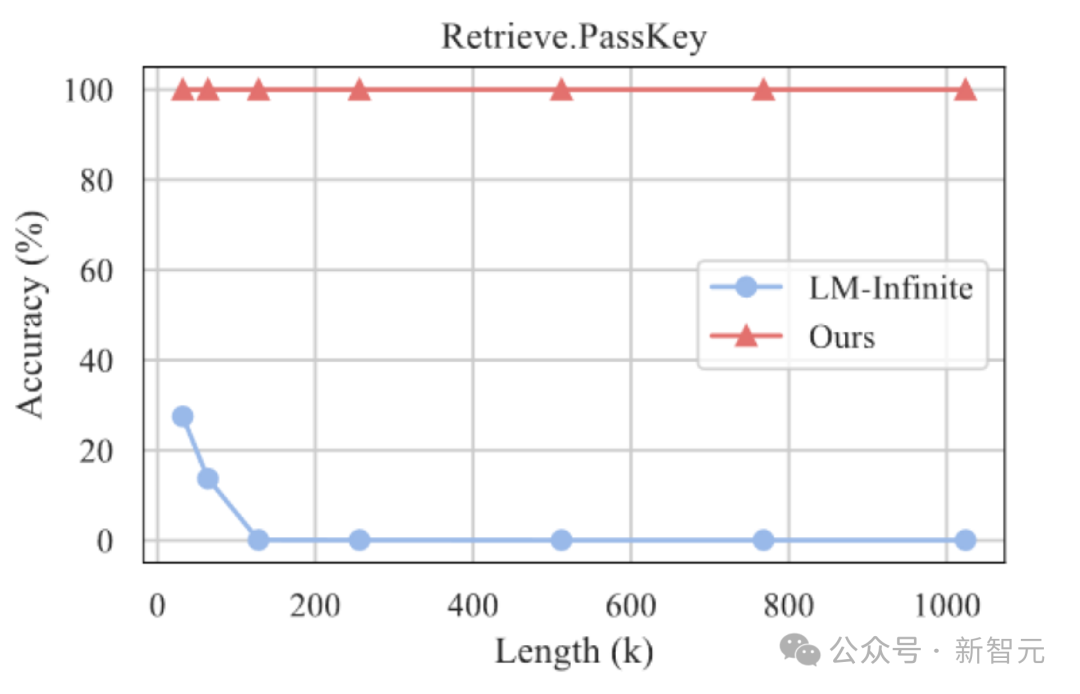
海底捞针实验结果
总结
在本文中,团队提出了 InfLLM,无需训练即可实现 LLM 的超长文本处理拓展,并可以捕捉到长距离的语义信息。
InfLLM 在滑动窗口的基础上,增加了包含长距离上下文信息的记忆模块,并使用缓存和offload 机制实现了少量计算和显存消耗的流式长文本推理。
以上是清華NLP組發布InfLLM:無需額外訓練,「1024K超長上下文」100%召回!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 centos關機命令行
Apr 14, 2025 pm 09:12 PM
centos關機命令行
Apr 14, 2025 pm 09:12 PM
CentOS 關機命令為 shutdown,語法為 shutdown [選項] 時間 [信息]。選項包括:-h 立即停止系統;-P 關機後關電源;-r 重新啟動;-t 等待時間。時間可指定為立即 (now)、分鐘數 ( minutes) 或特定時間 (hh:mm)。可添加信息在系統消息中顯示。
 如何檢查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
如何檢查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
檢查CentOS系統中HDFS配置的完整指南本文將指導您如何有效地檢查CentOS系統上HDFS的配置和運行狀態。以下步驟將幫助您全面了解HDFS的設置和運行情況。驗證Hadoop環境變量:首先,確認Hadoop環境變量已正確設置。在終端執行以下命令,驗證Hadoop是否已正確安裝並配置:hadoopversion檢查HDFS配置文件:HDFS的核心配置文件位於/etc/hadoop/conf/目錄下,其中core-site.xml和hdfs-site.xml至關重要。使用
 CentOS上GitLab的備份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS上GitLab的備份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS系統下GitLab的備份與恢復策略為了保障數據安全和可恢復性,CentOS上的GitLab提供了多種備份方法。本文將詳細介紹幾種常見的備份方法、配置參數以及恢復流程,幫助您建立完善的GitLab備份與恢復策略。一、手動備份利用gitlab-rakegitlab:backup:create命令即可執行手動備份。此命令會備份GitLab倉庫、數據庫、用戶、用戶組、密鑰和權限等關鍵信息。默認備份文件存儲於/var/opt/gitlab/backups目錄,您可通過修改/etc/gitlab
 CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
在CentOS系統上啟用PyTorchGPU加速,需要安裝CUDA、cuDNN以及PyTorch的GPU版本。以下步驟將引導您完成這一過程:CUDA和cuDNN安裝確定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA顯卡支持的CUDA版本。例如,您的MX450顯卡可能支持CUDA11.1或更高版本。下載並安裝CUDAToolkit:訪問NVIDIACUDAToolkit官網,根據您顯卡支持的最高CUDA版本下載並安裝相應的版本。安裝cuDNN庫:前
 docker原理詳解
Apr 14, 2025 pm 11:57 PM
docker原理詳解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux內核特性,提供高效、隔離的應用運行環境。其工作原理如下:1. 鏡像作為只讀模板,包含運行應用所需的一切;2. 聯合文件系統(UnionFS)層疊多個文件系統,只存儲差異部分,節省空間並加快速度;3. 守護進程管理鏡像和容器,客戶端用於交互;4. Namespaces和cgroups實現容器隔離和資源限制;5. 多種網絡模式支持容器互聯。理解這些核心概念,才能更好地利用Docker。
 centos安裝mysql
Apr 14, 2025 pm 08:09 PM
centos安裝mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安裝 MySQL 涉及以下步驟:添加合適的 MySQL yum 源。執行 yum install mysql-server 命令以安裝 MySQL 服務器。使用 mysql_secure_installation 命令進行安全設置,例如設置 root 用戶密碼。根據需要自定義 MySQL 配置文件。調整 MySQL 參數和優化數據庫以提升性能。
 CentOS下GitLab的日誌如何查看
Apr 14, 2025 pm 06:18 PM
CentOS下GitLab的日誌如何查看
Apr 14, 2025 pm 06:18 PM
CentOS系統下查看GitLab日誌的完整指南本文將指導您如何查看CentOS系統中GitLab的各種日誌,包括主要日誌、異常日誌以及其他相關日誌。請注意,日誌文件路徑可能因GitLab版本和安裝方式而異,若以下路徑不存在,請檢查GitLab安裝目錄及配置文件。一、查看GitLab主要日誌使用以下命令查看GitLabRails應用程序的主要日誌文件:命令:sudocat/var/log/gitlab/gitlab-rails/production.log此命令會顯示produc
 CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系統上進行PyTorch分佈式訓練,需要按照以下步驟操作:PyTorch安裝:前提是CentOS系統已安裝Python和pip。根據您的CUDA版本,從PyTorch官網獲取合適的安裝命令。對於僅需CPU的訓練,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,請確保已安裝對應版本的CUDA和cuDNN,並使用相應的PyTorch版本進行安裝。分佈式環境配置:分佈式訓練通常需要多台機器或單機多GPU。所
