

用Vision Pro即時訓練機器狗! MIT博士生開源專案火了

Vision Pro又現火爆新玩法,這回還和具身智能聯動了~
#就像這樣,MIT小哥利用Vision Pro的手部追蹤功能,成功實現了對機器狗的即時控制。

不只是開門這樣的動作能精準get:

也幾乎沒什麼延遲。

Demo一出,不只網友們大讚鵝妹嚶,各路具身智慧研究人員也嗨了。
例如這位準清華叉院博士生:

還有人大膽預測:這就是我們與下一代機器互動的方式。

專案如何實現,作者小哥樸英孝(Younghyo Park)已經在GitHub上開源。相關App可以直接在Vision Pro的App Store下載。
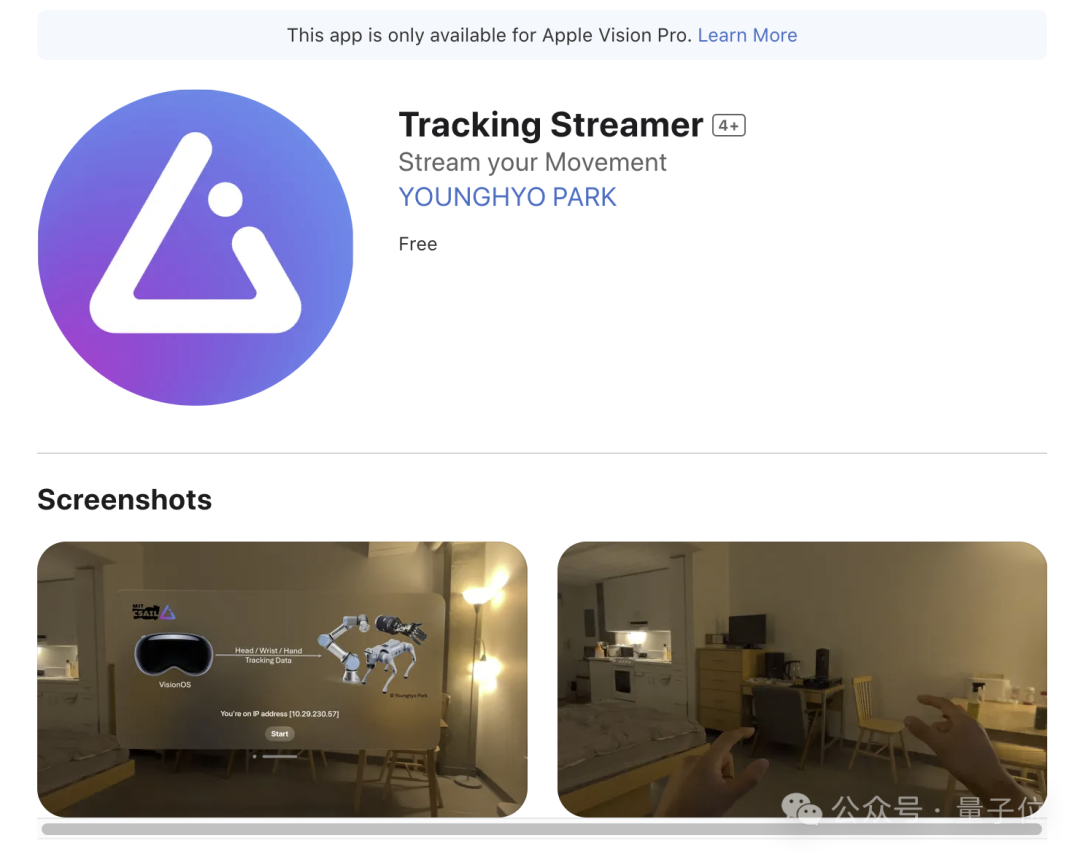
用Vision Pro訓練機器狗
具體來看看作者小哥開發的App——Tracking Steamer。
顧名思義,這個應用程式旨在利用Vision Pro追蹤人類動作,並將這些動作資料即時傳輸到同一WiFi下的其他機器人設備上。
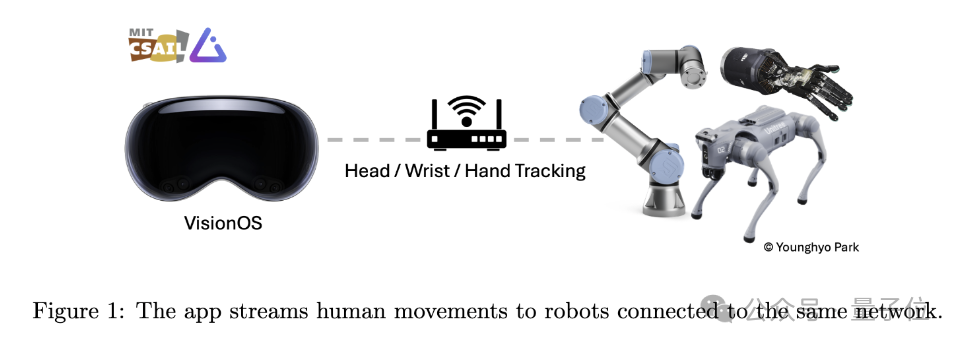
動作追蹤的部分,主要依靠蘋果的ARKit庫來實現。
其中頭部追蹤呼叫的是queryDeviceAnchor。使用者可以透過長按數字錶冠來重置頭部框架到目前位置。
手腕和手指追蹤則透過HandTrackingProvider實現。它能夠追蹤左右手腕相對於地面框架的位置和方向,以及每隻手25個手指關節相對於手腕框架的姿態。

網路通訊方面,這個App使用gRPC作為網路通訊協定來串流資料。這使得數據能被更多裝置訂閱,包括Linux、Mac和Windows設備。
另外,為了方便資料傳輸,作者小哥也準備了一個Python API,讓開發者能夠透過程式設計方式訂閱和接收從Vision Pro串流的追蹤資料。
API傳回的資料是字典形式,包含頭部、手腕、手指的SE(3)姿態訊息,即三維位置和方向。開發者可以直接在Python中處理這些數據,用於對機器人的進一步分析和控制。
就像不少專業人士所指出的那樣,別看機器狗的動作還是由人類控制,事實上,相較於「操控」本身,結合模仿學習演算法,人類在這個過程中,更像是機器人的教練。
而Vision Pro透過追蹤使用者的動作,提供了一種直覺、簡單的互動方式,使得非專業人員也能夠為機器人提供精準的訓練資料。
作者本人也在論文中寫道:
在不久的將來,人們可能會像日常戴眼鏡一樣佩戴Vision Pro這樣的設備,想像一下我們可以從這個過程中收集多少數據!
這是一個充滿前景的資料來源,機器人可以從中學習到,人類是如何與現實世界互動的。
最後,提醒一下,如果你想上手試試這個開源項目,那麼除了必備一台Vision Pro之外,還需要準備:
- 蘋果開發者帳號
- Vision Pro開發者配件(Developer Strap,售價299美元)
- 安裝了Xcode的Mac電腦
嗯,看樣子還是得先讓蘋果賺一筆了(doge)。
專案連結:https://github.com/Improbable-AI/VisionProTeleop?tab=readme-ov-file
以上是用Vision Pro即時訓練機器狗! MIT博士生開源專案火了的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
0.這篇文章乾了啥?提出了DepthFM:一個多功能且快速的最先進的生成式單目深度估計模型。除了傳統的深度估計任務外,DepthFM還展示了在深度修復等下游任務中的最先進能力。 DepthFM效率高,可以在少數推理步驟內合成深度圖。以下一起來閱讀這項工作~1.論文資訊標題:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 拋棄編碼器-解碼器架構,用擴散模型做邊緣偵測效果更好,國防科大提出DiffusionEdge
Feb 07, 2024 pm 10:12 PM
拋棄編碼器-解碼器架構,用擴散模型做邊緣偵測效果更好,國防科大提出DiffusionEdge
Feb 07, 2024 pm 10:12 PM
目前的深度邊緣檢測網路通常採用編碼器-解碼器架構,其中包含上下採樣模組,以更好地提取多層次的特性。然而,這種結構限制了網路輸出準確且細緻的邊緣檢測結果。針對這個問題,一篇AAAI2024的論文給了新的解決方案。論文題目:DiffusionEdge:DiffusionProbabilisticModelforCrispEdgeDetection作者:葉雲帆(國防科技大學),徐凱(國防科技大學),黃雨行(國防科技大學),易任嬌(國防科技大學),蔡志平(國防科技大學)論文連結:https ://ar
 通義千問再開源,Qwen1.5帶來六種體量模型,表現超越GPT3.5
Feb 07, 2024 pm 10:15 PM
通義千問再開源,Qwen1.5帶來六種體量模型,表現超越GPT3.5
Feb 07, 2024 pm 10:15 PM
趕在春節前,通義千問大模型(Qwen)的1.5版上線了。今天上午,新版本的消息引發了AI社群關注。新版大機型包括六個型號尺寸:0.5B、1.8B、4B、7B、14B和72B。其中,最強版本的效能超越了GPT3.5和Mistral-Medium。此版本包含Base模型和Chat模型,並提供多語言支援。阿里通義千問團隊表示,相關技術也已經上線到了通義千問官網和通義千問App。除此之外,今天Qwen1.5的發布還有以下一些重點:支援32K上下文長度;開放了Base+Chat模型的checkpoint;
 大模型也能切片,微軟SliceGPT讓LLAMA-2運算效率大增
Jan 31, 2024 am 11:39 AM
大模型也能切片,微軟SliceGPT讓LLAMA-2運算效率大增
Jan 31, 2024 am 11:39 AM
大型語言模型(LLM)通常擁有數十億參數,經過數萬億token的資料訓練。然而,這樣的模型訓練和部署成本都非常昂貴。為了降低運算需求,人們常常採用各種模型壓縮技術。這些模型壓縮技術一般可分為四類:蒸餾、張量分解(包括低秩因式分解)、剪枝、量化。剪枝方法已經存在一段時間,但許多方法需要在剪枝後進行恢復微調(RFT)以保持性能,這使得整個過程成本高昂且難以擴展。蘇黎世聯邦理工學院和微軟的研究者提出了一個解決這個問題的方法,名為SliceGPT。此方法的核心思想是透過刪除權重矩陣中的行和列來降低網路的嵌
 更新版 Point Transformer:更有效率、更快速、更強大!
Jan 17, 2024 am 08:27 AM
更新版 Point Transformer:更有效率、更快速、更強大!
Jan 17, 2024 am 08:27 AM
原標題:PointTransformerV3:Simpler,Faster,Stronger論文連結:https://arxiv.org/pdf/2312.10035.pdf程式碼連結:https://github.com/Pointcept/PointTransformerV3作者單位:HKUSHAILabMPIPKUMIT論文想法:本文無意在注意力機制內尋求創新。相反,它側重於利用規模(scale)的力量,克服點雲處理背景下準確性和效率之間現有的權衡。從3D大規模表示學習的最新進展中汲取靈感,
 你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
波士頓動力Atlas,正式進入電動機器人時代!昨天,液壓Atlas剛「含淚」退出歷史舞台,今天波士頓動力就宣布:電動Atlas上崗。看來,在商用人形機器人領域,波士頓動力是下定決心要跟特斯拉硬剛一把了。新影片放出後,短短十幾小時內,就已經有一百多萬觀看。舊人離去,新角色登場,這是歷史的必然。毫無疑問,今年是人形機器人的爆發年。網友銳評:機器人的進步,讓今年看起來像人類的開幕式動作、自由度遠超人類,但這真不是恐怖片?影片一開始,Atlas平靜地躺在地上,看起來應該是仰面朝天。接下來,讓人驚掉下巴
 追趕Gemini Pro,提升推理、OCR能力的LLaVA-1.6太強了
Feb 01, 2024 pm 04:51 PM
追趕Gemini Pro,提升推理、OCR能力的LLaVA-1.6太強了
Feb 01, 2024 pm 04:51 PM
在去年4月,威斯康辛大學麥迪遜分校、微軟研究院和哥倫比亞大學的研究者們共同發布了LLaVA(LargeLanguageandVisionAssistant)。儘管LLaVA只是用一個小的多模態指令資料集進行訓練,但在一些樣本上展現了與GPT-4非常相似的推理結果。然後在10月,他們推出了LLaVA-1.5,透過對原始LLaVA進行簡單修改,在11個基準測試中刷新了SOTA。這次升級的結果非常令人振奮,為多模態AI助理領域帶來了新的突破。研究團隊宣布推出LLaVA-1.6版本,針對推理、OCR和
 超級智能體生命力覺醒!可自我更新的AI來了,媽媽再也不用擔心資料瓶頸難題
Apr 29, 2024 pm 06:55 PM
超級智能體生命力覺醒!可自我更新的AI來了,媽媽再也不用擔心資料瓶頸難題
Apr 29, 2024 pm 06:55 PM
哭死啊,全球狂煉大模型,一網路的資料不夠用,根本不夠用。訓練模型搞得跟《飢餓遊戲》似的,全球AI研究者,都在苦惱怎麼才能餵飽這群資料大胃王。尤其在多模態任務中,這問題尤其突出。一籌莫展之際,來自人大系的初創團隊,用自家的新模型,率先在國內把「模型生成數據自己餵自己」變成了現實。而且還是理解側和生成側雙管齊下,兩側都能產生高品質、多模態的新數據,對模型本身進行數據反哺。模型是啥?中關村論壇上剛露面的多模態大模型Awaker1.0。團隊是誰?智子引擎。由人大高瓴人工智慧學院博士生高一鑷創立,高
