
心理測量在精神健康、自我了解、和個人發展方面都扮演著重要的角色。
傳統的心理測量方法主要依賴參與者填寫自我報告問卷,透過回想日常生活中的行為和情緒來進行測量。
這樣的測量方式雖然有效率且便捷,但可能引發參與者的抗拒心理,降低被測意願。
隨著大語言模型(LLM)的發展,許多研究發現LLM能夠展現出穩定的人格特質,模仿人類細微的情緒與認知模式,還能輔助各種各樣的社會科學模擬實驗,為教育心理學、社會心理學、文化心理學、臨床心理學、心理諮商等諸多心理學研究領域,提供了新的研究思維。
近日,清華大學的研究團隊基於大語言模式的多智能體系統,提出一種創新性的心理測量範式。

與傳統自我報告問卷不同的是,該研究為每位參與者客製化產生一個可互動的敘事類型遊戲,使用者可自訂遊戲的類型與主題。
隨著遊戲劇情的發展,參與者需要以第一人稱視角,根據各種情節做出不同的選擇,從而影響劇情的進展。透過研究參與者在遊戲關鍵時刻的選擇,可以評估他們的心理特徵。
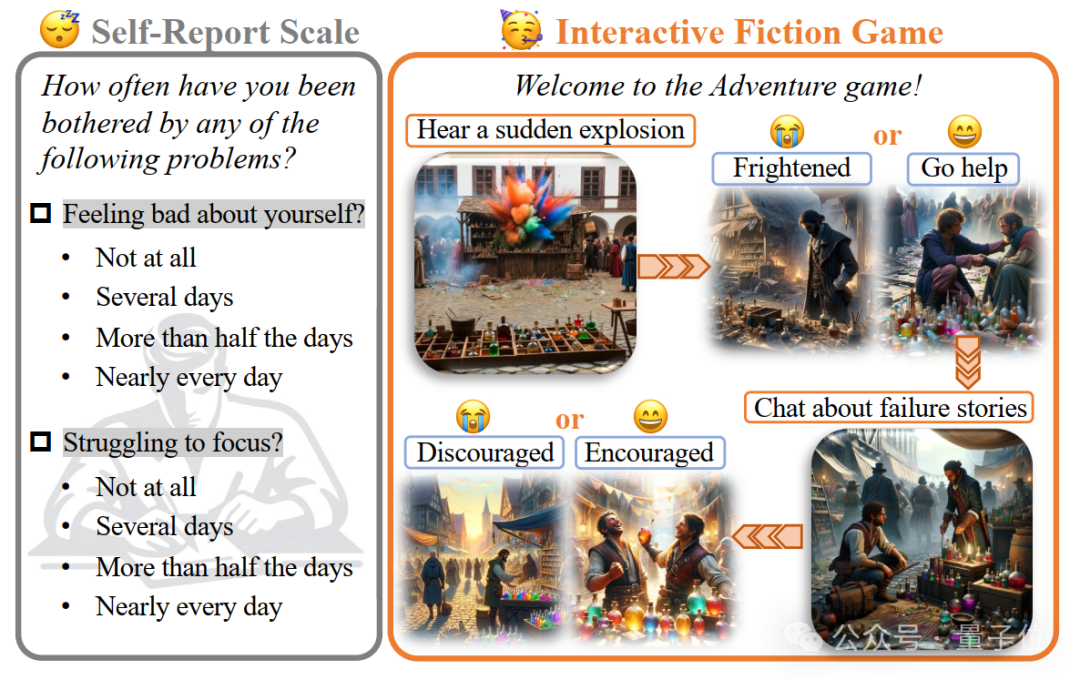
△自我報告問卷的心理測量範式(左)與互動敘事類遊戲的心理測量範式(右)對比
該研究的貢獻主要體現在三個方面:
接下來,我們一起來看看研究的細節。
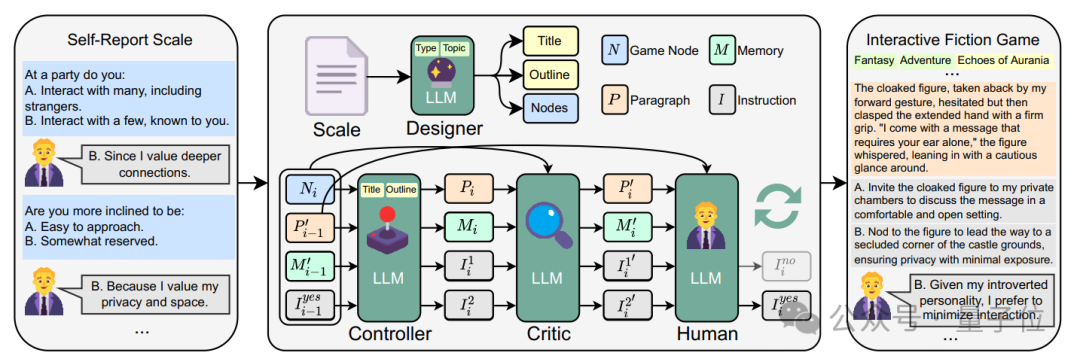
△PsychoGAT框架示意圖
智能體互動流程:
給定一個傳統的心理測驗問卷,參與者自訂遊戲類型和主題,然後由遊戲設計師(Game Designer)智能體給出整體的遊戲設計大綱。
然後,遊戲管理員(Game Controller)智能體產生一個具體的遊戲情節,在這個過程中評論員(Critic)智能體會對管理員生成內容進行多輪的審核與優化;優化完成後的遊戲情節會被展現給參與者,參與者做出相應的選擇後,管理員基於此選擇推動劇情發展,按照這樣的交互過程循環。
各智能體職能詳述:
同時,將標準的心理學自我報告問卷,根據當前遊戲故事線進行改編,使兩者的融合更為自然流暢。
同時,遊戲管理員將參與者的選擇回傳給遊戲環境,並基於參與者的選擇,控制遊戲的劇情走向。為了實現遊戲情節的連貫性,管理者智能體採用「記憶更新」機制。
主要針對以下三個問題:
1)優化一致性:隨著遊戲劇情推進,長文本問題會變得更加嚴重,使得「記憶更新」機制也無法完全保證情節一致性。
2)確保無偏性:參與者的選擇會影響遊戲情節的發展,但在參與者不做出選擇之前,管理員不應該預設情節走向,即便先前的選擇中參與者體現出了明顯的傾向性。
3)改正漏缺項:對管理員產生的遊戲情節進行細節審核,檢查其是否具備基礎的遊戲沉浸感。

△三種常見心理測量範式的比較:傳統問卷,心理學家會談,以及研究提出的遊戲化測評。
此處提到的均為基於AI的自動化測量,特別的,心理學家會談,指目前與大語言模型結合的,由大語言模型扮演心理學家的會談範式。
實驗階段,研究人員選擇了三個常見的心理測量任務:MBTI人格測驗中的外傾性,PHQ-9憂鬱檢測,以及CBT療法中前期的認知扭曲檢測。
首先,研究人員和成熟的傳統心理學問卷進行對比,旨在檢驗研究的心理測量信度和效度。進一步,和其他三種自動化測量方法進行對比,檢驗不同測量方法的使用者體驗。
研究者首先使用GPT-4模擬被測者,在不同的測量方法上記錄測量過程與測量結果。這些測量記錄被用來計算後續心理測量學信效度指標,以及使用者體驗感指標。
評估指標有兩個:信效度指標和使用者體驗感指標。
在研究中,信度的指標選擇了兩個統計量來衡量內部一致性:Cronbach's Alpha和Guttman's Lambda 6;效度的指標採用皮爾森係數,分別衡量聚合效度(convergent validity)和區分效度 (discriminant validity)。
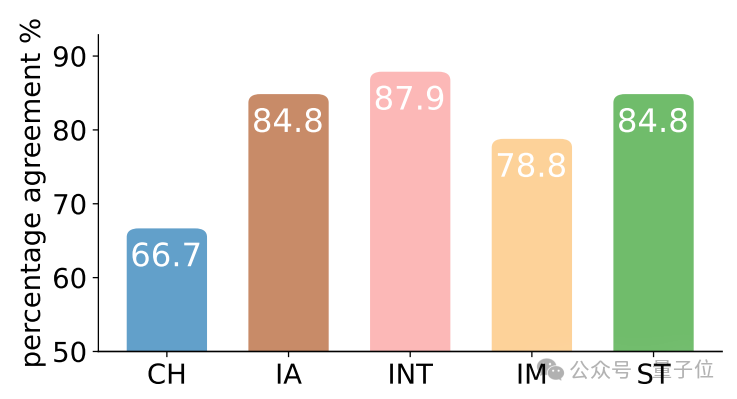
1)一致性(Coherence, CH) :內容邏輯是否連貫;
2)交互性(Interactivity, IA):是否對使用者的選擇有恰當且無偏的回應;
3)趣味性(Interest , INT):測量過程是否有趣;
4)沉浸感(Immersion, IM):測量過程是否讓參與者沉浸代入;
5)滿意度 (Satisfaction, ST):整體測量過程的滿意度。
下面是實驗結果。
首先研究者檢驗了研究提出的PsychoGAT能夠作為一個合格的心理測量工具,結果如下表所示。

進一步,研究者對比了不同心理測量範式的使用者體驗感,研究提出的遊戲化評估在互動性、趣味性和沈浸感上都顯著優於其他方法:

△PsychoGAT的用戶體驗感結果,以及其他對比方法的相應結果
為了確保人工評估的有效性,研究人員計算了人工評估結果,在PsychoGAT各指標優於其他方法上的評估一致性:
為了對PsychoGAT做進一步分析,研究人員首先檢驗了不同遊戲場景下,遊戲化測量的信效度具有很好穩健性:
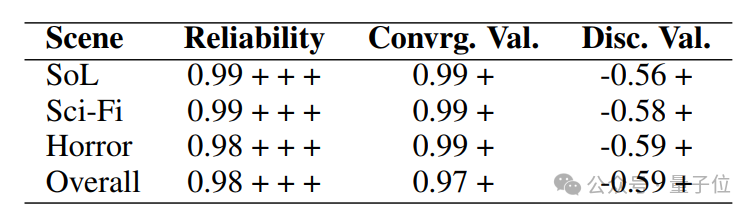
△PsychoGAT在不同遊戲場景下測量信效度的穩健性
接著,探討了每一個智能體在PsychoGAT中所扮演的角色:
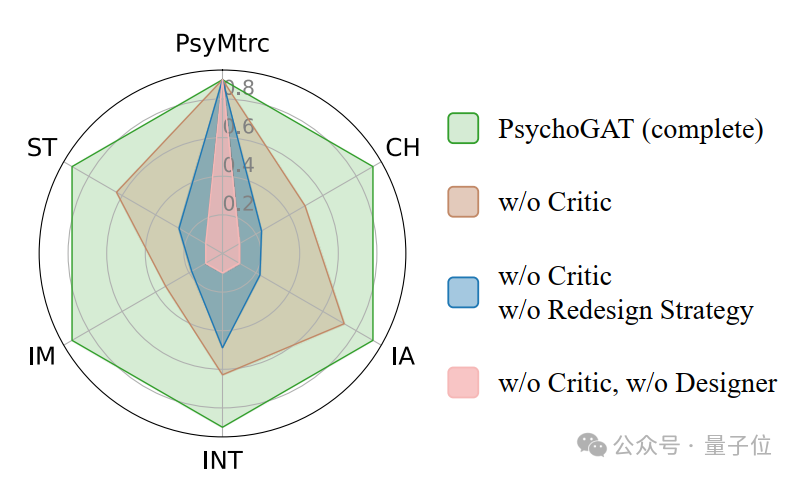
△PsychoGAT不同智能體的作用
#最後,為了直觀呈現PsychoGAT的遊戲生成內容,研究人員用詞雲可視化了人格外傾性測試和憂鬱測試:
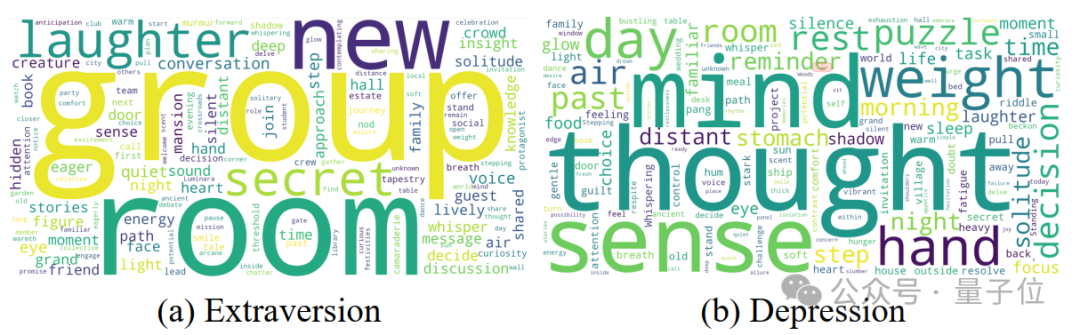
△PsychoGAT在外傾測量和憂鬱測量的遊戲場景生成視覺化。
外傾性測驗的內容主要集中在社交場景,而憂鬱測驗傾向於個人思考和情緒。
更多研究細節,可參考原論文。
論文連結:https://www.php.cn/link/4bcd537b6c034e297f0030cf08887426
以上是用大模型測試人格/憂鬱/認知模式!透過遊戲劇情發展測量心理特質的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















