

顏水成/程明明新作! Sora核心元件DiT訓練加速10倍,Masked Diffusion Transformer V2開源

作為Sora引人注目的核心技術之一,DiT利用Diffusion Transformer將生成模型擴展到更大的規模,從而實現出色的影像生成效果。
然而,更大的模型規模導致訓練成本飆升。
Sea AI Lab、南開大學、崑崙萬維2050研究院的顏水成和程明明研究團隊在ICCV 2023會議上提出了一個名為Masked Diffusion Transformer的新模型。該模型利用mask建模技術,透過學習語意表徵資訊來加快Diffusion Transfomer的訓練速度,並在影像生成領域中取得了SoTA的效果。這項創新為圖像生成模型的發展帶來了新的突破,為研究者提供了一個更有效率的訓練方法。透過結合不同領域的專業知識和技術,研究團隊成功地提出了一種能夠提高訓練速度並改善產生效果的解決方案。他們的工作為人工智慧領域的發展貢獻了重要的創新思路,為未來的研究和實踐提供了有益的啟
 圖片
圖片
##論文網址:https://arxiv.org/abs/2303.14389
GitHub網址:https://github.com/sail-sg/MDT
#例如上圖所示,DiT在第50k次訓練步驟時已經學會生成狗的毛髮紋理,然後在第200k次訓練步驟時才學會生成狗的一隻眼睛和嘴巴,但是卻漏生成了另一隻眼睛。
即使在第300k次訓練步驟時,DiT產生的狗的兩隻耳朵的相對位置也不是非常準確。
這個訓練學習過程揭示了擴散模型未能有效率地學習到影像中物體各部分之間的語意關係,而只是獨立地學習每個物體的語意資訊。 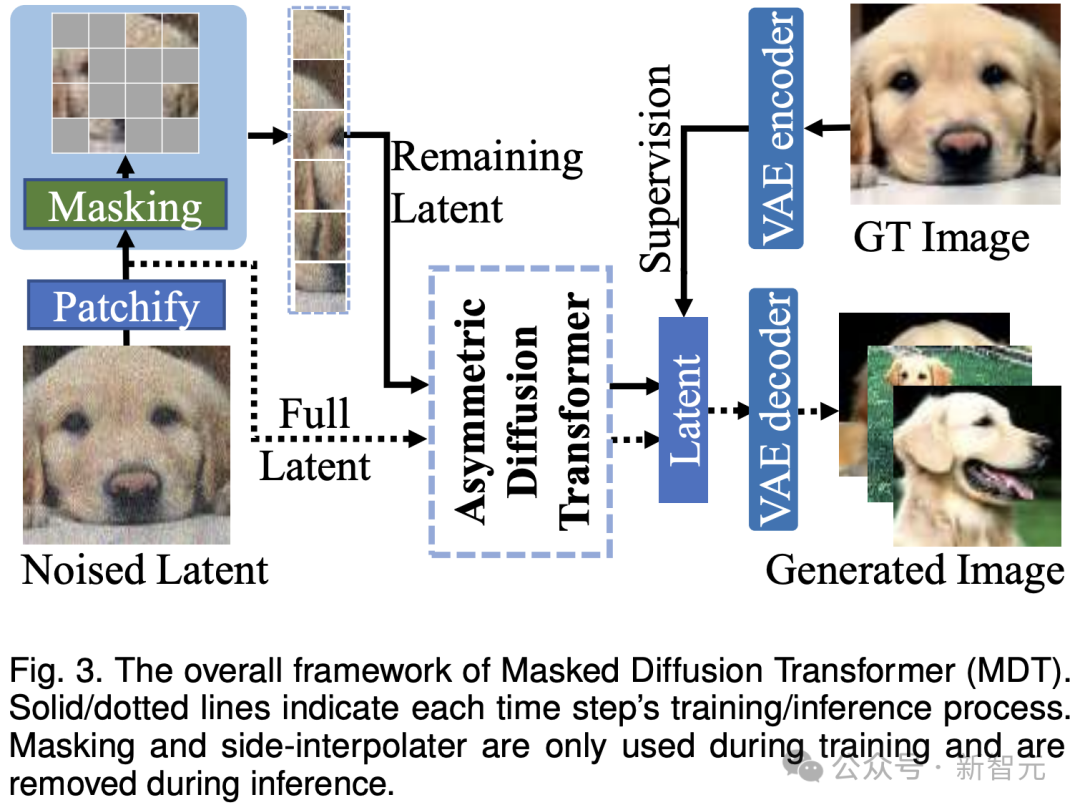
在推理過程中,MDT仍維持標準的擴散生成過程。 MDT的設計有助於Diffusion Transformer同時具有mask modeling表徵學習帶來的語意資訊表達能力和擴散模型對影像細節的生成能力。
具體而言,MDT透過VAE encoder將圖片對應到latent空間,並在latent空間中處理以節省計算成本。
在訓練過程中,MDT先mask掉部分加雜訊後的影像token,並將剩餘的token送入Asymmetric Diffusion Transformer來預測去雜訊後的全部影像token。
Asymmetric Diffusion Transformer架構
 圖片
圖片
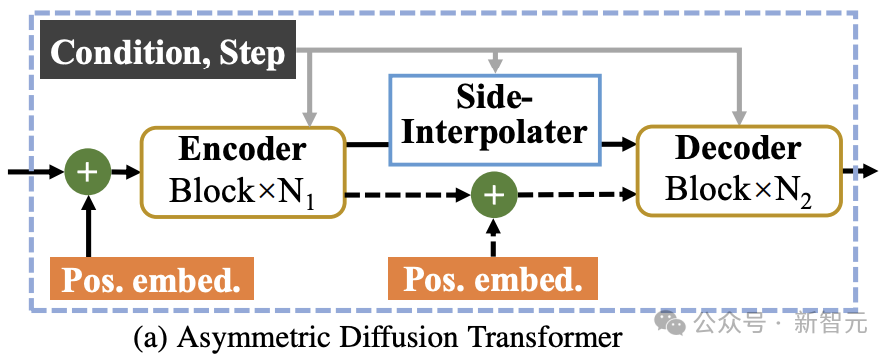
如上圖所示,Asymmetric Diffusion Transformer架構包含encoder、side-interpolater(輔助插值器)和decoder。
 圖片
圖片
在訓練過程中,Encoder只處理未被mask的token;而在在推理過程中,由於沒有mask步驟,它會處理所有token。
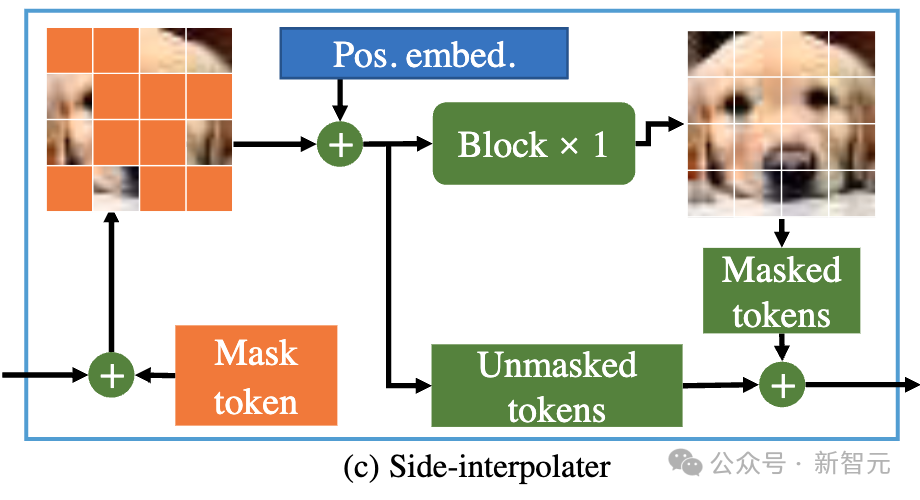
因此,為了確保在訓練或推理階段,decoder總是能處理所有的token,研究者提出了一個方案:在訓練過程中,透過一個由DiT block組成的輔助插值器(如上圖所示),從encoder的輸出中插值預測出被mask的token,並在推理階段將其移除因而不增加任何推理開銷。
MDT的encoder和decoder在標準的DiT block中插入全域和局部位置編碼資訊以幫助預測mask部分的token。
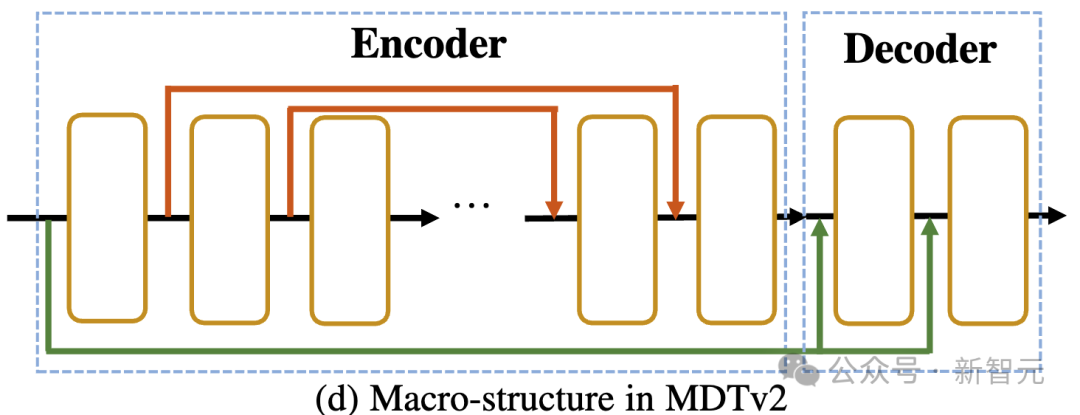
Asymmetric Diffusion Transformer V2
 圖片
圖片
 實驗結果
實驗結果
ImageNet 256基準產生品質比較
圖片
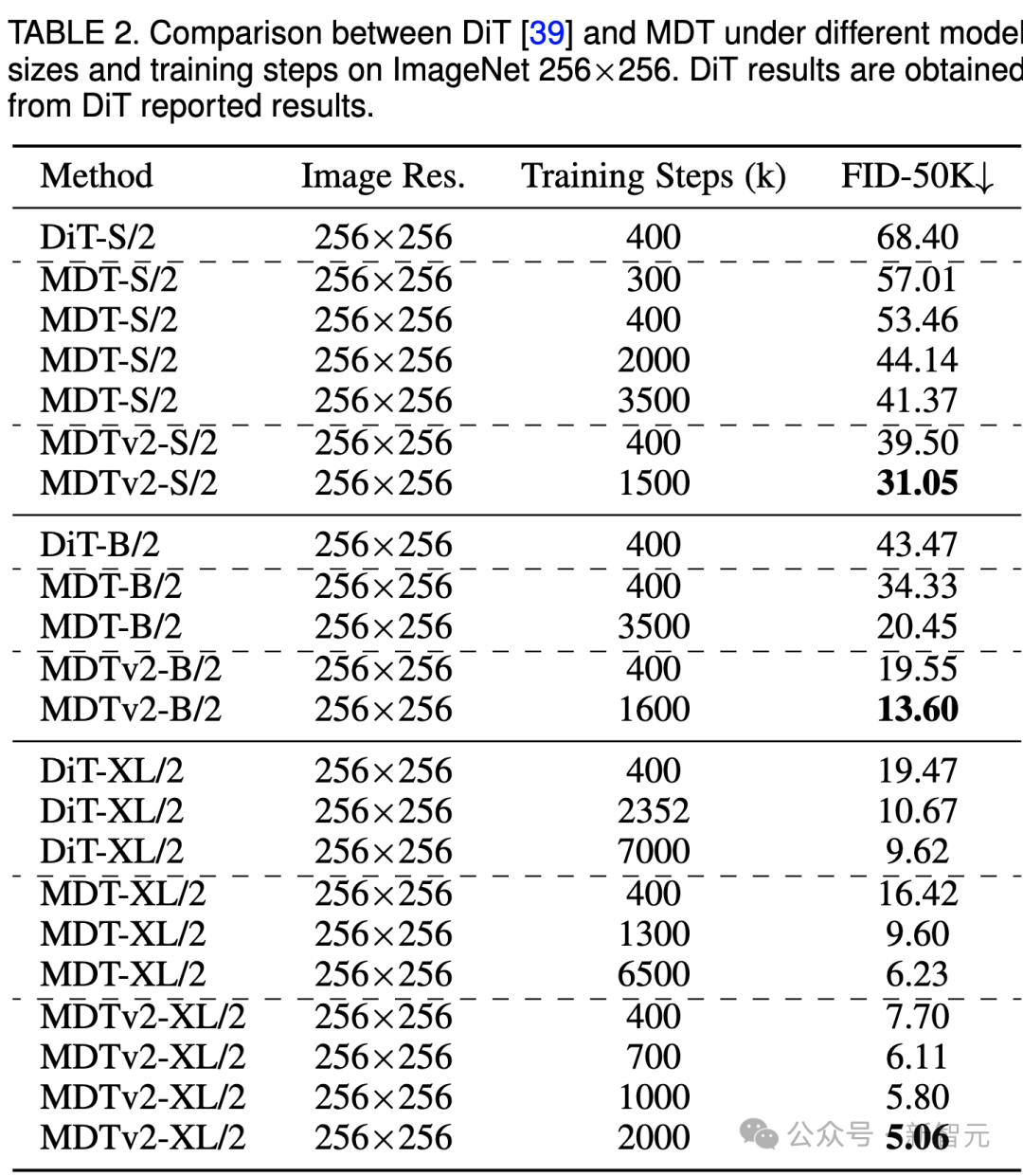
上表比較了不同模型尺寸下MDT與DiT在ImageNet 256基準下的效能比較。 顯而易見,MDT在所有模型規模上都以較少的訓練成本實現了更高的FID分數。 MDT的參數和推理成本與DiT基本一致,因為如前文所介紹的,MDT推理過程中仍保持與DiT一致的標準的diffusion過程。 ############對於最大的XL模型,經過400k步驟訓練的MDTv2-XL/2,顯著超過了經過7000k步驟訓練的DiT-XL/2,FID分數提高了1.92。在這一setting下,結果顯示了MDT相對DiT有約18倍的訓練加速。 ##########对于小型模型,MDTv2-S/2 仍然以显著更少的训练步骤实现了相比DiT-S/2显著更好的性能。例如同样训练400k步骤,MDTv2以39.50的FID指标大幅领先DiT 68.40的FID指标。
更重要的是,这一结果也超过更大模型DiT-B/2在400k训练步骤下的性能(39.50 vs 43.47)。
ImageNet 256基准CFG生成质量比较
 图片
图片
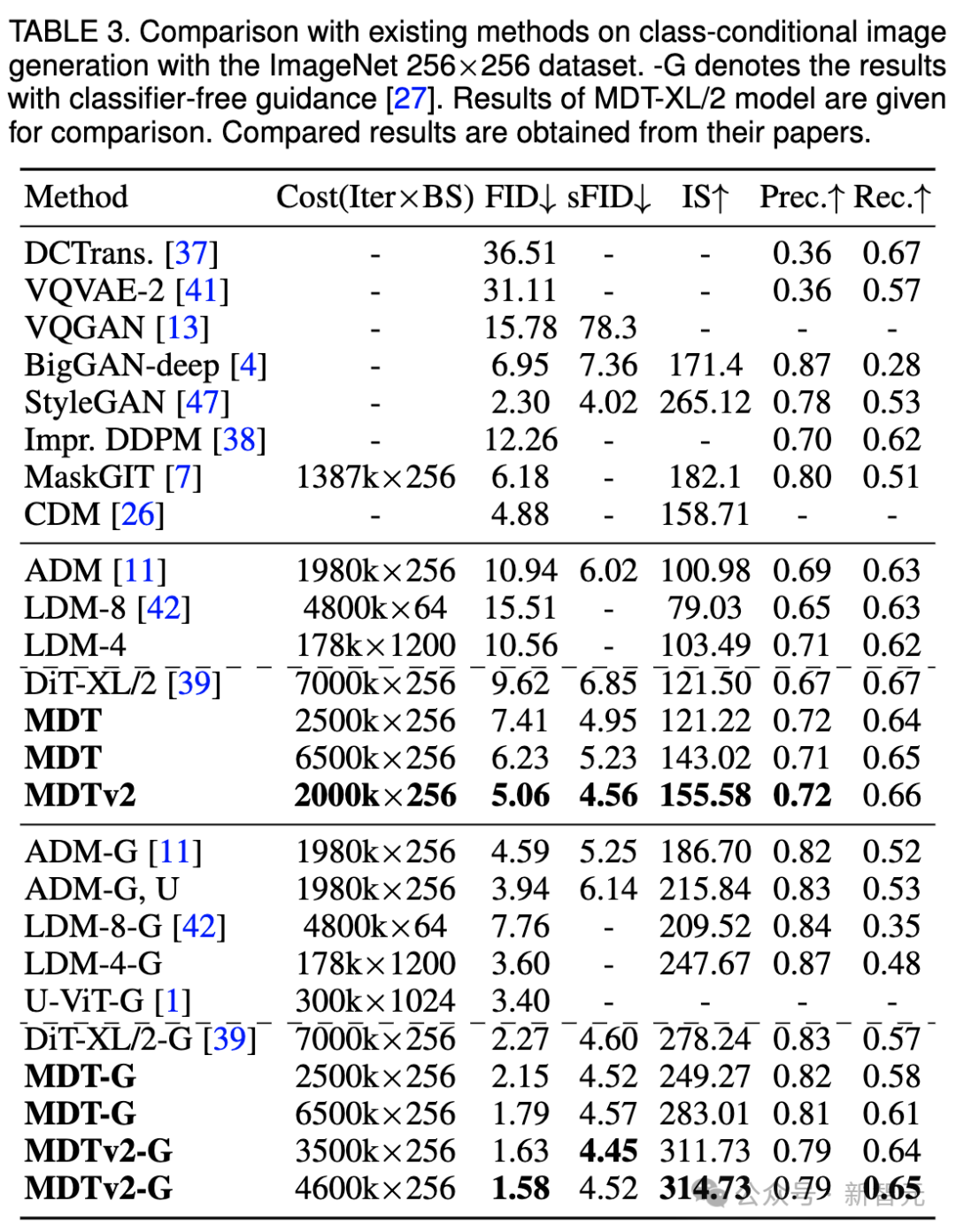
我们还在上表中比较了MDT与现有方法在classifier-free guidance下的图像生成性能。
MDT以1.79的FID分数超越了以前的SOTA DiT和其他方法。MDTv2进一步提升了性能,以更少的训练步骤将图像生成的SOTA FID得分推至新低,达到1.58。
与DiT类似,我们在训练过程中没有观察到模型的FID分数在继续训练时出现饱和现象。
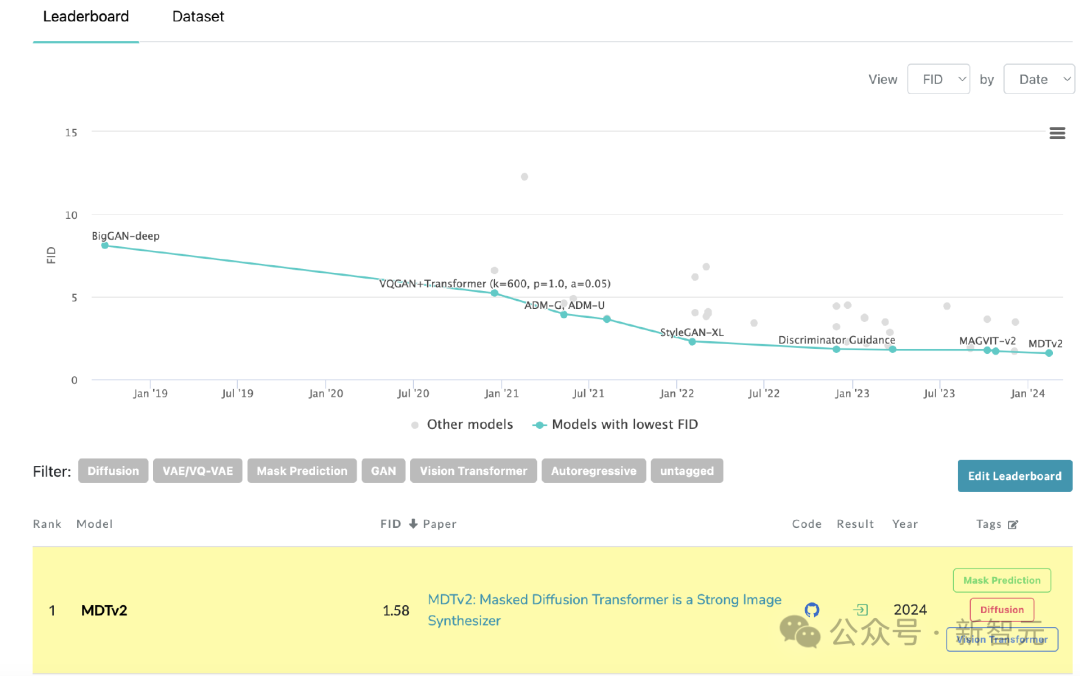 MDT在PaperWithCode的leaderboard上刷新SoTA
MDT在PaperWithCode的leaderboard上刷新SoTA
收敛速度比较
 图片
图片
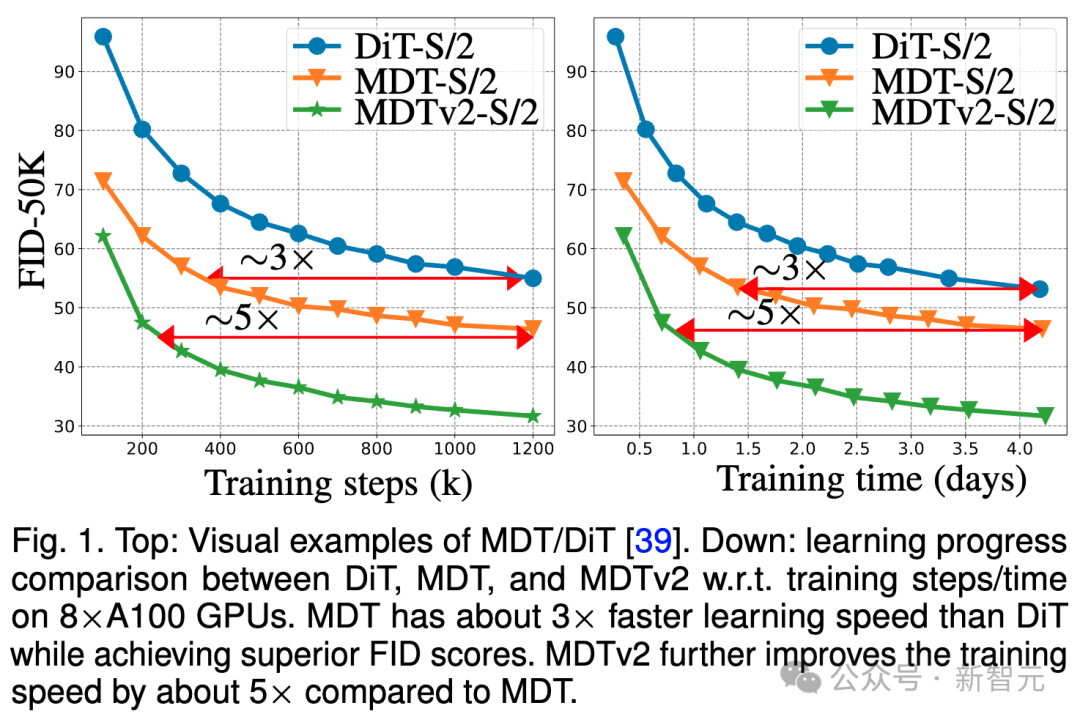
上图比较了ImageNet 256基准下,8×A100 GPU上DiT-S/2基线、MDT-S/2和MDTv2-S/2在不同训练步骤/训练时间下的FID性能。
得益于更优秀的上下文学习能力,MDT在性能和生成速度上均超越了DiT。MDTv2的训练收敛速度相比DiT提升10倍以上。
MDT在训练步骤和训练时间方面大相比DiT约3倍的速度提升。MDTv2进一步将训练速度相比于MDT提高了大约5倍。
例如,MDTv2-S/2仅需13小时(15k步骤)就展示出比需要大约100小时(1500k步骤)训练的DiT-S/2更好的性能,这揭示了上下文表征学习对于扩散模型更快的生成学习至关重要。
总结&讨论
MDT通过在扩散训练过程中引入类似于MAE的mask modeling表征学习方案,能够利用图像物体的上下文信息重建不完整输入图像的完整信息,从而学习图像中语义部分之间的关联关系,进而提升图像生成的质量和学习速度。
研究者认为,通过视觉表征学习增强对物理世界的语义理解,能够提升生成模型对物理世界的模拟效果。这正与Sora期待的通过生成模型构建物理世界模拟器的理念不谋而合。希望该工作能够激发更多关于统一表征学习和生成学习的工作。
参考资料:
https://arxiv.org/abs/2303.14389
以上是顏水成/程明明新作! Sora核心元件DiT訓練加速10倍,Masked Diffusion Transformer V2開源的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 joiplay模擬器使用方法介紹
May 04, 2024 pm 06:40 PM
joiplay模擬器使用方法介紹
May 04, 2024 pm 06:40 PM
jojplay模擬器是一款非常好用的手機模擬器,它支援電腦遊戲可以在手機上運行,而且相容性非常好,有些玩家不知道怎麼使用,下面小編就為大家帶來了使用方法介紹。 joiplay模擬器怎麼使用1、首先需要下載Joiplay本體及RPGM插件,最好按本體-插件的順序進行安裝,apk包可在Joiplay吧取得(點擊取得>>>)。 2.安卓完成後,就可以在左下角加入遊戲了。 3.name隨便填,executablefile按CHOOSE選擇遊戲的game.exe檔。 4.Icon可以留空也可以選擇自己喜歡的圖片
 微星(MSI)主機板vt開啟方法
May 01, 2024 am 09:28 AM
微星(MSI)主機板vt開啟方法
May 01, 2024 am 09:28 AM
微星主機板怎麼開啟VT?有哪些方法?本站為廣大用戶精心整理了微星(MSI)主機板vt開啟方法供大家參看,歡迎閱讀分享!第一步、重新啟動電腦,進入BIOS,開啟速度太快無法進入BIOS怎麼辦?螢幕亮起後不斷按下「Del」進入BIOS頁面,第二步、在選單中找到VT選項並開啟,不同型號的電腦,BIOS介面不相同,VT的叫法也不相同情況一:1、進入BIOS頁面後,找到「OC(或叫overclocking)」-「CPU特徵」-「SVMMode(或叫Intel虛擬化技術)」選項,把「Disabled(禁止)
 華擎(ASRock)主機板vt開啟方法
May 01, 2024 am 08:49 AM
華擎(ASRock)主機板vt開啟方法
May 01, 2024 am 08:49 AM
華擎主機板怎麼開啟VT,有哪些方法,怎麼操作。本站為大家整理了華擎(ASRock)主機板vt開啟方法供使用者閱讀分享!第一步,重新啟動電腦,螢幕亮起後不斷按下「F2」鍵,進入BIOS頁面,開啟速度過快無法進入BIOS怎麼辦?第二步,在選單中找到VT選項並開啟,不同型號的主機板,BIOS介面不相同,VT的叫法也不相同1、進入BIOS頁面後,找到「Advanced(高級)」-「CPUConfiguration(CPU配置)”——“SVMMOD(虛擬化技術)”選項,把“Disabled”都修改為“Enabled
 比較流暢的安卓模擬器推薦(選用的安卓模擬器)
Apr 21, 2024 pm 06:01 PM
比較流暢的安卓模擬器推薦(選用的安卓模擬器)
Apr 21, 2024 pm 06:01 PM
它能夠提供使用者更好的遊戲體驗和使用體驗,安卓模擬器是一種可以在電腦上模擬安卓系統運作的軟體。市面上的安卓模擬器種類繁多,品質參差不齊,然而。幫助讀者選擇最適合自己的模擬器、本文將重點放在一些流暢且好用的安卓模擬器。一、BlueStacks:運行速度快速具有出色的運行速度和流暢的用戶體驗、BlueStacks是一款備受歡迎的安卓模擬器。使用戶能夠暢玩各類行動遊戲和應用,它能夠在電腦上以極高的性能模擬安卓系統。二、NoxPlayer:支援多開,玩遊戲更爽可以同時在多個模擬器中運行不同的遊戲、它支援
 平板電腦怎麼裝windows系統
May 03, 2024 pm 01:04 PM
平板電腦怎麼裝windows系統
May 03, 2024 pm 01:04 PM
步步高平板怎麼刷windows系統第一種是硬碟安裝系統。只要電腦系統沒有崩潰,能進入系統,並且能下載東西就可以使用電腦硬碟安裝系統。方法如下:依照你的電腦配置,完全可以裝WIN7的作業系統。我們選擇在vivopad中選擇下載小白一鍵重裝系統來安裝,先選擇好適合你電腦的系統版本,點選「安裝此系統」下一步。然後我們耐心等待安裝資源的下載,等待環境部署完畢重啟即可。 vivopad裝win11步驟是:先透過軟體偵測一下是否可以安裝win11。通過了系統檢測,進入系統設定。選擇其中的更新和安全選項。點選
 人生重開模擬器攻略大全
May 07, 2024 pm 05:28 PM
人生重開模擬器攻略大全
May 07, 2024 pm 05:28 PM
人生重開模擬器是一款非常有趣的模擬小遊戲,這款遊戲最近非常的火,遊戲中有很多的玩法,下面小編就大家帶來了人生重開模擬器攻略大全,快來看看都有哪些攻略吧。人生重開模擬器攻略大全人生重開模擬器特色這是一款非常有創意的遊戲,遊戲裡玩家可以依照自己的想法進行遊戲。每天都會有許多的任務可以完成,在這個虛擬的世界裡享受全新的人生。遊戲裡擁有許多的歌曲,各種不同的人生等著你來感受。人生重開模擬器遊戲內容天賦抽卡:天賦:必選神秘的小盒子,才能修仙子。各種各樣的小膠囊可選,避免中途死掉。克蘇魯選了可能會
 pycharm怎麼打包成apk
Apr 18, 2024 am 05:57 AM
pycharm怎麼打包成apk
Apr 18, 2024 am 05:57 AM
如何使用 PyCharm 打包 Android 應用程式為 APK?確保項目已連接至 Android 裝置或模擬器。配置建置類型:新增一個建置類型,勾選「產生簽章 APK」。在建置工具列中點擊“建置 APK”,選擇建置類型並開始產生。
 joiplay模擬器字體設定方法介紹
May 09, 2024 am 08:31 AM
joiplay模擬器字體設定方法介紹
May 09, 2024 am 08:31 AM
jojplay模擬器其實可以自訂遊戲字體的,而且可以解決文字出現缺字、方框字的問題,想必不少玩家還不知道怎麼操作,下面小編就為大家帶來了joiplay模擬器字體設定方法介紹。 joiplay模擬器字體怎麼設定1、先開啟joiplay模擬器,點選右上角的設定(三個點),找到。 2.在RPGMSettings一欄,第三行CustomFont自訂字體,點選選擇。 3.選擇字體文件,點擊ok就行了,注意不要按右下角「儲存」圖標,不然會原預設設定。 4.推薦方正準圓簡體(已在復興、重生遊戲資料夾內)。 joi
