

首次攻克「圖基礎模型」三大難題!港大開源OpenGraph:零樣本學習適合多種下游任

图学习(Graph Learning)技术已经被广泛应用于各个领域,包括推荐系统、社交网络分析、引用网络和交通网络等。这种技术能够有效地挖掘和学习复杂的关系数据,为数据科学家和工程师提供了强大的工具。通过图学习算法,可以更好地理解数据之间的关联和联系,从而帮助我们发现隐藏在数据背后的规律和模式。在实际应用中,图学习技术可以帮助我们构建更准确和
图神经网络(Graph Neural Networks, GNNs)利用迭代的消息传递机制来捕获图结构数据中的复杂高阶关系,在各种图学习应用中取得了显著的成就。
通常,这种端到端的图神经网络需要大量、高质量的标注数据才能获得较好的训练效果。
近年来,一些工作提出图模型的预训练-微调(Pre-training and Fine-tuning)模式,使用各种自监督学习任务在无标注的图数据上首先进行预训练,再在少量标注数据上进行微调,以对抗监督信号不足的问题。这里的自监督学习任务包括对比学习、掩码重建、局部全局互信息最大化等方法。
尽管这种预训练方法在一定程度上取得了成功,但它们在泛化能力方面存在一定局限性,尤其是在预训练和下游任务之间出现分布偏移时。
在推荐系统中,预训练模型基于早期数据进行训练,但用户偏好和商品热度往往会发生变化,这就需要模型不断更新以适应新的信息。
为了应对这一挑战,近期的研究提出了针对图模型的提示微调方法,使预训练模型能够更有效地适应于不同的下游任务和数据。
虽然上述研究推动了图神经网络模型的泛化性能,但这些模型都基于一个假设:训练数据和测试数据具有相同的节点集合和特征空间。
这极大地限制了预训练图模型的应用范围。因此,本文探索进一步提升图模型泛化能力的方法。
我们期望OpenGraph能够捕捉通用的拓扑结构模式,实现对测试数据的零样本预测。这意味着通过前向传播过程,能够高效地提取特征并准确预测测试图数据。
模型的训练过程在完全不同的图数据上进行,在训练阶段不接触测试图的任何元素,包括节点、边、特征向量。

为了达成这一目的,本文需要解决以下三个挑战:
C1. 跨数据集的Token集合变化
零样本图预测任务的一个显著困难是,不同的图数据通常有完全不同的图token集合。具体来说,不同图的节点集合通常没有交集,并且不同图数据集也经常使用完全不同的节点特征。这使得模型不能通过学习和特定数据集的图token绑定的参数,来进行跨数据集的预测任务。
C2. 高效的节点间关系建模
在图学习领域,节点之间常常存在错综复杂的依赖关系,模型需要对节点的局部和全局邻域关系进行综合考量。在搭建通用图模型时,一个重要的任务是能够高效地建模节点间关系,这能够增强模型在处理大量图数据时的模型效果和可扩展性。
C3. 训练数据稀缺
由于隐私保护、数据采集成本等原因,在图学习的很多下游领域中都广泛存在数据稀缺问题,这使得通用图模型的训练容易缺乏对某些下游领域的了解而产生次优的训练效果。
为了应对上述挑战,香港大学的研究人员提出了 OpenGraph,这是一个擅长零样本学习的模型,能够识别不同下游领域之间可迁移的拓扑结构模式。

论文链接:https://arxiv.org/pdf/2403.01121.pdf
源码链接:https://github.com/HKUDS/OpenGraph
通过创建一个具有拓扑感知投影方案的图tokenizer来解决挑战 C1,从而生成统一的图tokens。
为了应对挑战 C2,设计了一个可扩展的图Transformer,它配备了基于锚点采样的高效自注意力机制,并包括了token序列采样以实现更高效的训练。
为了解决挑战 C3,我们利用大型语言模型进行数据增强,以丰富我们的预训练,使用提示树算法和吉布斯采样来模拟现实世界的图结构关系数据。我们在多个图数据集上进行的广泛测试显示了 OpenGraph 在各种设置中的卓越泛化能力。
模型介绍
模型整体架构如下图所示,可以分为三个部分,分别为1)统一图Tokenizer,2)可扩展的图Transformer,3)大语言模型知识蒸馏。

統一圖Tokenizer
#為了回應不同資料集在節點、邊、特徵上存在的巨大差異,我們的首要任務是建立一個統一的圖tokenizer,能夠有效地將不同圖形資料影射為統一的token序列。在我們的tokenizer中,每個token都有一個語義向量,用來描述對應節點的資訊。
透過採用統一的節點來表徵空間,以及靈活的序列資料結構,我們希望為不同的圖資料進行標準化、高效的tokenization。
為了達成這個目的,我們的tokenizer採用了經過平滑的拓撲訊息,以及一個從節點空間到隱表徵空間的映射函數。
高階平滑鄰接矩陣
#在圖tokenization過程中,使用鄰接矩陣的高次方作為輸入之一,這種方式既能夠獲取圖結構的高階連接關係,也能夠解決原始鄰接矩陣中連接稀疏性的問題。
計算過程中進行了Laplacian歸一化,並將不同階的鄰接矩陣冪全部考慮進來,具體計算方法如下。
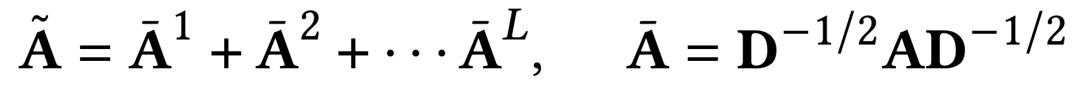
對任意圖的拓撲感知映射
不同資料集的鄰接矩陣在維度上有巨大的差異,這使得我們無法直接將鄰接矩陣作為輸入,再使用一個固定輸入維度的神經網路進行處理。
我們的解決方案是先將鄰接矩陣投射為節點表徵序列的形式,後續即可使用可變長的序列模型進行處理。而為了減少映射過程的資訊損失,我們提出了一種拓樸感知的映射方法。
首先,我們拓樸知覺映射的值域是一個維度較高的隱表徵空間。先前的一些工作指出,在採用較大的隱空間維度時,即使是隨機的映射也常常可以產生令人滿意的表徵效果。
為了進一步保留圖結構訊息,並減少隨機性影響,我們使用快速特徵值分解(SVD)來建構我們的映射函數。在實際實驗中,兩輪的快速特徵值分解可以有效地保留拓撲訊息,且產生的的計算開銷相對其他模組可以忽略不計。
可擴充的圖Transformer
#經過無參數的圖tokenization過程,對不同特徵的圖數據,OpenGraph分配了統一的拓樸感知圖token表徵。接下來的任務是採用可訓練的神經網絡,對節點間的複雜依賴關係進行建模。
OpenGraph採用了transformer架構,以利用其在複雜關係建模方面的強大能力。為了確保模型效率和效能,我們引入了以下兩種採樣技巧。
Token序列取樣
#由於我們的圖token序列資料一般有較大的token數量和隱表徵維度,OpenGraph採用的圖transformer對輸入的token序列進行採樣,只學習當前訓練批次內的token間兩兩關係,使得需要建模的關係對數量從節點數量平方,降低到訓練批次大小的平方,從而大大減少圖transformer在訓練階段的時間和空間開銷。並且,這種採樣方法能夠讓模型在訓練時更加關注目前的訓練批次。
儘管對輸入資料進行了取樣,由於我們的初始圖token表徵包含了節點間的拓撲關係,採樣的token序列仍然能夠一定程度地反映全圖所有節點的資訊.
自註意力中的錨點取樣方法
#雖然token序列取樣將複雜度從節點數量平方降低到了批次大小平方,但平方層級的複雜度對批次大小有著較大的限制,使得模型訓練無法採用較大的批次,從而影響整體的訓練時間和訓練穩定性。
為了緩解這個問題,OpenGraph的transformer部分放棄了對所有token之間兩兩關係的建模,而是採樣部分錨點,將所有節點間的關係學習拆分成兩次所有節點與錨點之間的關係學習。
大語言模型知識蒸餾
#由於資料隱私等原因,取得各個領域的資料來訓練通用圖模型是很有挑戰性的。感受到大型語言模型(LLM)所展現的驚人知識和理解能力,我們利用其力量來產生各種圖結構數據,用於通用圖模型的訓練。
我們設計的資料增強機制,使LLM增強的圖資料能夠更好地近似真實世界圖的特徵,從而提高了增強資料的相關性和有用性。
基於LLM的節點產生
#在產生圖表時,我們的初始步驟是建立一個適合特定應用場景的節點集。每個節點都具有一個基於文字的特徵描述,有助於後續的邊生成過程。
然而,當處理真實世界場景時,這項任務可能特別具有挑戰性,因為節點集的規模很大。例如,在電子商務平台上,圖數據可能包含數十億種產品。因此,有效地使LLM產生大量節點成為一個重大挑戰。
為了解決上述挑戰,我們採用了一個策略,不斷將一般節點分成更細緻的子類別。
例如,當產生電商場景下的產品節點時,首先使用類似於「列出淘寶等電子商務平台上的所有產品的子類別」的查詢來提示LLM。 LLM回答了一個子類別列表,如“衣服”、“家居廚具”和“電子產品”等。
然後,我們要求LLM進一步細化每個子類別來繼續這個迭代分裂過程。這個過程一直重複,直到我們獲得了類似於真實世界實例的節點,例如一個帶有“衣服”、“女士衣物”、“毛線衫”、“帶兜毛線衫”和“白色帶兜毛線衫”標籤的產品。
提示樹演算法
#將節點分割成子類別並產生細粒度實體的過程遵循一種樹狀結構。最初的一般節點(例如“產品”、“深度學習論文”)作為根,細粒度實體作為葉節點。我們採用樹狀提示策略來遍歷和產生這些節點。

基於LLM和吉布斯取樣的邊生成
為了生成邊,我們使用吉布斯取樣演算法與上文產生的節點集。演算法從一個隨機樣本開始進行迭代,每次在目前樣本的基礎上,採樣對其中某一個資料維度進行變更後所得到的樣本。
這個演算法的關鍵在於估計在目前樣本的條件下,某個資料維度改變的條件機率。我們提出根據節點生成時得到的文字特徵,由LLM進行機率估計。
由於邊的集合空間較大,為了避免讓LLM對其進行探索而產生巨大的開銷,我們首先使用LLM對節點集合進行表徵,再基於表徵向量,使用簡單的相似度算子對節點間關係進行計算。在以上的邊生成框架內,我們也採用了以下三種重要的技巧來進行調整。
動態機率歸一化
#由於LLM表徵的相似度可能與[0, 1]範圍差距巨大,為了獲得更適合採樣的機率數值,我們使用動態機率歸一化的方法。
該方法動態維護採樣過程中最近的T'個相似度估計數值,計算他們的平均值和標準差,最後將當前的相似度估計映射到該平均值上下兩在標準差的分佈範圍中,從而得到近似[0, 1]的機率估計。
引入節點局部性
#基於LLM的邊生成方法,能夠有效地根據節點的語意相似性,確定他們的潛在連結關係。
然而,它傾向於在所有語義相關的節點之間創建過多的連接,忽略了真實世界圖中重要的局部性概念。
在現實世界中,節點更有可能連接到相關節點的子集,因為它們通常只能夠與一部分節點有限地互動。為了模擬這一重要特性,引入了一種在邊生成過程中將局部性納入考慮的方法。
每個節點都隨機分配一個局部性索引,兩個節點之間的交互機率受到局部性索引絕對差值的衰減影響,節點的局部性索引差異越大,則衰減越嚴重。
注入圖拓樸模式
#為了讓產生的圖資料更符合拓樸結構的模式,我們在第在一次圖生成過程中再次產生修正的節點表徵。
這個節點表徵使用簡單的圖卷積網路在初始生成圖上得到,他能更好地符合圖結構資料的分佈特點,避免圖和文字空間之間的分佈偏移。最終,我們在修正的節點表徵基礎上,再次進行圖採樣,得到最終的圖結構資料。
實驗驗證
在實驗中,我們只使用基於LLM的生成資料集進行OpenGraph模型訓練,而測試資料集都是各個應用場景下的真實資料集,並包含了節點分類和連結預測兩類任務。實驗的具體設定如下:
0-shot設定
為了驗證OpenGraph的零樣本預測能力,OpenGraph在產生的訓練資料集上測試,再使用完全不同的真實測試資料集進行效果測試。訓練資料集和測試資料集在節點、邊、特徵、標註上均沒有任何重合。
Few-shot設定
#由於大多數現有方法無法進行有效的零樣本預測,我們採用少樣本預測的方式對他們進行測試。基線方法可以在預訓練資料上進行預訓練,之後使用k-shot樣本進行訓練、微調或提示微調。
整體效果比較
#在2個任務一共8個測試資料集上的測試效果如下圖所示。
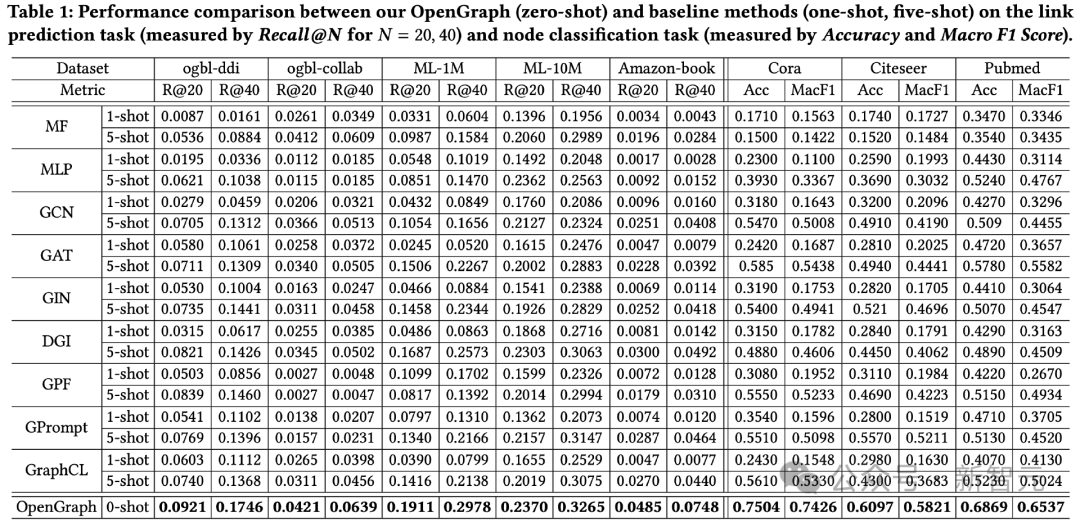
從中可以觀察到:
1)在跨資料集的情況下,OpenGraph的零樣本預測效果相對現有方法有較大的優點。
2)在跨資料集遷移的情況下,現有的預訓練方法有時甚至不如其基礎模型僅在少樣本上從零開始訓練,這體現了圖模型獲得跨資料集泛化能力的困難。
圖Tokenizer研究
#接下來我們探討圖tokenizer設計對效果的影響。首先我們調整了鄰接矩陣平滑結束,測試其對效果的影響。 0階時效果出現嚴重衰減,指示了採用高階平滑的重要性。
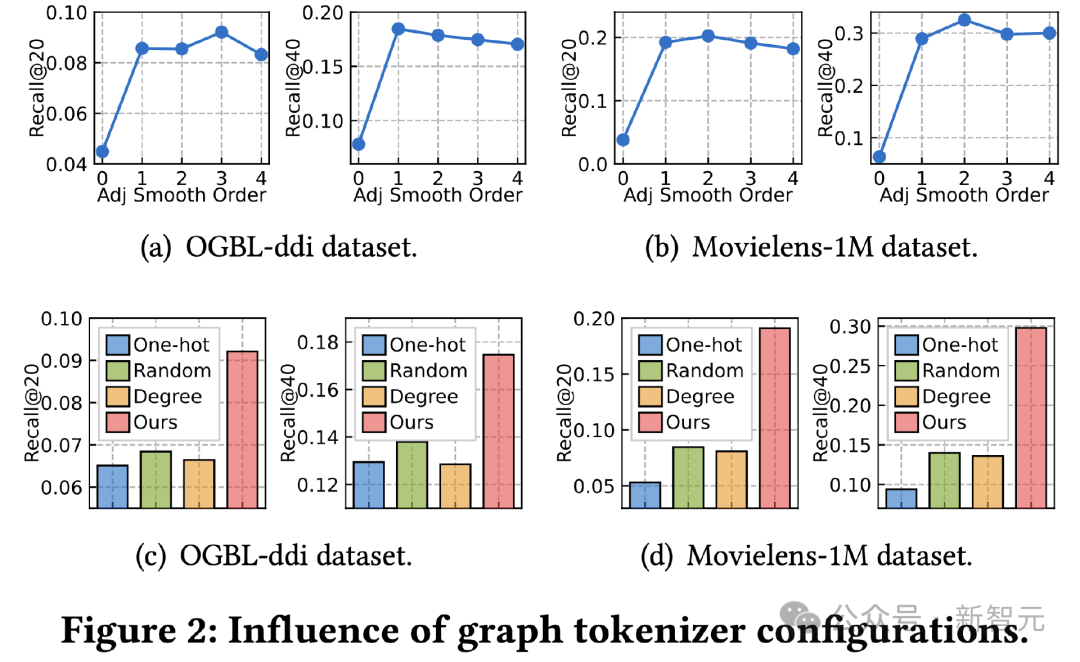
其次,我們將拓樸感知映射函數取代成其他簡單方法,包括跨資料集的可學習獨熱id表徵、隨機映射、基於節點度的可學習表徵。
結果顯示三種替代方案皆效果較差,其中跨資料集學習id表徵效果最差,現有工作中常用的度表徵效果也衰減較大,不可學習的隨機映射在所有替代方法中表現最好,但仍與我們的拓撲感知映射有很大的差距。
預訓練資料集研究
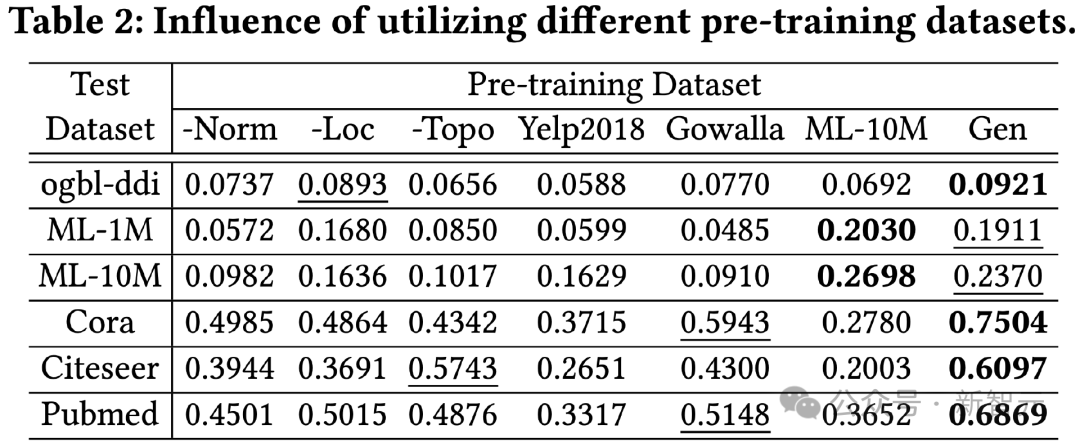
#為了驗證基於LLM的知識蒸餾方法的有效性,我們使用不同的預訓練資料集對OpenGraph進行訓練,並測試其在不同測試集上的效果。
本實驗比較的預訓練資料集包括單獨移除我們產生方法中某個技巧的版本、與測試資料集不相關的兩個真實資料集Yelp2018和Gowalla、以及與測試資料集相關的ML-10M資料集,從結果可以看出:
1)整體來說,我們的生成資料集能夠在所有測試資料上產生較好的效果。
2)所測試的三種生成技巧都起到了較為顯著的提升效果。
3)使用真實資料集(Yelp、Gowalla)進行訓練可能反而會帶來負面效果,這可能源自於不同真實資料集之間的分佈差異。
4)ML-10M在ML-1M和ML-10M上都取得了最佳效果,這說明使用相似的訓練資料集能夠產生較好的效果。
Transformer中的取樣技巧研究
這項實驗對我們圖transformer模組中的token序列採樣(Seq)和錨點採樣(Anc)進行了消融測試。
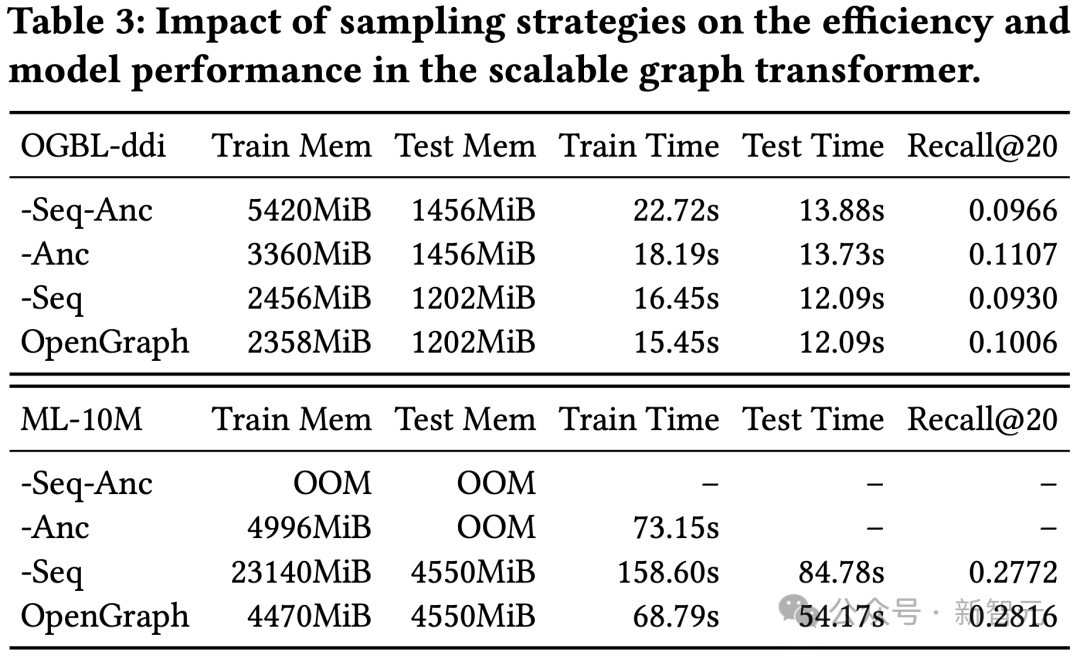
結果顯示,兩種取樣方法能夠在訓練和測試過程中最佳化模型的空間和時間開銷。在效果方面,token序列取樣對模型效果有正向作用,而ddi資料集上的結果顯示,錨點菜樣對模型效果有負面效果。
结论
本研究的主要焦点是开发一个高度适应性的框架,能够精确地捕捉和理解各种图结构中复杂的拓扑模式。
通过发挥所提出模型的潜力,我们的目的是显著提高模型的泛化能力,使其在包括各种下游应用在内的零样本图学习任务中表现出色。
为了进一步提高OpenGraph的效率和健壮性,我们在可扩展的图transformer架构和基于LLM的数据增强机制的基础上构建了我们的模型。
通过在多个基准数据集上进行的大量实验,我们验证了模型的杰出泛化能力。本研究在图基座模型方向作出了初步探索的尝试。
在未来的工作中,我们计划赋予我们的框架自动发现噪声连接和具有反事实学习影响力的结构的能力,同时学习各种图的通用和可转移的结构模式。
以上是首次攻克「圖基礎模型」三大難題!港大開源OpenGraph:零樣本學習適合多種下游任的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想像一下,一個人工智慧模型,不僅擁有超越傳統運算的能力,還能以更低的成本實現更有效率的效能。這不是科幻,DeepSeek-V2[1],全球最強開源MoE模型來了。 DeepSeek-V2是一個強大的專家混合(MoE)語言模型,具有訓練經濟、推理高效的特點。它由236B個參數組成,其中21B個參數用於啟動每個標記。與DeepSeek67B相比,DeepSeek-V2效能更強,同時節省了42.5%的訓練成本,減少了93.3%的KV緩存,最大生成吞吐量提高到5.76倍。 DeepSeek是一家探索通用人工智
 替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
本月初,來自MIT等機構的研究者提出了一種非常有潛力的MLP替代方法—KAN。 KAN在準確性和可解釋性方面表現優於MLP。而且它能以非常少的參數量勝過以更大參數量運行的MLP。例如,作者表示,他們用KAN以更小的網路和更高的自動化程度重現了DeepMind的結果。具體來說,DeepMind的MLP有大約300,000個參數,而KAN只有約200個參數。 KAN與MLP一樣具有強大的數學基礎,MLP基於通用逼近定理,而KAN基於Kolmogorov-Arnold表示定理。如下圖所示,KAN在邊上具
 美國空軍高調展示首個AI戰鬥機!部長親自試駕全程未乾預,10萬行代碼試飛21次
May 07, 2024 pm 05:00 PM
美國空軍高調展示首個AI戰鬥機!部長親自試駕全程未乾預,10萬行代碼試飛21次
May 07, 2024 pm 05:00 PM
最近,軍事圈被這個消息刷屏了:美軍的戰鬥機,已經能由AI完成全自動空戰了。是的,就在最近,美軍的AI戰鬥機首次公開,揭開了神秘面紗。這架戰鬥機的全名是可變穩定性飛行模擬器測試飛機(VISTA),由美空軍部長親自搭乘,模擬了一對一的空戰。 5月2日,美國空軍部長FrankKendall在Edwards空軍基地駕駛X-62AVISTA升空注意,在一小時的飛行中,所有飛行動作都由AI自主完成! Kendall表示——在過去的幾十年中,我們一直在思考自主空對空作戰的無限潛力,但它始終顯得遙不可及。然而如今,
 全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
為了將大型語言模型(LLM)與人類的價值和意圖對齊,學習人類回饋至關重要,這能確保它們是有用的、誠實的和無害的。在對齊LLM方面,一種有效的方法是根據人類回饋的強化學習(RLHF)。儘管RLHF方法的結果很出色,但其中涉及了一些優化難題。其中涉及訓練一個獎勵模型,然後優化一個策略模型來最大化該獎勵。近段時間已有一些研究者探索了更簡單的離線演算法,其中之一就是直接偏好優化(DPO)。 DPO是透過參數化RLHF中的獎勵函數來直接根據偏好資料學習策略模型,這樣就無需顯示式的獎勵模型了。此方法簡單穩定
 無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。这一创新成果在代码生成任务取得了显著突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数
 LLM全搞定! OmniDrive:集3D感知、推理規劃於一體(英偉達最新)
May 09, 2024 pm 04:55 PM
LLM全搞定! OmniDrive:集3D感知、推理規劃於一體(英偉達最新)
May 09, 2024 pm 04:55 PM
寫在前面&筆者的個人理解這篇論文致力於解決當前多模態大語言模型(MLLMs)在自動駕駛應用中存在的關鍵挑戰,即將MLLMs從2D理解擴展到3D空間的問題。由於自動駕駛車輛(AVs)需要針對3D環境做出準確的決策,這項擴展顯得格外重要。 3D空間理解對於AV來說至關重要,因為它直接影響車輛做出明智決策、預測未來狀態以及與環境安全互動的能力。目前的多模態大語言模型(如LLaVA-1.5)通常只能處理較低解析度的影像輸入(例如),這是由於視覺編碼器的分辨率限制,LLM序列長度的限制。然而,自動駕駛應用需
 AI新創集體跳槽OpenAI,Ilya出走後安全團隊重整旗鼓!
Jun 08, 2024 pm 01:00 PM
AI新創集體跳槽OpenAI,Ilya出走後安全團隊重整旗鼓!
Jun 08, 2024 pm 01:00 PM
上週,在內部的離職潮和外部的口誅筆伐之下,OpenAI可謂是內憂外患:-侵權寡姐引發全球熱議-員工簽署“霸王條款”被接連曝出-網友細數奧特曼“七宗罪」闢謠:根據Vox獲取的洩漏資訊和文件,OpenAI的高級領導層,包括Altman在內,非常了解這些股權回收條款,並且簽署了它們。除此之外,還有一個嚴峻而迫切的問題擺在OpenAI面前——AI安全。最近,五名與安全相關的員工離職,其中包括兩名最著名的員工,「超級對齊」團隊的解散讓OpenAI的安全問題再次被置於聚光燈下。 《財星》雜誌報道稱,OpenA
 Yolov10:詳解、部署、應用一站式齊全!
Jun 07, 2024 pm 12:05 PM
Yolov10:詳解、部署、應用一站式齊全!
Jun 07, 2024 pm 12:05 PM
一、前言在过去的几年里,YOLOs由于其在计算成本和检测性能之间的有效平衡,已成为实时目标检测领域的主导范式。研究人员探索了YOLO的架构设计、优化目标、数据扩充策略等,取得了显著进展。同时,依赖非极大值抑制(NMS)进行后处理阻碍了YOLO的端到端部署,并对推理延迟产生不利影响。在YOLOs中,各种组件的设计缺乏全面彻底的检查,导致显著的计算冗余,限制了模型的能力。它提供了次优的效率,以及相对大的性能改进潜力。在这项工作中,目标是从后处理和模型架构两个方面进一步提高YOLO的性能效率边界。为此
