

為了保護客戶隱私,使用Ruby在本地運行開源AI模型

譯者| 陳峻
#審校| 重樓
#最近,我們實作了一個客製化的人工智慧(AI)專案。鑑於甲方持有非常敏感的客戶訊息,為了安全起見,我們不能將它們傳遞給OpenAI或其他專有模型。因此,我們在AWS虛擬機器中下載並運行了一個開源的AI模型,使其完全處於我們的控制之下。同時,Rails應用程式可以在安全的環境中,對AI進行API呼叫。當然,如果不必考慮安全性問題,我們更傾向於直接與OpenAI合作。

下面,我將和大家分享如何在本地下載開源的AI模型,讓它運行起來,以及如何針對其執行Ruby腳本。
為什麼要自訂?
這個專案的動機很簡單:資料安全。在處理敏感的客戶資訊時,最可靠的做法通常是在公司內部進行。因此,我們需要客製化的AI模型,在提供更高等級的安全控制和隱私保護方面發揮作用。
開源模式
#在過去的6個月裡,市場上出現了諸如:Mistral、Mixtral和Lama等大量開源的AI模型。雖然它們沒有GPT-4那麼強大,但是其中不少模型的性能已經超過了GPT-3.5#,而且隨著時間的推移,它們會越來越強。當然,該選用哪種模型,則完全取決於您的處理能力和需要實現的目標。
由於我們將在本地運行AI模型,因此選擇了大小約為4GB的 Mistral。它在大多數指標上都優於GPT-3.5。儘管Mixtral的效能優於Mistral,但它是一個龐大的模型,至少需要48GB記憶體才能運作。
參數
#在談論大語言模型(LLM )時,我們往往會考慮提到它們的參數大小。在此,我們將在本地運行的Mistral模型是一個70億參數的模型(當然,Mixtral有700億個參數,而GPT-3.5大約有
## 1750 億個參數)。 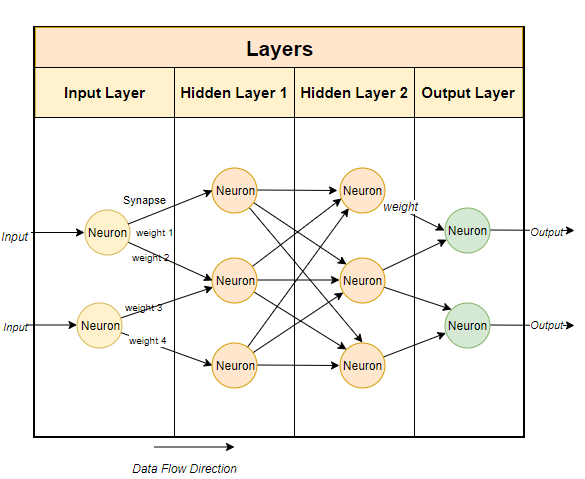
通常,大型語言模型使用基於神經網路的技術。神經網路是由神經元組成的,每個神經元與下一層的所有其他神經元相連。
############################如上所示,每個連線都有一個權重,通常用百分比表示。每個神經元還有一個偏差(bias),當資料通過某個節點時,偏差會對資料進行修正。 ############神經網路的目的是要「學到」一種先進的演算法、一種模式匹配的演算法。透過在大量文本中接受訓練,它將逐漸學會預測文本模式的能力,進而對我們給予的提示做出有意義的回應。簡單而言,參數就是模型中權重和偏差的數量。它可以讓我們了解神經網路中有多少個神經元。例如,對於一個70億參數的模型來說,大約有#100#層,每層都有數千個神經元。
在本機運行模型
#要在本機上執行開源模型,首先必須下載相關應用。雖然市面上有許多選擇,但我發現最簡單,也便於在英特爾Mac#上運行的是Ollama。
雖然Ollama目前只能在Mac#和Linux上運行,不過它未來還能運行在Windows上。當然,您可以在Windows上使用WSL(Windows Subsystem for Linux)來執行Linux shell。
Ollama不但允許您下載並運行各種開源模型,而且會在本地端口上打開模型,讓您能夠通過Ruby程式碼進行API呼叫。這便方便了Ruby開發者編寫能夠與本機模型整合的Ruby應用程式。
取得Ollama
#由於Ollama主要基於命令列,因此在Mac和Linux系統上安裝Ollama非常簡單。您只需透過連結https://www.php.cn/link/04c7f37f2420f0532d7f0e062ff2d5b5下載Ollama,花#5##分鐘左右時間安裝軟體包,再運行模型即可。
#安裝首個模型
#在設定並執行Ollama之後,您將在瀏覽器的工作列中看到Ollama圖示。這意味著它正在後台運行,並可運行您的模型。為了下載模型,您可以打開終端機並執行以下命令:
由於Mistral約有4GB大小,因此您需要花一段時間完成下載。下載完成後,它將自動開啟Ollama提示符,以便您與Mistral#互動和通訊。
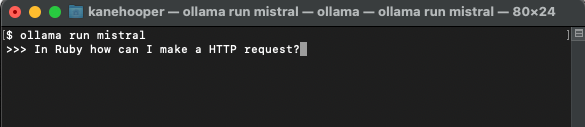
下一次您再透過Ollama執行mistral時,便可直接運行對應的模型了。
自訂模型
#類似我們在OpenAI##在#中建立自訂的GPT,透過Ollama,您可以對基礎模型進行自訂。在此,我們可以簡單地建立一個自訂的模型。更多詳細案例,請參考Ollama的線上文件。
首先,您可以建立一個Modelfile(模型檔案),並在其中加入以下文字:
##FROM mistral# Set the temperature set the randomness or creativity of the responsePARAMETER temperature 0.3# Set the system messageSYSTEM ”””You are an excerpt Ruby developer. You will be asked Program Program. explanation along with code examples.”””接著,您可以在終端機上執行以下命令,以建立新的模型:
ollama create
#Ruby。
ollama create ruby -f './Modelfile'ollama list
至此您可以用如下指令執行自訂的模型了: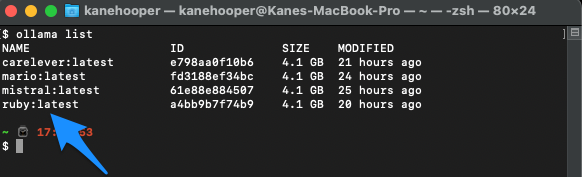
#<h4> <span>與Ruby整合</span><span></span> </h4><p><span>雖然Ollama尚沒有專用的</span><span>gem</span><span>,但</span><span>Ruby</span><span>開發人員可以使用基本的</span><span>HTTP</span><span>#請求方法與模型互動。在背景運行的Ollama可以透過</span><span>11434</span><span>連接埠開啟模型,因此您可以透過「</span><span><a href="https://www.php.cn/link/dcd3f83c96576c0fd437286a1ff6f1f0" rel="nofollow" target="_blank">https://www.php.cn/link/ dcd3f83c96576c0fd437286a1ff6f1f0</a></span><span>」存取它。此外,Ollama</span><span>API</span><span>的文件也為聊天對話和建立嵌入等基本指令提供了不同的端點。 </span><span></span></p><p><span>在本專案案例中,我們希望使用</span><span>/api/chat</span><span>端點向AI模型發送提示。下圖展示了一些與模型互動的基本</span><span>Ruby</span><span>程式碼:</span><span></span></p><p style="text-align:center;"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/465/014/171076920967027.png" class="lazy" alt="為了保護客戶隱私,使用Ruby在本地運行開源AI模型"></p><p><span>上述</span><span>Ruby</span><span>程式碼片段的功能包括:</span><span></span></p>#<ol> <li> <span>透過「</span><span>net/http</span><span>」、「</span><span>uri</span><span>」和「</span><span></span><span></span><span></span><span></span><span></span><span></span><span># #json</span><span>」三個函式庫,分別執行</span><span>HTTP</span> </li>請求、解析<li> <span>URI</span><span>、處理</span><span>JSON</span><span>資料。 </span><span></span><span></span><span>建立包含</span> </li>API<li> <span>#端點位址(</span><span>https://www.php. cn/link/dcd3f83c96576c0fd437286a1ff6f1f0/api/chat</span><span>)的</span><span>URI</span><span>物件。 </span><span></span><span>使用以</span><span>URI</span> </li>為參數的<li> <span>Net::HTTP::Post.new</span><span> #方法,建立新的</span><span>HTTP POST</span> </li>#請求。 </ol><ol data-indent="1"> <li> <span></span><span>請求的正文被設定為一個代表了雜湊值的</span><span>JSON</span><span>字串。此雜湊值包含了三個鍵:「模型」、「訊息」和「流」。其中,</span> </li> <li> <span></span><span>模型鍵被設定為“</span> </li>ruby<li> <span>”,也就是我們的模型;</span> <span></span><span></span><span>訊息鍵被設定為數組,其中包含了代表使用者訊息的單一雜湊值;</span> </li> <li> <span></span><span>#而流鍵被設定為</span> </li>false<li> <span>。 </span><span></span> </li> <li> <span>系統引導模型該如何回應訊息。我們已經在Modelfile中予以了設定。 </span><span></span> </li> </ol><ol start="5">使用者資訊是我們的標準提示。 <li> <span></span><span></span> </li>模型會以輔助資訊回應。 <li> <span></span><span></span><span></span><span>訊息雜湊遵循與AI模型交叉的模式。它帶有一個角色和內容。此處的角色可以是系統、使用者和輔助。其中,</span><span></span><span></span><span>HTTP</span><span>請求使用</span><span>Net::HTTP.start</span><span>方法被傳送。此方法會開啟與指定主機名稱和連接埠的網路連接,然後發送請求。連線的讀取逾時時間被設定為</span><span>120</span><span>秒,畢竟我運行的是</span><span>2019</span> </li>版本英特爾<li> <span></span><span></span><span></span><span></span> </li> </ol><h4> <span></span><span></span> </h4><p><span></span><span> Mac</span><span>,所以反應速度可能有點慢。而在對應的</span><span>AWS</span></p>伺服器上運行時,這將不是問題。 <p><strong><span></span><span></span>伺服器的回應被儲存在「</strong></p>response<p><span>」變數中。 </span><span></span></p><p><span><strong>案例小結</strong></span><a href="https://www.php.cn/link/005f91955ff9fc532184ba7566f088fd" rel="nofollow" target="_blank"><span><strong></strong>#如上所述,運行本地AI模型的真正價值體現在,協助持有敏感數據的公司,處理電子郵件或文件等非結構化的數據,並提取有價值的結構化資訊。在我們參加的專案案例中,我們對客戶關係管理(</span></a>CRM<span><strong>)系統中的所有客戶資訊進行了模型培訓。據此,用戶可以詢問其任何有關客戶的問題,而無需翻閱數百份記錄。 </strong></span></p>
以上是為了保護客戶隱私,使用Ruby在本地運行開源AI模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 位元組跳動剪映推出 SVIP 超級會員:連續包年 499 元,提供多種 AI 功能
Jun 28, 2024 am 03:51 AM
位元組跳動剪映推出 SVIP 超級會員:連續包年 499 元,提供多種 AI 功能
Jun 28, 2024 am 03:51 AM
本站6月27日訊息,剪映是由位元組跳動旗下臉萌科技開發的一款影片剪輯軟體,依託於抖音平台且基本面向該平台用戶製作短影片內容,並相容於iOS、安卓、Windows 、MacOS等作業系統。剪映官方宣布會員體系升級,推出全新SVIP,包含多種AI黑科技,例如智慧翻譯、智慧劃重點、智慧包裝、數位人合成等。價格方面,剪映SVIP月費79元,年費599元(本站註:折合每月49.9元),連續包月則為59元每月,連續包年為499元每年(折合每月41.6元) 。此外,剪映官方也表示,為提升用戶體驗,向已訂閱了原版VIP
 為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
為大模型提供全新科學複雜問答基準與評估體系,UNSW、阿貢、芝加哥大學等多家機構共同推出SciQAG框架
Jul 25, 2024 am 06:42 AM
編輯|ScienceAI問答(QA)資料集在推動自然語言處理(NLP)研究中發揮著至關重要的作用。高品質QA資料集不僅可以用於微調模型,也可以有效評估大語言模型(LLM)的能力,尤其是針對科學知識的理解和推理能力。儘管目前已有許多科學QA數據集,涵蓋了醫學、化學、生物等領域,但這些數據集仍有一些不足之處。其一,資料形式較為單一,大多數為多項選擇題(multiple-choicequestions),它們易於進行評估,但限制了模型的答案選擇範圍,無法充分測試模型的科學問題解答能力。相比之下,開放式問答
 SOTA性能,廈大多模態蛋白質-配體親和力預測AI方法,首次結合分子表面訊息
Jul 17, 2024 pm 06:37 PM
SOTA性能,廈大多模態蛋白質-配體親和力預測AI方法,首次結合分子表面訊息
Jul 17, 2024 pm 06:37 PM
編輯|KX在藥物研發領域,準確有效地預測蛋白質與配體的結合親和力對於藥物篩選和優化至關重要。然而,目前的研究並沒有考慮到分子表面訊息在蛋白質-配體相互作用中的重要作用。基於此,來自廈門大學的研究人員提出了一種新穎的多模態特徵提取(MFE)框架,該框架首次結合了蛋白質表面、3D結構和序列的信息,並使用交叉注意機制進行不同模態之間的特徵對齊。實驗結果表明,該方法在預測蛋白質-配體結合親和力方面取得了最先進的性能。此外,消融研究證明了該框架內蛋白質表面資訊和多模態特徵對齊的有效性和必要性。相關研究以「S
 SK 海力士 8 月 6 日將展示 AI 相關新品:12 層 HBM3E、321-high NAND 等
Aug 01, 2024 pm 09:40 PM
SK 海力士 8 月 6 日將展示 AI 相關新品:12 層 HBM3E、321-high NAND 等
Aug 01, 2024 pm 09:40 PM
本站8月1日消息,SK海力士今天(8月1日)發布博文,宣布將出席8月6日至8日,在美國加州聖克拉拉舉行的全球半導體記憶體峰會FMS2024,展示諸多新一代產品。未來記憶體和儲存高峰會(FutureMemoryandStorage)簡介前身是主要面向NAND供應商的快閃記憶體高峰會(FlashMemorySummit),在人工智慧技術日益受到關注的背景下,今年重新命名為未來記憶體和儲存高峰會(FutureMemoryandStorage),以邀請DRAM和儲存供應商等更多參與者。新產品SK海力士去年在
 佈局 AI 等市場,格芯收購泰戈爾科技氮化鎵技術和相關團隊
Jul 15, 2024 pm 12:21 PM
佈局 AI 等市場,格芯收購泰戈爾科技氮化鎵技術和相關團隊
Jul 15, 2024 pm 12:21 PM
本站7月5日消息,格芯(GlobalFoundries)於今年7月1日發布新聞稿,宣布收購泰戈爾科技(TagoreTechnology)的功率氮化鎵(GaN)技術及智慧財產權組合,希望在汽車、物聯網和人工智慧資料中心應用領域探索更高的效率和更好的效能。隨著生成式人工智慧(GenerativeAI)等技術在數位世界的不斷發展,氮化鎵(GaN)已成為永續高效電源管理(尤其是在資料中心)的關鍵解決方案。本站引述官方公告內容,在本次收購過程中,泰戈爾科技公司工程師團隊將加入格芯,進一步開發氮化鎵技術。 G
 Iyo One:是耳機,也是音訊計算機
Aug 08, 2024 am 01:03 AM
Iyo One:是耳機,也是音訊計算機
Aug 08, 2024 am 01:03 AM
任何時候,專注都是一種美德。作者|湯一濤編輯|靖宇人工智慧的再次流行,催生了新一波的硬體創新。風頭最勁的AIPin遭遇了前所未有的負評。 MarquesBrownlee(MKBHD)稱這是他評測過的最糟糕的產品;TheVerge的編輯DavidPierce則表示,他不會建議任何人購買這款設備。它的競爭對手RabbitR1也沒有好到哪裡去。對這款AI設備最大的質疑是,明明只是做一個App的事情,但Rabbit公司卻整出了一個200美元的硬體。許多人把AI硬體創新視為顛覆智慧型手機時代的機會,並投身其
 首個全自動科學發現AI系統,Transformer作者新創公司Sakana AI推出AI Scientist
Aug 13, 2024 pm 04:43 PM
首個全自動科學發現AI系統,Transformer作者新創公司Sakana AI推出AI Scientist
Aug 13, 2024 pm 04:43 PM
編輯|ScienceAI一年前,Google最後一位Transformer論文作者LlionJones離職創業,與前Google研究人員DavidHa共同創立人工智慧公司SakanaAI。 SakanaAI聲稱將創建一種基於自然啟發智能的新型基礎模型!現在,SakanaAI交上了自己的答案。 SakanaAI宣布推出AIScientist,這是世界上第一個用於自動化科學研究和開放式發現的AI系統!從構思、編寫程式碼、運行實驗和總結結果,到撰寫整篇論文和進行同行評審,AIScientist開啟了AI驅動的科學研究和加速
 怎麼在手機上把XML文件轉換為PDF?
Apr 02, 2025 pm 10:12 PM
怎麼在手機上把XML文件轉換為PDF?
Apr 02, 2025 pm 10:12 PM
不可能直接在手機上用單一應用完成 XML 到 PDF 的轉換。需要使用雲端服務,通過兩步走的方式實現:1. 在雲端轉換 XML 為 PDF,2. 在手機端訪問或下載轉換後的 PDF 文件。
