

谷歌發布'Vlogger”模型:單張圖片生成10秒視頻

Google發布了一個新的視訊框架:
只需要一張你的頭像、一段講話錄音,就能得到一個本人栩栩如生的演講影片。
影片長度可變,目前看到的範例最高為10s。
可以看到,無論是口型還是臉部表情,它都非常自然。
如果輸入影像囊括整個上半身,它也能配合豐富的手勢:

網友看完就表示:
有了它,以後咱開線上視訊會議再也不需要整理好髮型、穿好衣服再去了。
嗯,拍一張肖像,錄好演講音頻就可以(手動狗頭)
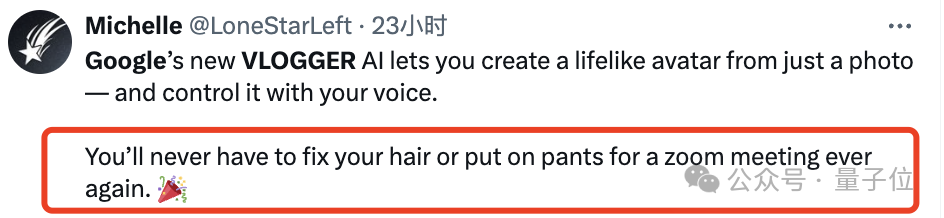
用聲音控制肖像生成影片
這個框架叫做VLOGGER。
它主要基於擴散模型,並包含兩部分:
一個是隨機的人體到3D運動(human-to-3d-motion)擴散模型。
另一個是用於增強文字到圖像模型的新擴散架構。
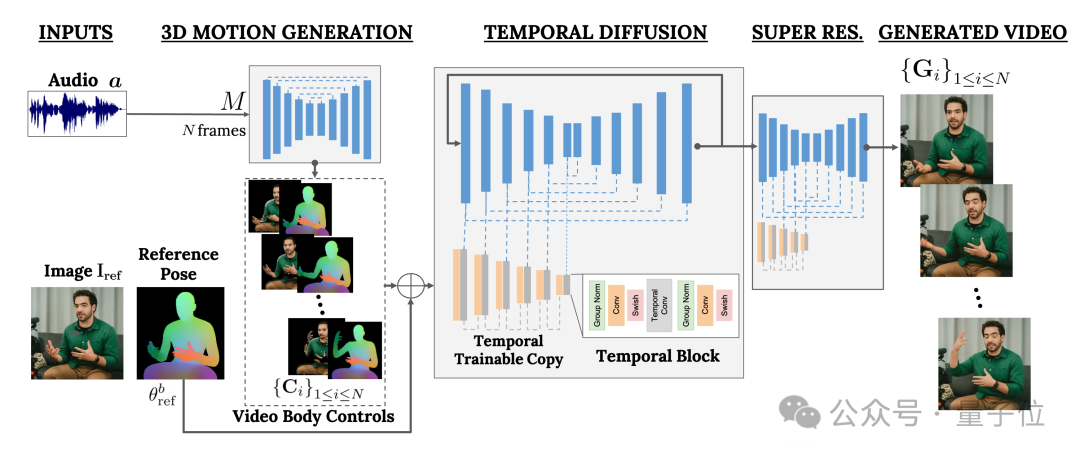
其中,前者負責將音訊波形作為輸入,產生人物的身體控制動作,包括眼神、表情和手勢、身體整體姿勢等等。
後者則是一個時間維度的圖像到圖像模型,用於擴展大型圖像擴散模型,使用剛剛預測的動作來產生相應的幀。
為了讓結果符合特定的人物形象,VLOGGER也將參數影像的pose圖作為輸入。
VLOGGER的訓練是在一個超大的資料集(名叫MENTOR)上完成的。
有多大? 全長2200小時,共包含80萬個人物影片。
其中,測試集的影片長度也有120小時長,共4000個人物。
Google介紹,VLOGGER最突出的表現是具備多樣性:
如下圖所示,最後的像素圖顏色越深(紅)的部分,代表動作越豐富。

而和業界先前的同類方法相比,VLOGGER最大的優勢則體現在不需要對每個人進行訓練、也不依賴於臉部偵測和裁剪,並且生成的影片很完整(既包括臉部和唇部,也包括肢體動作)等等。

具體來看,如下表所示:
Face Reenactment方法無法用音訊和文字來控制此類視訊生成。
Audio-to-motion倒是可以音訊生成,方式也是將音訊編碼為3D人臉動作,不過它生成的效果不夠逼真。
Lip sync可以處理不同主題的視頻,但只能模擬嘴部動作。
對比起來,後面的兩種方法SadTaker和Styletalk表現最接近谷歌VLOGGER,但也敗在了不能進行身體控制上,並且也不能進一步編輯視頻。

說到影片編輯,如下圖所示,VLOGGER模型的應用之一就是這個,它可以一鍵讓人物閉嘴、閉眼、只閉左眼或全程睜開:

另一個應用程式則是影片翻譯:
例如將原始影片的英文講話改成口型一致的西班牙文。
網友吐槽
最後,“老規矩”,Google沒有發布模型,現在能看的只有更多效果還有論文。
嗯,吐槽也是不少的:
畫質模型、口型抽風對不上、看起來還是很機器人等等。
因此,有人毫不猶豫打上負評:
這就是Google的水準嗎?

有點對不起「VLOGGER」這個名字了。

——和OpenAI的Sora對比,網友的說法確實也不是沒有道理。 。
大家覺得呢?
更多效果:https://enriccorona.github.io/vlogger/
完整論文:https://enriccorona.github.io/vlogger/paper.pdf
以上是谷歌發布'Vlogger”模型:單張圖片生成10秒視頻的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 如何用OPPO手機錄製螢幕影片(簡單操作)
May 07, 2024 pm 06:22 PM
如何用OPPO手機錄製螢幕影片(簡單操作)
May 07, 2024 pm 06:22 PM
遊戲技巧或進行教學演示,在日常生活中,我們經常需要用手機錄製螢幕影片來展示一些操作步驟。其錄製螢幕影片的功能也非常出色,而OPPO手機作為一款功能強大的智慧型手機。讓您輕鬆快速地完成錄製任務、本文將詳細介紹如何使用OPPO手機來錄製螢幕影片。準備工作-確定錄製目標您需要明確自己的錄製目標、在開始之前。是要錄製一個操作步驟的示範影片?還是要錄製一個遊戲的精彩時刻?還是要錄製一段教學影片?才能更好地安排錄製過程、只有明確目標。開啟OPPO手機的錄影功能在快速面板中找到、錄影功能位於快速面板中,在
 替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
本月初,來自MIT等機構的研究者提出了一種非常有潛力的MLP替代方法—KAN。 KAN在準確性和可解釋性方面表現優於MLP。而且它能以非常少的參數量勝過以更大參數量運行的MLP。例如,作者表示,他們用KAN以更小的網路和更高的自動化程度重現了DeepMind的結果。具體來說,DeepMind的MLP有大約300,000個參數,而KAN只有約200個參數。 KAN與MLP一樣具有強大的數學基礎,MLP基於通用逼近定理,而KAN基於Kolmogorov-Arnold表示定理。如下圖所示,KAN在邊上具
 Adobe After Effects cs6(Ae cs6)怎麼切換語言 Ae cs6中英文切換的詳細步驟-ZOL下載
May 09, 2024 pm 02:00 PM
Adobe After Effects cs6(Ae cs6)怎麼切換語言 Ae cs6中英文切換的詳細步驟-ZOL下載
May 09, 2024 pm 02:00 PM
1.首先找到AMTLanguages這個資料夾。我們發現了在AMTLanguages資料夾中的一些文件。如果你安裝的是簡體中文,會有一個zh_CN.txt的文字文件(文字內容為:zh_CN)。如果你安裝的是英文,會有一個en_US.txt的文字文件(文字內容為:en_US)。 3.所以,如果我們要切換到中文,我們要在AdobeAfterEffectsCCSupportFilesAMTLanguages路徑下,新建zh_CN.txt的文本文檔(文字內容是:zh_CN)。 4.相反如果我們要切換到英文,
 快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
什麼?瘋狂動物城被國產AI搬進現實了?與影片一同曝光的,是一款名為「可靈」全新國產影片生成大模型。 Sora利用了相似的技術路線,結合多項自研技術創新,生產的影片不僅運動幅度大且合理,還能模擬物理世界特性,具備強大的概念組合能力與想像。數據上看,可靈支持生成長達2分鐘的30fps的超長視頻,分辨率高達1080p,且支援多種寬高比。另外再劃個重點,可靈不是實驗室放出的Demo或影片結果演示,而是短影片領域頭部玩家快手推出的產品級應用。而且主打一個務實,不開空頭支票、發布即上線,可靈大模型已在快影
 美國空軍高調展示首個AI戰鬥機!部長親自試駕全程未乾預,10萬行代碼試飛21次
May 07, 2024 pm 05:00 PM
美國空軍高調展示首個AI戰鬥機!部長親自試駕全程未乾預,10萬行代碼試飛21次
May 07, 2024 pm 05:00 PM
最近,軍事圈被這個消息刷屏了:美軍的戰鬥機,已經能由AI完成全自動空戰了。是的,就在最近,美軍的AI戰鬥機首次公開,揭開了神秘面紗。這架戰鬥機的全名是可變穩定性飛行模擬器測試飛機(VISTA),由美空軍部長親自搭乘,模擬了一對一的空戰。 5月2日,美國空軍部長FrankKendall在Edwards空軍基地駕駛X-62AVISTA升空注意,在一小時的飛行中,所有飛行動作都由AI自主完成! Kendall表示——在過去的幾十年中,我們一直在思考自主空對空作戰的無限潛力,但它始終顯得遙不可及。然而如今,
 抖音如何拍攝影片?拍攝視訊麥克風怎麼開?
May 09, 2024 pm 02:40 PM
抖音如何拍攝影片?拍攝視訊麥克風怎麼開?
May 09, 2024 pm 02:40 PM
抖音作為當今最受歡迎的短影片平台之一,其拍攝影片的品質和效果直接影響到用戶的觀看體驗。那麼,如何在抖音上拍攝出高品質的影片呢?一、抖音如何拍攝影片? 1.開啟抖音APP,點選底部中間的「+號」按鈕,進入影片拍攝頁面。 2.抖音提供了多種拍攝模式,包括正常拍攝、慢動作、短影片等。根據需要選擇合適的拍攝模式。 3.在拍攝頁面,點選螢幕下方的「濾鏡」按鈕,可以選擇不同的濾鏡效果,讓影片更有個性。 4.如果需要調整曝光度、對比等參數,可以點選螢幕左下角的「參數」按鈕進行設定。 5.拍攝過程中,可以點選螢幕左
 全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
為了將大型語言模型(LLM)與人類的價值和意圖對齊,學習人類回饋至關重要,這能確保它們是有用的、誠實的和無害的。在對齊LLM方面,一種有效的方法是根據人類回饋的強化學習(RLHF)。儘管RLHF方法的結果很出色,但其中涉及了一些優化難題。其中涉及訓練一個獎勵模型,然後優化一個策略模型來最大化該獎勵。近段時間已有一些研究者探索了更簡單的離線演算法,其中之一就是直接偏好優化(DPO)。 DPO是透過參數化RLHF中的獎勵函數來直接根據偏好資料學習策略模型,這樣就無需顯示式的獎勵模型了。此方法簡單穩定
 無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
無需OpenAI數據,躋身程式碼大模型榜單! UIUC發表StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。这一创新成果在代码生成任务取得了显著突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数
