

Stable Video 3D震撼登場:單圖生成無死角3D影片、模型權重開放

Stability AI 的大模型家族来了一位新成员。
昨日,Stability AI 继推出文生图 Stable Diffusion、文生视频 Stable Video Diffusion 之后,又为社区带来了 3D 视频生成大模型「Stable Video 3D」(简称 SV3D)。
该模型是基于 Stable Video Diffusion 构建的,其主要优势在于显著提升了3D生成的质量和多视角一致性。相较于之前的Stability AI推出的Stable Zero123以及联合开源的Zero123-XL,该模型的效果更为出色。
目前,Stable Video 3D 既支持商用,需要加入 Stability AI 会员(Membership);也支持非商用,用户在 Hugging Face 上下载模型权重即可。

Stability AI 提供了两个模型变体,分别是 SV3D_u 和 SV3D_p。SV3D_u 基于单个图像输入,无需进行相机调整即可生成轨道视频;而 SV3D_p 则进一步扩展了生成能力,通过适配单个图像和轨道视角,允许用户沿指定的相机路径创建 3D 视频。
目前,Stable Video 3D 的研究论文已经放出,核心作者有三位。

- 论文地址:https://stability.ai/s/SV3D_report.pdf
- 博客地址:https://stability.ai/news/introducing-stable-video-3d
- Huggingface 地址:https://huggingface.co/stabilityai/sv3d
技术概览
Stable Video 3D 在 3D 生成领域实现重大进步,尤其是在新颖视图生成(novel view synthesis,NVS)方面。
以往的方法通常倾向于解决有限视角和输入不一致的问题,而 Stable Video 3D 能够从任何给定角度提供连贯视图,并能够很好地泛化。因此,该模型不仅增加了姿势可控性,还能确保多个视图中对象外观的一致性,进一步改进了影响真实和准确 3D 生成的关键问题。
如下图所示,与 Stable Zero123、Zero-XL 相比,Stable Video 3D 能够生成细节更强、更忠实于输入图像和多视角更一致的新颖多视图。

此外,Stable Video 3D 利用其多视角一致性来优化 3D 神经辐射场(Neural Radiance Fields,NeRF),以提高直接从新视图生成 3D 网格的质量。
為此,Stability AI 設計了遮罩分數蒸餾取樣損失,進一步增強了預測視圖中未見過區域的 3D 品質。同時為了減輕烘焙照明問題,Stable Video 3D 採用了與 3D 形狀和紋理共同優化的解耦照明模型。
下圖為使用 Stable Video 3D 模型及其輸出時,透過 3D 最佳化改進後的 3D 網格產生範例。

下圖為使用 Stable Video 3D 產生的 3D 網格結果與 EscherNet、Stable Zero123 的產生結果比較。

#架構細節
#Stable Video 3D 模型的架構如下圖2所示,它是基於Stable Video Diffusion 架構建構而成,包含一個具有多個層的UNet,其中每一層又包含一個帶有Conv3D 層的殘差塊序列,以及兩個帶有註意力層(空間和時間)的transformer 區塊。
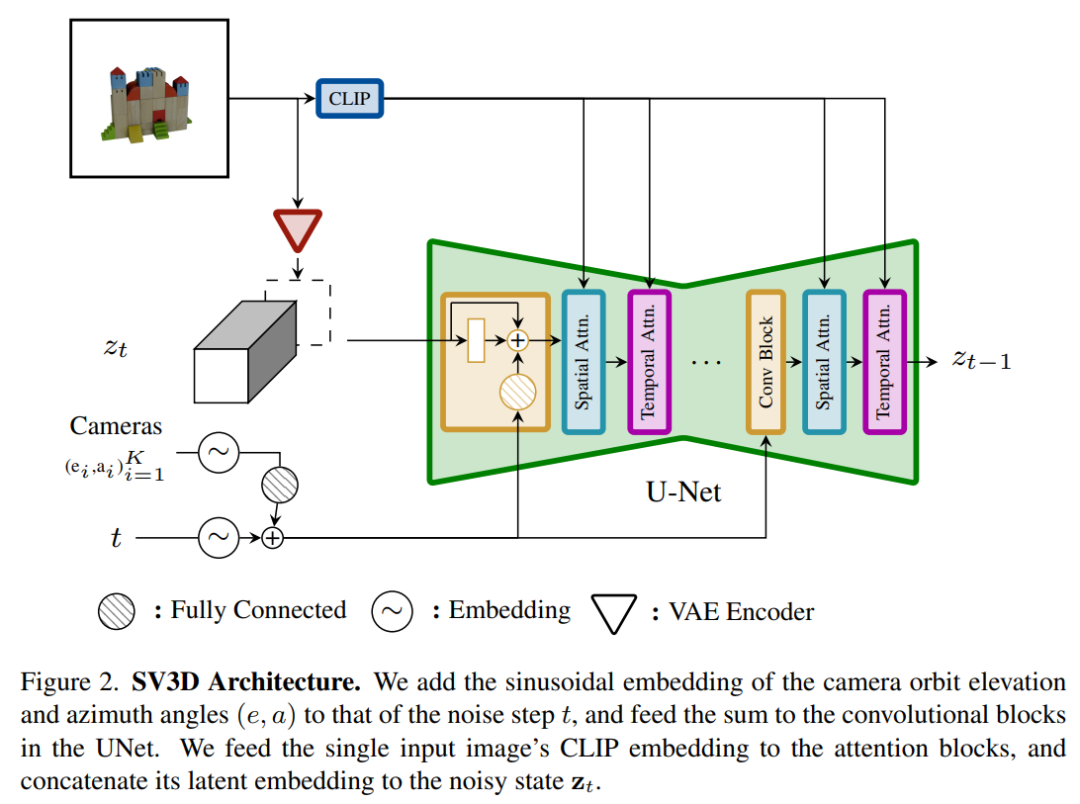
具體流程如下所示:
(i) 刪除「fps id」和「motion bucket id」的向量條件,原因是它們與Stable Video 3D 無關;
(ii) 條件圖像透過Stable Video Diffusion 的VAE 編碼器嵌入到潛在空間,然後在通往UNet 的雜訊時間步t 處連接到雜訊潛在狀態輸入zt;
(iii) 條件影像的CLIPembedding 矩陣被提供給每個transformer 區塊的交叉注意力層來充當鍵和值,而查詢成為對應層的特徵;
(iv) 相機軌跡沿著擴散雜訊時間步被饋入到殘差區塊中。相機姿勢角度ei 和ai 以及噪聲時間步t 首先被嵌入到正弦位置嵌入中,然後將相機姿勢嵌入連接在一起進行線性變換並添加到噪聲時間步嵌入中,最後被饋入到每個殘差塊並被加入到該區塊的輸入特徵中。
此外,Stability AI 設計了靜態軌道和動態軌道來研究相機姿勢調整的影響,如下圖 3 所示。
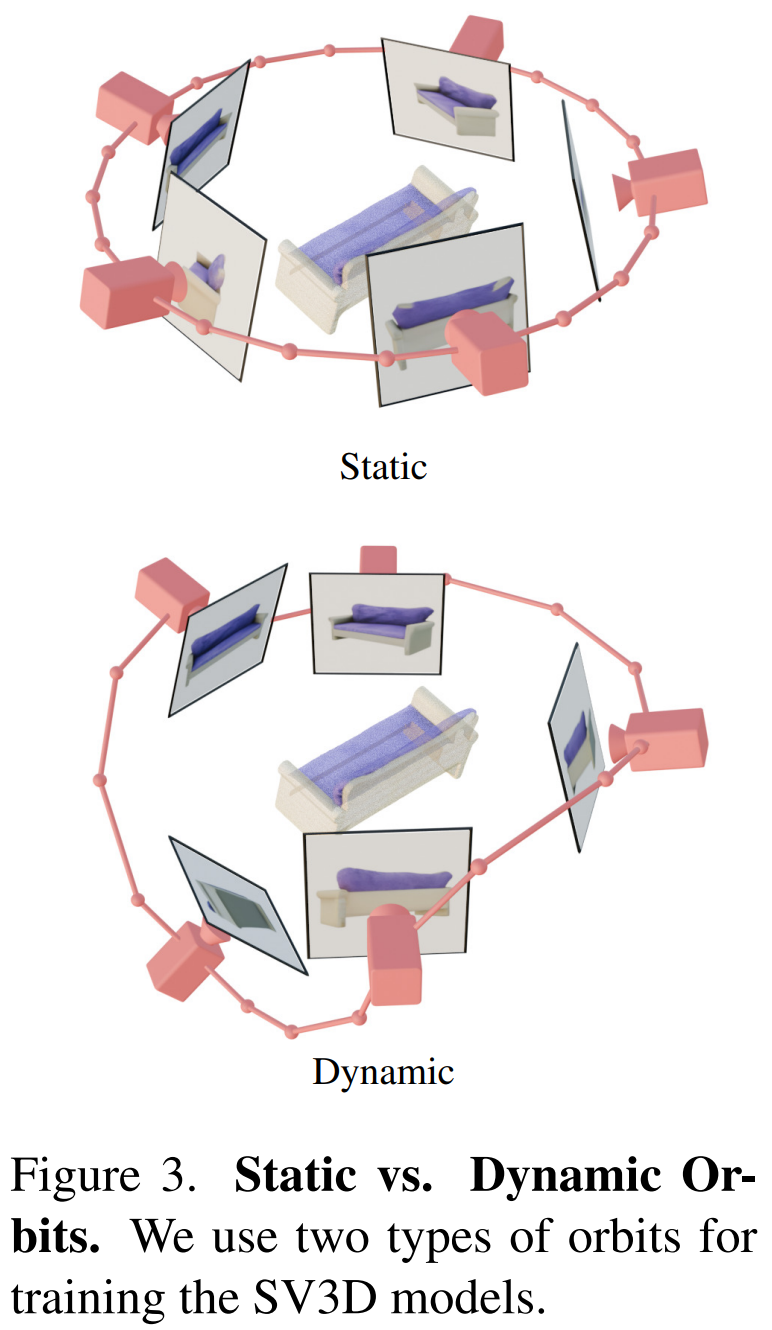
在靜態軌道上,相機採用與條件影像相同的仰角,以等距方位角圍繞物件旋轉。這樣做的缺點是基於調整的仰角,可能無法獲得關於物件頂部或底部的任何資訊。而在動態軌道上,方位角可以不等距,每個視圖的仰角也可以不同。
為了建立動態軌道,Stability AI 對靜態軌道取樣,向方位角添加小的隨機噪聲,並向其仰角添加不同頻率的正弦曲線的隨機加權組合。這樣做提供了時間平滑性,並確保相機軌跡沿著與條件影像相同的方位角和仰角循環結束。
實驗結果
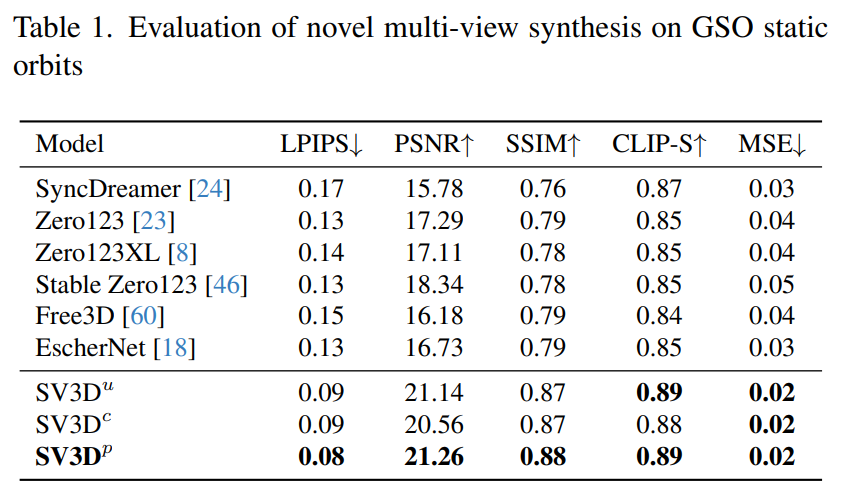
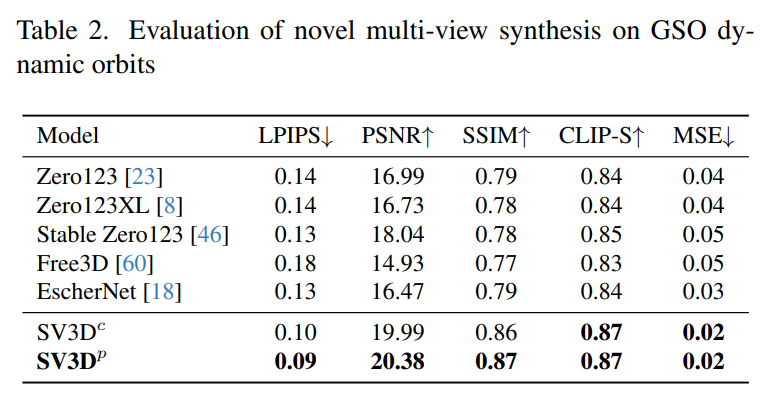
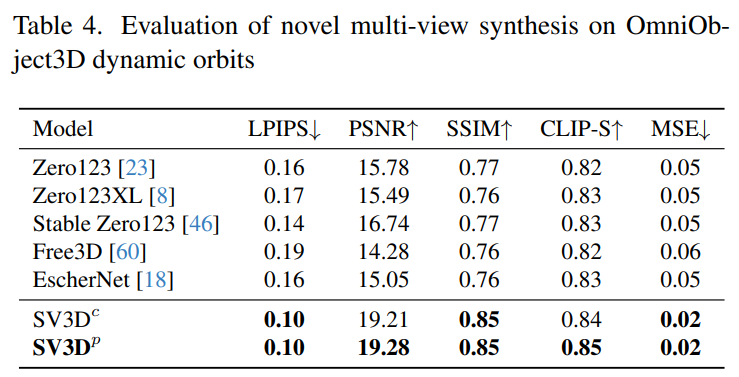
Stability AI 在未見過的GSO 和OmniObject3D 資料集上,評估了靜態和動態軌道上的Stable Video 3D 合成多視圖效果。結果如下表 1 至表 4 所示,Stable Video 3D 在新穎多視圖合成方面實現了 SOTA 效果。
表1 和表3 顯示了Stable Video 3D 與其他模型在靜態軌道的結果,顯示了即使是無姿勢調整的模型SV3D_u,也比所有先前的方法表現得更好。
消融分析結果表明,SV3D_c 和 SV3D_p 在靜態軌道的生成方面優於 SV3D_u,儘管後者專門在靜態軌道上進行了訓練。
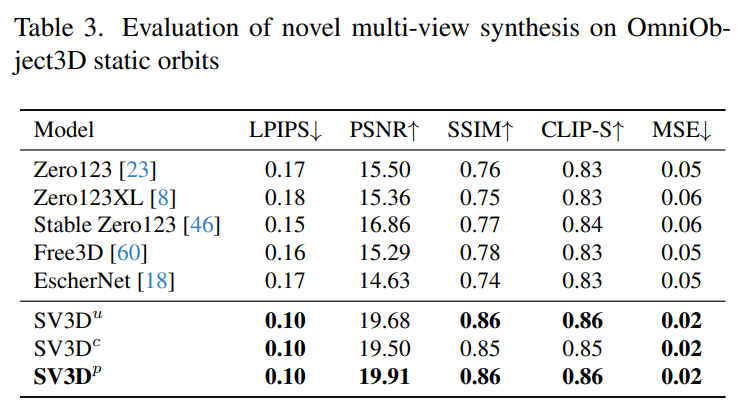
下表2 和表4 展示了動態軌道的產生結果,包括姿勢調整模型SV3D_c 和SV3D_p,後者在所有指標上實現了SOTA。
下圖6 中的視覺比較結果進一步表明,與以往工作相比,Stable Video 3D產生的影像細節更強、更忠於條件影像、多視角更加一致。

更多技術細節和實驗結果請參考原始論文。
以上是Stable Video 3D震撼登場:單圖生成無死角3D影片、模型權重開放的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
本文介紹如何在Debian系統上自定義Apache的日誌格式。以下步驟將指導您完成配置過程:第一步:訪問Apache配置文件Debian系統的Apache主配置文件通常位於/etc/apache2/apache2.conf或/etc/apache2/httpd.conf。使用以下命令以root權限打開配置文件:sudonano/etc/apache2/apache2.conf或sudonano/etc/apache2/httpd.conf第二步:定義自定義日誌格式找到或
 Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌是診斷內存洩漏問題的關鍵。通過分析Tomcat日誌,您可以深入了解內存使用情況和垃圾回收(GC)行為,從而有效定位和解決內存洩漏。以下是如何利用Tomcat日誌排查內存洩漏:1.GC日誌分析首先,啟用詳細的GC日誌記錄。在Tomcat啟動參數中添加以下JVM選項:-XX: PrintGCDetails-XX: PrintGCDateStamps-Xloggc:gc.log這些參數會生成詳細的GC日誌(gc.log),包含GC類型、回收對像大小和時間等信息。分析gc.log
 debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
在Debian系統中,readdir函數用於讀取目錄內容,但其返回的順序並非預先定義的。要對目錄中的文件進行排序,需要先讀取所有文件,再利用qsort函數進行排序。以下代碼演示瞭如何在Debian系統中使用readdir和qsort對目錄文件進行排序:#include#include#include#include//自定義比較函數,用於qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系統中,readdir系統調用用於讀取目錄內容。如果其性能表現不佳,可嘗試以下優化策略:精簡目錄文件數量:盡可能將大型目錄拆分成多個小型目錄,降低每次readdir調用處理的項目數量。啟用目錄內容緩存:構建緩存機制,定期或在目錄內容變更時更新緩存,減少對readdir的頻繁調用。內存緩存(如Memcached或Redis)或本地緩存(如文件或數據庫)均可考慮。採用高效數據結構:如果自行實現目錄遍歷,選擇更高效的數據結構(例如哈希表而非線性搜索)存儲和訪問目錄信
 debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
Debian系統中的readdir函數是用於讀取目錄內容的系統調用,常用於C語言編程。本文將介紹如何將readdir與其他工具集成,以增強其功能。方法一:C語言程序與管道結合首先,編寫一個C程序調用readdir函數並輸出結果:#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
本文介紹如何在Debian系統中使用iptables或ufw配置防火牆規則,並利用Syslog記錄防火牆活動。方法一:使用iptablesiptables是Debian系統中功能強大的命令行防火牆工具。查看現有規則:使用以下命令查看當前的iptables規則:sudoiptables-L-n-v允許特定IP訪問:例如,允許IP地址192.168.1.100訪問80端口:sudoiptables-AINPUT-ptcp--dport80-s192.16
 Debian syslog如何學習
Apr 13, 2025 am 11:51 AM
Debian syslog如何學習
Apr 13, 2025 am 11:51 AM
本指南將指導您學習如何在Debian系統中使用Syslog。 Syslog是Linux系統中用於記錄系統和應用程序日誌消息的關鍵服務,它幫助管理員監控和分析系統活動,從而快速識別並解決問題。一、Syslog基礎知識Syslog的核心功能包括:集中收集和管理日誌消息;支持多種日誌輸出格式和目標位置(例如文件或網絡);提供實時日誌查看和過濾功能。二、安裝和配置Syslog(使用Rsyslog)Debian系統默認使用Rsyslog。您可以通過以下命令安裝:sudoaptupdatesud
 Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
在Debian郵件服務器上安裝SSL證書的步驟如下:1.安裝OpenSSL工具包首先,確保你的系統上已經安裝了OpenSSL工具包。如果沒有安裝,可以使用以下命令進行安裝:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私鑰和證書請求接下來,使用OpenSSL生成一個2048位的RSA私鑰和一個證書請求(CSR):openss
