

一文讀懂大型語言模型微調技術挑戰與最佳化策略

大家好,我是Luga。今天我們將繼續探討人工智慧生態領域的技術,特別是LLM Fine-Tuning。本文將持續深入剖析LLM Fine-Tuning技術,幫助大家更能理解其實現機制,以便更好地應用於市場開發和其他領域。

LLMs (Large Language Models )正在引領人工智慧技術的新浪潮。這種先進的 AI 透過利用統計模型分析大量數據,學習單字和詞組之間的複雜模式,從而模擬人類認知和語言能力。 LLMs 的強大功能已引起了眾多頭部企業以及科技愛好者的濃厚興趣,他們紛紛競相採用這些由人工智慧驅動的創新解決方案,旨在提高營運效率、減輕工作負擔、降低成本支出,並最終激發出更多創造業務價值的創新想法。
然而,要真正發揮 LLMs 的潛力,關鍵在於「客製化」。即企業如何將通用的預訓練模型,透過特定的最佳化策略,轉換為契合自身獨特業務需求和使用案例情境的專屬模型。鑑於不同企業和應用場景的差異,選擇合適的LLM整合方法便顯得尤為重要。因此,準確評估具體的用例需求,並理解不同整合選項之間細微的差異和權衡,將有助於企業做出明智的決策。
什麼是 Fine-Tuning (微調) ?
在當今知識普及化的時代,獲取有關 AI 和 LLM 的資訊和觀點變得前所未有的容易。然而,要找到實際可行、符合具體情境的專業解答仍面臨挑戰。在我們的日常生活中,經常遇到這樣一種普遍存在的誤解:人們普遍認為,Fine-Tuning (微調)模型是使 LLM 獲取新知識的唯一(或者可能是最佳)方式。事實上,無論是為產品增添智慧協作助手,還是使用 LLM 分析儲存在雲端的大量非結構化數據,企業的實際數據和業務環境都是選擇合適 LLM 方法的關鍵因素。
在許多情況下,與傳統的微調方法相比,採用操作複雜度更低、對頻繁變化的資料集具有更強穩健性、能產生更可靠準確結果的替代策略,往往更能有效達成企業的目標。微調雖然是一種常見的 LLM 客製化技術,透過在特定資料集上對預訓練模型進行額外的訓練,使其更好地適應特定任務或領域,但它也存在一些重要的權衡和限制。
那麼,什麼是 Fine-Tuning (微調)?
LLM (大型語言模型) 微調是近年來 NLP (自然語言處理) 領域中備受關注的技術之一。它透過在已經訓練好的模型上進行額外的訓練,讓模型能夠更好地適應特定領域或任務。這種方法能夠使模型學習到更多與特定領域相關的知識,從而在這個領域或任務中取得更好的表現。 LLM 微調的優點在於利用了預訓練模型已經學到的通用知識,然後在特定領域上進行進一步的微調,從而在特定任務上獲得更高的準確性和性能。這種方法已經被廣泛運用在各種NLP任務中,取得了顯
LLM微調的主要概念在於利用預訓練模型的參數作為新任務的基礎,並透過少量特定領域或任務資料的微調,讓模型能夠快速適應新任務或資料集。這種方法可以節省大量訓練時間和資源,同時提高模型在新任務上的表現表現。 LLM微調的靈活性和高效性使得它成為許多自然語言處理任務中的首選方法之一。透過在預訓練模型的基礎上進行微調,模型可以更快地學習新任務的特徵和模式,從而提高整體表現。這
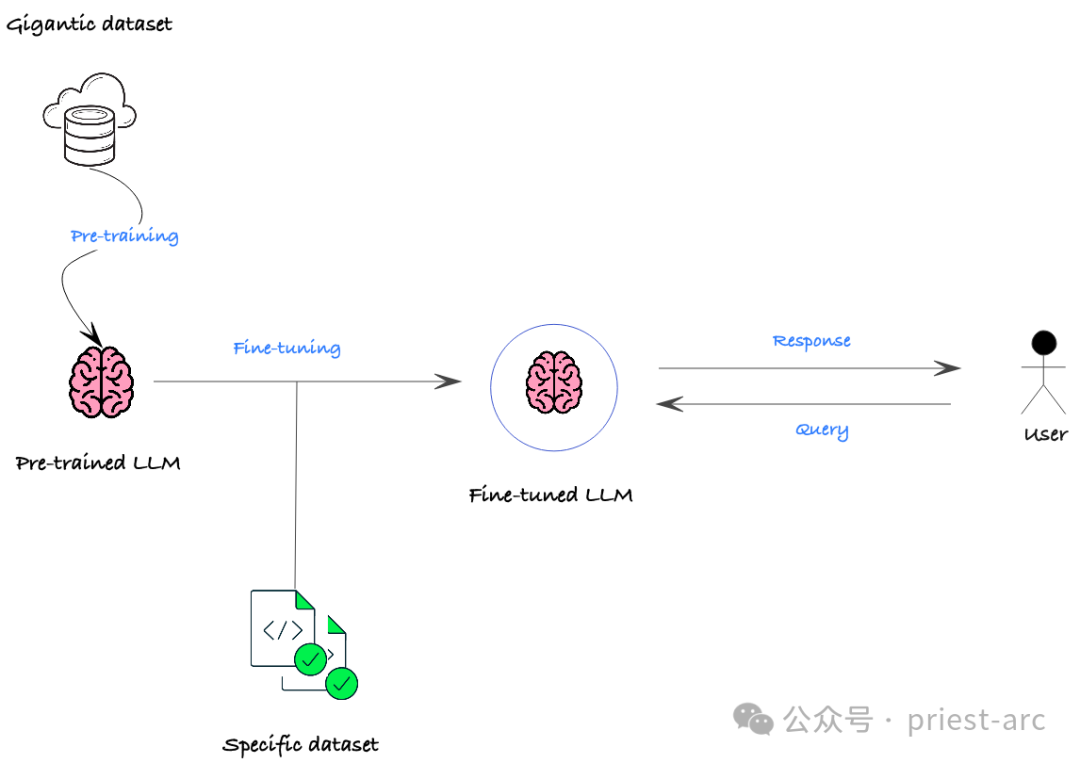
在實際的業務場景中,微調的主要目的通常包括以下幾點:
(1) 領域適配
LLM 通常是在跨領域的通用資料上訓練,但在應用到特定領域時,如金融、醫療、法律等場景,效能可能會大打折扣。透過微調,可以將預訓練模型調整適配到目標領域,使其更好地捕捉特定領域的語言特徵和語義關係,從而提高在該領域下的表現表現。
(2) 任務客製化
即使在同一領域,不同的具體任務也可能有差異化的需求。例如文本分類、問答、命名實體辨識等 NLP 任務,都會對語言理解和生成能力提出不同的要求。透過微調,可以根據下游任務的具體需求,優化模型在特定任務上的表現指標,如準確率、Recall、F1值等。
(3) 效能提升
即使在某個特定任務上,預訓練模型也可能存在準確率、速度等方面的瓶頸。透過微調,我們可以進一步提升模型在該任務上的表現表現。例如,針對推理速度要求很高的即時應用場景,可以對模型進行壓縮最佳化;對於要求更高準確率的關鍵任務,也可以透過微調進一步提升模型的判斷能力。
Fine-Tuning (微調)有哪些收益以及面臨的困境?
通常而言,Fine-Tuning (微調)的主要好處在於能夠有效提升現有預訓練模型在特定應用場景下的效能表現。透過在目標領域或任務上對基礎模型進行持續訓練和參數調整,可以使其更好地捕捉特定場景下的語義特徵和規律,從而顯著提高模型在該領域或任務上的關鍵指標。例如,透過對 Llama 2 模型進行微調,在某些功能上的表現就可以優於 Meta 原始的語言模型實作。
雖然 Fine-Tuning 為 LLM 帶來了顯著的好處,但也有一些缺點需要考慮。那麼,Fine-Tuning (微調)面臨的困境有哪些呢?
挑戰與限制:
- 災難性遺忘:微調可能會導致“災難性遺忘”,即模型忘記在預訓練期間學到的一些常識。如果微調資料過於具體或主要集中在狹窄的領域,則可能會發生這種情況。
- 資料需求:雖然與從頭開始訓練相比,微調所需的資料較少,但對於特定任務仍然需要高品質且相關的資料。數據不足或標記不當可能會導致性能不佳。
- 運算資源:微調過程的運算成本仍然很高,特別是對於複雜模型和大型資料集。對於較小的組織或資源有限的組織來說,這可能是一個障礙。
- 所需的專業知識:微調通常需要機器學習、NLP 和手頭上的特定任務等領域的專業知識。對於那些沒有必要知識的人來說,選擇正確的預訓練模型、配置超參數和評估結果可能會很複雜。
潛在問題:
- 偏差放大:預訓練的模型可以從其訓練資料中繼承偏差。如果微調數據反映了類似的偏差,則微調可能會無意中放大這些偏差。這可能會導致不公平或歧視性的結果。
- 可解釋性挑戰:微調模型比預訓練模型更難解釋。了解模型如何得出結果可能很困難,這會阻礙調試和對模型輸出的信任。
- 安全風險:經過微調的模型可能容易受到對抗性攻擊,其中惡意行為者操縱輸入數據,導致模型產生不正確的輸出。
Fine-Tuning (微調)與其他客製化方法相比如何?
#通常來講,Fine-Tuning 並不是唯一的客製化模型輸出或整合自訂資料的方法。實際上,它可能不適合我們的具體需求和用例,有一些其他的替代方案值得探索和考慮,具體如下:
1. Prompt Engineering(提示工程)
Prompt Engineering 是一種透過在發送給AI 模型的提示中提供詳細的說明或上下文資料來增加獲得所需輸出的可能性的過程。相較於微調,Prompt Engineering 的操作複雜性要低得多,而且可以隨時修改和重新部署提示,而無需對底層模型進行任何更改。
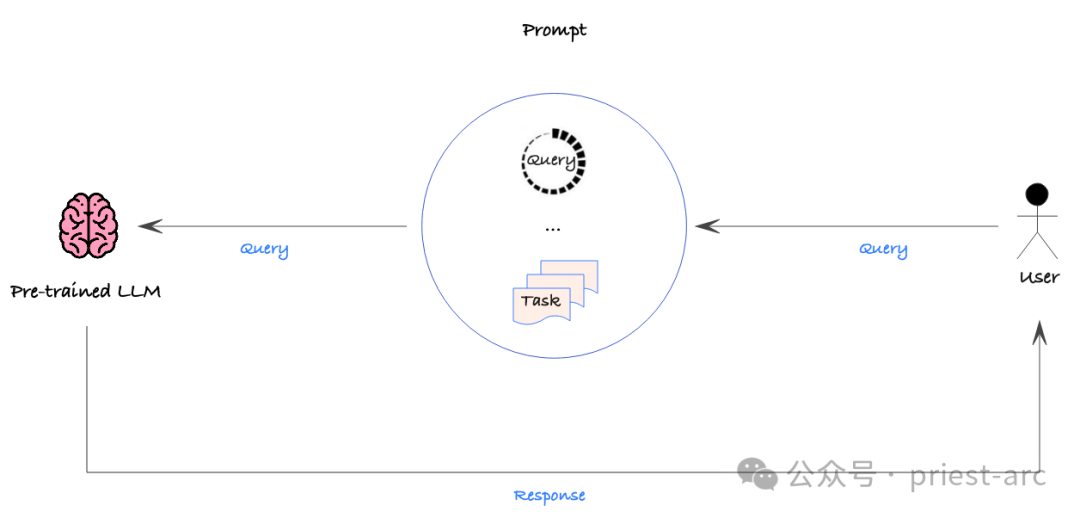
這種策略相對簡單,但仍應採用數據驅動的方法,對各種提示的準確性進行定量評估,以確保獲得所需的性能。透過這種方式,我們可以有系統地最佳化提示,找到最有效的方式來指導模型產生所需的輸出。
不過,Prompt Engineering 並非沒有缺點。首先,它無法直接整合大型資料集,因為提示通常是手動修改和部署的。這意味著在處理大規模資料時,Prompt Engineering 可能會顯得效率較低。
另外,Prompt Engineering 也無法讓模型產生基礎訓練資料中不存在的新行為或功能。這種限制意味著,如果我們需要模型具有全新的能力,單純依靠提示工程可能無法滿足需求,可能需要考慮其他方法,例如微調或從頭訓練模型等。
2. RAG (检索增强生成)
RAG (检索增强生成)是一种有效将大型非结构化数据集(如文档)与 LLM 相结合的方法。它利用语义搜索和向量数据库技术,结合提示机制,使 LLM 能够从丰富的外部信息中获取所需的知识和背景,从而生成更加准确和有见地的输出。
虽然 RAG 本身并不是一种生成新模型功能的机制,但它是将 LLM 与大规模非结构化数据集高效集成的一个极其强大的工具。利用 RAG ,我们可以轻松地为 LLM 提供大量的相关背景信息,增强它们的知识和理解能力,从而显著提高生成性能。
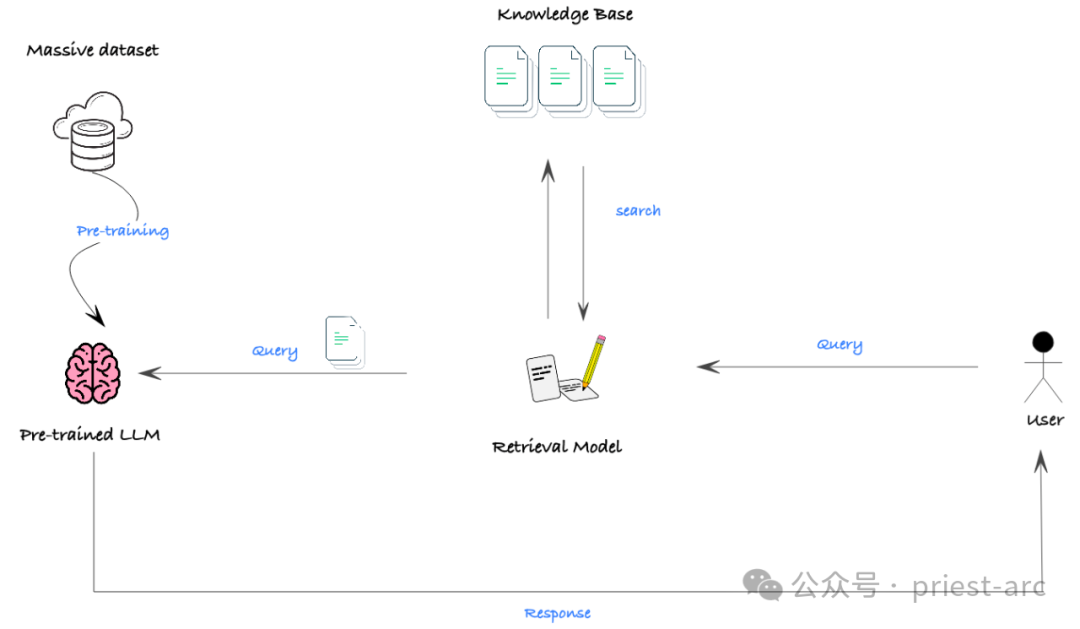
在实际的场景中,RAG 的有效性最大的障碍在于,许多模型的上下文窗口有限,即模型一次性可以处理的最大文本长度受到限制。在某些需要广泛背景知识的情况下,可能会阻碍模型获取足够的信息来实现良好的性能。
不过,随着技术的快速发展,模型的上下文窗口正在快速扩大。甚至一些开源模型已经能够处理多达 32,000 个标记的长文本输入。这意味着 RAG 在未来将拥有更广阔的应用前景,能够为更复杂的任务提供有力支持。
接下来,让我们来了解、对比一下这三种技术在数据隐私方面的具体表现情况,具体可参考如下所示:
(1) Fine-Tuning (微调)
Fine-Tuning (微调)的主要缺点是,训练模型时使用的信息会被编码到模型的参数中。这意味着,即使模型的输出对用户来说是隐私的,底层的训练数据仍可能被泄露。研究表明,恶意攻击者甚至可以通过注入攻击从模型中提取原始训练数据。因此,我们必须假设任何用于训练模型的数据都可能被未来的用户访问到。
(2) Prompt Engineering(提示工程)
相比之下,Prompt Engineering 的数据安全足迹要小得多。因为提示可以针对每个用户进行隔离和定制,不同用户看到的提示中包含的数据可以是不同的。但我们仍需要确保提示中包含的任何数据对于任何有权访问该提示的用户来说都是非敏感的或允许的。
(3) RAG (检索增强生成)
RAG 的安全性取决于其基础检索系统中的数据访问权限控制。我们需要确保底层的矢量数据库和提示模板都配置了适当的隐私和数据控制措施,以防止未经授权的访问。只有这样,RAG 才能真正确保数据隐私。
总的来说,在数据隐私方面,Prompt Engineering 和 RAG 相对于微调来说具有明显的优势。但无论采用哪种方法,我们都必须非常谨慎地管理数据访问和隐私保护,确保用户的敏感信息得到充分的保护。
因此,从某种意义上而言,无论我们最终选择 Fine-Tuning、Prompt Engineering 还是 RAG,采用的方法都应该与组织的战略目标、可用资源、专业技能以及预期的投资回报率等因素保持高度一致。这不仅涉及到纯粹的技术能力,更要考虑这些方法如何与我们的业务战略、时间表、当前工作流程以及市场需求相匹配。
對於 Fine-Tuning 這個選項來說,深入了解其複雜性是做出明智決策的關鍵。 Fine-Tuning 涉及的技術細節和資料準備工作都比較複雜,需要對模型和資料有深入的理解。因此,與擁有豐富微調經驗的合作夥伴進行緊密合作至關重要。這些合作夥伴不僅要具備可靠的技術能力,還要能充分理解我們的業務流程和目標,為我們選擇最合適的客製化技術方案。
同樣地,如果我們選擇使用 Prompt Engineering 或 RAG,也需要仔細評估這些方法是否能夠與我們的業務需求、資源條件以及預期效果相符。只有確保所選的客製化技術能夠真正為我們的組織創造價值,才能最終取得成功。
Reference :
- [1] https://medium.com/@younesh.kc/rag-vs-fine-tuning-in-large-language-models-a -comparison-c765b9e21328
- [2] https://kili-technology.com/large-language-models-llms/the-ultimate-guide-to-fine-tuning-llms-2023
以上是一文讀懂大型語言模型微調技術挑戰與最佳化策略的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 C 中的chrono庫如何使用?
Apr 28, 2025 pm 10:18 PM
C 中的chrono庫如何使用?
Apr 28, 2025 pm 10:18 PM
使用C 中的chrono庫可以讓你更加精確地控制時間和時間間隔,讓我們來探討一下這個庫的魅力所在吧。 C 的chrono庫是標準庫的一部分,它提供了一種現代化的方式來處理時間和時間間隔。對於那些曾經飽受time.h和ctime折磨的程序員來說,chrono無疑是一個福音。它不僅提高了代碼的可讀性和可維護性,還提供了更高的精度和靈活性。讓我們從基礎開始,chrono庫主要包括以下幾個關鍵組件:std::chrono::system_clock:表示系統時鐘,用於獲取當前時間。 std::chron
 如何理解C 中的DMA操作?
Apr 28, 2025 pm 10:09 PM
如何理解C 中的DMA操作?
Apr 28, 2025 pm 10:09 PM
DMA在C 中是指DirectMemoryAccess,直接內存訪問技術,允許硬件設備直接與內存進行數據傳輸,不需要CPU干預。 1)DMA操作高度依賴於硬件設備和驅動程序,實現方式因係統而異。 2)直接訪問內存可能帶來安全風險,需確保代碼的正確性和安全性。 3)DMA可提高性能,但使用不當可能導致系統性能下降。通過實踐和學習,可以掌握DMA的使用技巧,在高速數據傳輸和實時信號處理等場景中發揮其最大效能。
 怎樣在C 中處理高DPI顯示?
Apr 28, 2025 pm 09:57 PM
怎樣在C 中處理高DPI顯示?
Apr 28, 2025 pm 09:57 PM
在C 中處理高DPI顯示可以通過以下步驟實現:1)理解DPI和縮放,使用操作系統API獲取DPI信息並調整圖形輸出;2)處理跨平台兼容性,使用如SDL或Qt的跨平台圖形庫;3)進行性能優化,通過緩存、硬件加速和動態調整細節級別來提升性能;4)解決常見問題,如模糊文本和界面元素過小,通過正確應用DPI縮放來解決。
 C 中的實時操作系統編程是什麼?
Apr 28, 2025 pm 10:15 PM
C 中的實時操作系統編程是什麼?
Apr 28, 2025 pm 10:15 PM
C 在實時操作系統(RTOS)編程中表現出色,提供了高效的執行效率和精確的時間管理。 1)C 通過直接操作硬件資源和高效的內存管理滿足RTOS的需求。 2)利用面向對象特性,C 可以設計靈活的任務調度系統。 3)C 支持高效的中斷處理,但需避免動態內存分配和異常處理以保證實時性。 4)模板編程和內聯函數有助於性能優化。 5)實際應用中,C 可用於實現高效的日誌系統。
 怎樣在C 中測量線程性能?
Apr 28, 2025 pm 10:21 PM
怎樣在C 中測量線程性能?
Apr 28, 2025 pm 10:21 PM
在C 中測量線程性能可以使用標準庫中的計時工具、性能分析工具和自定義計時器。 1.使用庫測量執行時間。 2.使用gprof進行性能分析,步驟包括編譯時添加-pg選項、運行程序生成gmon.out文件、生成性能報告。 3.使用Valgrind的Callgrind模塊進行更詳細的分析,步驟包括運行程序生成callgrind.out文件、使用kcachegrind查看結果。 4.自定義計時器可靈活測量特定代碼段的執行時間。這些方法幫助全面了解線程性能,並優化代碼。
 量化交易所排行榜2025 數字貨幣量化交易APP前十名推薦
Apr 30, 2025 pm 07:24 PM
量化交易所排行榜2025 數字貨幣量化交易APP前十名推薦
Apr 30, 2025 pm 07:24 PM
交易所內置量化工具包括:1. Binance(幣安):提供Binance Futures量化模塊,低手續費,支持AI輔助交易。 2. OKX(歐易):支持多賬戶管理和智能訂單路由,提供機構級風控。獨立量化策略平台有:3. 3Commas:拖拽式策略生成器,適用於多平台對沖套利。 4. Quadency:專業級算法策略庫,支持自定義風險閾值。 5. Pionex:內置16 預設策略,低交易手續費。垂直領域工具包括:6. Cryptohopper:雲端量化平台,支持150 技術指標。 7. Bitsgap:
 給MySQL表添加和刪除字段的操作步驟
Apr 29, 2025 pm 04:15 PM
給MySQL表添加和刪除字段的操作步驟
Apr 29, 2025 pm 04:15 PM
在MySQL中,添加字段使用ALTERTABLEtable_nameADDCOLUMNnew_columnVARCHAR(255)AFTERexisting_column,刪除字段使用ALTERTABLEtable_nameDROPCOLUMNcolumn_to_drop。添加字段時,需指定位置以優化查詢性能和數據結構;刪除字段前需確認操作不可逆;使用在線DDL、備份數據、測試環境和低負載時間段修改表結構是性能優化和最佳實踐。
 C 中的字符串流如何使用?
Apr 28, 2025 pm 09:12 PM
C 中的字符串流如何使用?
Apr 28, 2025 pm 09:12 PM
C 中使用字符串流的主要步驟和注意事項如下:1.創建輸出字符串流並轉換數據,如將整數轉換為字符串。 2.應用於復雜數據結構的序列化,如將vector轉換為字符串。 3.注意性能問題,避免在處理大量數據時頻繁使用字符串流,可考慮使用std::string的append方法。 4.注意內存管理,避免頻繁創建和銷毀字符串流對象,可以重用或使用std::stringstream。
