
洪水是最為普遍的自然災害之一,全球近 15 億人(佔世界總人口的 19%)直面著受洪水威脅的風險。洪水不僅導致巨大的物質損失,每年還造成全球約 500 億美元的經濟損失。
近年來,人類造成的氣候變遷進一步增加了一些地區的洪水頻率。然而,目前的預報方法主要依賴沿河而建的觀測站,其在全球的分佈並不均勻,這就導致未經測量的河流更難預報,其負面影響主要體現在發展中國家。升級預警系統,使這些人群能夠獲得準確、及時的訊息,每年可以挽救數千人的生命。
那麼,如何在全球範圍內進行可靠的洪水預報?人工智慧(AI)模式或許大有可為。
來自 Google Research 洪水預測團隊的 Grey Nearing 和團隊成員已經成功開發了一種人工智慧模型,利用現有的 5680 個測量儀進行訓練。此模型可以準確預測未測量流域在未來 7 天的日徑流,為洪水預警和防範提供了重要的數據支援。 Grey Nearing 指出,這項技術的發展是為了提高對洪水風險的預測能力,以便及時採取必要的措施來減少潛在的災害影響。這項研究成果的成功展示
接著,他們對這個人工智慧模型進行了與全球領先的短期和長期洪水預測軟體——全球洪水預警系統(GloFAS)的比較測試。研究結果表明,該模型在同日預測準確率方面與現有系統相當甚至更高。
此外,模型在預測重現視窗(return window)為五年的極端天氣事件方面表現出與 GloFAS 在預測一年重現視窗事件時相當甚至更高的準確性水平。
相關研究論文以「Global prediction of extreme floods in ungauged watersheds」為題,已發表在權威科學期刊 Nature 上。
研究小組指出,此模型能夠提前警示未測流域內可能發生的小規模和極端洪水事件,且比過去的方法提供了更長的預警時間。這將有助於提高發展中國家地區獲得可靠的洪水預警資訊的機會。
那麼,這個人工智慧模型如何能給出可靠的洪水預報呢?
研究中採用了長短期記憶(LSTM)網路作為人工智慧模型,用於預測河流的流量。這個模型的工作原理類似於人類大腦,能夠透過學習氣象資料序列來預測未來的河流流量。模型分為編碼器和解碼器兩部分,編碼器負責處理輸入數據,解碼器則負責產生預測結果。透過這種方式,模型能夠提供準確且可靠的河流流量預測,為水資源管理和防災工作提供重要的支援。
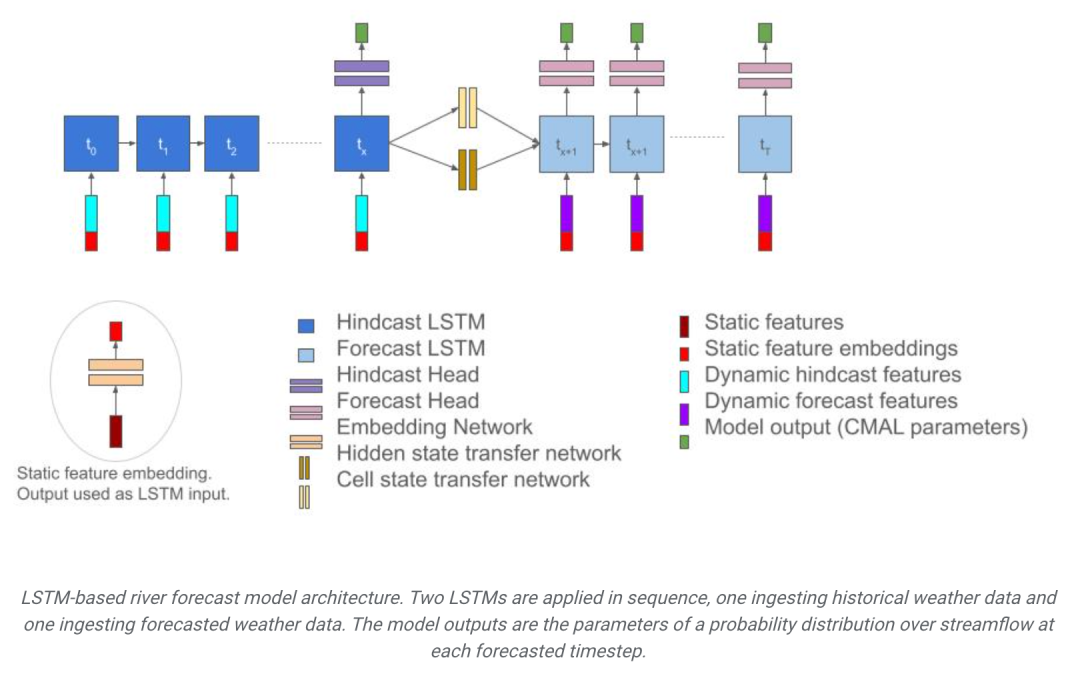
基於 LSTM 的河流預報模型架構。兩個 LSTM 依序應用,一個接收歷史天氣數據,另一個接收預測天氣數據。模型輸出為每個預報時間步的流量機率分佈參數。
首先,編碼器負責從上一段時間內的氣象資料中提取訊息,它從過去的天氣狀況中理解河流流量的變化。它將歷史氣象資料轉化為可供解碼器使用的資訊形式的作用。透過學習氣象資料中的特徵和時間模式,模型對過去氣象情況形成抽象理解,為後續的流量預測提供了關鍵性的輸入。
編碼器則透過接收一系列氣象資料(例如降水量、溫度、輻射等)作為輸入,學習如何擷取這些資料中的關鍵特徵資訊。這些特徵資訊可能包括季節性變化、氣象事件(如暴雨、高溫等)以及它們對河流流量的影響。
同時,編碼器能夠捕捉氣象資料之間的時間依賴關係。這意味著它不僅考慮當下時刻的氣象情況,還考慮了先前一段時間內的氣象變化趨勢。透過對歷史資料的學習,編碼器能夠理解氣象資料的時間序列模式,並將其納入模型中。
在編碼器中,LSTM 網路被用來處理時間序列資料。 LSTM 具有內部記憶單元,可以記住過去的訊息,並根據當前的輸入來更新內部狀態。這使得編碼器能夠在處理長期依賴關係時表現優異,並在建模過程中保留重要的歷史資訊。
最終,編碼器將歷史氣象資料轉化為一個潛在的表示形式,這個表示形式包含了對過去氣象情況的理解和總結。這個表示形式是編碼器的輸出,並傳遞給解碼器,用於未來流量的預測。
然後,解碼器部分使用這些資訊來預測未來幾天的河流流量。它考慮了目前的氣象預報,以及過去的天氣對未來流量的影響。這樣,就可以得到未來一週的流量預測。

解碼器在模型中負責將歷史氣象資訊和未來預測結合起來,產生對未來河流流量的預測,並輸出相應的流量機率分佈。
解碼器首先接收來自編碼器的潛在表示形式,這個表示形式包含了歷史氣象資料的抽象理解。解碼器利用這些資訊來理解過去的氣象條件對河川流量的影響,並建立起歷史資料與未來預測之間的連結。
解碼器同時接收未來的氣象預測資料作為輸入。這些預測數據通常包括了未來幾天的降水量、溫度等氣象指標。解碼器將歷史資訊和未來預測結合起來,透過學習它們之間的關係來預測未來的河流流量。
在了解歷史氣象條件和未來預測之後,解碼器透過一個獨立的 LSTM 網路來產生對未來河流流量的預測。這個網路可以理解為一個時間序列的生成器,根據過去的資訊和未來的預測來產生流量序列。
解碼器不僅預測未來的河川流量值,還輸出一個機率分佈。具體來說,模型使用一個單邊拉普拉斯分佈來描述流量的不確定性,預測每個時間步的流量值時,輸出一個單邊拉普拉斯分佈的參數,而不是一個確定的值。這使得模型能夠考慮到流量預測的不確定性,為決策提供了更多的資訊。
最終的流量預測結果是透過整合多個解碼器模型的輸出而得到的。模型使用了三個獨立訓練的解碼器 LSTM 網絡,然後將它們的預測結果取中位數,從而減少預測的變異數並提高預測的穩定性。
研究人員收集了大量的氣象數據和河流流量數據,來訓練這個模型。這些數據來自於不同的數據來源,包括氣象預報、歷史記錄和地理資訊。透過將數據標準化處理,模型得以正確理解它們。
然後,資料分成兩種:訓練集和測試集。訓練集用於訓練模型,而測試集則用於評估模型的表現。研究人員使用了一種「交叉驗證」的方法,以確保模型在不同的時間和地點都能夠有效地工作。
最後,研究團隊評估了模型的效能,並與現有的流量預測模型進行了比較。
研究團隊採用了常見的誤差指標來量化模型預測值與實際觀測值之間的差異。由於模型預測的不只是未來流量的具體數值,而且還給出了流量預測的不確定性,因此他們使用了機率積分變換(PIT)圖來評估預測分佈的準確性。
研究團隊也透過與其他流量預測模型的對比來評估所提出模型的效能。這包括了傳統的實體模型和其他機器學習模型。透過比較不同模型的誤差指標,可以直觀地展示所提模型在準確性和可靠性上的優勢。
另外,研究團隊也採用了特定的流域或河流作為案例研究,應用模型於實際情境中,並詳細分析模型在不同季節、不同氣候條件下的預測性能。這有助於評估模型在實際應用上的可行性和穩定性。
除了量化指標,研究團隊也對模型預測的不確定性進行了深入分析。這包括評估不同來源的不確定性(如輸入資料的不確定性、模型結構的不確定性等)對預測結果的影響,以及模型如何在存在不確定性的情況下仍然提供有用的預測。
結果顯示,模型展現了較高的精確度和召回率,尤其是對於短期報酬週期的事件。這意味著模型能夠準確地識別出洪水事件,並且錯過的事件較少。
結合精確度和召回率,模型在不同回報週期的事件上獲得了較高的 F1 score,顯示了其在準確度和全面性之間取得了良好的平衡。
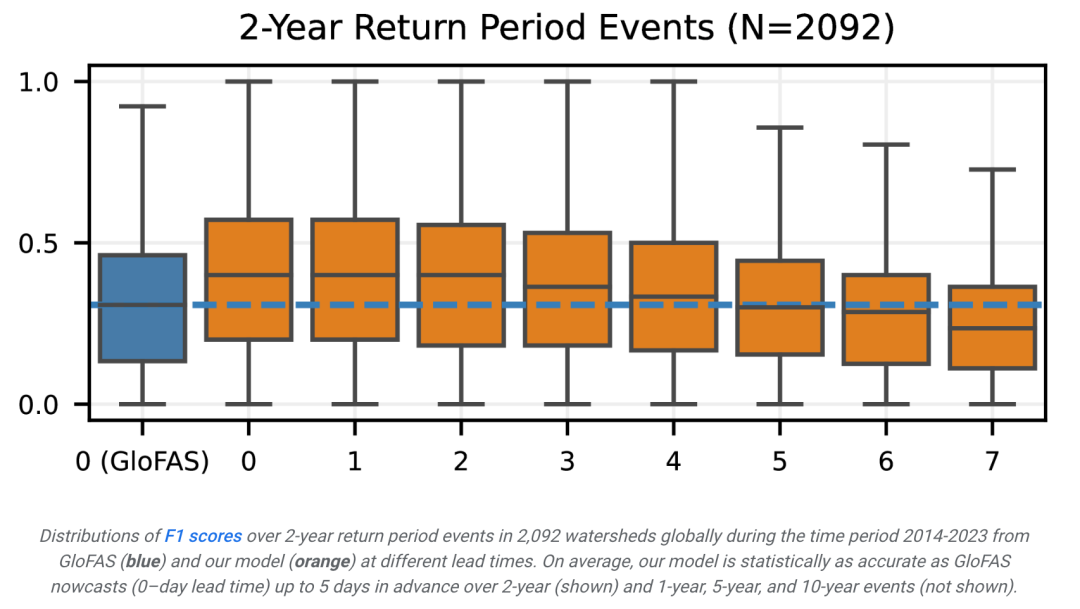
此外,通过双侧 Wilcoxon 符号秩检验,模型的预测结果在统计上显著优于基准模型。这证明了模型在洪水预测方面的有效性。
Cohen's d 指标显示,模型性能改进的效果是显著的,这进一步验证了模型相对于传统方法的优势。
在 Nash–Sutcliffe 效率和 Kling-Gupta 效率等水文指标上,模型同样显示了良好的预测精度和对水文过程变化的敏感性。
然而,该研究也存在一些局限性。
例如,实验采用的样本可能较小,限制了研究结果的普遍适用性和统计功效。研究所用的数据集的多样性存在不足,这可能影响模型的泛化能力。采用的模型复杂度较高,可能导致计算成本增加并限制了其可解释性和便捷性。
另外,研究聚焦于特定任务或领域,可能限制了方法的广泛应用;这个方法缺乏长期影响的评估,使得对模型随时间变化的表现理解不足,评估标准可能无法全面反映模型性能;且对现有技术的改进程度可能相对有限。
对此,研究团队表示,未来的工作需要进一步将洪水预报的覆盖范围扩大到全球更多地点,以及其他类型的洪水相关事件和灾害,包括山洪和城市洪水。人工智能技术也将继续发挥关键作用,帮助推动科学研究,促进气候行动。
以上是Nature重磅:AI擊敗最先進全球洪水預警系統,提前7天預測河川洪水,每年挽救數千人生命的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















