

大佬出走後首個發布! Stability官宣程式碼模型Stable Code Instruct 3B

大佬出走後,第一個模型來了!
就在今天,Stability AI官宣了新的程式碼模型Stable Code Instruct 3B。
 圖片
圖片
Stability是非常重要的,執行長離職對Stable Diffusion造成了一些困擾,投資公司出了點故障,自己的薪水也可能有問題了。
然而,樓外風雨飄搖,實驗室裡巋然不動,研究該做做,討論該發發,模型該調調,大模型各領域的戰爭是一個沒落下。
不只是鋪開攤子搞全面戰爭,每項研究也都在不斷前進,例如今天的Stable Code Instruct 3B就是在之前的Stable Code 3B的基礎上做了指令調優。
 圖片
圖片
論文地址:https://static1.squarespace.com/static/6213c340453c3f502425776e/t/6601c5713150412ed /Stable_Code_TechReport_release.pdf
透過自然語言提示,Stable Code Instruct 3B可以處理各種任務,例如程式碼產生、數學和其他與軟體開發相關的查詢。
 圖片
圖片
同階無敵,越級強殺
Stable Code Instruct 3B在同等參數量的模型中,做到了目前的SOTA,甚至優於比自己大兩倍多的CodeLlama 7B Instruct等模型,並且在軟體工程相關任務中的表現與StarChat 15B相當。
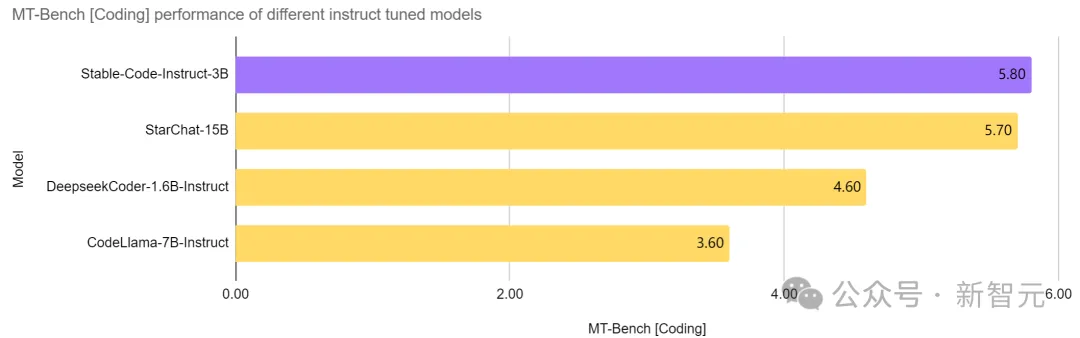 圖片
圖片
從上圖可以看出,與Codellama 7B Instruct和DeepSeek-Coder Instruct 1.3B等領先模型相比,Stable Code Instruct 3B在一系列程式設計任務中表現優異。
測試表明,Stable Code Instruct 3B在程式碼完成準確性、對自然語言指令的理解、以及跨不同程式語言的多功能性方面,都能夠打平甚至超越競爭對手。
 圖片
圖片
Stable Code Instruct 3B根據Stack Overflow 2023開發者調查的結果,將訓練專注於Python、Javascript、 Java、C、C 和Go等程式語言。
上圖使用Multi-PL基準測試,比較了三個模型以各種程式語言產生輸出的強度。可以發現Stable Code Instruct 3B在所有語言中都明顯優於CodeLlama,且參數量還少了一半以上。
除了上述的熱門程式語言,Stable Code Instruct 3B還包括對其他語言(如SQL、PHP和Rust)的訓練,並且即使在沒有經過訓練的語言(如Lua)中,也能提供強大的測試性能。
Stable Code Instruct 3B不僅精通程式碼生成,還精通FIM(程式碼中間填充)任務、資料庫查詢、程式碼翻譯、解釋和創建。
透過指令調優,模型能夠理解細微的指令並採取行動,促進了除了簡單程式碼完成之外的廣泛編碼任務,例如數學理解、邏輯推理和處理軟體開發的複雜技術。
 圖片
圖片
模式下載:https://huggingface.co/stabilityai/stable-code-instruct-3b
Stable Code Instruct 3B現在可以透過Stability AI會員資格,用於商業目的。對於非商業用途,可以在Hugging Face上下載模型重量和程式碼。
Technical details
 Pictures
Pictures
Model architecture
Stable Code is built on Stable LM 3B and is a decoder-only Transformer structure with a design similar to LLaMA. The following table is some key structural information:
 Picture
Picture
##The main differences from LLaMA include:
Positional embedding: Use rotated positional embedding in the first 25% of the header embedding to improve subsequent throughput.
Regularization: Use LayerNorm with learning bias term instead of RMSNorm.
Bias terms: All bias terms in the feedforward network and multi-head self-attention layer are deleted, except for KQV.
Uses the same tokenizer (BPE) as the Stable LM 3B model, with a size of 50,257; in addition, special markers of StarCoder are also referenced, including indicating file name, storage Library stars, fill-in-the-middle (FIM), etc.
For long context training, special markers are used to indicate when two concatenated files belong to the same repository.
Training process
Training data
Pre-training data set A variety of publicly accessible large-scale data sources are collected, including code repositories, technical documentation (such as readthedocs), mathematics-focused texts, and extensive web datasets.
The main goal of the initial pre-training phase is to learn rich internal representations to significantly improve the model's ability in mathematical understanding, logical reasoning, and processing complex technical texts related to software development.
Additionally, the training data includes a general text dataset to provide the model with broader language knowledge and context, ultimately enabling the model to handle a wider range of queries and tasks in a conversational manner.
The following table shows the data sources, categories and sampling weights of the pre-training corpus, where the ratio of code and natural language data is 80:20.
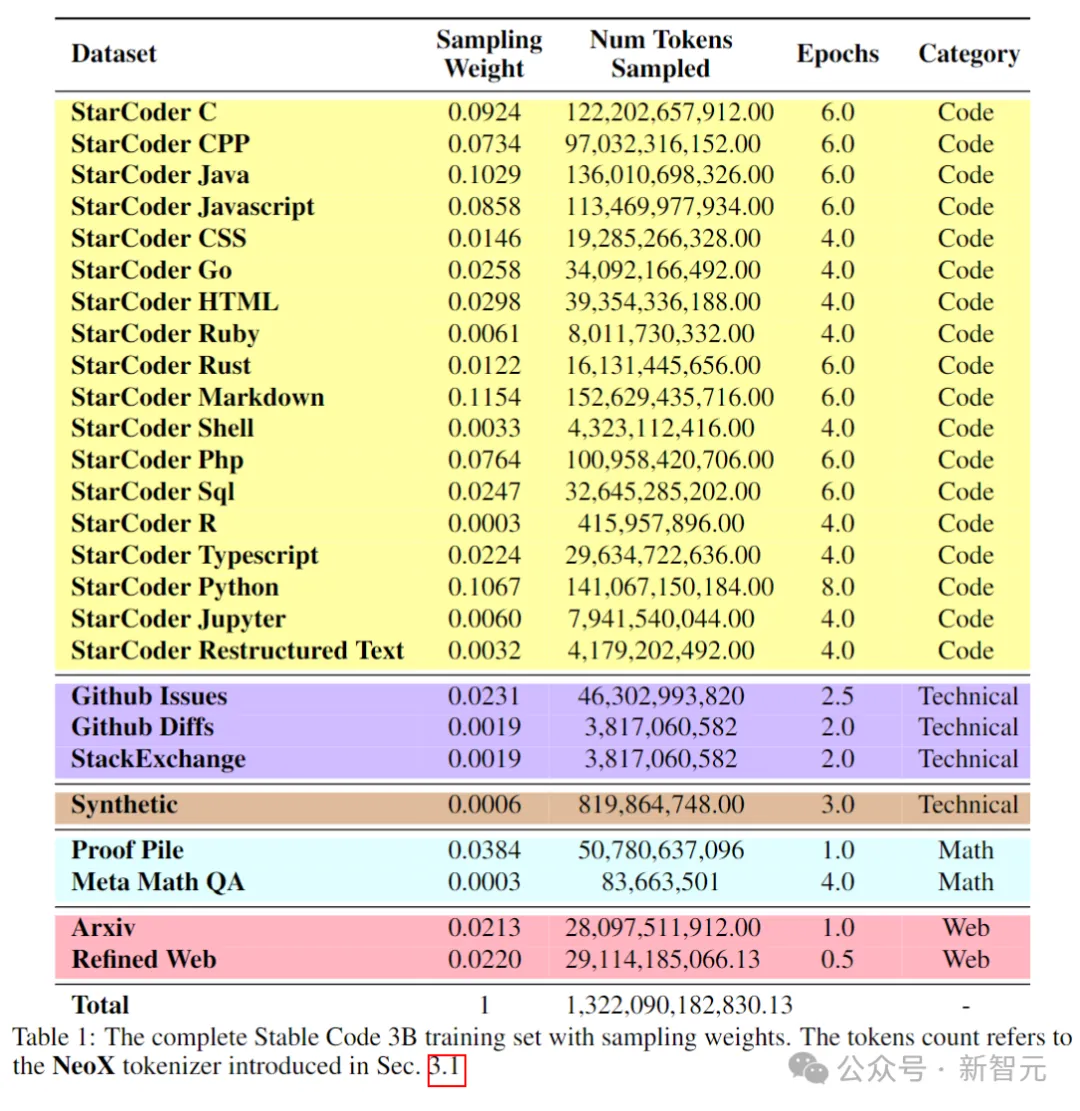 Picture
Picture
In addition, the researchers also introduced a small synthetic dataset, the data was synthesized from the seed prompts of CodeAlpaca dataset, Contains 174,000 tips.
And followed the WizardLM method, gradually increasing the complexity of the given seed prompts, and obtained an additional 100,000 prompts.
The authors believe that introducing this synthetic data early in the pre-training stage helps the model respond better to natural language text.
Long context dataset
Since multiple files in a repository often depend on each other, the context length is important for encoding Models are important.
The researchers estimated the median and average number of tokens in the software repository to be 12k and 18k respectively, so 16,384 was chosen as the context length.
The next step was to create a long context dataset. The researchers took some files written in popular languages in the repository and combined them together, inserting between each file. A special tag to maintain separation while preserving content flow.
To circumvent any potential bias that might arise from the fixed order of the files, the authors employed a randomization strategy. For each repository, two different sequences of connection files are generated.
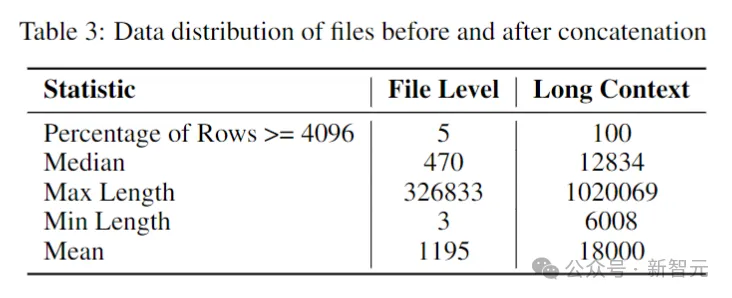 Picture
Picture
Phase-based training
Stable Code uses 32 Amazon P4d instances for training, containing 256 NVIDIA A100 (40GB HBM2) GPUs, and uses ZeRO for distributed optimization.
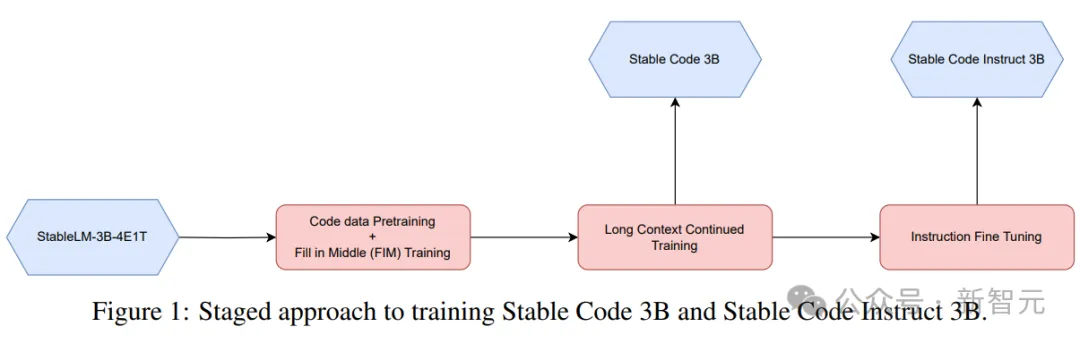 Picture
Picture
A phased training method is used here, as shown in the picture above.
Training follows standard autoregressive sequence modeling to predict the next token. The model is initialized using the checkpoint of Stable LM 3B. The context length of the first stage of training is 4096, and then continuous pre-training is performed.
Training is performed with BFloat16 mixed precision, and FP32 is used for all-reduce. AdamW optimizer settings are: β1=0.9, β2=0.95, ε=1e−6, λ (weight decay)=0.1. Start with learning rate = 3.2e-4, set the minimum learning rate to 3.2e-5, and use cosine decay.
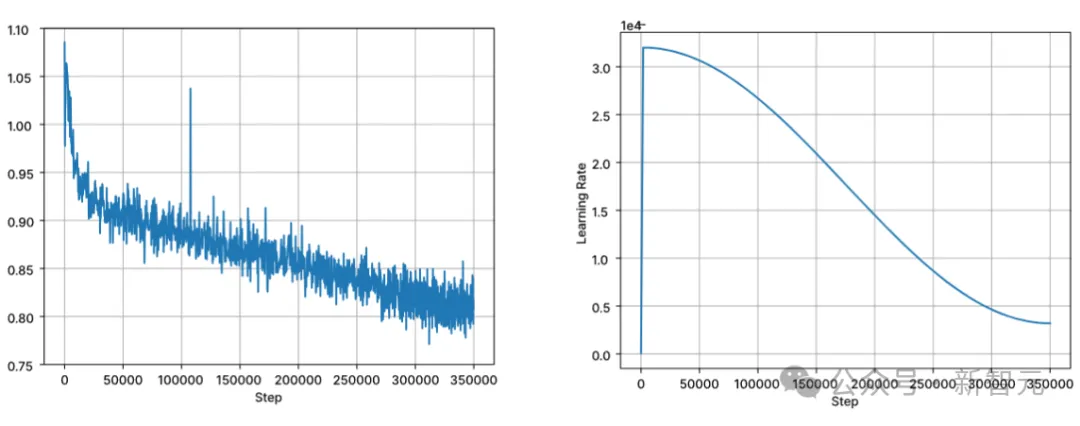 Picture
Picture
One of the core assumptions of natural language model training is the causal order from left to right, but for code Say, this assumption does not always hold (e.g., function calls and function declarations can be in any order for many functions).
To solve this problem, researchers used FIM (fill-in-the-middle). Randomly split the document into three segments: prefix, middle, and suffix, then move the middle segment to the end of the document. After rearrangement, the same autoregressive training process is followed.
Instruction fine-tuning
After pre-training, the author further improves the model’s dialogue skills through a fine-tuning stage, which includes supervised fine-tuning (SFT) and Direct Preference Optimization (DPO).
First perform SFT fine-tuning using publicly available datasets on Hugging Face: including OpenHermes, Code Feedback, CodeAlpaca.
After performing exact match deduplication, the three datasets provide a total of approximately 500,000 training samples.
Use the cosine learning rate scheduler to control the training process and set the global batch size to 512 to pack the input into sequences of length no longer than 4096.
After SFT, the DPO phase begins, using data from UltraFeedback to curate a dataset containing approximately 7,000 samples. In addition, in order to improve the security of the model, the author also included the Helpful and Harmless RLFH dataset.
The researchers adopted RMSProp as the optimization algorithm and increased the learning rate to a peak of 5e-7 in the initial stage of DPO training.
Performance Test
The following compares the performance of the model on the code completion task, using the Multi-PL benchmark to evaluate the model.
Stable Code Base
The following table shows the size of 3B parameters and below on Multi-PL Performance of different code models.
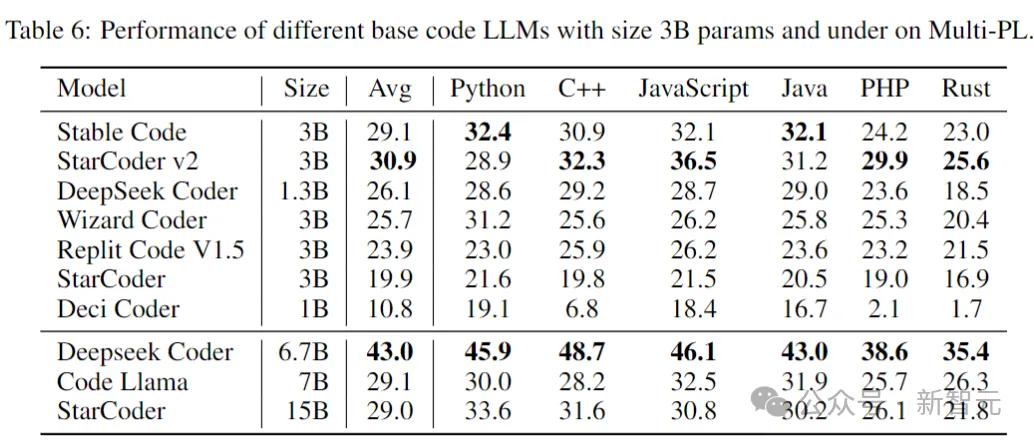 Picture
Picture
Although the parameters of Stable Code are less than 40% and 20% of those of Code Llama and StarCoder 15B, respectively, The model's average performance across programming languages is on par with them.
Stable Code Instruct
The following table evaluates the instructs of several models in the Multi-PL benchmark test Fine-tuned version.
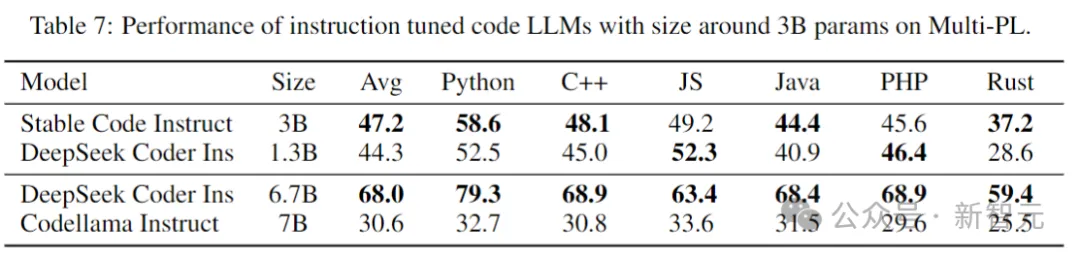 Picture
Picture
SQL Performance
Code language An important application of the model is database query tasks. In this area, the performance of Stable Code Instruct is compared with other popular instruction-tuned models, and models trained specifically for SQL. Benchmarks created here using Defog AI.
 Picture
Picture
Inference performance
Table below The throughput and power consumption when running Stable Code on consumer-grade devices and corresponding system environments are given.
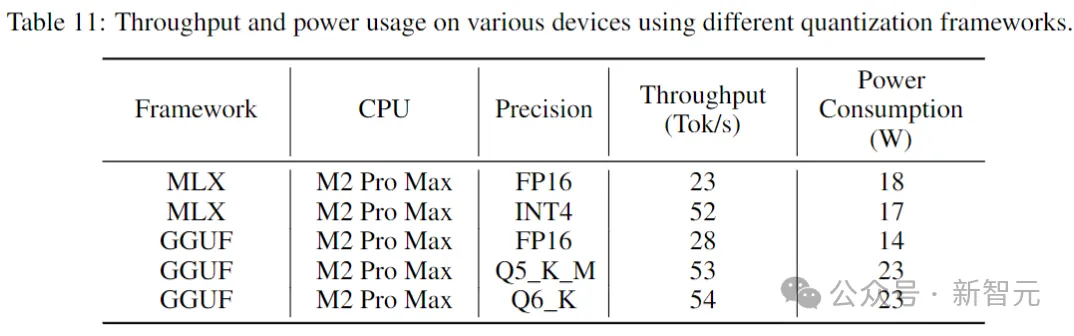 Picture
Picture
The results show that when using lower precision, the throughput increases by nearly two times. However, it is important to note that implementing lower precision quantization may result in some (potentially large) degradation in model performance.
Reference:https://www.php.cn/link/8cb3522da182ff9ea5925bbd8975b203
以上是大佬出走後首個發布! Stability官宣程式碼模型Stable Code Instruct 3B的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap 圖片居中方法多樣,不一定要用 Flexbox。如果僅需水平居中,text-center 類即可;若需垂直或多元素居中,Flexbox 或 Grid 更合適。 Flexbox 兼容性較差且可能增加複雜度,Grid 則更強大且學習成本較高。選擇方法時應權衡利弊,並根據需求和偏好選擇最適合的方法。
 H5頁面製作是前端開發嗎
Apr 05, 2025 pm 11:42 PM
H5頁面製作是前端開發嗎
Apr 05, 2025 pm 11:42 PM
是的,H5頁面製作是前端開發的重要實現方式,涉及HTML、CSS和JavaScript等核心技術。開發者通過巧妙結合這些技術,例如使用<canvas>標籤繪製圖形或使用JavaScript控制交互行為,構建出動態且功能強大的H5頁面。
 如何通過JavaScript或CSS控制瀏覽器打印設置中的頁首和頁尾?
Apr 05, 2025 pm 10:39 PM
如何通過JavaScript或CSS控制瀏覽器打印設置中的頁首和頁尾?
Apr 05, 2025 pm 10:39 PM
如何使用JavaScript或CSS控制瀏覽器打印設置中的頁首和頁尾在瀏覽器的打印設置中,有一個選項可以控制是否顯�...
 wordpress文章列表怎麼調
Apr 20, 2025 am 10:48 AM
wordpress文章列表怎麼調
Apr 20, 2025 am 10:48 AM
有四種方法可以調整 WordPress 文章列表:使用主題選項、使用插件(如 Post Types Order、WP Post List、Boxy Stuff)、使用代碼(在 functions.php 文件中添加設置)或直接修改 WordPress 數據庫。
 如何通過CSS自定義resize符號並使其與背景色統一?
Apr 05, 2025 pm 02:30 PM
如何通過CSS自定義resize符號並使其與背景色統一?
Apr 05, 2025 pm 02:30 PM
CSS自定義resize符號的方法與背景色統一在日常開發中,我們經常會遇到需要自定義用戶界面細節的情況,比如調...
 Bootstrap如何讓圖片在容器中居中
Apr 07, 2025 am 09:12 AM
Bootstrap如何讓圖片在容器中居中
Apr 07, 2025 am 09:12 AM
綜述:使用 Bootstrap 居中圖片有多種方法。基本方法:使用 mx-auto 類水平居中。使用 img-fluid 類自適應父容器。使用 d-block 類將圖片設置為塊級元素(垂直居中)。高級方法:Flexbox 佈局:使用 justify-content-center 和 align-items-center 屬性。 Grid 佈局:使用 place-items: center 屬性。最佳實踐:避免不必要的嵌套和样式。選擇適合項目的最佳方法。注重代碼的可維護性,避免犧牲代碼質量來追求炫技


