

DeepMind終結大模型幻覺?標註事實比人類可靠、還便宜20倍,全開源

大模型的幻覺終於要終結了?
今日,社群媒體平台Reddit上的一則貼文引起網友熱議。貼文討論的是GoogleDeepMind昨日提交的一篇論文《Long-form factuality in large language models(大語言模型的長篇事實性)》,文中提出的方法和結果讓人得出大語言模型幻覺不再是問題了。

我們知道,大語言模型在回應開放式主題的fact-seeking(事實尋求)提問時,通常會產生包含事實錯誤的內容。 DeepMind 針對這一現象進行了一些探索性研究。
為了對一個模型在開放域的長篇事實性進行基準測試,研究者使用GPT-4 產生LongFact,它是一個包含38個主題、數千個問題的提示集。然後他們提出使用搜尋增強事實評估器(SAFE)來將 LLM 智能體用作長篇事實性的自動評估器。 SAFE 的目的是提高事實可信度評估器的準確性。
關於SAFE,使用LLM可以更準確地解釋每個實例的準確性。這裡多步驟推理過程包括將搜尋查詢傳送到Google搜尋並確定搜尋結果是否支援某個實例。

論文網址:https://arxiv.org/pdf/2403.18802.pdf
GitHub網址:https://github.com/google-deepmind/long-form-factuality
此外,研究者提出將F1 分數(F1@K)擴展為長篇實踐性的聚合指標。他們平衡了回應中支援的實際的百分比(精度)和所提供事實相對於代表用戶首選回應長度的超參數的百分比(召回率)。
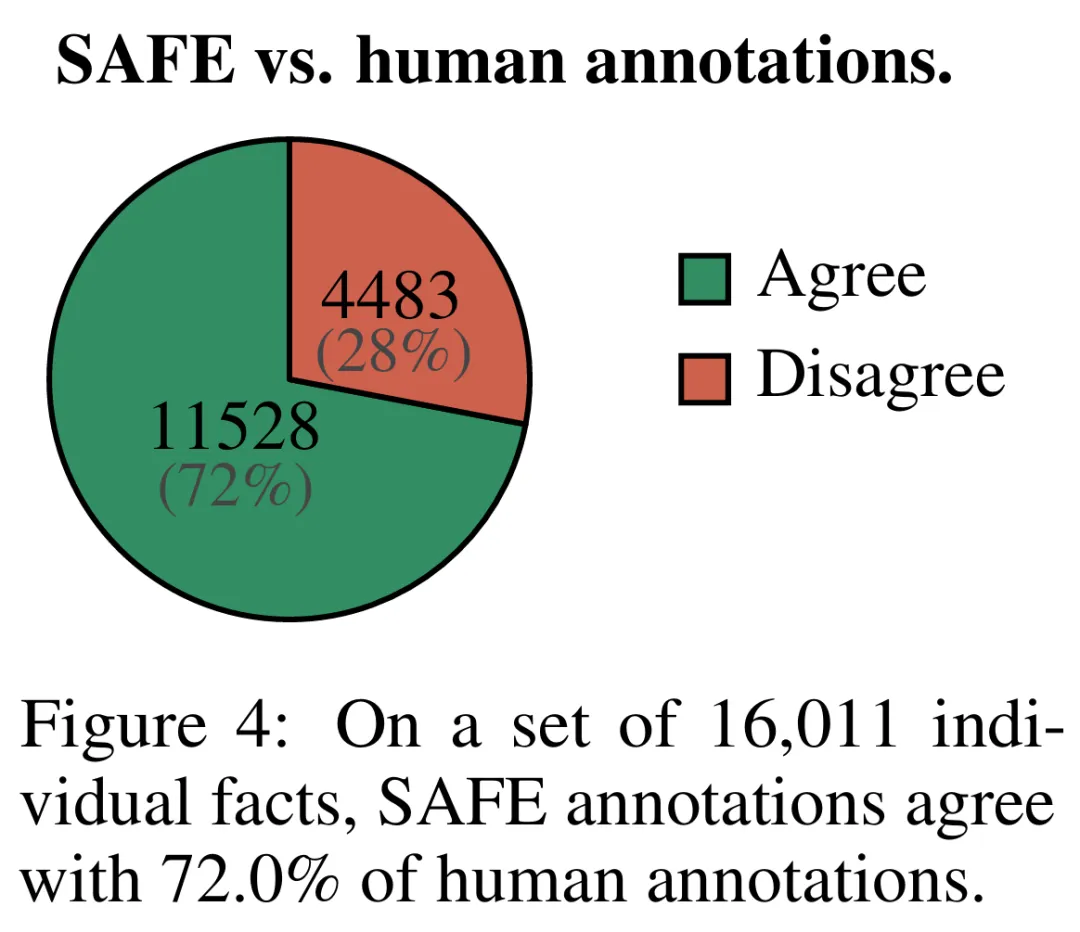
實證結果表明,LLM 智能體可以實現超越人類的評級表現。在一組約 16k 個單獨的事實上,SAFE 在 72% 的情況下與人類註釋者一致,並且在 100 個分歧案例的隨機子集上,SAFE 的贏率為 76%。同時,SAFE 的成本比人類註釋者便宜 20 倍以上。
研究者也使用LongFact,對四個大模型系列(Gemini、GPT、Claude 和PaLM-2)的13 種流行的語言模型進行了基準測試,結果發現較大的語言模型通常可以實現更好的長篇事實性。
論文作者之一、Google研究科學家Quoc V. Le 表示,這篇對長篇事實性進行評估和基準測試的新工作提出了一個新資料集、 一種新評估方法以及一種兼顧精確度和召回率的聚合指標。同時所有資料和程式碼將開源以供未來工作使用。
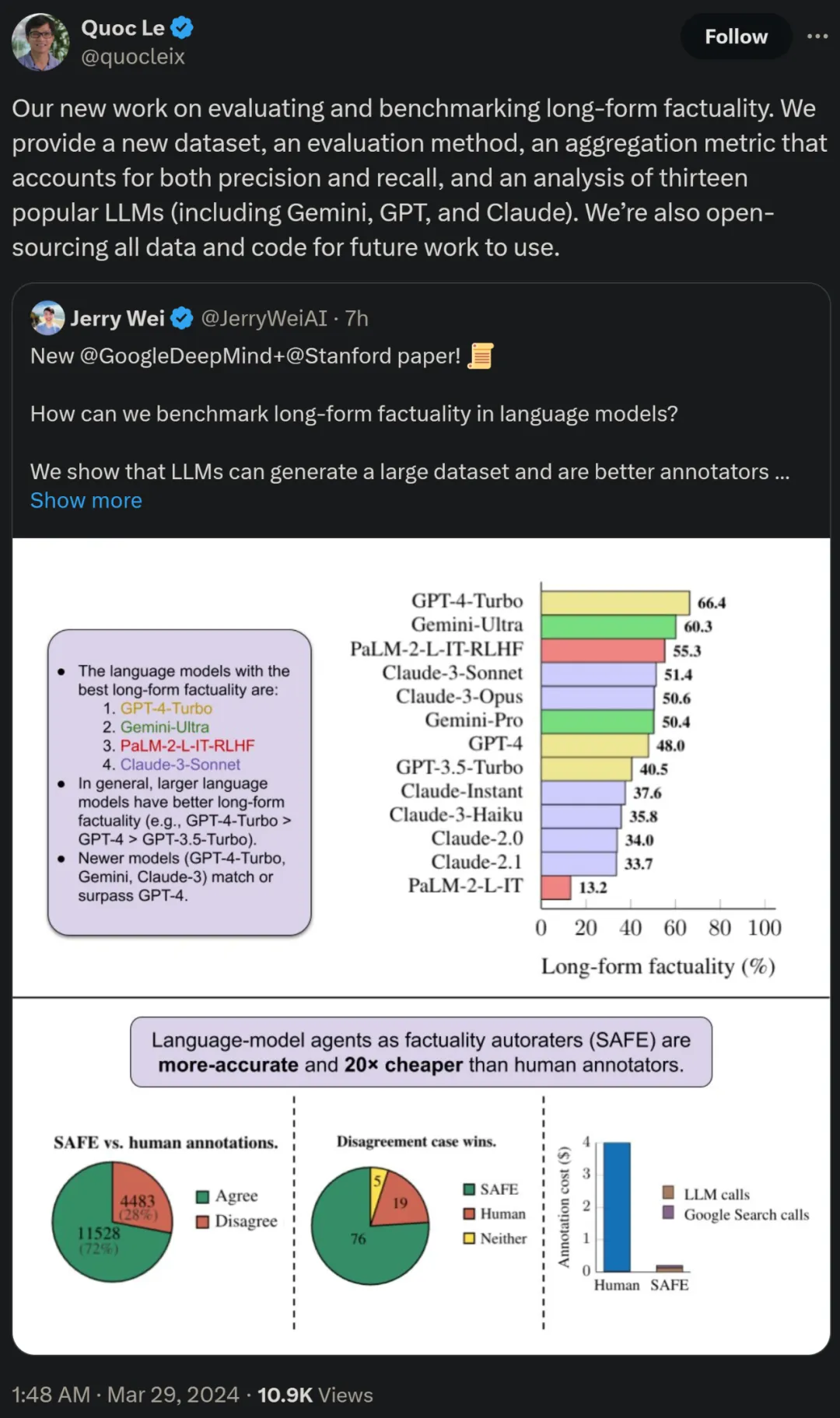
方法概覽
#LONGFACT:使用LLM 產生長篇事實性的多主題基準
首先來看使用GPT-4 產生的LongFact 提示集,包含了2280 個事實尋求提示,這些提示要求跨38 個手動選擇主題的長篇回應。研究者表示,LongFact 是第一個用於評估各領域長篇事實性的提示集。
LongFact 包含兩個任務:LongFact-Concepts 和 LongFact-Objects,根據問題是否詢問概念或物件來區分。研究者為每個主題產生 30 個獨特的提示,每個任務各有 1140 個提示。

SAFE:LLM 智能體作為事實性自動評分者
研究者提出了搜尋增強事實評估器(SAFE),它的運作原理如下所示:
a)將長篇的回應拆分為單獨的獨立事實;
b)確定每個單獨的事實是否與回答上下文中的提示相關;
c) Для каждого релевантного факта итеративно введите поисковый запрос Google в многоэтапном процессе и оцените, подтверждают ли результаты поиска этот факт.
Они считают, что ключевым нововведением SAFE является использование языковых моделей в качестве агентов для создания многоэтапных поисковых запросов Google и тщательного анализа того, подтверждают ли результаты поиска факты. На рисунке 3 ниже показан пример цепочки рассуждений.
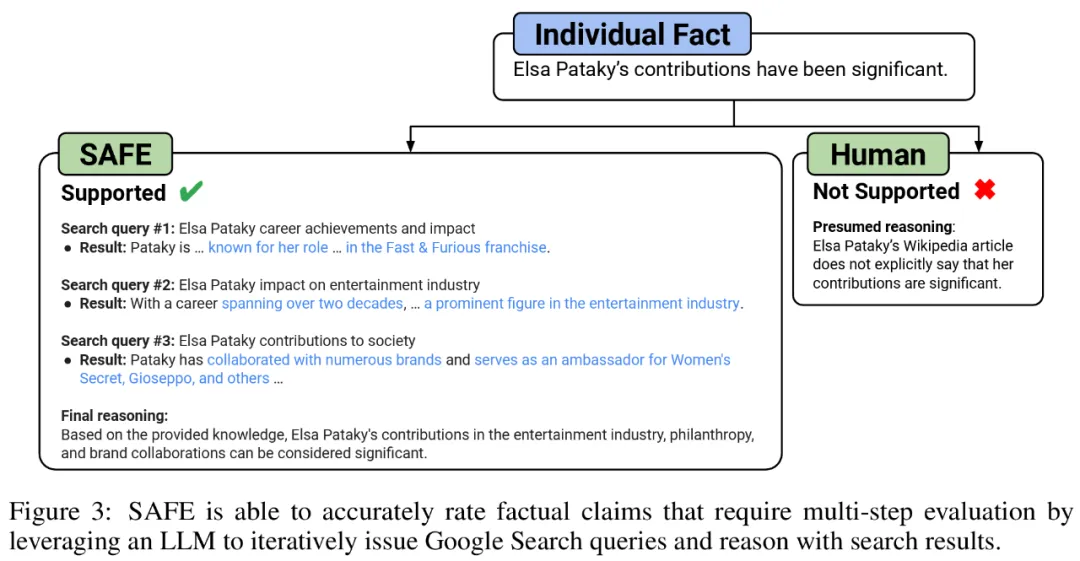
Чтобы разделить длинный ответ на отдельные независимые факты, исследователи сначала предложили языковой модели разделить каждое предложение в длинном ответе на отдельные факты, а затем измените каждый отдельный факт, чтобы он был независимым, поручив модели заменить неоднозначные ссылки (например, местоимения) правильными объектами, на которые они ссылаются в контексте ответа.
Чтобы оценить каждый независимый факт, они использовали языковую модель, чтобы определить, имеет ли этот факт отношение к подсказке, на которую был дан ответ в контексте ответа, а затем использовали многоэтапный метод для ранжирования. каждому оставшемуся Соответствующие факты оцениваются как «подтвержденные» или «не подтвержденные». Подробности показаны на рисунке 1 ниже.
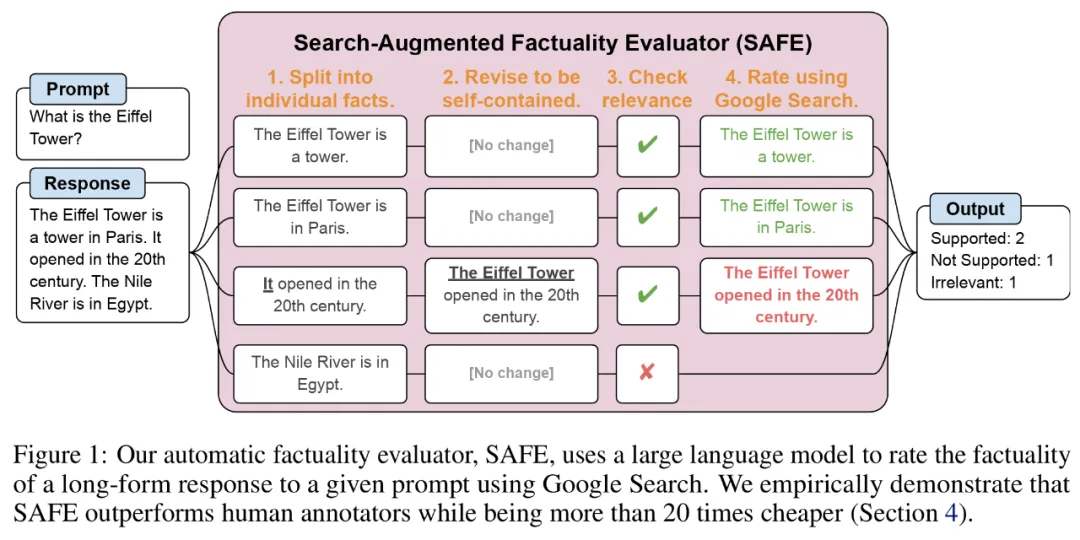
На каждом этапе модель генерирует поисковый запрос на основе фактов, подлежащих оценке, и ранее полученных результатов поиска. После определенного количества шагов модель выполняет вывод, чтобы определить, подтверждают ли результаты поиска этот факт, как показано на рисунке 3 выше. После того, как все факты оценены, выходными показателями SAFE для данной пары «быстрый ответ» являются количество «подтверждающих» фактов, количество «нерелевантных» фактов и количество «неподтвержденных» фактов.
Результаты экспериментов
#Агент LLM становится лучшим аннотатором фактов, чем люди
Чтобы количественно оценить качество аннотаций, полученных с помощью SAFE, исследователи использовали аннотации, полученные вручную. Данные содержат 496 пар «подсказка-ответ», в которых ответы были вручную разбиты на отдельные факты (всего 16 011 отдельных фактов), и каждый отдельный факт был вручную помечен как поддерживаемый, нерелевантный или неподдерживаемый.
Они напрямую сравнили аннотации SAFE с аннотациями человека для каждого факта и обнаружили, что SAFE согласуется с людьми в 72,0% отдельных фактов, как показано на рисунке 4 ниже. Это показывает, что SAFE достигает эффективности человеческого уровня по большинству отдельных фактов. Затем была проверена подгруппа из 100 отдельных фактов из случайных интервью, для которых аннотации SAFE не соответствовали аннотациям оценщиков-людей.
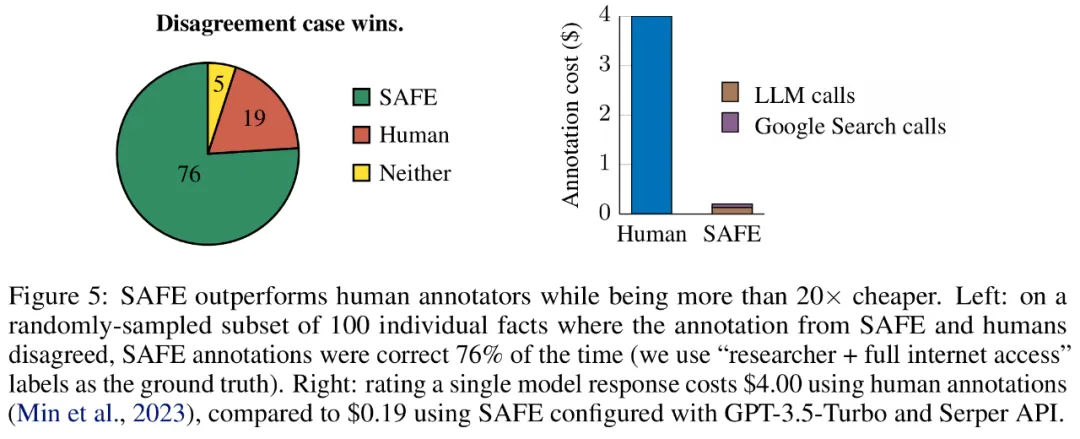
Исследователи вручную повторно аннотировали каждый факт (открывая доступ к поиску Google, а не только к Википедии, для более подробной аннотации) и использовали эти метки как основная истина. Они обнаружили, что в этих случаях разногласий аннотации SAFE были правильными в 76% случаев, в то время как аннотации, написанные человеком, были правильными только в 19% случаев, что представляет собой коэффициент выигрыша SAFE 4 к 1. Подробности показаны на рисунке 5 ниже.
Здесь цены на два аннотационных плана заслуживают внимания. Стоимость оценки ответа одной модели с использованием человеческих аннотаций составляет 4 доллара США, а стоимость SAFE с использованием GPT-3.5-Turbo и Serper API — всего 0,19 доллара США.
#Бенчмарки серий Gemini, GPT, Claude и PaLM-2
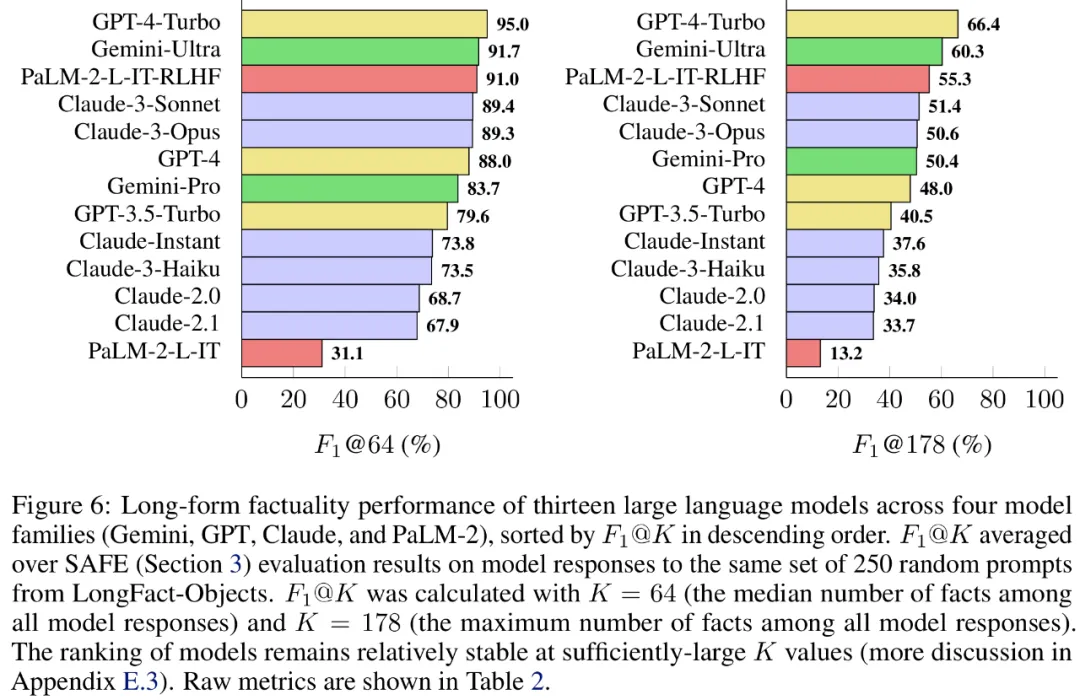
Наконец Исследователи провели обширное тестирование LongFact на 13 крупных языковых моделях из четырех серий моделей (Gemini, GPT, Claude и PaLM-2), представленных в таблице 1 ниже.
В частности, они оценивали каждую модель, используя одно и то же случайное подмножество из 250 запросов в LongFact-Objects, а затем использовали SAFE для получения необработанных показателей оценки ответа каждой модели. Индикатор F1@K для агрегации.

##
Было обнаружено, что, как правило, более крупные языковые модели обеспечивают лучшую фактологичность в полной форме. Как показано на рисунке 6 и в таблице 2 ниже, GPT-4-Turbo лучше, чем GPT-4, GPT-4 лучше, чем GPT-3.5-Turbo, Gemini-Ultra лучше, чем Gemini-Pro, и PaLM-2-L. -IT-RLHF Лучше, чем PaLM-2-L-IT.
以上是DeepMind終結大模型幻覺?標註事實比人類可靠、還便宜20倍,全開源的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 Vue.js 中字符串轉對像用什麼方法?
Apr 07, 2025 pm 09:39 PM
Vue.js 中字符串轉對像用什麼方法?
Apr 07, 2025 pm 09:39 PM
Vue.js 中字符串轉對象時,首選 JSON.parse() 適用於標準 JSON 字符串。對於非標準 JSON 字符串,可根據格式採用正則表達式和 reduce 方法或解碼 URL 編碼字符串後再處理。根據字符串格式選擇合適的方法,並註意安全性與編碼問題,以避免 bug。
 Laravel的地理空間:互動圖和大量數據的優化
Apr 08, 2025 pm 12:24 PM
Laravel的地理空間:互動圖和大量數據的優化
Apr 08, 2025 pm 12:24 PM
利用地理空間技術高效處理700萬條記錄並創建交互式地圖本文探討如何使用Laravel和MySQL高效處理超過700萬條記錄,並將其轉換為可交互的地圖可視化。初始挑戰項目需求:利用MySQL數據庫中700萬條記錄,提取有價值的見解。許多人首先考慮編程語言,卻忽略了數據庫本身:它能否滿足需求?是否需要數據遷移或結構調整? MySQL能否承受如此大的數據負載?初步分析:需要確定關鍵過濾器和屬性。經過分析,發現僅少數屬性與解決方案相關。我們驗證了過濾器的可行性,並設置了一些限制來優化搜索。地圖搜索基於城
 如何設置Vue Axios的超時時間
Apr 07, 2025 pm 10:03 PM
如何設置Vue Axios的超時時間
Apr 07, 2025 pm 10:03 PM
為了設置 Vue Axios 的超時時間,我們可以創建 Axios 實例並指定超時選項:在全局設置中:Vue.prototype.$axios = axios.create({ timeout: 5000 });在單個請求中:this.$axios.get('/api/users', { timeout: 10000 })。
 mysql 無法啟動怎麼解決
Apr 08, 2025 pm 02:21 PM
mysql 無法啟動怎麼解決
Apr 08, 2025 pm 02:21 PM
MySQL啟動失敗的原因有多種,可以通過檢查錯誤日誌進行診斷。常見原因包括端口衝突(檢查端口占用情況並修改配置)、權限問題(檢查服務運行用戶權限)、配置文件錯誤(檢查參數設置)、數據目錄損壞(恢復數據或重建表空間)、InnoDB表空間問題(檢查ibdata1文件)、插件加載失敗(檢查錯誤日誌)。解決問題時應根據錯誤日誌進行分析,找到問題的根源,並養成定期備份數據的習慣,以預防和解決問題。
 Vue.js 如何將字符串類型的數組轉換為對像數組?
Apr 07, 2025 pm 09:36 PM
Vue.js 如何將字符串類型的數組轉換為對像數組?
Apr 07, 2025 pm 09:36 PM
總結:將 Vue.js 字符串數組轉換為對像數組有以下方法:基本方法:使用 map 函數,適合格式規整的數據。高級玩法:使用正則表達式,可處理複雜格式,但需謹慎編寫,考慮性能。性能優化:考慮大數據量,可使用異步操作或高效數據處理庫。最佳實踐:清晰的代碼風格,使用有意義的變量名、註釋,保持代碼簡潔。
 mysql安裝後怎麼使用
Apr 08, 2025 am 11:48 AM
mysql安裝後怎麼使用
Apr 08, 2025 am 11:48 AM
文章介紹了MySQL數據庫的上手操作。首先,需安裝MySQL客戶端,如MySQLWorkbench或命令行客戶端。 1.使用mysql-uroot-p命令連接服務器,並使用root賬戶密碼登錄;2.使用CREATEDATABASE創建數據庫,USE選擇數據庫;3.使用CREATETABLE創建表,定義字段及數據類型;4.使用INSERTINTO插入數據,SELECT查詢數據,UPDATE更新數據,DELETE刪除數據。熟練掌握這些步驟,並學習處理常見問題和優化數據庫性能,才能高效使用MySQL。
 偏遠的高級後端工程師(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
偏遠的高級後端工程師(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
遠程高級後端工程師職位空缺公司:Circle地點:遠程辦公職位類型:全職薪資:$130,000-$140,000美元職位描述參與Circle移動應用和公共API相關功能的研究和開發,涵蓋整個軟件開發生命週期。主要職責獨立完成基於RubyonRails的開發工作,並與React/Redux/Relay前端團隊協作。為Web應用構建核心功能和改進,並在整個功能設計過程中與設計師和領導層緊密合作。推動積極的開發流程,並確定迭代速度的優先級。要求6年以上複雜Web應用後端
 mysql安裝後怎麼優化數據庫性能
Apr 08, 2025 am 11:36 AM
mysql安裝後怎麼優化數據庫性能
Apr 08, 2025 am 11:36 AM
MySQL性能優化需從安裝配置、索引及查詢優化、監控與調優三個方面入手。 1.安裝後需根據服務器配置調整my.cnf文件,例如innodb_buffer_pool_size參數,並關閉query_cache_size;2.創建合適的索引,避免索引過多,並優化查詢語句,例如使用EXPLAIN命令分析執行計劃;3.利用MySQL自帶監控工具(SHOWPROCESSLIST,SHOWSTATUS)監控數據庫運行狀況,定期備份和整理數據庫。通過這些步驟,持續優化,才能提升MySQL數據庫性能。
