
目前,Video Pose Transformer(VPT)在基於視訊的三維人體姿態估計領域取得了最領先的性能。近年來,這些VPT的計算量變得越來越大,這些龐大的計算量同時也限制了這個領域的進一步發展。對那些計算資源不足的研究者十分不友善。例如,訓練一個243幀的VPT模型通常需要花費好幾天的時間,嚴重拖慢了研究的進度,並成為了該領域亟待解決的一大痛點。
那麼,該如何有效地提升 VPT 的效率同時幾乎不失去精度呢?
來自北京大學的團隊提出了一個基於沙漏Tokenizer的高效三維人體姿態估計框架HoT,用來解決現有視訊姿態Transformer(Video Pose Transformer,VPT)高計算需求的問題。此框架可即插即用無縫整合至MHFormer、MixSTE、MotionBERT等模型中,降低模型近40%的運算量而不損失精度,程式碼已開源。


#程式碼網址:https://github.com/NationalGAILab/HoT

研究動機
影片冗餘得去除:由於相鄰影格之間動作的相似性,影片中經常包含大量的冗餘訊息。此外,已有研究指出,在 Transformer 架構中,隨著層的加深,Token 之間的差異性越來越小。因此,可推斷在 Transformer 的深層使用全長的 Pose Token 會引入不必要的冗餘計算,而這些冗餘計算對於最終的估計結果的貢獻有限。 ###############基於這兩方面的觀察,作者提出對深層 Transformer 的 Pose Token 進行剪枝,以減少視訊畫面的冗餘性,同時提高 VPT 的整體效率。然而,這引發了一個新的挑戰:剪枝操作導致了 Token 數量的減少,這時模型不能直接估計出與原始視訊序列相符數量的三維姿態估計結果。這是因為,在傳統的VPT 模型中,每個Token 通常對應影片中的一幀,剪枝後剩餘的序列將不足以覆蓋原始影片的全部幀,這在估計影片中所有幀的三維人體姿態時成為一個顯著的障礙。因此,為了實現高效率的 VPT,還需兼顧另一個重要因素:#######
基於上述三點思考,作者提出了一個基於沙漏結構的高效三維人體姿態估計框架,⏳ Hourglass Tokenizer (HoT)。總的來說,此方法有兩大亮點:
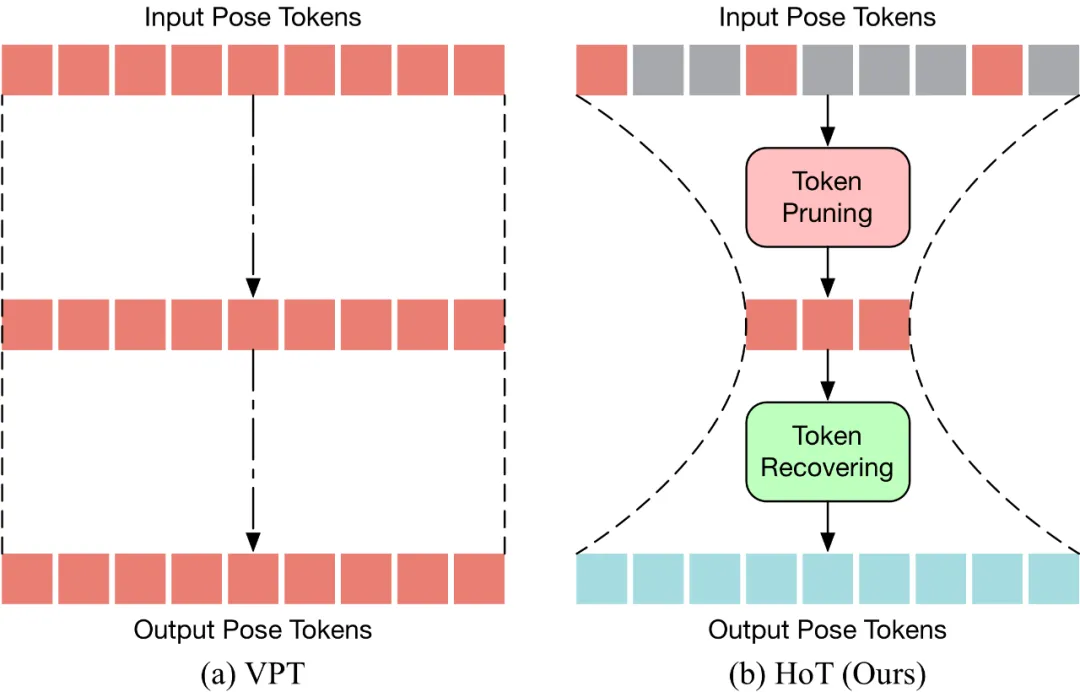
#HoT是第一個基於Transformer 的高效三維人體姿態估計的即插即用框架。如下圖所示,傳統的 VPT 採用了一個 “矩形” 的範式,即在模型的所有層中維持完整長度的 Pose Token,這帶來了高昂的計算成本及特徵冗餘。與傳統的VPT 不同,HoT 先剪枝去除冗餘的Token,再恢復整個序列的Token(看起來像一個「沙漏」),使得Transformer 的中間層中僅保留少量的Token,從而有效地提升了模型的效率。 HoT 也展現了極高的通用性,它不僅可以無縫整合到常規的 VPT 模型中,不論是基於 seq2seq 還是 seq2frame 的 VPT,同時也能夠適配各種 Token 剪枝和恢復策略。
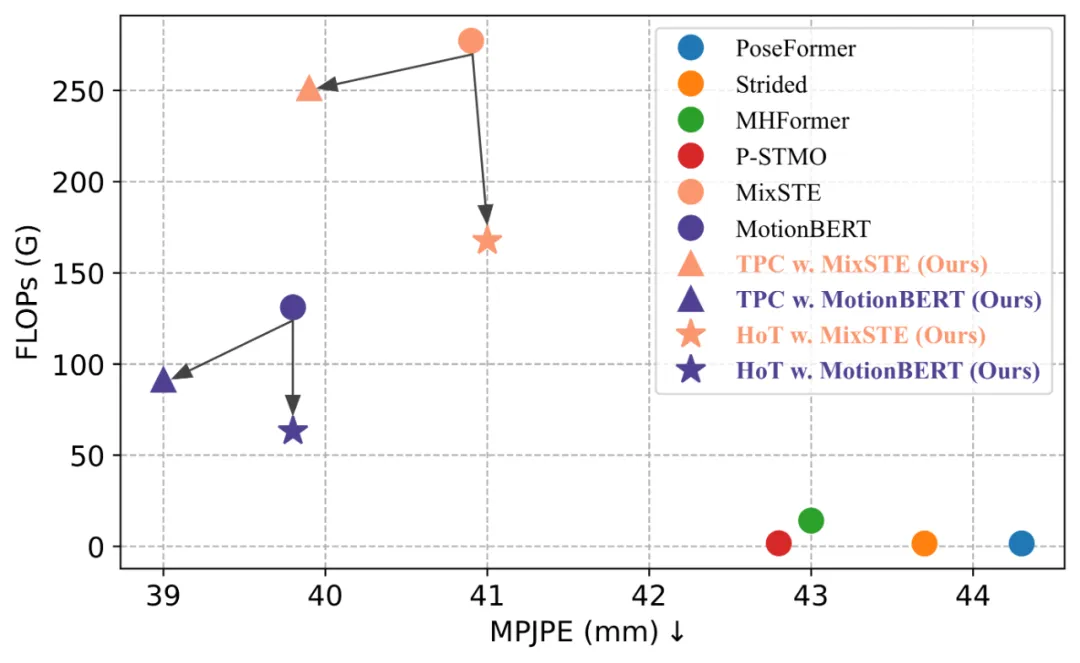
HoT揭示了維持全長的姿態序列是冗餘的,使用少量代表性幀的Pose Token 就可以同時實現高效率和高性能。與傳統的 VPT 模型相比,HoT 不僅大幅提升了處理效率,還實現了高度競爭性甚至更好的結果。例如,它可以在不犧牲效能的情況下,將 MotionBERT 的 FLOPs 降低近 50%;同時將 MixSTE 的 FLOPs 降低近 40%,而效能僅輕微下降 0.2%。
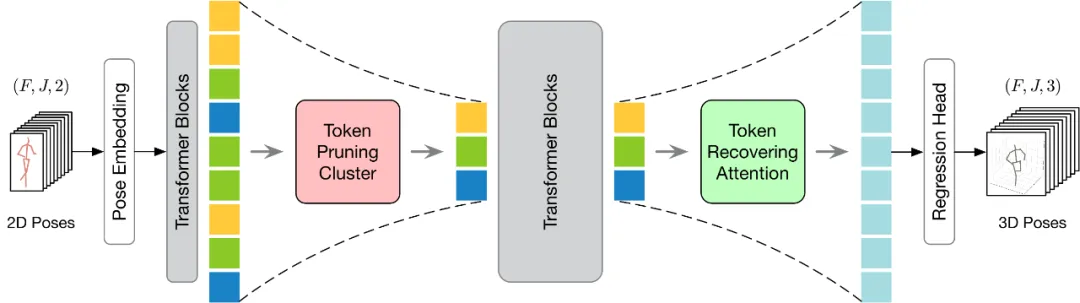
#提出的 HoT 整體架構如下圖所示。為了更有效地執行 Token 的剪枝和恢復,本文提出了 Token 剪枝聚類(Token Pruning Cluster,TPC)和 Token 恢復注意力(Token Recovering Attention,TRA)兩個模組。其中,TPC 模組動態地選擇少量具有高語義多樣性的代表性 Token,同時減輕視訊幀的冗餘。 TRA 模組根據所選的 Token 來恢復詳細的時空信息,從而將網路輸出擴展到原始的全長時序分辨率,以進行快速推理。
Token 剪枝聚類模組
本文認為選取出少量且帶有豐富資訊的Pose Token 以進行準確的三維人體姿態估計是一個難點問題。
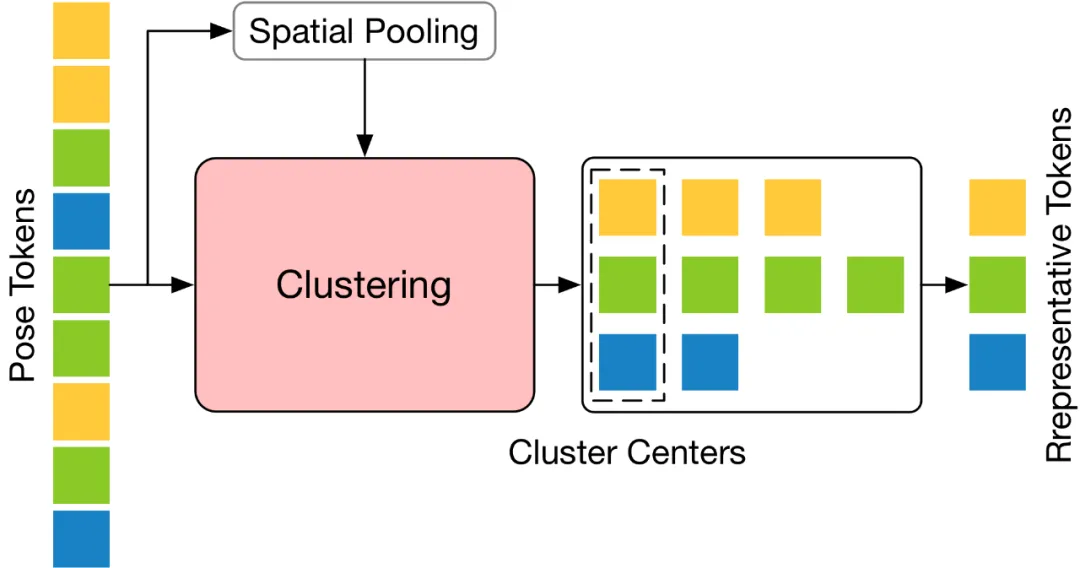
為了解決這個問題,本文認為關鍵在於挑選那些具有高度語義多樣性的代表性 Token,因為這樣的 Token 能夠在降低視訊冗餘的同時保留必要的資訊。基於這個理念,本文提出了一個簡單、有效且無需額外參數的 Token 剪枝聚類(Token Pruning Cluster,TPC)模組。這個模組的核心在於鑑別並去除那些在語義上貢獻較小的 Token,並聚焦於那些能夠為最終的三維人體姿態估計提供關鍵資訊的 Token。透過採用聚類演算法,TPC 動態地選擇聚類中心作為代表性 Token,藉此利用聚類中心的特性來保留原始資料的豐富語意。
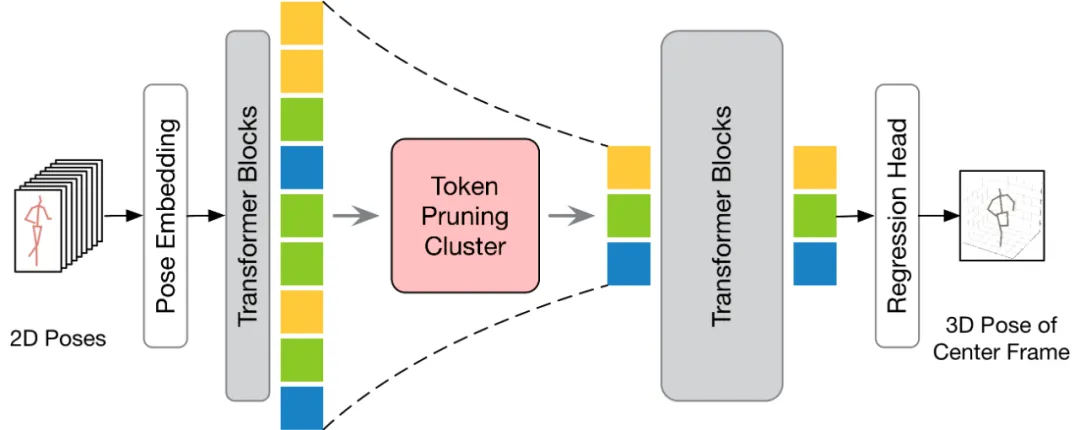
TPC 的結構如下圖所示,它先將輸入的Pose Token 在空間維度上進行池化處理,然後利用池化後Token 的特徵相似性對輸入Token 進行聚類,並選取聚類中心作為代表性Token。
Token 恢復注意力模組
TPC 模組有效地減少了 Pose Token 的數量,然而,剪枝操作引起的時間分辨率下降限制了 VPT 進行 seq2seq 的快速推理。因此,需要對 Token 進行復原操作。同時,考慮到效率因素,此恢復模組應設計得輕量級,以最小化對總體模型計算成本的影響。
為了解決上述挑戰,本文設計了一個輕量級的Token 恢復注意力(Token Recovering Attention,TRA)模組,它能夠基於選定的Token 恢復詳細的時空信息。透過這種方式,由剪枝操作引起的低時間分辨率得到了有效擴展,達到了原始完整序列的時間分辨率,使得網絡能夠一次性估計出所有幀的三維人體姿態序列,從而實現seq2seq 的快速推理。
TRA 模組的結構如下圖所示,其利用最後一層Transformer 中的代表性Token 和初始化為零的可學習Token,透過一個簡單的交叉注意力機制來還原完整的Token 序列。
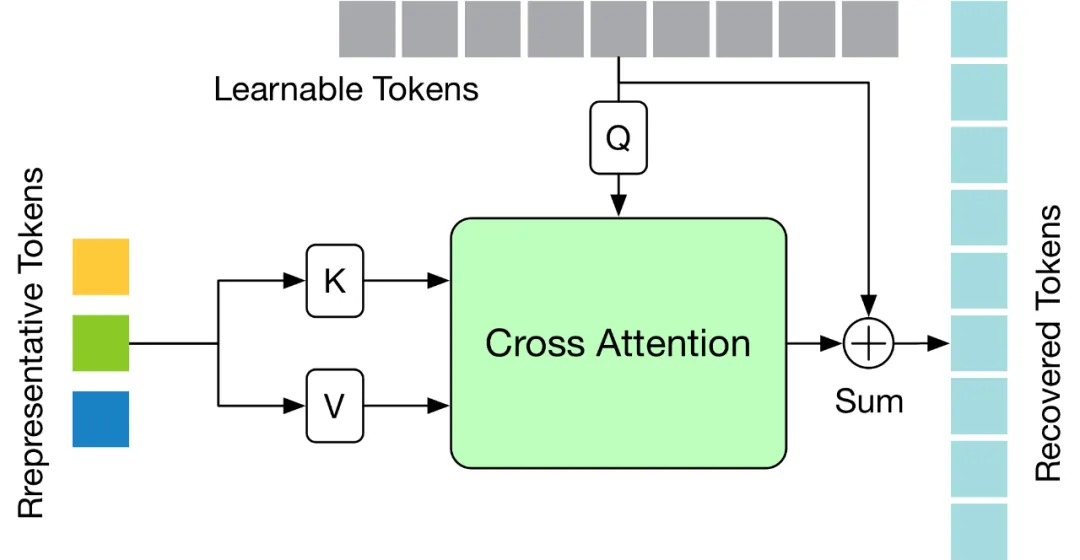
應用程式到現有的VPT
在討論如何將所所提出的方法應用在現有的VPT 之前,本文首先對現有的VPT 架構進行了總結。如下圖所示,VPT 架構主要由三個組成部分構成:一個姿態嵌入模組用於編碼姿態序列的空間與時間信息,多層Transformer 用於學習全局時空表徵,以及一個回歸頭模組用於回歸輸出三維人體姿態結果。
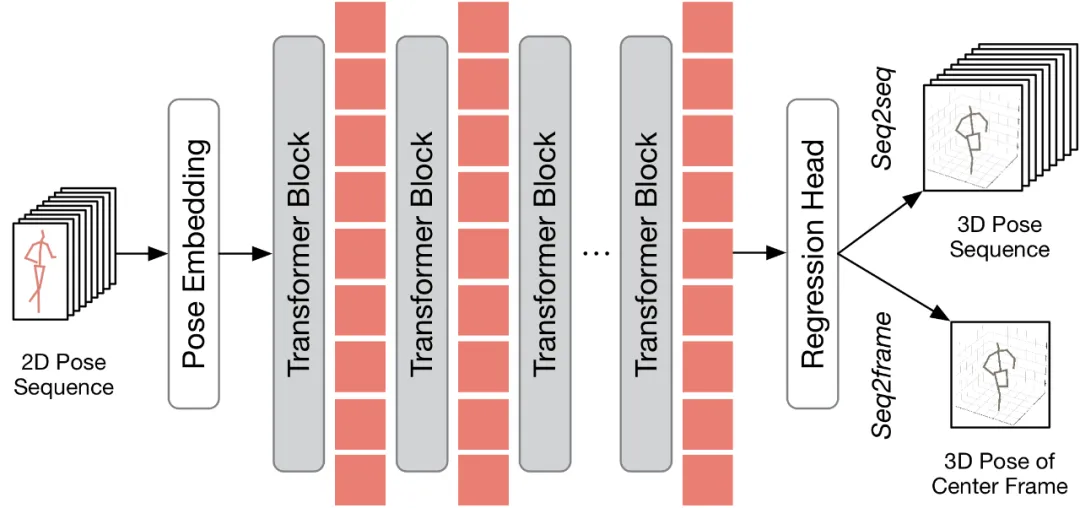
根據輸出的幀數不同,現有的 VPT 可分為兩種推理流程:seq2frame 和 seq2seq。在 seq2seq 流程中,輸出是輸入影片的所有幀,因此需要恢復原始的全長時序解析度。如 HoT 框架圖所示的,TPC 和 TRA 兩個模組都嵌入 VPT 中。在 seq2frame 流程中,輸出是視訊中心幀的三維姿態。因此,在該流程下,TRA 模組是不必要的,只需在 VPT 中整合 TPC 模組即可。其框架如下圖所示。
消融實驗
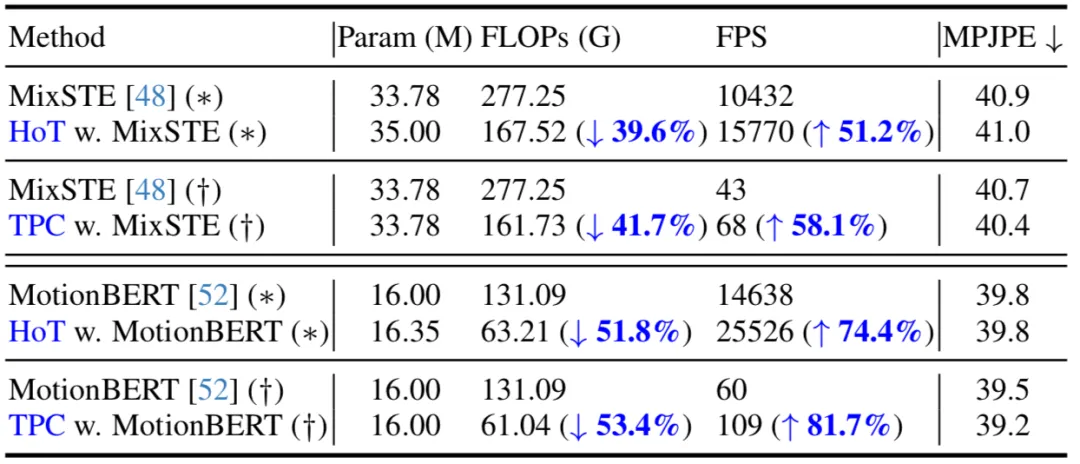
##在下表,本文給出了在seq2seq(*)和seq2frame(†)推理流程下的比較。結果表明,透過在現有 VPT 上應用所提出的方法,本方法能夠在保持模型參數量幾乎不變的同時,顯著減少 FLOPs,並且大幅提高了 FPS。此外,相較於原始模型,所提出的方法在性能上基本持平或能取得更好的性能。
本文也比較了不同的Token 剪枝策略,包括注意力分數剪枝,均勻採樣,以及選擇前k 個具有較大運動量Token 的運動剪枝策略,可見所提出的TPC 取得了最佳的表現。
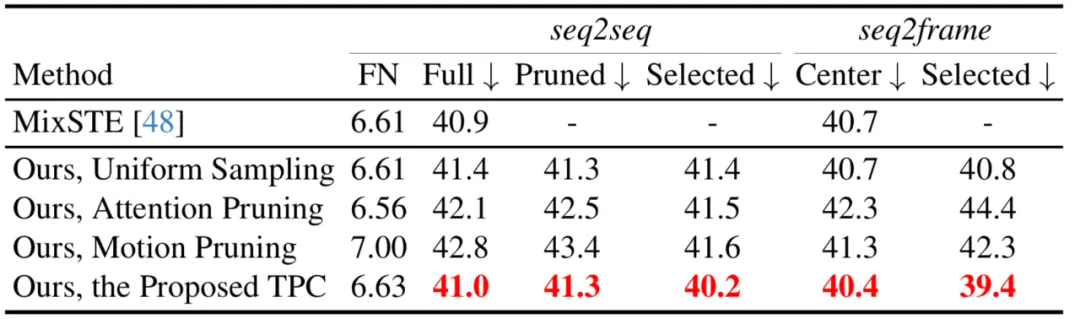
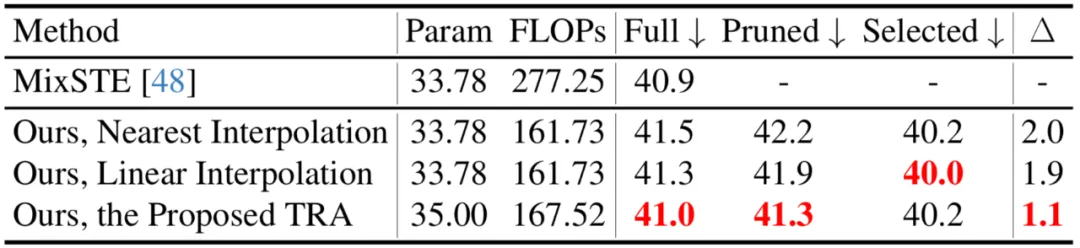
本文也比較了不同的Token 復原策略,包括最近鄰插值和線性插值,可見所提出的TRA 取得了最佳的效能。
與SOTA 方法的比較
##目前,在Human3.6M 資料集上,三維人體姿態估計的領先方法均採用了基於Transformer 的架構。為了驗證本方法的有效性,作者將其應用於三個最新的 VPT 模型:MHForme,MixSTE 和 MotionBERT,並與它們在參數量、FLOPs 和 MPJPE 上進行了比較。
###如下表所示,本方法在保持原有精度的前提下,显著降低了 SOTA VPT 模型的计算量。这些结果不仅验证了本方法的有效性和高效率,还揭示了现有 VPT 模型中存在着计算冗余,并且这些冗余对最终的估计性能贡献甚小,甚至可能导致性能下降。此外,本方法可以剔除掉这些不必要的计算量,同时达到了高度竞争力甚至更优的性能。
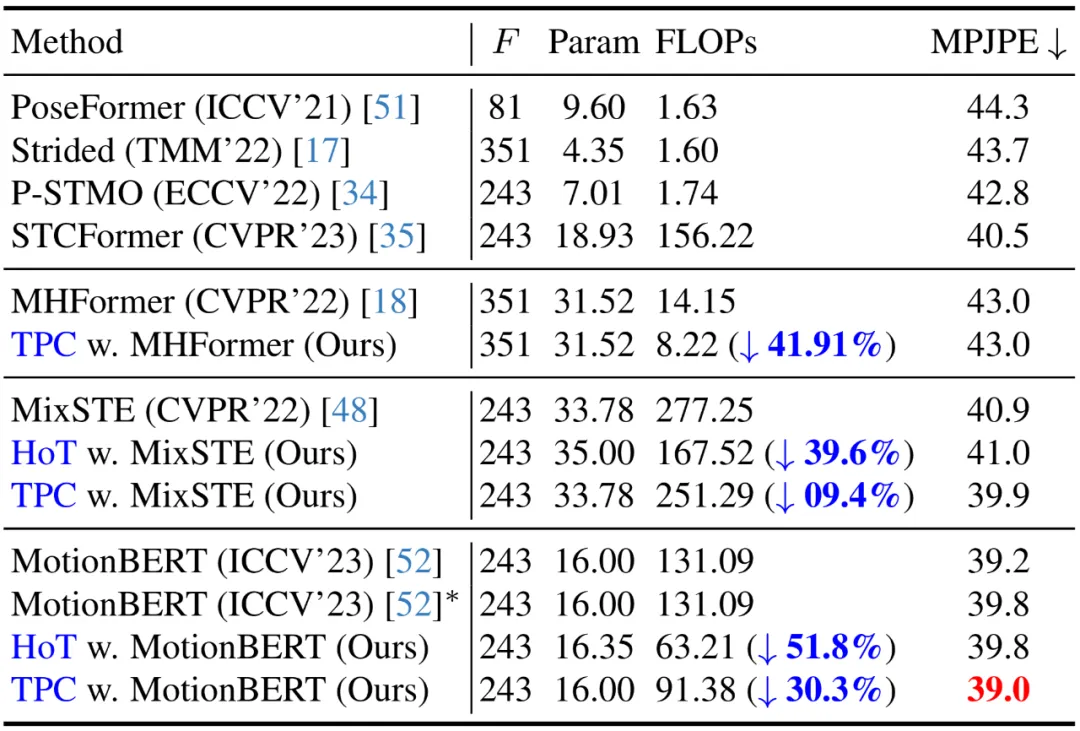
作者还给出了 demo 运行(https://github.com/NationalGAILab/HoT),集成了 YOLOv3 人体检测器、HRNet 二维姿态检测器、HoT w. MixSTE 二维到三维姿态提升器。只需下载作者提供的预训练模型,输入一小段含有人的视频,便可一行代码直接输出三维人体姿态估计的 demo。
python demo/vis.py --video sample_video.mp4
运行样例视频得到的结果:

本文针对现有 Video Pose Transforme(VPT)计算成本高的问题,提出了沙漏 Tokenizer(Hourglass Tokenizer,HoT),这是一种即插即用的 Token 剪枝和恢复框架,用于从视频中高效地进行基于 Transformer 的 3D 人体姿势估计。研究发现,在 VPT 中维持全长姿态序列是不必要的,使用少量代表性帧的 Pose Token 即可同时实现高精度和高效率。大量实验验证了本方法的高度兼容性和广泛适用性。它可以轻松集成至各种常见的 VPT 模型中,不论是基于 seq2seq 还是 seq2frame 的 VPT,并且能够有效地适应多种 Token 剪枝与恢复策略,展示出其巨大潜力。作者期望 HoT 能够推动开发更强、更快的 VPT。
以上是讓影片姿態Transformer變得飛速,北大提出高效三維人體姿態估計框架HoT的詳細內容。更多資訊請關注PHP中文網其他相關文章!




















