

阿里7B多模態文件理解大模型拿下新SOTA

多模態文件理解能力新SOTA!
阿里mPLUG團隊發布最新開源工作mPLUG-DocOwl 1.5,針對高解析度圖片文字辨識、通用文件結構理解、指令遵循、外部知識引入四大挑戰,提出了一系列解決方案。
話不多說,先來看效果。
複雜結構的圖表一鍵辨識轉換為Markdown格式:
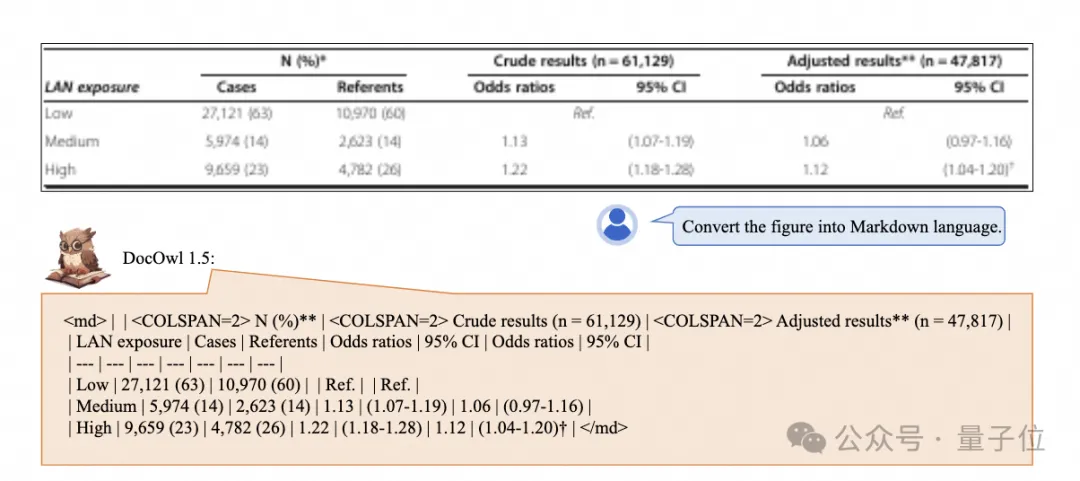
#不同樣式的圖表都可以:
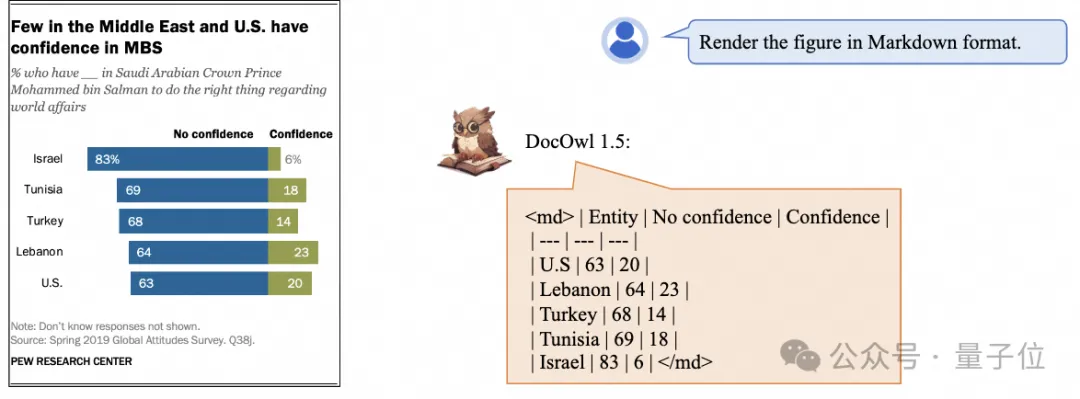
#更細節的文字辨識與定位也能輕鬆搞定:

#還能對文件理解給出詳細解釋:

#要知道,「文檔理解」目前是大語言模型實現落地的一個重要場景,市面上有很多輔助文檔閱讀的產品,有的主要透過OCR系統進行文字識別,配合LLM進行文字理解可以達到不錯的文件理解能力。
不過,由於文件圖片類別多元、文字豐富且排版複雜,難以實現圖表、資訊圖表、網頁等結構複雜圖片的一般理解。
目前爆火的多模態大模型QwenVL-Max、Gemini, Claude3、GPT4V都具備很強的文檔圖片理解能力,然而開源模型在這個方向上的進展緩慢。
而阿里新研究mPLUG-DocOwl 1.5在10個文檔理解基準上拿下SOTA,5個資料集上提升超過10個點,部分資料集上超過智譜17.3B的CogAgent,在DocVQA上達到82.2的效果。
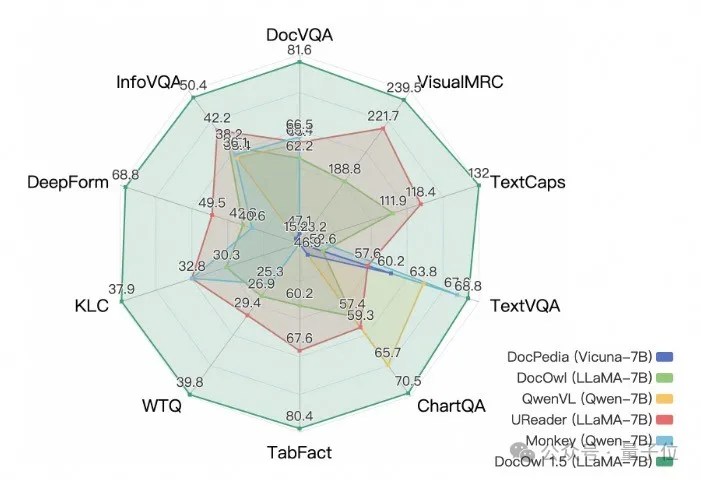
除了具備基準上簡單回答的能力,透過少量「詳細解釋」(reasoning)資料的微調,DocOwl 1.5-Chat也能具備多模態文件領域詳細解釋的能力,具有很大的應用潛力。
阿里mPLUG團隊從2023年7月份開始投入多模態文件理解的研究,陸續發布了mPLUG-DocOwl、 UReader、mPLUG-PaperOwl、mPLUG-DocOwl 1.5,開源了一系列文件理解大模型和訓練資料。
本文從最新工作mPLUG-DocOwl 1.5出發,剖析「多模態文件理解」領域的關鍵挑戰和有效解決方案。
挑戰一:高解析度圖片文字辨識
區分於一般圖片,文件圖片的特點在於形狀大小多樣化,其可以包含A4大小的文件圖、短而寬的表格圖、長而窄的手機網頁截圖以及隨手拍攝的場景圖等等,解析度的分佈十分廣泛。
主流的多模態大模型編碼圖片時,往往直接縮放圖片的大小,例如mPLUG-Owl2和QwenVL縮放到448x448,LLaVA 1.5縮放到336x336。
簡單的縮放文件圖片會導致圖片中的文字模糊形變從而不可辨認。
為了處理文件圖片,mPLUG-DocOwl 1.5延續了其前序工作UReader的切圖做法,模型結構如圖1所示:
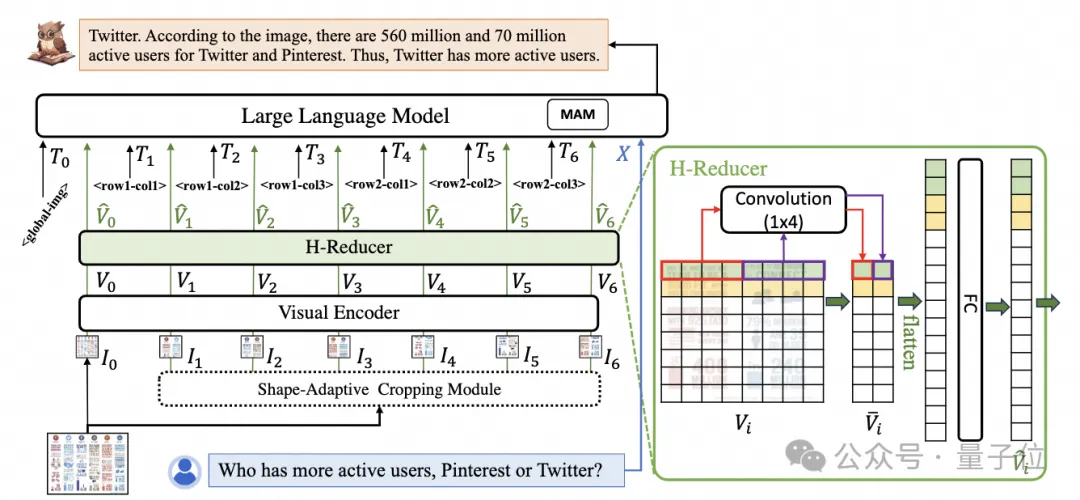
#△圖1:DocOwl 1.5模型結構圖
UReader最早提出在已有多模態大模型的基礎上,透過無參數的形狀適應切圖模組(Shape -adaptive Cropping Module)得到一系列子圖,每張子圖透過低解析度編碼器進行編碼,最後透過語言模型關聯子圖直接的語意。
此切圖策略可以最大程度利用已有通用視覺編碼器(例如CLIP ViT-14/L)的能力進行文件理解,大幅減少重新訓練高分辨率視覺編碼器的代價。形狀適應的切圖模組如圖2所示:
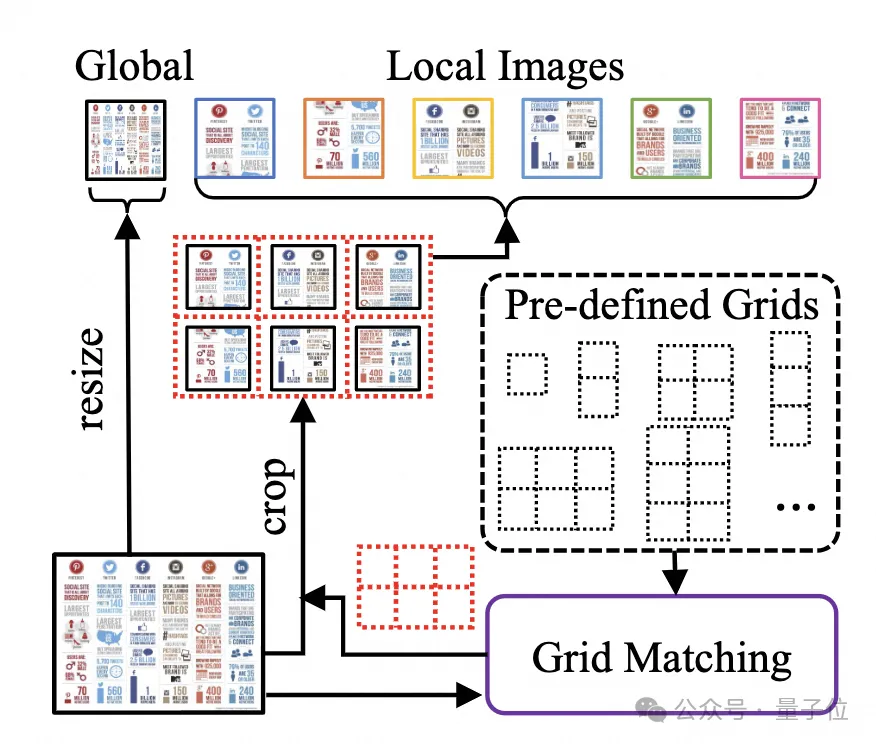
△图2:形状适应的切图模块。
挑战二:通用文档结构理解
对于不依赖OCR系统的文档理解来说,识别文字是基本能力,要实现文档内容的语义理解、结构理解十分重要,例如理解表格内容需要理解表头和行列的对应关系,理解图表需要理解线图、柱状图、饼图等多样化结构,理解合同需要理解日期署名等多样化的键值对。
mPLUG-DocOwl 1.5着力于解决通用文档等结构理解能力,通过模型结构的优化和训练任务的增强实现了显著更强的通用文档理解能力。
结构方面,如图1所示,mPLUG-DocOwl 1.5放弃了mPLUG-Owl/mPLUG-Owl2中Abstractor的视觉语言连接模块,采用基于“卷积 全连接层”的H-Reducer进行特征聚合以及特征对齐。
相比于基于learnable queries的Abstractor,H-Reducer保留了视觉特征之间的相对位置关系,更好的将文档结构信息传递给语言模型。
相比于保留视觉序列长度的MLP,H-Reducer通过卷积大幅缩减了视觉特征数量,使得LLM可以更高效地理解高分辨率文档图片。
考虑到大部分文档图片中文字优先水平排布,水平方向的文字语义具有连贯性,H-Reducer中采用1x4的卷积形状和步长。论文中,作者通过充分的对比实验证明了H-Reducer在结构理解方面的优越性以及1x4是更通用的聚合形状。
训练任务方面,mPLUG-DocOwl 1.5为所有类型的图片设计了统一结构学习(Unified Structure Learning)任务,如图3所示。
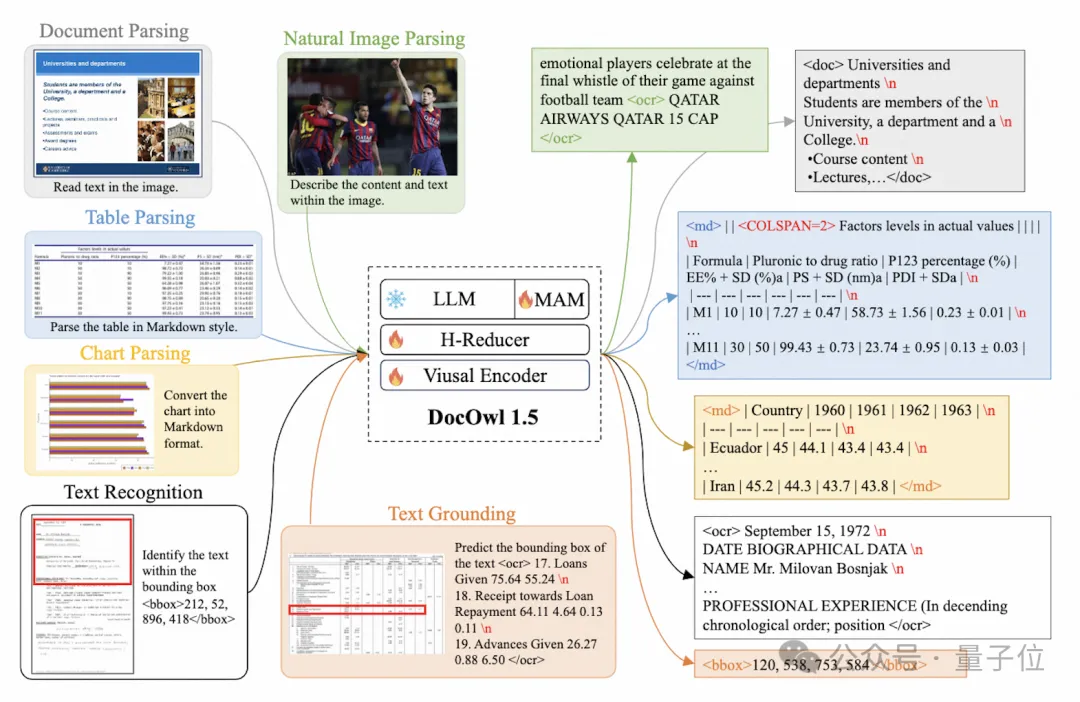
△图3:统一结构学习
Unified Structure Learning既包括了全局的图片文字解析,又包含了多粒度的文字识别和定位。
在全局图片文字解析任务中,对于文档图片和网页图片,采用空格和换行的形式可以最通用地表示文字的结构;对于表格,作者在Markdown语法的基础上引入表示多行多列的特殊字符,兼顾了表格表示的简洁性和通用性;对于图表,考虑到图表是表格数据的可视化呈现,作者同样采用Markdown形式的表格作为图表的解析目标;对于自然图,语义描述和场景文字同等重要,因此采用图片描述拼接场景文字的形式作为解析目标。
在“文字识别和定位”任务中,为了更贴合文档图片理解,作者设计了单词、词组、行、块四种粒度的文字识别和定位,bounding box采用离散化的整数数字表示,范围0-999。
为了支持统一的结构学习,作者构建了一个全面的训练集DocStruct4M,涵盖了文档/网页、表格、图表、自然图等不同类型的图片。
经过统一结构学习,DocOwl 1.5具备多领域文档图片的结构化解析和文字定位能力。

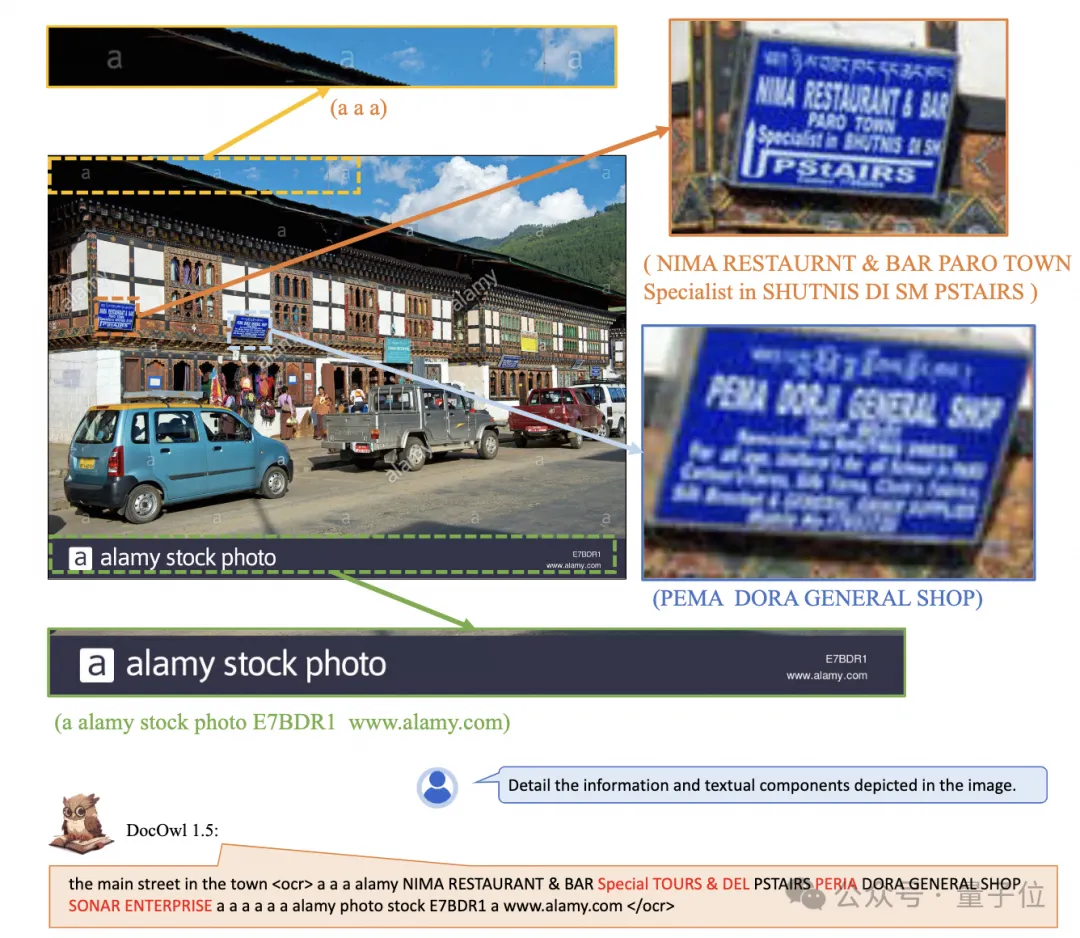
△图4: 结构化文字解析
如图4和图5所示:
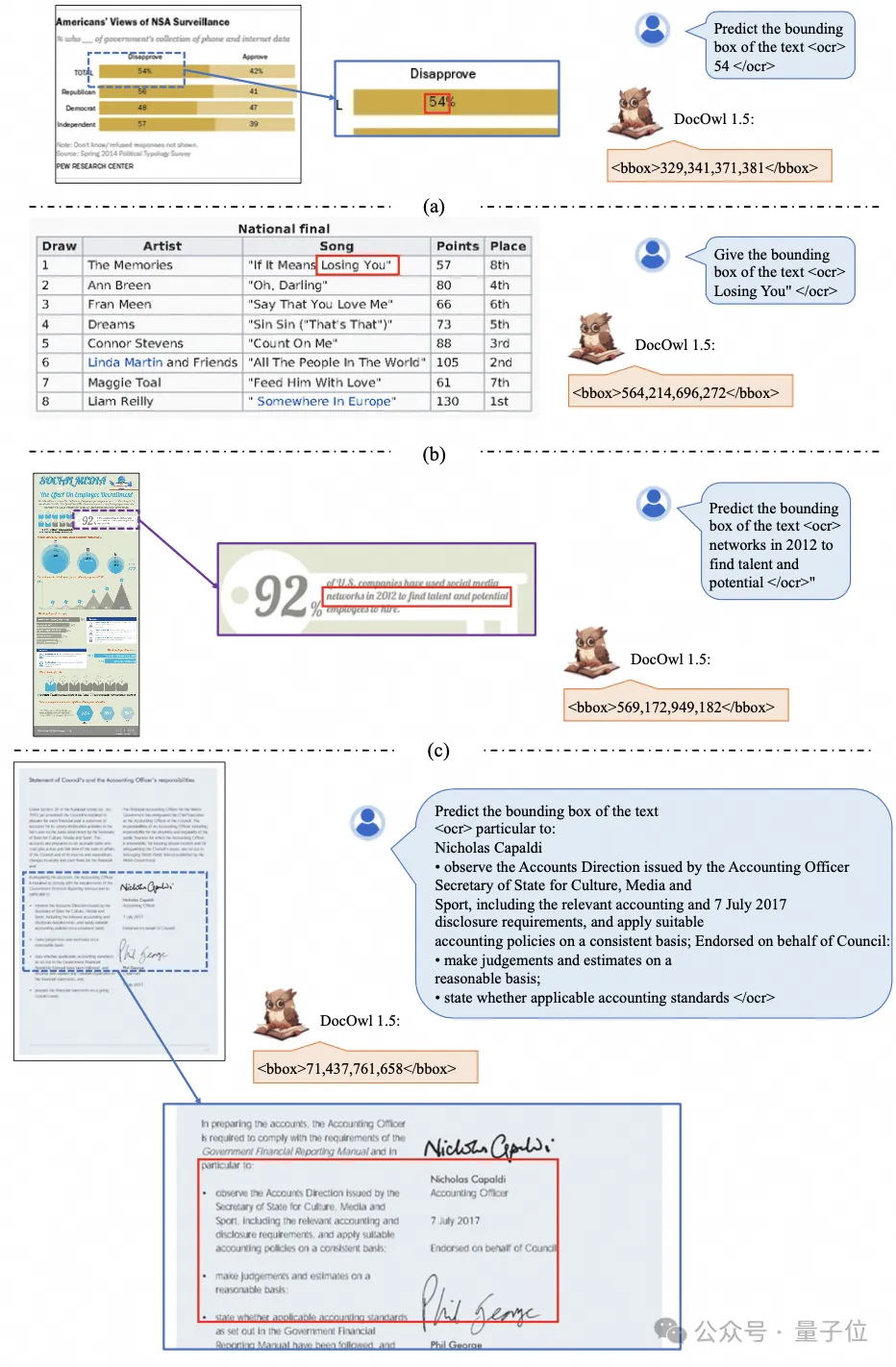
△图5: 多粒度文字识别和定位
挑战三:指令遵循
“指令遵循”(Instruction Following)要求模型基于基础的文档理解能力,根据用户的指令执行不同的任务,例如信息抽取、问答、图片描述等。
延续mPLUG-DocOwl的做法,DocOwl 1.5将多个下游任务统一为指令问答的形式,在统一的结构学习之后,通过多任务联合训练的形式得到一个文档领域的通用模型(generalist)。
此外,为了使得模型具备详细解释的能力,mPLUG-DocOwl曾尝试引入纯文本指令微调数据进行联合训练,有一定效果但并不理想。
在DocOwl 1.5中,作者基于下游任务的问题,通过GPT3.5以及GPT4V构建了少量的详细解释数据(DocReason25K)。
透過聯合文件下游任務和DocReason25K進行訓練,DocOwl 1.5-Chat既可以在基準上實現更優的效果:
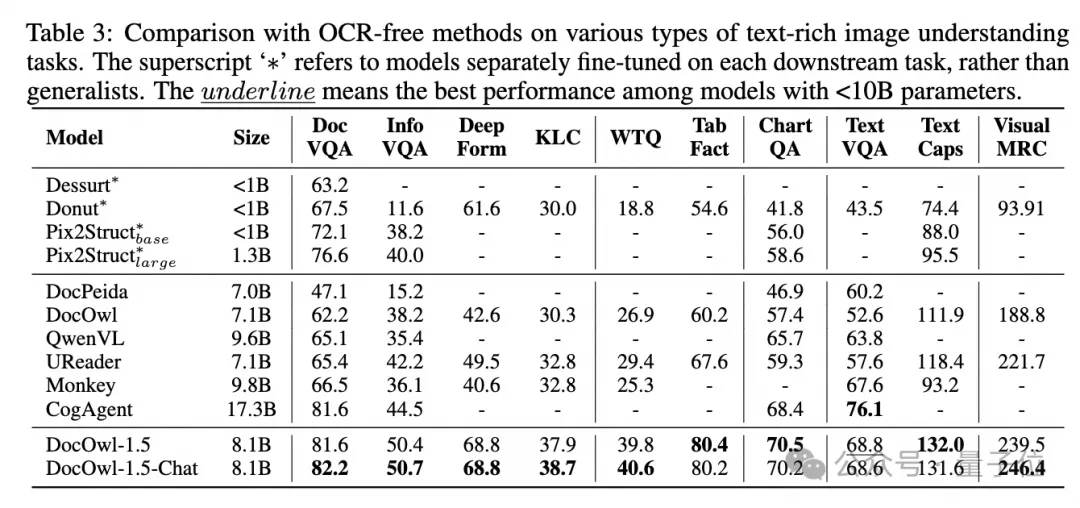
△圖6:文檔理解Benchmark評測
又能給予詳細的解釋:

#△圖7:文件理解詳細解釋
挑戰四:外部知識引入
文件圖片由於資訊的豐富性,進行理解的時候往往需要額外的知識引入,例如特殊領域的專業名詞及其意義等等。
為了研究如何引入外部知識進行更好的文檔理解,mPLUG團隊著手於論文領域提出了mPLUG-PaperOwl,構建了一個高品質論文圖表分析資料集M-Paper,涉及447k的高清論文圖表。
該資料中為論文中的圖表提供了上下文作為外部知識來源,並且設計了「要點」(outline)作為圖表分析的控制訊號,幫助模型更好地掌握用戶的意圖。
基於UReader,作者在M-Paper上微調得到mPLUG-PaperOwl,展現了初步的論文圖表分析能力,如圖8所示。
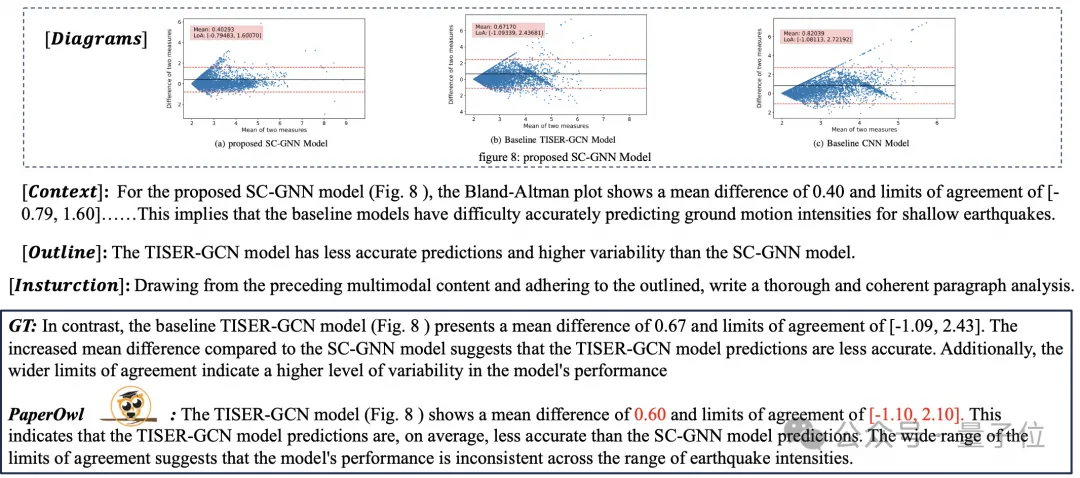
△圖8:論文圖表分析
mPLUG-PaperOwl目前只是引入外部知識進文檔理解的初步嘗試,仍然面臨著領域局限性、知識來源單一等問題需要進一步解決。
總的來說,本文從最近發布的7B最強多模態文檔理解大模型mPLUG-DocOwl 1.5出發,總結了不依賴OCR的情況下,進行多模態文檔理解的關鍵四個關鍵挑戰(“高解析度圖片文字識別”,“通用文件結構理解”,“指令遵循”, “外部知識引入” )和阿里巴巴mPLUG團隊給出的解決方案。
儘管mPLUG-DocOwl 1.5大幅提升了開源模型的文檔理解表現,其距離閉源大模型以及現實需求仍然有較大差距,在自然場景中文字識別、數學計算、通用型等方面仍然有進步空間。
mPLUG團隊會進一步優化DocOwl的效能並進行開源,歡迎大家持續關注和友好討論!
GitHub連結:https://github.com/X-PLUG/mPLUG-DocOwl
論文連結:https://arxiv.org/abs/2403.12895
以上是阿里7B多模態文件理解大模型拿下新SOTA的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 MySQL數據表字段操作指南之添加、修改與刪除方法
Apr 11, 2025 pm 05:42 PM
MySQL數據表字段操作指南之添加、修改與刪除方法
Apr 11, 2025 pm 05:42 PM
MySQL 中字段操作指南:添加、修改和刪除字段。添加字段:ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY] [AUTO_INCREMENT]修改字段:ALTER TABLE table_name MODIFY column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY]
 MySQL數據庫中的嵌套查詢實例詳解
Apr 11, 2025 pm 05:48 PM
MySQL數據庫中的嵌套查詢實例詳解
Apr 11, 2025 pm 05:48 PM
嵌套查詢是一種在一個查詢中包含另一個查詢的方式,主要用於檢索滿足複雜條件、關聯多張表以及計算匯總值或統計信息的數據。實例示例包括:查找高於平均工資的僱員、查找特定類別的訂單以及計算每種產品的總訂購量。編寫嵌套查詢時,需要遵循:編寫子查詢、將其結果寫入外層查詢(使用別名或 AS 子句引用)、優化查詢性能(使用索引)。
 oracle是乾嘛的
Apr 11, 2025 pm 06:06 PM
oracle是乾嘛的
Apr 11, 2025 pm 06:06 PM
Oracle 是全球最大的數據庫管理系統(DBMS)軟件公司,其主要產品包括以下功能:關係數據庫管理系統(Oracle 數據庫)開發工具(Oracle APEX、Oracle Visual Builder)中間件(Oracle WebLogic Server、Oracle SOA Suite)雲服務(Oracle Cloud Infrastructure)分析和商業智能(Oracle Analytics Cloud、Oracle Essbase)區塊鏈(Oracle Blockchain Pla
 Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌是診斷內存洩漏問題的關鍵。通過分析Tomcat日誌,您可以深入了解內存使用情況和垃圾回收(GC)行為,從而有效定位和解決內存洩漏。以下是如何利用Tomcat日誌排查內存洩漏:1.GC日誌分析首先,啟用詳細的GC日誌記錄。在Tomcat啟動參數中添加以下JVM選項:-XX: PrintGCDetails-XX: PrintGCDateStamps-Xloggc:gc.log這些參數會生成詳細的GC日誌(gc.log),包含GC類型、回收對像大小和時間等信息。分析gc.log
 如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
本文介紹如何在Debian系統上自定義Apache的日誌格式。以下步驟將指導您完成配置過程:第一步:訪問Apache配置文件Debian系統的Apache主配置文件通常位於/etc/apache2/apache2.conf或/etc/apache2/httpd.conf。使用以下命令以root權限打開配置文件:sudonano/etc/apache2/apache2.conf或sudonano/etc/apache2/httpd.conf第二步:定義自定義日誌格式找到或
 Ubuntu安裝MariaDB的具體步驟記錄
Apr 11, 2025 pm 05:15 PM
Ubuntu安裝MariaDB的具體步驟記錄
Apr 11, 2025 pm 05:15 PM
Ubuntu 安裝 MariaDB 的步驟:添加 MariaDB 存儲庫安裝 MariaDB啟動 MariaDB 服務保護 MariaDB 安裝連接到 MariaDB創建數據庫和用戶(可選)驗證安裝
 MongoDB性能優化策略,提升數據讀寫速度
Apr 12, 2025 am 06:42 AM
MongoDB性能優化策略,提升數據讀寫速度
Apr 12, 2025 am 06:42 AM
MongoDB性能優化可以通過以下幾個方面實現:1.創建合適的索引,避免全表掃描,根據查詢模式選擇索引類型,定期分析查詢日誌;2.編寫高效的查詢語句,避免使用$where操作符,合理運用查詢操作符,進行分頁查詢;3.合理設計數據模型,避免過大的文檔,保持文檔結構簡潔一致,使用合適的字段類型,考慮數據分片;4.使用連接池復用數據庫連接,減少連接開銷;5.持續監控性能指標,例如查詢時間和連接數,並根據監控數據不斷調整優化策略,最終實現MongoDB的飛速讀寫。
 mongodb與redis怎麼選擇
Apr 12, 2025 am 08:42 AM
mongodb與redis怎麼選擇
Apr 12, 2025 am 08:42 AM
根據應用程序需求選擇 MongoDB 或 Redis:MongoDB 適用於存儲複雜數據,Redis 適用於快速訪問鍵值對和緩存。 MongoDB 使用文檔數據模型、提供持久化存儲和可水平擴展;而 Redis 使用鍵值對數據模型、性能出色且具有成本效益。最終選擇取決於應用程序的具體需求,如數據類型、性能要求、可擴展性和可靠性。
