

RV融合性能拉爆! RCBEVDet:Radar也有春天,最新SOTA!

寫在前面&筆者的個人理解
這篇討論文關注的主要問題是3D目標偵測技術在自動駕駛進程中的應用。儘管環境視覺相機技術的發展為3D目標檢測提供了高分辨率的語義訊息,但這種方法因無法精確捕獲深度資訊和在惡劣天氣或低光照條件下的表現不佳等問題而受限。針對這一問題,討論提出了一種結合環視相機和經濟型毫米波雷達感測器的多模式3D目標檢測新方法—RCBEVDet。該方法透過綜合使用多感測器的信息,提供了更豐富的語義資訊以及在惡劣天氣或低光照條件下的表現不佳等問題的解決方案。針對這一問題,討論提出了一種結合環視相機和經濟型毫米波雷達感測器的多模式3D目標檢測新方法—RCBEVDet。透過綜合使用多模感測器的信息,RCBEVDet能夠提供高解析度的語義訊息,並在惡劣天氣或低光照條件下表現出良好的性能。此方法的提出對於改善自動
RCBEVDet的核心在於兩個關鍵設計:RadarBEVNet和Cross-Attention Multi-layer Fusion Module(CAMF)。 RadarBEVNet旨在有效提取雷達特徵,它包括雙流雷達主幹網路RCS(雷達截面積)感知的BEV(鳥瞰圖)編碼器。這樣的設計利用了點雲基和變換器基編碼器處理雷達點,透過交互更新雷達點特徵,同時將雷達特定的RCS特性作為目標大小的先驗資訊來優化BEV空間的點特徵分佈。 CAMF模組透過多模態交叉注意力機制解決了雷達點的方位誤差問題,實現了雷達和相機的BEV特徵圖的動態對齊以及透過通道和空間融合的多模態特徵自適應融合。 在實作中,透過互動更新雷達點特徵,同時將雷達特定的RCS特性作為目標大小的先驗資訊來優化BEV空間的點特徵分佈。 CAMF模組透過多模態交叉注意力機制解決了雷達點的方位誤差問題,實現了雷達和相機的BEV特徵圖的動態對齊以及透過通道和空間融合的多模態特徵自適應融合。
論文提出的新方法透過以下幾點實現對現有問題的解決:
- 高效的雷達特徵提取器:透過雙流雷達主幹和RCS感知的BEV編碼器設計,專門針對雷達資料的特性進行最佳化,解決了使用為光達設計的編碼器處理雷達資料的不足。
- 強大的雷達-相機特徵融合模組:採用變形的交叉注意力機制,有效處理環視圖像和雷達輸入之間的空間不對齊問題,提高融合效果。
論文的主要貢獻如下:
- 提出了一種新穎的雷達-相機多模態3D目標偵測器RCBEVDet,實現了高精度、高效率和強魯棒性的3D目標偵測。
- 設計了雷達資料的高效能特徵提取器RadarBEVNet,透過雙流雷達主幹和RCS感知BEV編碼器,提高了特徵提取的效率和準確性。
- 引入了Cross-Attention Multi-layer Fusion模組,透過變形交叉注意力機制實現了雷達和相機特徵的精確對齊和高效融合。
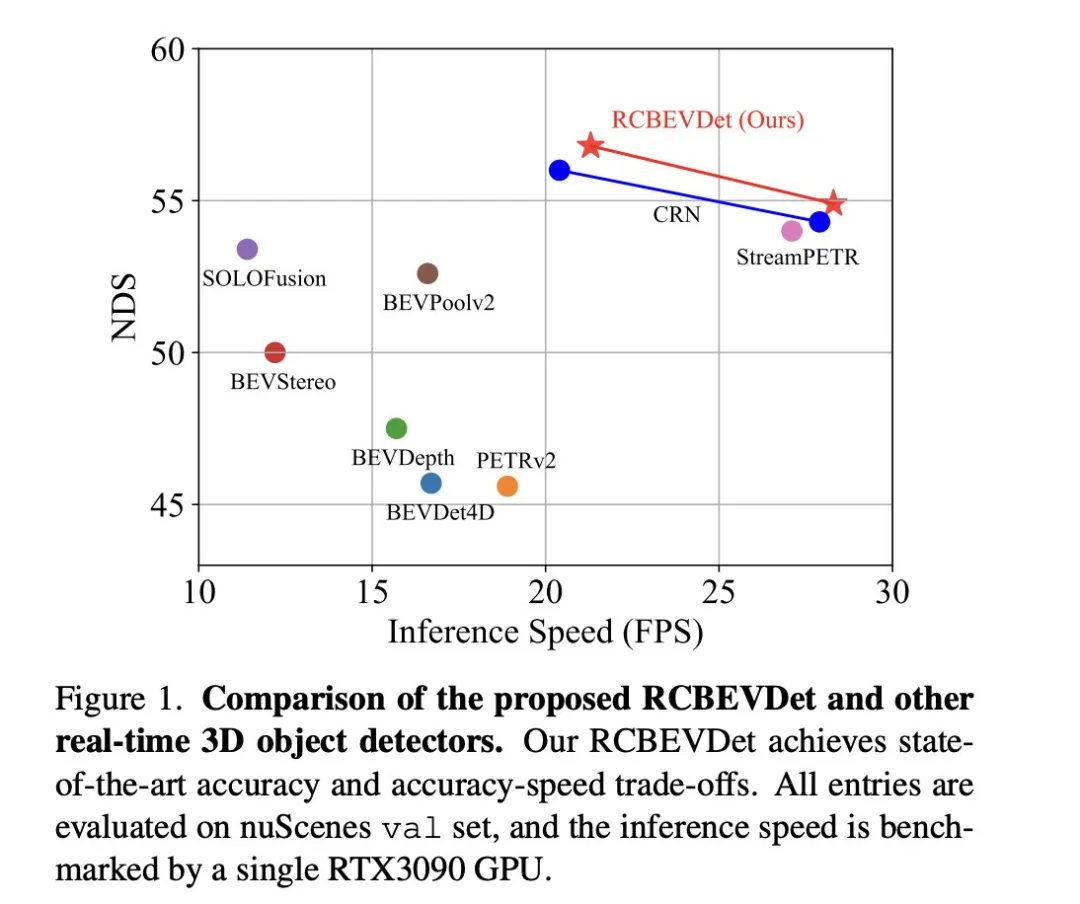
- 在nuScenes和VoD資料集上達到了雷達-相機多模態3D目標偵測的新的最佳性能,同時在精度和速度之間實現了最佳平衡,並展示了在感測器失效情況下的良好魯棒性。
詳解RCBEVDet
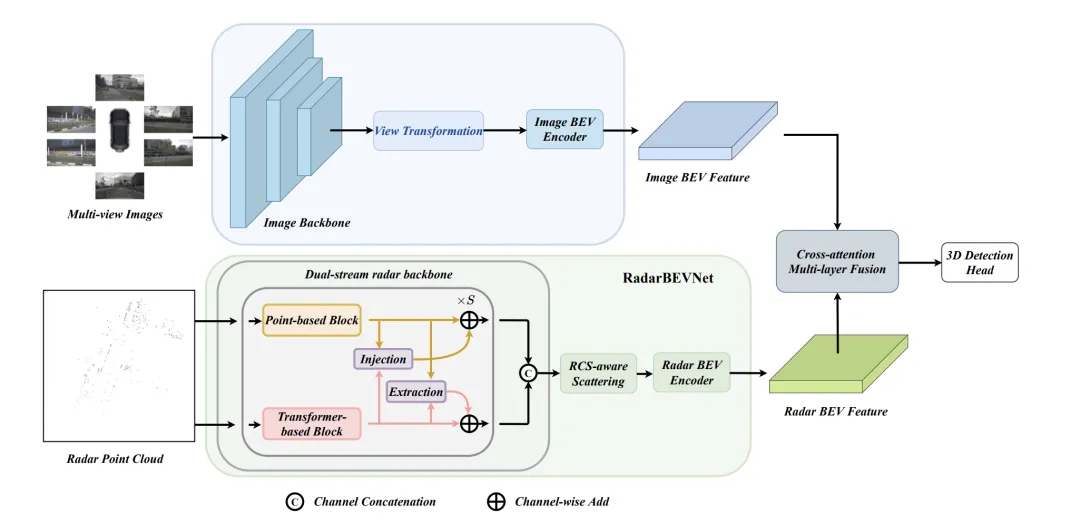
RadarBEVNet
RadarBEVNet是這篇論文提出的有效雷輛BEV(鳥現圖)特徵提取的網路架構,主要包括兩個核心組成部分:雙流雷達主幹網路和RCS(雷達截面積)感知的BEV編碼器。 雙流雷達主幹網路用於從多通道雷達資料中提取豐富的特徵表示。它基於深度卷積神經網路(CNN)構建,在嵌套的捲積和池化層之間交替進行特徵提取和降維操作,以逐漸獲得抽
Dual-stream radar backbone
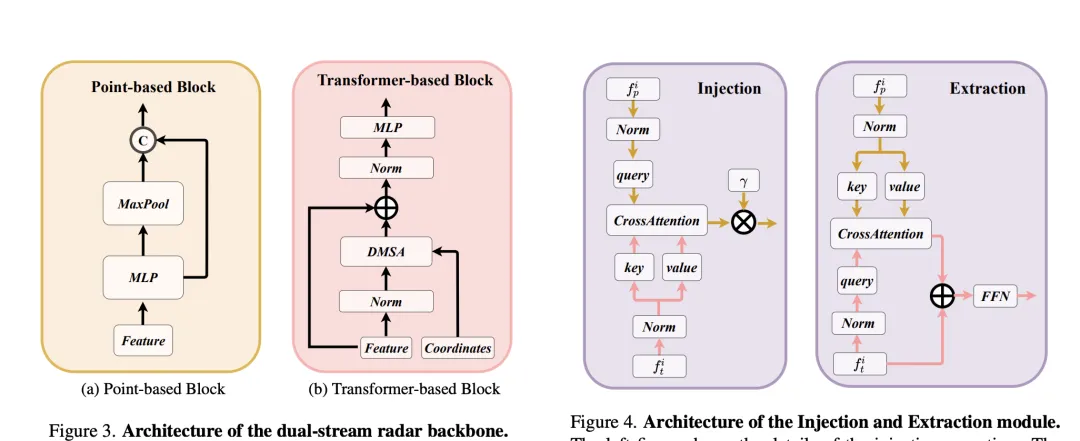
雙流雷達主幹網路由點基主幹幹和變換器基底主幹組成。點基主幹網路透過多層感知機(MLP)和最大池化操作學習部雷達特徵,其過程可以簡化為以下公式:
在這裡的表示雷達點特徵,透過MLP增加特徵維度後,再透過最大池化操作提取全局資訊並與高維特徵連接。
變換器基於幹擾量塊,引入了距離調製的注意力機制(DMSA),透過考慮雷達點之間的距離訊息,優化模型聚集鄰近資訊的能力,促進模型的收斂。 DMSA機制的自註意力可表示為:
RCS-aware BEV encoder
為了解決傳統雷達BEV編碼器產生的BEV特徵稀疏性問題,提出了RCS感知的BEV編碼器。它利用RCS作為目標大小的先驗訊息,將雷達點特徵散佈到BEV空間中的多個像素上,而不是單一像素,以增加BEV特徵的密度。該過程透過以下公式實現:
其中,為基於RCS的高斯式BEV權重圖,透過最大化所有雷達點的權重圖來最佳化。最終,將RCS散佈得到的特徵與連接並透過MLP處理,得到最終的RCS感知BEV特徵。
整體而言,RadarBEVNet透過結合雙流雷達主幹網路和RCS感知的BEV編碼器,高效地提取雷達資料的特徵,並透過RCS作為目標大小的先驗,優化了BEV空間的特徵分佈,為之後的多模態融合提供了強大的基礎。
Cross-Attention Multi-layer Fusion Module
Cross-Attention Multi-layer Fusion Module (CAMF)是一種用於動態對齊和融合多模態特徵的高階網路結構,特別針對雷達和相機產生的鳥瞰圖(BEV)特徵的動態對齊和融合設計。這個模組主要解決了由於雷達點雲的方位誤差導致的特徵不對齊問題,透過變形的交叉注意力機制(Deformable Cross-Attention),有效地捕捉雷達點的微小偏差,並減少了標準交叉注意力的計算複雜度。
CAMF利用變形交叉注意力機制來對齊相機和雷達的BEV特徵。給定相機和雷達的BEV特徵和,首先給和添加可學習的位置嵌入,然後將轉換為查詢和參考點,作為鍵和值。多頭變形交叉注意力的計算可以表示為:
其中表示注意力頭的索引,表示取樣鍵的索引,是總的取樣鍵數。表示採樣偏移,是由和計算得到的注意力權重。
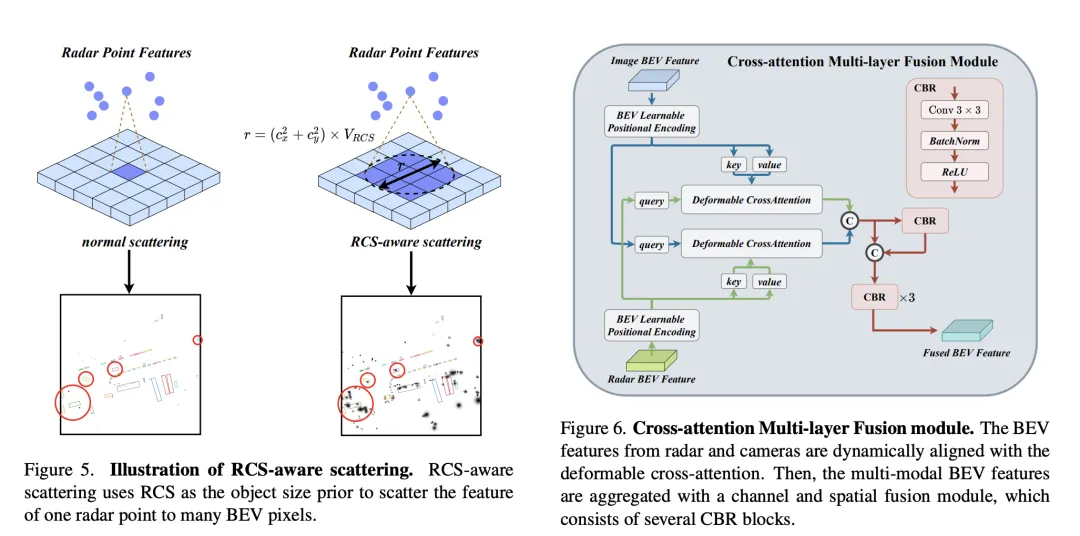
在透過交叉注意力對齊相機和雷達的BEV特徵之後,CAMF使用通道和空間融合層來聚合多模態BEV特徵。具體地,首先將兩個BEV特徵串聯為,然後將送入CBR(卷積-批歸一化-激活函數)區塊並透過殘差連接獲得融合特徵。 CBR塊依序由一個的捲積層、一個批歸一化層和一個ReLU激活函數組成。之後,連續應用三個CBR塊以進一步融合多模態特徵。
透過上述過程,CAMF有效地實現了雷達和相機BEV特徵的精確對齊和高效融合,為3D目標檢測提供了豐富而準確的特徵信息,從而提高了檢測性能。
相關實驗
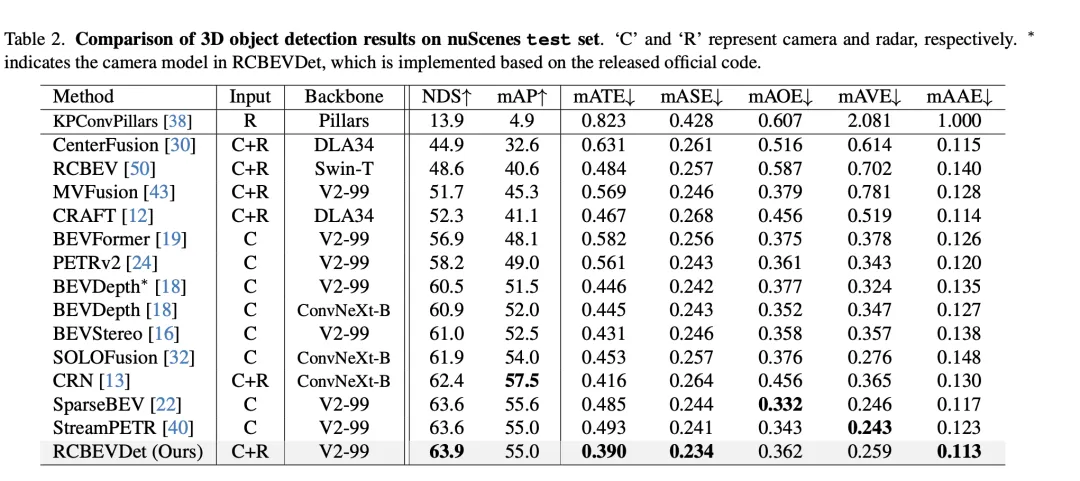
在VoD驗證集上的3D目標偵測結果比較中,RadarBEVNet透過融合相機和雷達數據,在整個標註區域內和興趣區域內的平均精度(mAP)表現上均展現了優秀的性能。具體來說,對於整個標註區域,RadarBEVNet在汽車、行人和騎乘者的偵測上分別達到了40.63%、38.86%和70.48%的AP值,將綜合mAP提升到了49.99%。而在興趣區域,即靠近本車的駕駛通道內,RadarBEVNet的表現更為突出,分別在汽車、行人和騎行者的檢測上達到了72.48%、49.89%和87.01%的AP值,綜合mAP達到了69.80%。
這些結果揭示了幾個關鍵點。首先,RadarBEVNet透過有效融合相機和雷達輸入,能夠充分利用兩種感光元件的互補優勢,提升了整體的偵測效能。相較於僅使用雷達的方法如PointPillar和RadarPillarNet,RadarBEVNet在綜合mAP上有明顯的提升,顯示多模態融合對於提高偵測精度尤為重要。其次,RadarBEVNet在興趣區域內的表現特別優秀,這對於自動駕駛應用來說尤其關鍵,因為興趣區域內的目標通常對即時駕駛決策影響最大。最後,雖然在汽車和行人的偵測上,RadarBEVNet的AP值略低於某些單一模態或其他多模態方法,但在騎乘者偵測和綜合mAP表現上,RadarBEVNet展現了其綜合性能的優勢。 RadarBEVNet透過融合相機和雷達的多模態數據,實現了在VoD驗證集上的優異表現,特別是在對自動駕駛至關重要的興趣區域內展現了強大的檢測能力,證明了其作為一種有效的3D目標檢測方法的潛力。
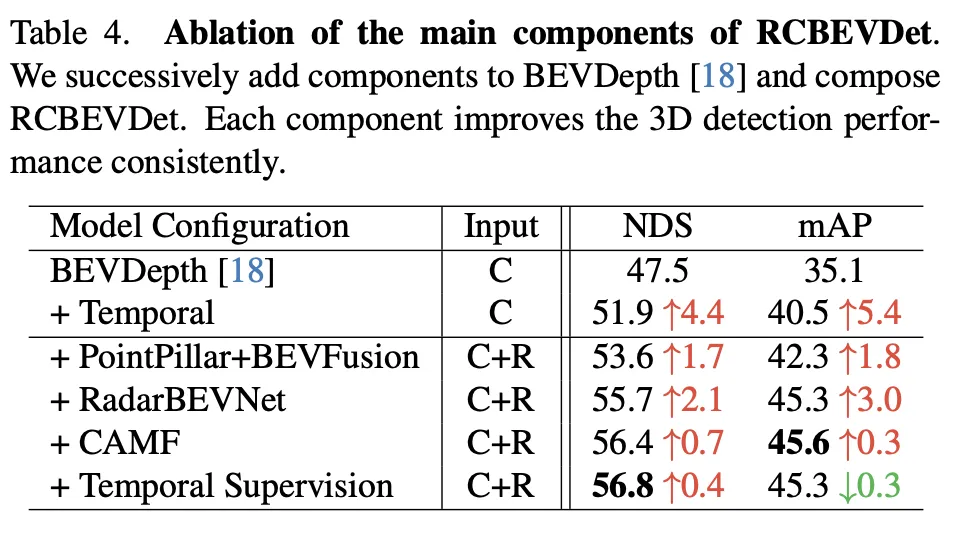
这个消融实验展示了RadarBEVNet在逐步添加主要组件时,对3D目标检测性能的持续改进。从基准模型BEVDepth开始,每一步增加的组件都显著提高了NDS(核心度量标准,反映了检测精度和完整性)和mAP(平均精确度,反映了模型对目标的检测能力)。
- 添加时间信息:通过引入时间信息,NDS和mAP分别提升了4.4和5.4个百分点。这表明时间信息对于提高3D目标检测的准确性和鲁棒性非常有效,可能是因为时间维度提供了额外的动态信息,有助于模型更好地理解场景和目标的动态特性。
- 加入PointPillar BEVFusion(基于雷达和相机的融合):这一步进一步提升了NDS和mAP,分别增加了1.7和1.8个百分点。这说明通过融合雷达和相机数据,模型能够获取更全面的场景理解,弥补了单一模态数据的局限。
- 引入RadarBEVNet:NDS和mAP分别再次提升2.1和3.0个百分点。RadarBEVNet作为一个高效的雷达特征提取器,优化了雷达数据的处理,提高了特征的质量和有效性,这对于整体检测性能的提升至关重要。
- 添加CAMF(交叉注意力多层融合模块):通过精细的特征对齐和融合,NDS增加了0.7个百分点,mAP稍微提升到45.6,显示出在特征融合方面的有效性。这一步骤的改进虽然不如前几步显著,但依然证明了在多模态融合过程中,精确的特征对齐对于提高检测性能的重要性。
- 加入时间监督:最后,引入时间监督后,NDS微增0.4个百分点至56.8,而mAP略有下降0.3个百分点至45.3。这表明时间监督能进一步提升模型在时间维度的性能,尽管对mAP的贡献可能受到特定实验设置或数据分布的影响而略显限制。
总的来说,这一系列的消融实验清晰地展示了RadarBEVNet中每个主要组件对于提高3D目标检测性能的贡献,从时间信息的引入到复杂的多模态融合策略,每一步都为模型带来了性能上的提升。特别是,对雷达和相机数据的精细处理和融合策略,证明了在复杂的自动驾驶环境中,多模态数据处理的重要性。
讨论
论文提出的RadarBEVNet方法通过融合相机和雷达的多模态数据,有效地提升了3D目标检测的准确性和鲁棒性,尤其在复杂的自动驾驶场景中表现出色。通过引入RadarBEVNet和Cross-Attention Multi-layer Fusion Module(CAMF),RadarBEVNet不仅优化了雷达数据的特征提取过程,还实现了雷达和相机数据之间精准的特征对齐和融合,从而克服了单一传感器数据使用中的局限性,如雷达的方位误差和相机在低光照或恶劣天气条件下的性能下降。
优点方面,RadarBEVNet的主要贡献在于其能够有效处理并利用多模态数据之间的互补信息,提高了检测的准确度和系统的鲁棒性。RadarBEVNet的引入使得雷达数据的处理更为高效,而CAMF模块确保了不同传感器数据之间的有效融合,弥补了各自的不足。此外,RadarBEVNet在实验中展现了在多个数据集上的优异性能,尤其是在自动驾驶中至关重要的兴趣区域内,显示了其在实际应用场景中的潜力。
缺点方面,尽管RadarBEVNet在多模态3D目标检测领域取得了显著成果,但其实现的复杂性也相应增加,可能需要更多的计算资源和处理时间,这在一定程度上限制了其在实时应用场景中的部署。此外,虽然RadarBEVNet在骑行者检测和综合性能上表现优秀,但在特定类别上(如汽车和行人)的性能仍有提升空间,这可能需要进一步的算法优化或更高效的特征融合策略来解决。
总之,RadarBEVNet通过其创新的多模态融合策略,在3D目标检测领域展现了显著的性能优势。尽管存在一些局限性,如计算复杂度较高和在特定检测类别上的性能提升空间,但其在提高自动驾驶系统准确性和鲁棒性方面的潜力不容忽视。未来的工作可以聚焦于优化算法的计算效率和进一步提高其在各类目标检测上的表现,以推动RadarBEVNet在实际自动驾驶应用中的广泛部署。
结论
论文通过融合相机和雷达数据,引入了RadarBEVNet和Cross-Attention Multi-layer Fusion Module(CAMF),在3D目标检测领域展现出显著的性能提升,特别是在自动驾驶的关键场景中表现优异。它有效地利用了多模态数据之间的互补信息,提高了检测准确性和系统的鲁棒性。尽管存在计算复杂度高和在某些类别上性能提升空间的挑战,\ours在推动自动驾驶技术发展,尤其是在提升自动驾驶系统的感知能力方面,展现了巨大的潜力和价值。未来工作可以关注于优化算法效率和进一步提升检测性能,以便更好地适应实时自动驾驶应用的需求。
以上是RV融合性能拉爆! RCBEVDet:Radar也有春天,最新SOTA!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 為何在自動駕駛方面Gaussian Splatting如此受歡迎,開始放棄NeRF?
Jan 17, 2024 pm 02:57 PM
為何在自動駕駛方面Gaussian Splatting如此受歡迎,開始放棄NeRF?
Jan 17, 2024 pm 02:57 PM
寫在前面&筆者的個人理解三維Gaussiansplatting(3DGS)是近年來在顯式輻射場和電腦圖形學領域出現的一種變革性技術。這種創新方法的特點是使用了數百萬個3D高斯,這與神經輻射場(NeRF)方法有很大的不同,後者主要使用隱式的基於座標的模型將空間座標映射到像素值。 3DGS憑藉其明確的場景表示和可微分的渲染演算法,不僅保證了即時渲染能力,而且引入了前所未有的控制和場景編輯水平。這將3DGS定位為下一代3D重建和表示的潛在遊戲規則改變者。為此我們首次系統性地概述了3DGS領域的最新發展與關
 自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
昨天面試被問到了是否做過長尾相關的問題,所以就想著簡單總結一下。自動駕駛長尾問題是指自動駕駛汽車中的邊緣情況,即發生機率較低的可能場景。感知的長尾問題是目前限制單車智慧自動駕駛車輛運行設計域的主要原因之一。自動駕駛的底層架構和大部分技術問題已經解決,剩下的5%的長尾問題,逐漸成了限制自動駕駛發展的關鍵。這些問題包括各種零碎的場景、極端的情況和無法預測的人類行為。自動駕駛中的邊緣場景"長尾"是指自動駕駛汽車(AV)中的邊緣情況,邊緣情況是發生機率較低的可能場景。這些罕見的事件
 選擇相機還是光達?實現穩健的三維目標檢測的最新綜述
Jan 26, 2024 am 11:18 AM
選擇相機還是光達?實現穩健的三維目標檢測的最新綜述
Jan 26, 2024 am 11:18 AM
0.寫在前面&&個人理解自動駕駛系統依賴先進的感知、決策和控制技術,透過使用各種感測器(如相機、光達、雷達等)來感知周圍環境,並利用演算法和模型進行即時分析和決策。這使得車輛能夠識別道路標誌、檢測和追蹤其他車輛、預測行人行為等,從而安全地操作和適應複雜的交通環境。這項技術目前引起了廣泛的關注,並認為是未來交通領域的重要發展領域之一。但是,讓自動駕駛變得困難的是弄清楚如何讓汽車了解周圍發生的事情。這需要自動駕駛系統中的三維物體偵測演算法可以準確地感知和描述周圍環境中的物體,包括它們的位置、
 你是否真正掌握了座標系轉換?自動駕駛離不開的多感測器問題
Oct 12, 2023 am 11:21 AM
你是否真正掌握了座標系轉換?自動駕駛離不開的多感測器問題
Oct 12, 2023 am 11:21 AM
一先導與重點文章主要介紹自動駕駛技術中幾種常用的座標系統,以及他們之間如何完成關聯與轉換,最終建構出統一的環境模型。這裡重點理解自車到相機剛體轉換(外參),相機到影像轉換(內參),影像到像素有單位轉換。 3d向2d轉換會有對應的畸變,平移等。重點:自車座標系相機機體座標系需要被重寫的是:平面座標系像素座標系難點:要考慮影像畸變,去畸變和加畸變都是在像平面上去補償二簡介視覺系統一共有四個座標系:像素平面座標系(u,v)、影像座標系(x,y)、相機座標系()與世界座標系()。每種座標系之間均有聯繫,
 SIMPL:用於自動駕駛的簡單高效的多智能體運動預測基準
Feb 20, 2024 am 11:48 AM
SIMPL:用於自動駕駛的簡單高效的多智能體運動預測基準
Feb 20, 2024 am 11:48 AM
原文標題:SIMPL:ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving論文連結:https://arxiv.org/pdf/2402.02519.pdf程式碼連結:https://github.com/HKUST-Aerial-Robotics/SIMPLobotics單位論文想法:本文提出了一種用於自動駕駛車輛的簡單且有效率的運動預測基線(SIMPL)。與傳統的以代理為中心(agent-cent
 FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
目標偵測在自動駕駛系統當中是一個比較成熟的問題,其中行人偵測是最早得以部署演算法之一。在多數論文當中已經進行了非常全面的研究。然而,利用魚眼相機進行環視的距離感知相對來說研究較少。由於徑向畸變大,標準的邊界框表示在魚眼相機當中很難實施。為了緩解上述描述,我們探索了擴展邊界框、橢圓、通用多邊形設計為極座標/角度表示,並定義一個實例分割mIOU度量來分析這些表示。所提出的具有多邊形形狀的模型fisheyeDetNet優於其他模型,並同時在用於自動駕駛的Valeo魚眼相機資料集上實現了49.5%的mAP
 自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
自動駕駛與軌跡預測看這篇就夠了!
Feb 28, 2024 pm 07:20 PM
軌跡預測在自動駕駛中承擔著重要的角色,自動駕駛軌跡預測是指透過分析車輛行駛過程中的各種數據,預測車輛未來的行駛軌跡。作為自動駕駛的核心模組,軌跡預測的品質對於下游的規劃控制至關重要。軌跡預測任務技術堆疊豐富,需熟悉自動駕駛動/靜態感知、高精地圖、車道線、神經網路架構(CNN&GNN&Transformer)技能等,入門難度很高!許多粉絲期望能夠盡快上手軌跡預測,少踩坑,今天就為大家盤點下軌跡預測常見的一些問題和入門學習方法!入門相關知識1.預習的論文有沒有切入順序? A:先看survey,p
 聊聊端到端與下一代自動駕駛系統,以及端到端自動駕駛的一些迷思?
Apr 15, 2024 pm 04:13 PM
聊聊端到端與下一代自動駕駛系統,以及端到端自動駕駛的一些迷思?
Apr 15, 2024 pm 04:13 PM
最近一個月由於眾所周知的一些原因,非常密集地和業界的各種老師同學進行了交流。交流中必不可免的一個話題自然是端到端與火辣的特斯拉FSDV12。想藉此機會,整理當下這個時刻的一些想法和觀點,供大家參考和討論。如何定義端到端的自動駕駛系統,應該期望端到端解決什麼問題?依照最傳統的定義,端到端的系統指的是一套系統,輸入感測器的原始訊息,直接輸出任務關心的變數。例如,在影像辨識中,CNN相對於傳統的特徵提取器+分類器的方法就可以稱之為端到端。在自動駕駛任務中,輸入各種感測器的資料(相機/LiDAR
