

讓Siri不再智障!蘋果定義新的端側模型,「大大優於GPT-4,擺脫文本,可視化模擬螢幕訊息,最小參數模型相較基線系統仍提升5%

撰稿丨諾亞
#出品| 51CTO技術堆疊(微訊號:blog51cto)
#總是被使用者吐槽「有點智障」的Siri有救了!
Siri自誕生以來就是智慧語音助理領域的代表之一,但在很長一段時間裡,其表現並不盡如人意。然而,蘋果的人工智慧團隊最新發布的研究成果有望大幅改變現狀。這些成果令人興奮,同時也引發了對該領域未來的極大期待。
在相關的研究論文中,蘋果的AI專家們描述了一個系統,其中Siri不僅可以識別圖像中的內容,還能做更多的事情,變得更加智能、更實用。這個功能模型被稱為ReALM,它是基於GPT 4.0的標準,具有比GPT 4.0更優秀的基準能力。這些專家認為,他們開發的這個模型是用來實現自己研發的一個功能的,它可以讓Siri更智能,更實用,更適用於各種場景。
一、動機:解決不同實體的指涉解析
根據蘋果的研究團隊指出:「讓對話助手能夠理解上下文,包括相關的內容指向,非常關鍵。能讓用戶根據他們所看到的螢幕內容進行提問,是確保實現語音操作體驗的重要一步。」
#打個比方,在人機互動過程中,使用者常常會在對話中提及螢幕上的某個元素或內容,例如指示語音助理撥打電話號碼、導航至地圖上的特定地點、開啟特定應用程式或網頁等。如果對話助手無法理解使用者指令背後的實體指代,就無法準確地執行這些命令。
而且人類對話中普遍存在模糊指代的現象,為了實現自然的人機交互,以及在用戶與語音助手進行關於屏幕內容查詢時準確理解語境,指代解析能力至關重要。
蘋果在論文中提到的名為ReALM(Reference Resolution As Language Modeling)的模型,其優勢就在於,它能夠同時考慮用戶螢幕上的內容和正在進行的任務,利用大語言模型解決不同類型實體(包括對話實體和非對話實體)的指涉解析問題。
儘管傳統的文字模態不便於處理螢幕上顯示的實體,但ReALM系統透過將指涉解析轉換為語言建模問題,並成功運用LLMs來處理螢幕上非對話實體的指涉,極大地推動了這一目標的達成。如此一來,便可望達成高度智慧、更沉浸的使用者體驗。
二、重構:突破傳統文字模態的限制
傳統的文字模態不便於處理螢幕上顯示的實體,是因為螢幕上的實體通常包含豐富的視覺資訊和佈局結構,例如圖像、圖標、按鈕及它們之間的相對位置關係等,這些資訊在純粹的文字描述中難以完全表達。
ReALM系統針對這項挑戰,創造性地提出了透過解析螢幕上的實體及其位置資訊來重建螢幕,並產生一種純文字表示,這種文字能視覺化地反映螢幕內容。
實體部分會被特別標記,以便語言模型了解實體出現在何處及其周圍的文字是什麼,這樣就能模擬「看到」螢幕上的信息,並在理解和解析螢幕上的指涉時提供必要的上下文資訊。這種方法是首次嘗試使用大型語言模型從螢幕內容中編碼上下文,克服了傳統文本模態難以處理的螢幕實體的問題。
具體來說,ReALM系統為了讓大型語言模型能夠「理解」並處理螢幕上顯示的實體,採用了以下步驟:
首先,借助上層資料偵測器擷取螢幕文字中的實體,這些實體會帶有類型、邊界框以及實體周圍非實體文字元素的清單。這意味著,對於螢幕上每一個可視化的實體,系統都會捕捉其基本資訊和它所處的上下文環境。
然後,ReALM創新地提出了一種演算法,透過將實體及其周圍物件的邊界框中心點按照垂直(從上至下)和水平(從左到右)的順序排序,並穩定排列。若實體間距較近,則認為它們在同一行內,並用製表符隔開;若距離超出設定的邊距,則將它們置於下一行。這樣,透過連續應用上述方法,就可以將螢幕內容按從左到右、從上到下的方式編碼成純文字格式,有效地保留了實體間的相對空間位置關係。
這樣一來,原本難以直接被LLM處理的螢幕視覺訊息轉化成了適合語言模型輸入的文字形式,使LLM能夠在處理序列到序列的任務時,充分考慮到了螢幕實體的具體位置和上下文,從而實現對螢幕實體的正確識別和指涉解析。
這使得ReALM系統不僅在解決對話實體的指稱問題上表現出色,而且在處理非對話類實體——即螢幕上的實體時同樣表現出了顯著的性能提升。
三、細節:任務定義與資料集
簡單來,ReALM系統面臨的任務是,根據使用者想要執行的任務,在給定的實體集合中,找出與目前使用者查詢相關的實體。
這個任務被建構成一個針對大型語言模型的選擇題,期望從使用者畫面展示的實體中選擇一個或多個選項作為答案。當然,在某些情況下,答案可能是「都不是」。
事實上,研究論文將任務涉及的實體分為三類:
#1. 螢幕實體:是指目前在使用者介面上可見的實體。
2. 對話實體:與對話內容相關的實體,可能來自用戶的上一輪發言(如用戶提到“呼叫媽媽”,則聯絡人列表中“媽媽”的條目就是相關實體) ,也可能由虛擬助理在對話中提供(如供使用者選擇的地點清單)。
3. 背景實體:源自於背景進程,不一定直接體現在使用者螢幕顯示或與虛擬助理互動中的相關實體,例如預設會響起的鬧鐘或正在後台播放的音樂。
至於用於訓練和測試ReALM的資料集,由合成資料和手動標註的資料組成,同樣可劃分為三類:
其一,對話資料集:包含了與使用者與代理程式互動相關的實體的資料點。這些資料透過讓評分員查看含有合成實體清單的截圖,並要求他們提供明確指向清單中任意選定實體的查詢來收集。
其二,合成數據集:採用模板生成法得到數據,特別是當用戶查詢和實體類型足以確定指代,無需依賴詳細描述時,這種方法特別有用。合成資料集中也可以包含多個實體對應相同查詢的情況。
其三,螢幕數據集:主要涵蓋了用戶螢幕上目前顯示的實體的數據,每一條數據都包含用戶查詢、實體列表以及與該查詢對應的正確實體(或實體集合)。每個實體的資訊包括實體類型和其他屬性,如名稱以及其他與實體相關的文字細節(例如,鬧鐘的標籤和時間)。
對於含有螢幕相關上下文的資料點,上下文資訊以實體的邊界框以及圍繞該實體的其他物件清單的形式提供,同時附帶這些週邊物件的類型、文字內容和位置等屬性資訊。整個資料集的大小依類別分為訓練集和測試集,並且各具一定規模。
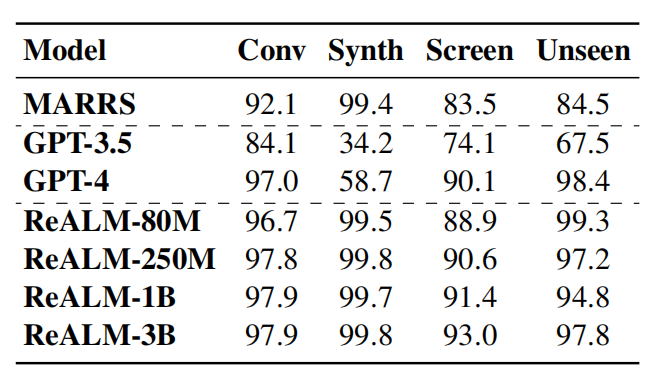
四、結果:最小的模型也取得了5%的效能提升
在基準測試中,蘋果公司將自家系統與GPT 3.5和GPT 4.0進行了比較。 ReALM模型在解決不同類型的指涉解析任務方面展現出卓越的競爭力。
 圖片
圖片
#根據論文所述,即使是ReALM中參數最少的版本,相較於基線系統也實現了超過5%的效能提升。而在更大的模型版本上,ReALM則明顯勝過GPT-4。特別是在處理螢幕上顯示的實體時,隨著模型規模的增加,ReALM在螢幕資料集上的效能提升更為顯著。
另外,ReALM模型在全新領域的零樣本學習場景上,其效能與GPT-4相當接近。而在處理特定領域的查詢時,由於經過使用者請求的微調,ReALM模型比GPT-4表現得更精準。
例如,對於要求調整亮度這樣的用戶請求,GPT-4僅將該請求關聯到設置,而忽略了背景中存在的智慧家庭設備也是相關實體,而ReALM因為接受了領域特有資料的訓練,能夠更好地理解並正確解析此類特定領域內的指涉問題。
「我們證明了ReaLM超越了以往的方法,並且儘管參數數量遠少於當前最先進的LLM——GPT-4,即使在純粹基於文本領域處理屏幕內在引用時,ReaLM也能達到與其相當的表現水準。此外,對於特定領域的使用者話語,ReaLM的表現還優於GPT-4,因此,ReaLM可以說是在保證性能不打折扣的同時,適用於開發方面實際應用環境、可在設備本地高效運行的指代解析系統的首選方案。”
#此外,研究人員還表示,在資源有限、需要低延遲響應或涉及多階段整合如API呼叫等實際應用場景中,單一的大型端對端模型往往並不適用。
在這種背景下,模組化設計的ReALM系統更具優勢,允許在不影響整體架構的情況下,輕鬆替換和升級原有的指涉解析模組,同時提供更好的優化潛力和可解釋性。
#面向未來,研究方向則指向了更複雜的方法,例如將螢幕區域劃分為網格並以文字形式編碼空間相對位置,雖然頗具挑戰性,但這是一種有前景的探索途徑。
五、寫在最後
在人工智慧領域,蘋果雖然一直比較謹慎,但也在默默投入。無論是多模態大模型MM1,還是AI驅動的動畫生成工具Keyframer,再到現今的ReALM,蘋果的研究團隊一直持續實現技術突破。
圍觀Google、微軟、亞馬遜等競爭對手,紛紛在搜尋、雲端服務、辦公室軟體上加碼AI,秀了一波又一波肌肉。蘋果顯然正努力不落人後。隨著生成式AI落地成果不斷湧現,蘋果更是加快了追趕的腳步。早有知情人士透露,在6月舉辦的全球開發者大會上,蘋果將聚焦於人工智慧領域,新的人工智慧策略極有可能成為iOS 18升級的核心內容。屆時,說不定會帶給諸君驚喜。
參考連結:
https://apple.slashdot.org/story/24/04/01/1959205/apple-ai-researchers-boast-useful -on-device-model-that-substantially-outperforms-gpt-4
https://arxiv.org/pdf/2403.20329.pdf
以上是讓Siri不再智障!蘋果定義新的端側模型,「大大優於GPT-4,擺脫文本,可視化模擬螢幕訊息,最小參數模型相較基線系統仍提升5%的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap 圖片居中方法多樣,不一定要用 Flexbox。如果僅需水平居中,text-center 類即可;若需垂直或多元素居中,Flexbox 或 Grid 更合適。 Flexbox 兼容性較差且可能增加複雜度,Grid 則更強大且學習成本較高。選擇方法時應權衡利弊,並根據需求和偏好選擇最適合的方法。
 c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
C35 的計算本質上是組合數學,代表從 5 個元素中選擇 3 個的組合數,其計算公式為 C53 = 5! / (3! * 2!),可通過循環避免直接計算階乘以提高效率和避免溢出。另外,理解組合的本質和掌握高效的計算方法對於解決概率統計、密碼學、算法設計等領域的許多問題至關重要。
 網頁批註如何實現Y軸位置的自適應佈局?
Apr 04, 2025 pm 11:30 PM
網頁批註如何實現Y軸位置的自適應佈局?
Apr 04, 2025 pm 11:30 PM
網頁批註功能的Y軸位置自適應算法本文將探討如何實現類似Word文檔的批註功能,特別是如何處理批註之間的間�...
 wordpress文章列表怎麼調
Apr 20, 2025 am 10:48 AM
wordpress文章列表怎麼調
Apr 20, 2025 am 10:48 AM
有四種方法可以調整 WordPress 文章列表:使用主題選項、使用插件(如 Post Types Order、WP Post List、Boxy Stuff)、使用代碼(在 functions.php 文件中添加設置)或直接修改 WordPress 數據庫。
 Bootstrap如何讓圖片在容器中居中
Apr 07, 2025 am 09:12 AM
Bootstrap如何讓圖片在容器中居中
Apr 07, 2025 am 09:12 AM
綜述:使用 Bootstrap 居中圖片有多種方法。基本方法:使用 mx-auto 類水平居中。使用 img-fluid 類自適應父容器。使用 d-block 類將圖片設置為塊級元素(垂直居中)。高級方法:Flexbox 佈局:使用 justify-content-center 和 align-items-center 屬性。 Grid 佈局:使用 place-items: center 屬性。最佳實踐:避免不必要的嵌套和样式。選擇適合項目的最佳方法。注重代碼的可維護性,避免犧牲代碼質量來追求炫技

 如何讓Element UI中同一行相鄰列的高度自動適應內容?
Apr 05, 2025 am 06:12 AM
如何讓Element UI中同一行相鄰列的高度自動適應內容?
Apr 05, 2025 am 06:12 AM
如何讓同一行相鄰列的高度自動適應內容?在網頁設計中,我們經常會遇到這樣的問題:當一個表格或行內的多...
 distinct函數用法 distance函數c 用法教程
Apr 03, 2025 pm 10:27 PM
distinct函數用法 distance函數c 用法教程
Apr 03, 2025 pm 10:27 PM
std::unique 去除容器中的相鄰重複元素,並將它們移到末尾,返回指向第一個重複元素的迭代器。 std::distance 計算兩個迭代器之間的距離,即它們指向的元素個數。這兩個函數對於優化代碼和提升效率很有用,但也需要注意一些陷阱,例如:std::unique 只處理相鄰的重複元素。 std::distance 在處理非隨機訪問迭代器時效率較低。通過掌握這些特性和最佳實踐,你可以充分發揮這兩個函數的威力。
