

快手強化學習與多工推薦

一、Two-Stage Constrained Actor-Critic for Short Video Recommendation
第一篇工作是快手自研的,主要針對的是帶約束的多任務場景。
1. 短片多工推薦場景

#這篇工作主要針對的是短影片的一個比較專業化的場景,多任務的使用者回饋分為觀看時間長度和互動,比較常見的互動包括按讚、收藏、追蹤還有評論,這些回饋各有特色。我們透過線上系統觀察發現,時長訊號其實非常稀疏,而且因為它是連續值,難以精確度量使用者的興趣程度。相較之下,互動訊號更加豐富,包括讚、藏、關注以及評論,這些回饋可以分為觀眾的喜好和行為回饋兩類。我們在優化過程中,把這個訊號當作主要目標,互動作為輔助優化,盡量確保互動的訊號不會損失,作為優化的整體目標。相較之下,互動號碼更加稀疏,同時因為沒有統一的標準,難以精確度量使用者的興趣程度。為了提高效果,我們需要進行一定的最佳化,使得在我們的系統中將其作為主要目標來進行最佳化,同時確保互動資料的完整性,作為整體目標的輔助。

這樣就可以非常直觀地將問題描述成一個帶有約束的最佳化問題,有一個主目標標utility的最佳化,輔助目標是滿足一個下界即可。有別於常見的Pareto優化問題,這裡是需要分主次的。
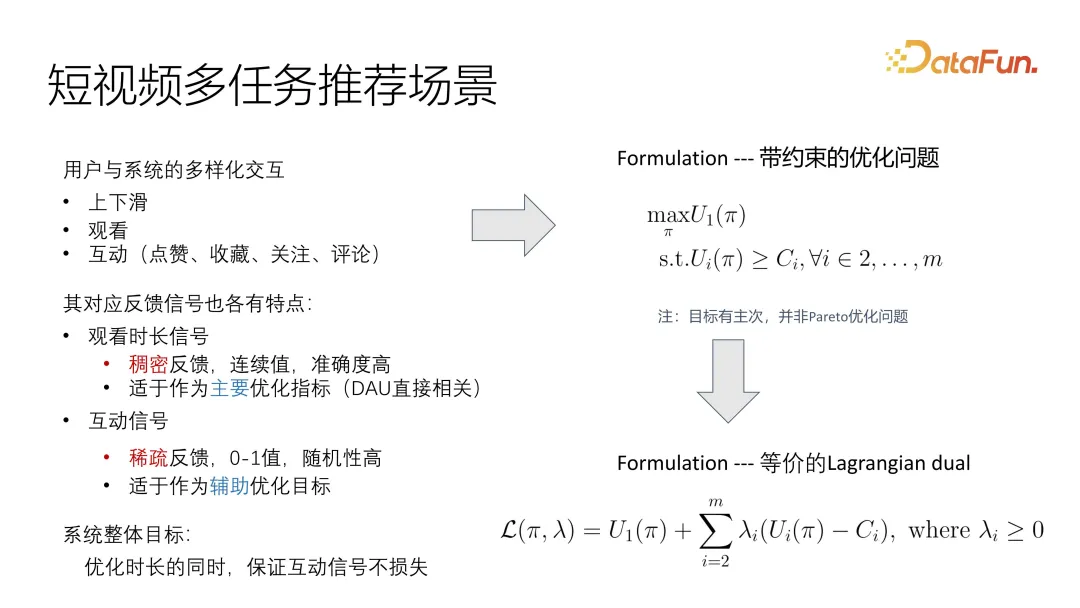
解決這個問題的一個常用手段,就是把它轉換成拉格朗日對偶問題,這樣就可以直接合到一個最佳化的目標函數裡面,無論是整體最佳化或交替最佳化,可以成一個整體目標來進行最佳化。當然,需要控制不同目標的相關性以及影響因子。
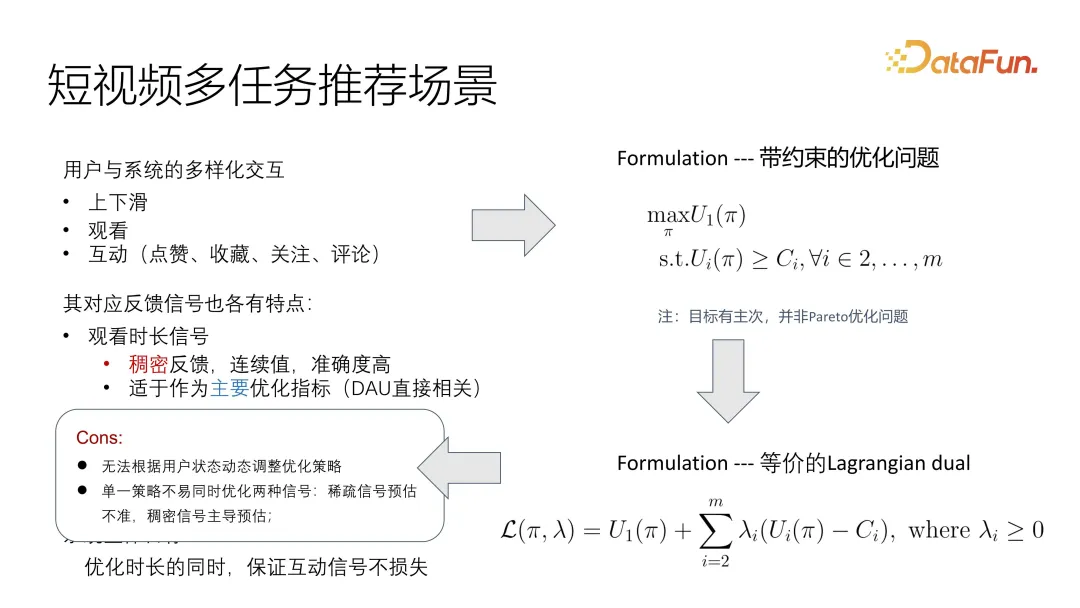
這種觀察的發展仍存在一些問題,因為使用者狀態動態變化,使得它在短影片場景下,變化速度非常快。另外因為訊號不統一,尤其是主要目標最佳化和紺疏的輔助目標最佳化有非常不一致的分佈問題,現有的解決方案很難處理。如果把它統一到一個目標function,其中一個訊號就可能dominate另外一個訊號。
2. Multi-task Reinforcement Learning
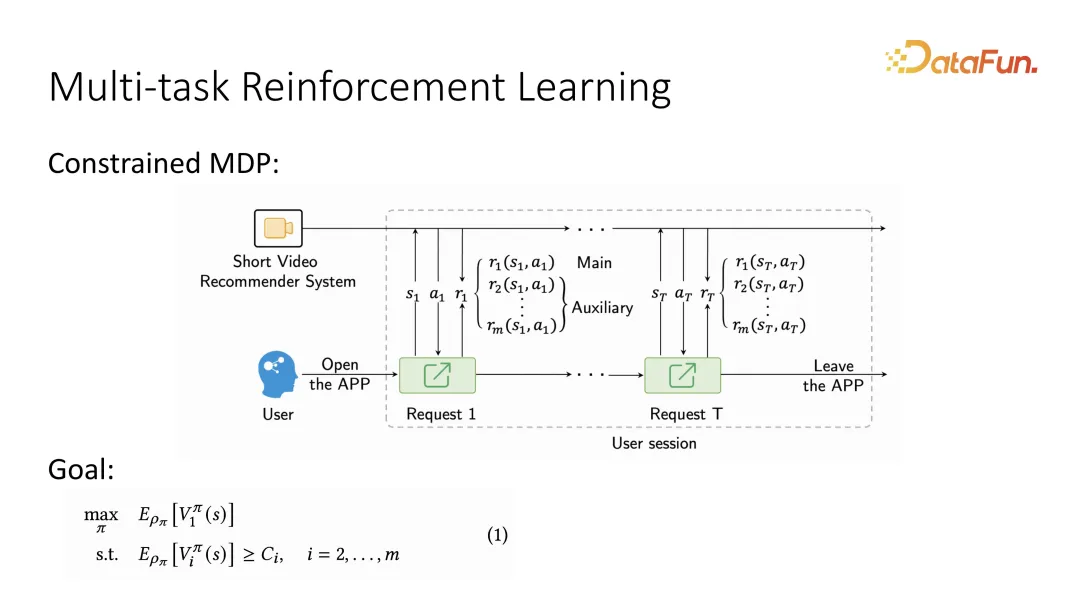
基於第一點,考慮使用者的動態變化問題常被描述成MDP,也就是使用者與系統的交替互動的sequence,而這個sequence 描述成Markov Decision Process 之後就可以使用強化學習的手段來求解。具體地,在描述成 Markov Decision Process 之後,因為同時還需要區分主要目標和輔助目標,所以需要額外聲明一下,在用戶反饋時,要區分兩種不同目標,此外輔助目標也可能有多個。強化學習在定義長期最佳化目標時,會將要最佳化的主目標定義成長期價值函數,稱為 value function。同樣對於輔助目標,也會有對應的 value function。相當於每個使用者的回饋,都會有長期價值評估,比起之前做 utility function,現在變成了一個長期價值的 value function。
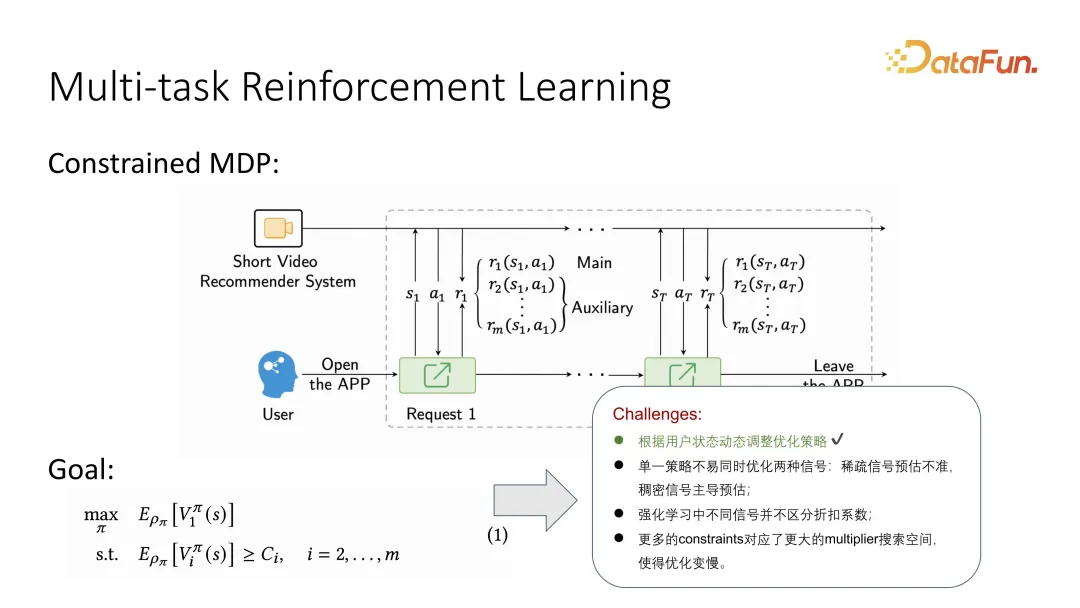
同樣地,結合強化學習時會產生一些新的問題,例如強化學習如何區分不同的折扣係數。另外,因為引入了更多的 constraints,參數的搜尋空間也變得更大,強化學習將變得更困難。
3. Solution: Two-Stage Multi-Critic Optimization

這篇工作的解決方案是把整個最佳化分成兩個階段,第一個階段優化輔助目標,第二個階段優化主要目標。
在第一階段輔助目標最佳化時,採取了典型的actor critic 最佳化方式,針對例如按讚和關注等輔助目標的最佳化,分別優化一個critic,用來預估目前state 的優劣。長期價值預估準確之後,再去優化 actor 時就可以使用 value function 來引導它的學習。公式(2)是 critic 的最佳化,公式(3)是 actor 的最佳化,針對 critic 的最佳化,在訓練時會用到目前的 state 和下一步的 state 以及目前 action 的取樣。根據 Bellman equation 可以得到 action,再加上未來的 state 的 value 預估,應該趨近於當前 state 的預估,這樣去優化就可以逐漸逼近準確的長期價值預估。在引導 actor 學習,也就是推薦策略學習時,會採用一個 advantage function。 Advantage function 就是當採用某個 action 之後,其效果是否比平均預估更強,這個平均預估叫做 baseline。 Advantage 越大,表示 action 越好,採用這個推薦策略的機率就會越大。這是第一階段,輔助目標的最佳化。

第二階段是最佳化主要目標,我們採用的是長度。輔助目標在約束主要目標時,採用了近似的策略,我們希望主要目標輸出的 action 分佈盡可能接近不同的輔助目標,只要不斷接近輔助目標,輔助目標的結果應該就不會太差。在得到近似的 formulation 之後,透過 completion of square 可以得到一個閉式解,即加權的方式。整個主要目標的 actor critic 的最佳化方式,在 critic 層面和 value function 估計層面上,其實也沒有太大差別。但在 actor 時,我們引入了透過閉式解得到的權重。此權重的意義是,某個輔助策略 I 對應的影響因子越大,它對整體權重的影響也越大。我們希望策略輸出的分佈盡可能接近所有輔助目標策略的平均值,而得出來的閉式解的 behavior 時會有這樣的現象。
4. Experiments
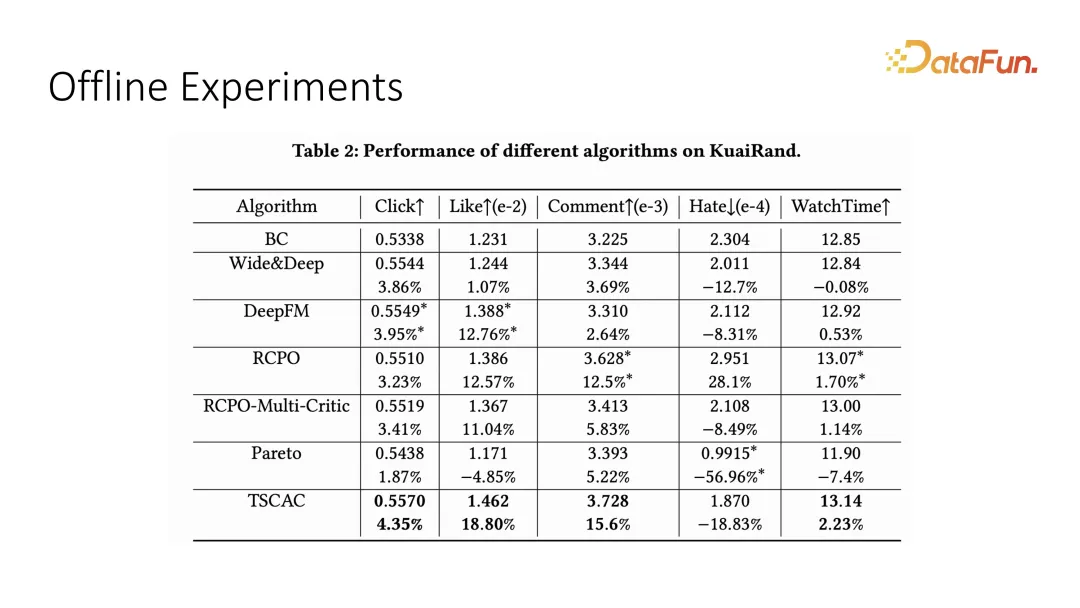
#我們在offline 的資料集上測試了多目標最佳化的效果,這裡的主要目標是watch time 即觀看時長,輔助目標是click、like、comment 和hate 等互動指標。可以看到我們提出的 two-stage 的 actor-critic 能夠得到最佳效果。
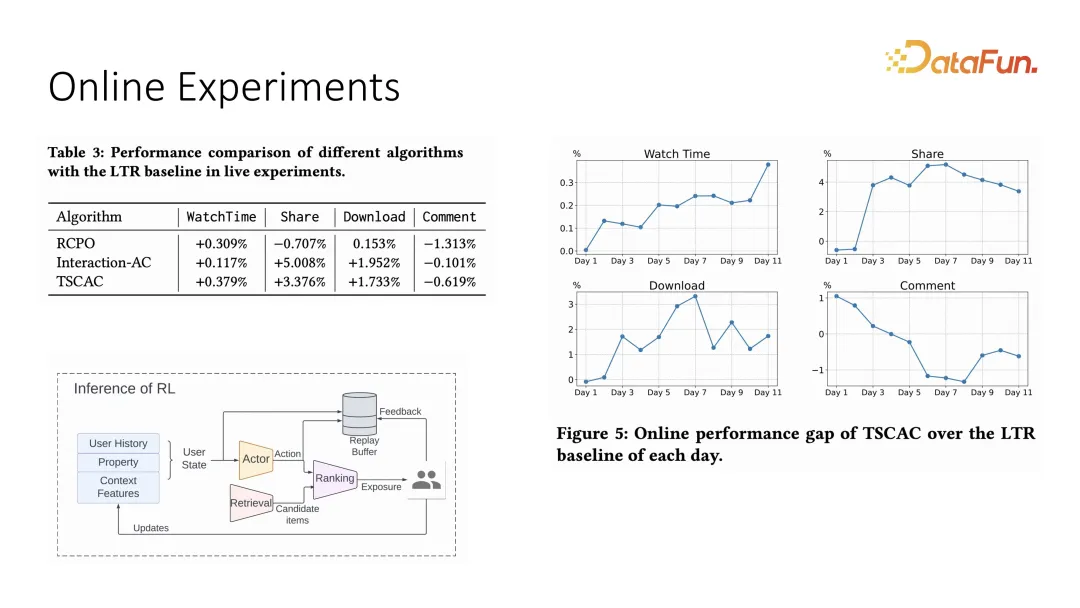
同樣我們也在線上系統做了相應的對比實驗,線上系統的設定採用了actor 加ranking 的推薦模式,這裡的action 是權重,最終的ranking 是由每一個item 和權重做內積所得的結果。線上實驗也可以看到,watch time 能夠在提升的同時對其它互動有約束效果,相較於先前的最佳化策略,它能夠更好地約束互動指標。
以上就是第一篇工作的介紹。
二、Multi-Task Recommendations with Reinforcement Learning
第二個工作同樣也是強化學習在多任務優化的應用,只不過這是比較傳統的優化。這篇工作是快手和港城大的合作項目,一作是 Liu Ziru。
1. Background and Motivation
#這篇工作主要討論的問題是典型的多任務聯合訓練,其挑戰是需要平衡不同任務之間的係數,傳統的MTL 的解決方案一般會考慮線性組合方式,且會忽略session 維度,即長期的動態變化。這篇工作提出的 RMTL 透過長期的預估來改變加權方式。
2. Problem Formulation
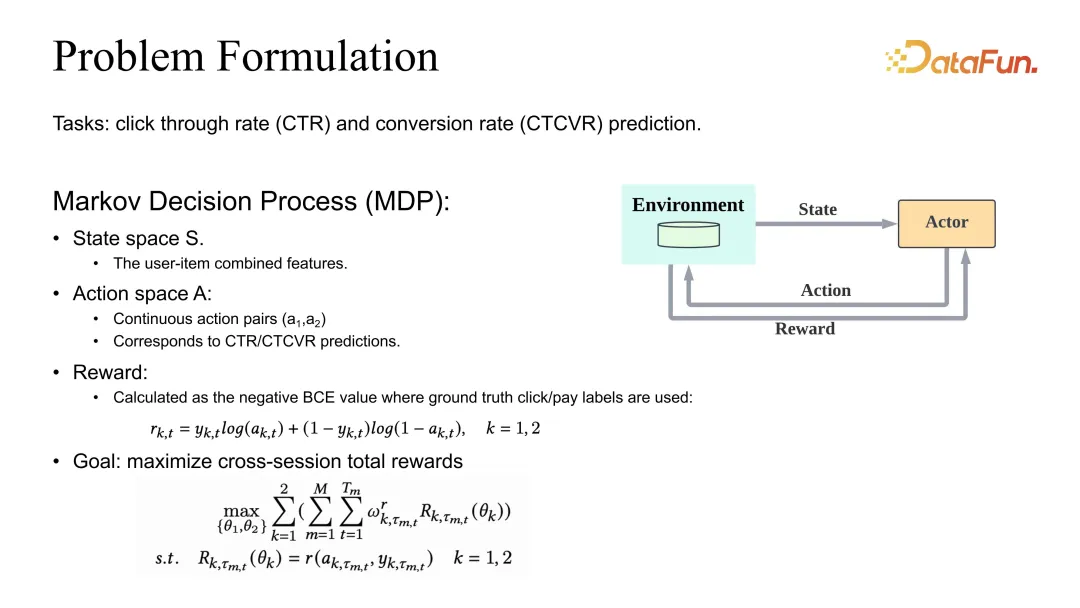
問題設定是定義 CTR 和 CVR 的預估的聯合最佳化。同樣我們也有一個 MDP(Markov Decision Process)的定義,但這裡 action 不再是推薦列表,而是對應的 CTR 和 CVR 預估。如果要預估準確,reward 就應該定義為 BCE 或對應的任何一個合理的 loss。在整體的目標定義上,一般情況下會定義成不同的任務加權之後再對整個 session 以及所有的 data sample 進行求和。
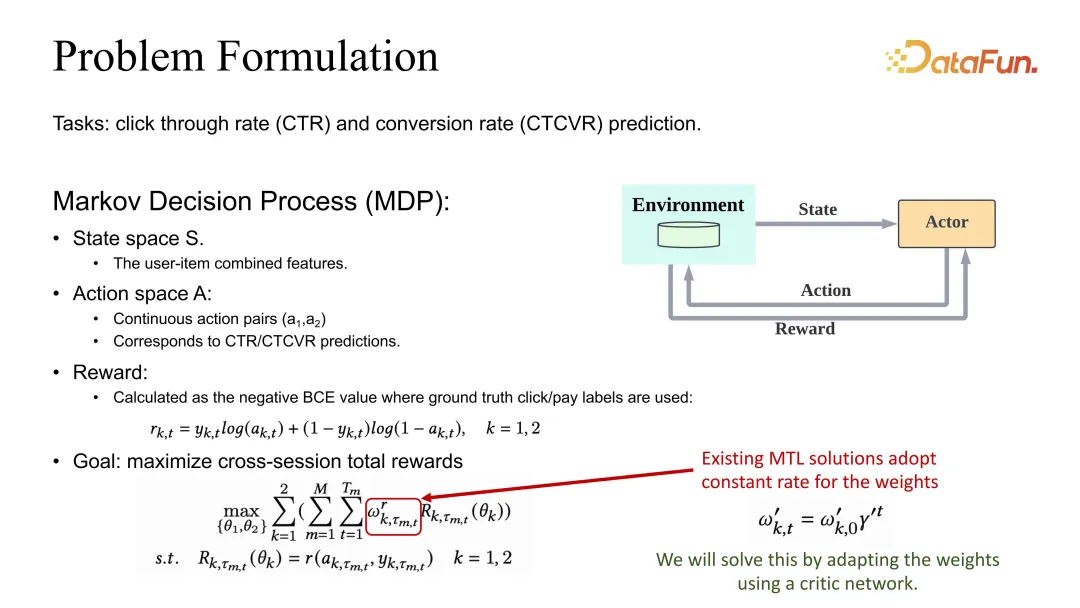
可以看到,它的權重係數除了 Gamma 的 discount 之外,還會受到一個需要調整的係數的影響。
3. Solution Framework
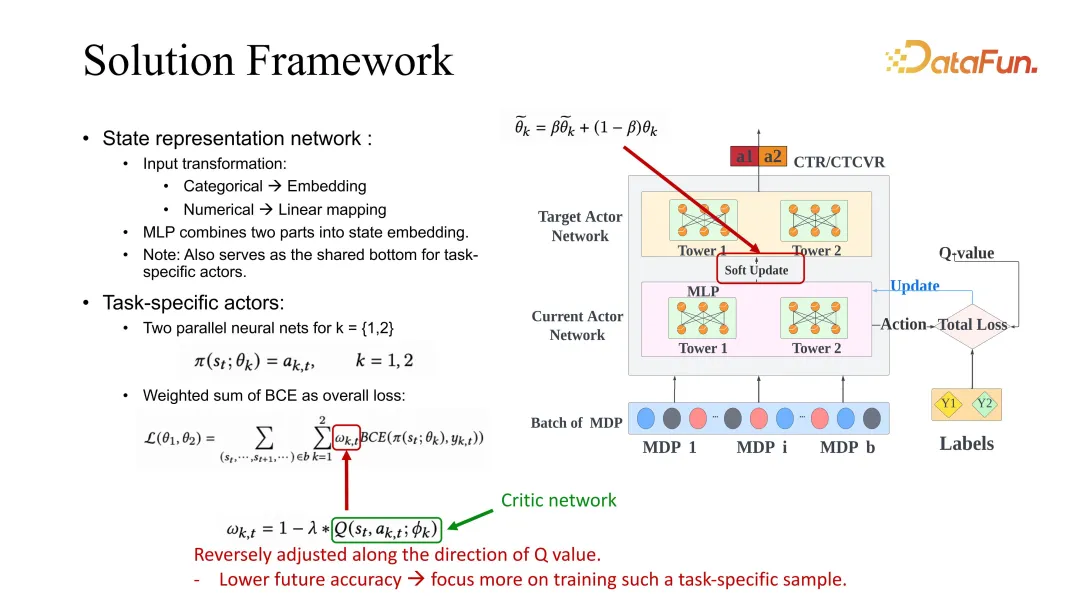
#我們的解決方案是讓這個係數的調整和 session 維度的預估相關。這裡給了一個 ESMM 的 backbone,當然其它 baseline 的使用也是通用的,都可以用我們的方法來改進。
下面詳細介紹ESMM,首先有一個task specific 的actor,對每個任務都會有一個target 和current actor 的優化,優化時用到了類似之前提到的actor critic 的framework。在優化過程中,BCE loss 在引導 actor 學習時,需要對 task specific 的權重進行調整。在我們的解決方案裡,這個權重需要根據未來的價值評估進行相應的更改。該設定的意思是,如果未來的評估價值較高,說明當前 state 和當前 action 是比較準確的,對它的學習就可以放慢。相反,如果對未來的預估較差,說明該模型對 state 和 action 的未來並不看好,就應該增加它的學習,weight 採用這種方式進行了調整。這裡的未來評估同樣採用前文提到的 critic network 進行學習。
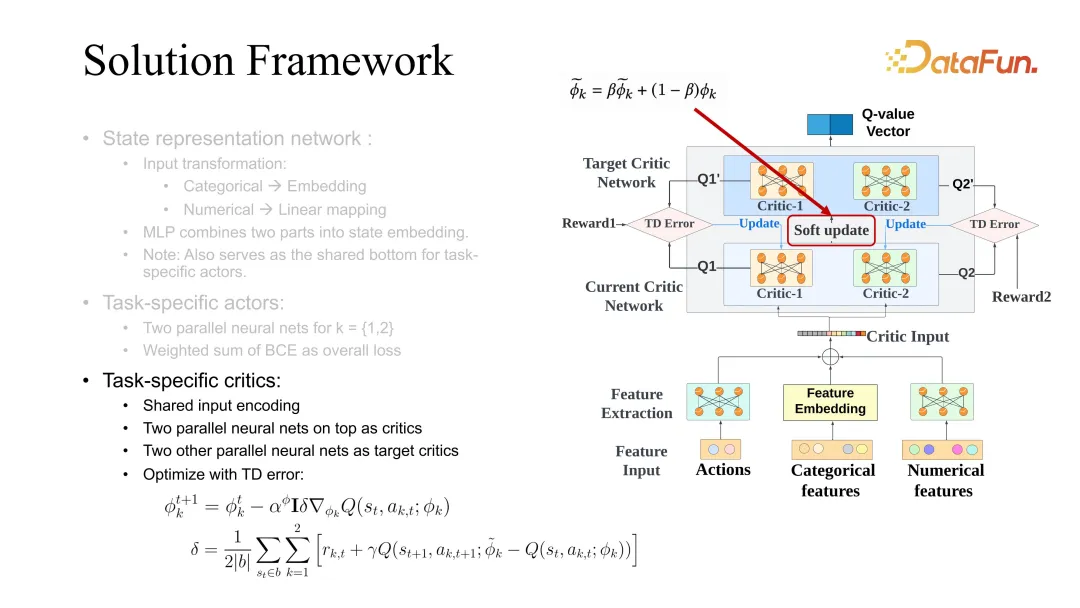
critic 的學習也同樣採用未來state 和目前state 的差異,但區別於value function,這裡差值的學習採用的是Q function,需要用到state 和action 的聯合評估。在做 actor 更新時,也要同時使用不同 task 對應的 actor 的學習。這裡 soft update 是一個通用的 trick,在增加 RL 學習穩定性的時候比較有用,一般會同時優化 target 和目前的 critic。
4. Experiment
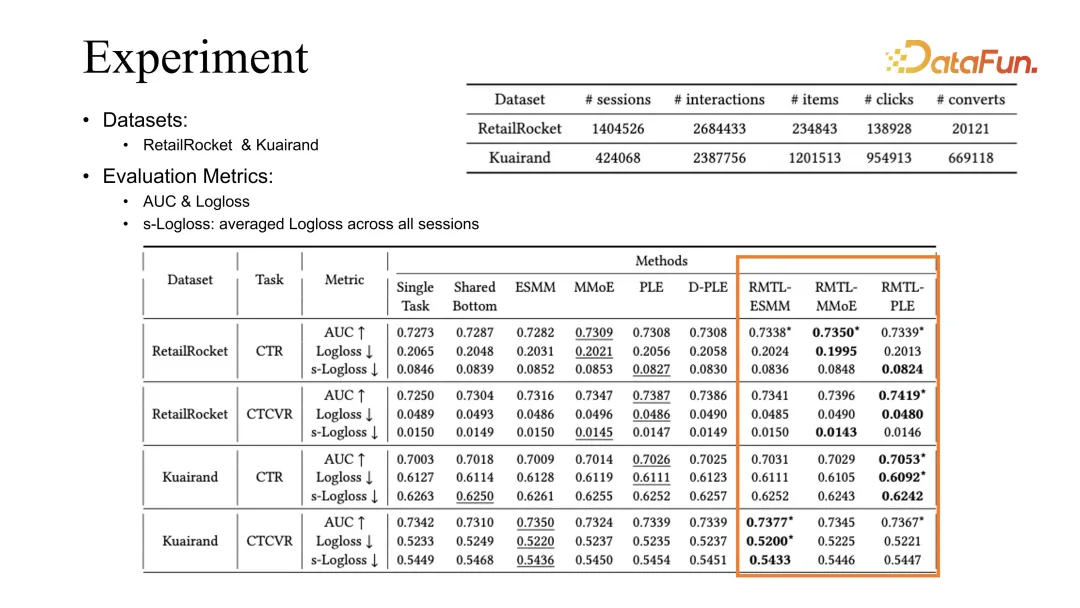
#透過兩個公開資料集的比較實驗,可以看出,我們的方法可以結合現有的最佳化方式包括ESMM、MMoE 以及PLE,得到的效果都能夠對先前的baseline 有所提升。
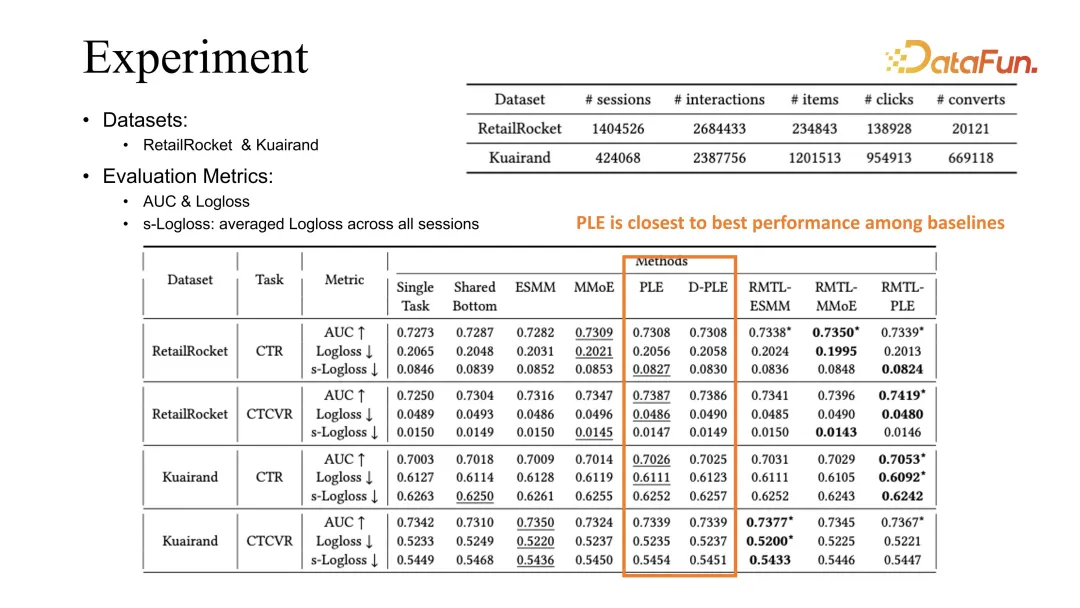
PLE 在我們的觀測中是最好的baseline,我們根據觀測現象的歸因是在學習不同task 時,PLE 能夠更好地學習到shared embedding。
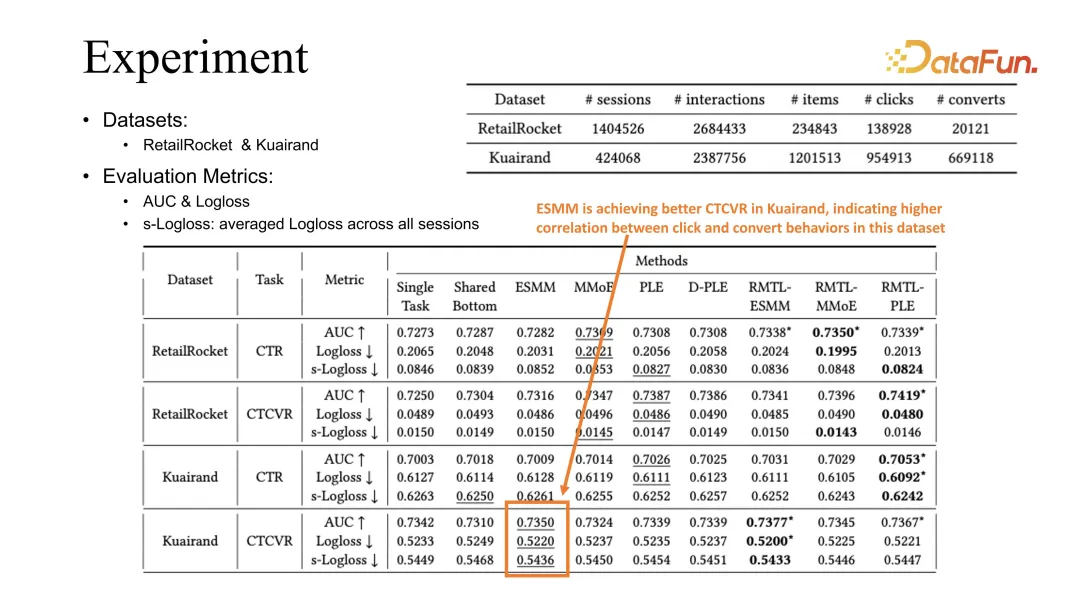
相比之下,ESMM 在 Kuairand task 上面可以達到更好的 CVR 的評估。我們推測這與 click 和 conversion 在這個 dataset 裡更強的相關性有關。
#5. Transferability Study
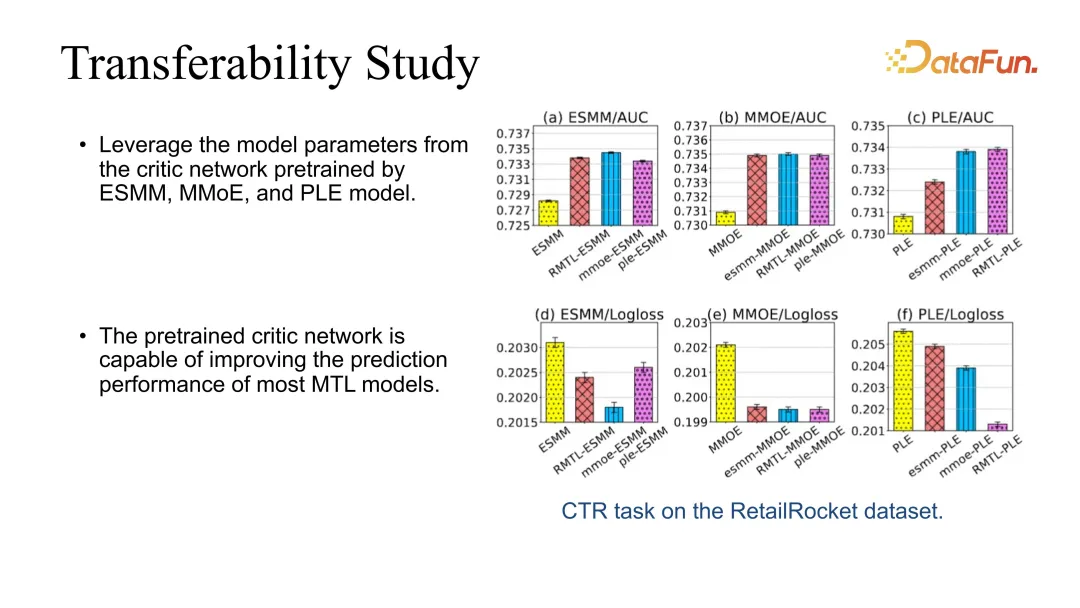
#除此之外我們也做了transferability 的test,因為我們的critic 是可以直接嫁接到其他模型上的。例如可以透過最基本的 RMTL 學習 actor critic,然後用 critic 直接去提升其他模型的效果。我們發現,嫁接時都能夠穩定提升效果。
6. Ablation Study
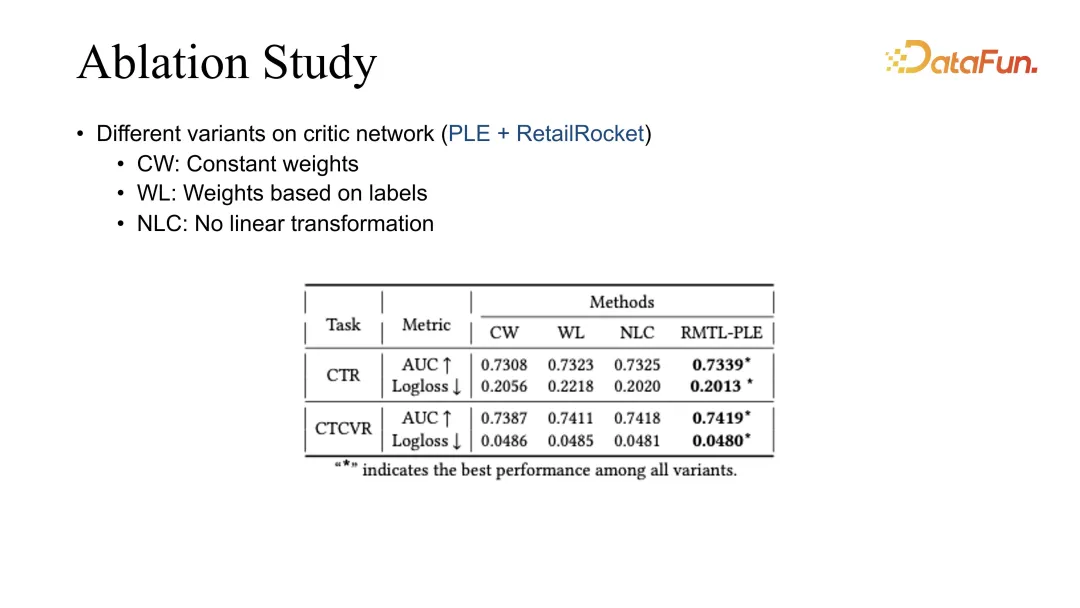
最後我們做了 ablation study,對不同的加權方式進行了對比,目前最好的效果都是由我們的 RMTL 得出來的。
三、Conclusion
最後總結 RL 和 MTL 的一些經驗。

我們發現推薦系統在長期最佳化時,尤其是在長期優化複雜指標時,是非常典型的強化學習和多任務最佳化的場景。如果是主副目標聯合最佳化,可以透過 soft regularization 去約束主要目標學習。多目標聯合優化時,如果考慮不同目標的動態變化,也能夠提升其最佳化效果。
除此之外也存在一些挑戰,例如在強化學習不同模組結合時,會對系統的穩定性帶來許多挑戰。我們的經驗是,對資料品質的把控、label 的準確性的把控和模型預估準確率的監督是非常重要的途徑。除此之外,由於推薦系統和使用者是直接互動的,不同目標僅能片面反映使用者體驗,所以得到的推薦策略也會非常不同。如何在不斷變化的使用者狀態下,聯合優化全面提升使用者體驗,未來將會是一個非常重要的課題。
四、Q&A
Q1:快手的長度訊號和互動訊號一般用的是什麼loss,是分類還是回歸,互動目標和觀看目標離線評估一般看哪些指標?
A1:時長指標是典型的迴歸任務。但我們同樣也注意到,時長預估是和影片本身的長度強相關的,例如短影片和長影片的分佈會非常不一樣,所以在預估時會先對它做分類處理,然後再做regression 。最近我們在 KDD 也有工作,講用樹方法分割時長訊號預估的方法,如果大家有興趣可以關注。大概意思是,例如把時長分成長視頻和短視頻,長視頻預估會有一個預估的範圍,短視頻會有一個短視頻的預估範圍。也可以用樹方法進行更細緻的下分,長視頻可以分成中視頻和長視頻,短視頻也可以分成超短視頻和短視頻。當然也有純用分類方法解決時長預估的,我們也有做測試。整體效果上來看,目前還是在分類的框架下,再做 regression,效果會稍微好一點。其他的互動的指標預估,一般和現有的預估方法差不多。離線評估時,一般 AUC 和 GAUC 是比較強的訊號,目前看這兩個訊號還是比較準確的。
Q2:迴歸類別的例如時長指標離線看什麼指標?
A2:我們的系統主要看的是 online 的指標,離線一般是用 MAE 和 RMSE。但我們同樣看到離線和線上的評估也存在差異,如果離線評估沒有比較明顯的提升,那線上也不一定能看到對應的提升效果,它的實際對應關係在沒有達到一定顯著性的時候,差別不會太大。
Q3:類似轉送等比較稀疏的目標,建模上有沒有方法可以使其估得更準?
A3:使用者轉送的理由分析,做一些觀測等可能會有比較好的成效。目前我們在做轉送預估的時候,在我們的連結下做和其他的互動目標的預估方式差距不太大。有個比較通用的思路,就是 label 的定義尤其是負回饋訊號的定義,會非常大程度上影響模型訓練準確度。除此之外就是資料來源的最佳化,資料和線上的分佈是否有偏,也會影響到預估準確率,所以我們很多工作也在做消偏。因為在推薦場景下,許多預估的指標其實是間接的訊號,它在下一步才會影響到推薦效果。所以以推薦效果為主導去優化指標,就是我們這邊的應用程式場景。
Q4:快手這邊這個多目標融合是怎麼做的?是強化學習調參嗎?
A4:在多目標融合時,一開始有一些 heuristic 的方法,一些手調的參數平衡的方法。後面逐漸開始使用調參方式,強化學習調參也嘗試過。目前的經驗是自動化調參比手調好一些,它的上限稍微高一些。
Q5:假如線上資料或是要調的某個目標本身特別稀疏,如果基於線上資料調參,回饋週期或觀察置信需要比較久,這樣調參效率會不會比較低,這種情況下有什麼解決方法?
A5:我們最近也有一些工作討論極度稀疏、甚至幾天才有回饋的這種訊號。其中最典型的一個訊號就是使用者的留存,因為使用者可能離開之後幾天才會回來,這樣我們拿到訊號時,模型已經更新好幾天了。解決這些問題有一些折中方案,一個解決方案是可以去分析即時的回饋訊號有哪些和這種極為稀疏的訊號有一定的相關性。透過優化這些即時的訊號採用組合方式去間接優化長期訊號。以剛才的留存作為例子,在我們的系統中,我們發現用戶的留存和用戶實時的觀看時長存在非常強的正相關,用戶觀看時長就代表用戶對系統的粘度,這樣基本上能夠保證用戶留存的下界。我們優化留存時,一般會使用優化時長組合一些其他相關指標去優化留存。只要是我們分析發現和留存有一定相關性的,都可以引入進來。
Q6:有沒有試過其他的強化學習方法,actor critic 有什麼優勢,為什麼要用這種方式?
A6:Actor critic 是我們迭代了幾次之後的結果,之前也試過DQN 和Reinforce 等稍微直觀的方法,有的在一些場景下確實會有效果,但目前actor critic 是一個相對穩定且好調試的方法。舉個例子,例如用 Reinforce 需要用到長期訊號,而長期的 trajectory 訊號波動性比較大,想提升它的穩定性會是比較困難的問題。但 actor critic 的一個優點是可以根據單步驟訊號進行最佳化,這是非常符合推薦系統的一個特性。我們希望每個使用者的回饋都能作為一個 training sample 去學習,對應的 actor critic 和 DDPG 方法會非常符合我們系統的設定。
Q7:快手多目標融合用強化學習方法時,一般會使用哪些 user 特徵,是否存在一些很精細的特徵例如 user id 導致模型收斂困難,怎麼解決這個問題?
A7:user id 其實還好,因為我們 user 側的特徵還是會用到各種各樣的特徵的。 user 除了有 id 特徵以外,還會有一些統計特徵。除此之外在推薦鏈路上,因為RL 在我們應用的模組處於比較靠後的階段,例如精排和重排,在前面的一些階段也會給出預估還有模型的排序訊號,這些實際上都有用戶的訊號在裡面。所以強化學習在建議的場景下拿到的 user 側的訊號還是很多的,基本上不會出現只用一個 user id 的情況。
Q8:所以也用了 user id,不過暫時還沒有出現收斂困難的問題,對吧?
A8:對的,而且我們發現如果不用 user id,對個人化影響還挺大的。如果只用一些使用者的統計特徵,有的時候不如一個 user id 的提升效果大。確實 user id 的影響比較大,但如果讓它的影響佔比太大,會有波動性的問題。
Q9:有些公司的某些業務中,使用者的行為資料可能比較少,是否也會遇到如果用user id 就不好收斂這個問題,如果遇到類似問題,有什麼解決方案?
A9:這個問題偏向user cold start,偏cold start 場景下在推薦鏈路一般會用補全或自動化feature 填充,先把它假設成一個默認user,可能會在一定程度上解決這個問題。後面隨著 user 和系統不斷互動、session 不斷充實,實際上可以拿到一定的使用者回饋,會逐漸訓的越來越準。確保穩定性方面,基本上只要控制好不讓一個 user id 去 dominate 訓練,還是能很好地提升系統效果的。
Q10:前面提到的對時長目標建模先做分類再做回歸,具體是時長先做分桶,分完桶再回歸嗎?這種方式還是不是無偏估計?
A10:那篇工作是直接去做分桶,然後用每一個分桶到達的機率去聯合評估時長,不是分桶之後再做 regression。它只用分桶的機率,再加上分桶的值去做整體的帶機率的評估。分桶之後再 regression 應該確實不再是無偏的,畢竟每一個分桶還是有它自己的分佈規律的。
Q11:剛才老師提到一個問題,對於兩個目標 a 和 b,我們的主目標是 a,對 b 的要求就是不降就行。我們實際場景中可能還存在 a 是主目標,對 b 沒任何限制的場景。例如,把 CTR 目標跟 CVR 目標一起優化,但模型本身就是一個 CVR 模型,我們只專注在 CVR 的效果,不關心 CTR 效果會不會變差,我們只是希望 CTR 盡可能地幫助到 CVR。類似這種場景,如果想把它們放在一起聯合訓練,是否有解決方法?
A11:這其實已經不再是多目標優化了,CTR 的指標甚至都可以直接作為一個輸入去優化 CPR,因為 CTR 不再是優化目標了。但這樣可能對使用者不太好,因為使用者的 CTR 更大程度上代表了對系統的喜好程度和黏性。不過不同系統可能也有所差別,這取決於推薦系統是以賣商品還是以流量為主。由於快手短影片這種是以流量為主的,所以說用戶 CTR 是一個更直覺、更主要的指標,CVR 只是流量引流之後的一個效果。
以上是快手強化學習與多工推薦的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 如何使用Go語言和Redis實現推薦系統
Oct 27, 2023 pm 12:54 PM
如何使用Go語言和Redis實現推薦系統
Oct 27, 2023 pm 12:54 PM
如何使用Go語言和Redis實現推薦系統推薦系統是現代網路平台中重要的一環,它幫助使用者發現和獲取感興趣的資訊。而Go語言和Redis是兩個非常流行的工具,它們在實現推薦系統的過程中能夠發揮重要作用。本文將介紹如何使用Go語言和Redis來實作一個簡單的推薦系統,並提供具體的程式碼範例。 Redis是一個開源的記憶體資料庫,它提供了鍵值對的儲存接口,並支援多種數據
 應用實例:使用go-micro 建置微服務推薦系統
Jun 18, 2023 pm 12:43 PM
應用實例:使用go-micro 建置微服務推薦系統
Jun 18, 2023 pm 12:43 PM
隨著網路應用的普及,微服務架構成為目前較受歡迎的架構方式。其中,微服務架構的關鍵在於將應用程式拆分為不同的服務,透過RPC方式進行通信,實現鬆散耦合的服務架構。在本文中,我們將結合實際案例,介紹如何使用go-micro建構一個微服務推薦系統。一、什麼是微服務推薦系統微服務推薦系統是一種基於微服務架構的推薦系統,它將推薦系統中的不同模組(如特徵工程、分類
 精準推薦的秘術:阿里解耦域適應無偏召回模型詳解
Jun 05, 2023 am 08:55 AM
精準推薦的秘術:阿里解耦域適應無偏召回模型詳解
Jun 05, 2023 am 08:55 AM
一、場景介紹首先來介紹本文涉及的場景—「有好貨」場景。它的位置是在淘寶首頁的四宮格,分為一跳精選頁和二跳承接頁。承接頁主要有兩種形式,一種是圖文的承接頁,另一種是短視頻的承接頁。這個場景的目標主要是為使用者提供滿意的好貨,帶動GMV的成長,從而進一步撬動達人的供給。二、流行度偏差是什麼,為什麼接下來進入本文的重點,流行度偏差。流行度偏差是什麼?為什麼會產生流行度偏差? 1.流行度偏差是什麼流行度偏差有很多別名,例如馬太效應、資訊繭房,直觀來講它是高爆品的狂歡,越熱門的商品,越容易曝光。這會導致
 利用Java實現的推薦系統演算法與應用
Jun 19, 2023 am 09:06 AM
利用Java實現的推薦系統演算法與應用
Jun 19, 2023 am 09:06 AM
隨著網路技術的不斷發展和普及,推薦系統作為一種重要的資訊過濾技術,越來越受到廣泛的應用和關注。在實作推薦系統演算法方面,Java作為一種快速、可靠的程式語言,已被廣泛應用。本文將介紹利用Java實現的推薦系統演算法和應用,並著重介紹三種常見的推薦系統演算法:基於使用者的協同過濾演算法、基於物品的協同過濾演算法和基於內容的推薦演算法。基於用戶的協同過濾演算法是基於用戶的協同過
 關於網易雲音樂冷啟動技術的推薦系統
Nov 14, 2023 am 08:14 AM
關於網易雲音樂冷啟動技術的推薦系統
Nov 14, 2023 am 08:14 AM
一、问题背景:冷启动建模的必要性和重要性作为一个内容平台,云音乐每天都会有大量的新内容上线。虽然相较于短视频等其他平台,云音乐平台的新内容数量相对较少,但实际数量可能远远超出大家的想象。同时,音乐内容与短视频、新闻、商品推荐又有着显著的不同。音乐的生命周期跨度极长,通常会以年为单位。有些歌曲可能在沉寂几个月、几年之后爆发,经典歌曲甚至可能经过十几年仍然有着极强的生命力。因此,对于音乐平台的推荐系统来说,发掘冷门、长尾的优质内容,并把它们推荐给合适的用户,相比其他类目的推荐显得更加重要冷门、长尾的
 Go語言如何實現雲端搜尋和推薦系統?
May 16, 2023 pm 11:21 PM
Go語言如何實現雲端搜尋和推薦系統?
May 16, 2023 pm 11:21 PM
隨著雲端運算技術的不斷發展和普及,雲端搜尋和推薦系統也越來越得到了人們的青睞。而針對這項需求,Go語言也提供了很好的解決方案。在Go語言中,我們可以利用其高速的並發處理能力和豐富的標準庫來實現一個高效的雲端搜尋和推薦系統。以下將介紹Go語言如何實現這樣的系統。一、雲上搜尋首先,我們需要對搜尋的姿勢和原理進行了解。搜尋姿勢指的是搜尋引擎根據使用者輸入的關鍵字來配對頁面
 因果糾偏法在螞蟻行銷推薦場景中的應用
Jan 13, 2024 pm 12:15 PM
因果糾偏法在螞蟻行銷推薦場景中的應用
Jan 13, 2024 pm 12:15 PM
一、因果糾偏的背景1、偏差的產生在推薦系統中,透過收集資料來訓練推薦模型,以向使用者推薦合適的物品。當使用者與推薦的物品互動時,收集的資料又會用於進一步訓練模型,形成一個閉環循環。然而,這個閉環中可能存在各種影響因素,導致誤差的產生。主要的誤差原因在於訓練模式所使用的數據大多是觀測數據,而非理想的訓練數據,受到曝光策略和使用者選擇等因素的影響。這種偏差的本質在於經驗風險估計的期望和真實理想風險估計的期望之間的差異。 2.常見的偏差推薦行銷系統裡面比較常見的偏差主要有以下三種:選擇性偏差:是由於使用者根
 PHP中的推薦系統與協同過濾技術
May 11, 2023 pm 12:21 PM
PHP中的推薦系統與協同過濾技術
May 11, 2023 pm 12:21 PM
隨著網路的快速發展,推薦系統變得越來越重要。推薦系統是一種用於預測使用者感興趣的物品的演算法。在網路應用程式中,推薦系統可以提供個人化建議和推薦,從而提高用戶滿意度和轉換率。 PHP是一種被廣泛應用於Web開發的程式語言。本文將探討PHP中的建議系統與協同過濾技術。推薦系統的原理推薦系統依賴機器學習演算法和資料分析,它透過對使用者歷史行為進行分析,預測
