AniPortrait 模型是開源的,可以自由暢玩。
近日,騰訊開源發布的一個新項目在推上獲得瞭如此評價。這個項目是 AniPortrait,可基於音訊和一張參考圖像生成高品質動畫人像。 話不說多,我們先來看看可能會被律師函警告的demo:
##動畫圖片也能輕鬆開口說話:
該專案剛上線幾天,就已經收穫了廣泛好評:GitHub Star 數已經突破2800。
下面我們來看看 AniPortrait 的創新之處。

- 論文標題:AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation
- #論文網址:https ://arxiv.org/pdf/2403.17694.pdf
- 程式碼位址:https://github.com/Zejun-Yang/AniPortrait
#騰訊新提出的AniPortrait 框架包含兩個模組:Audio2Lmk 和Lmk2Video。
Audio2Lmk 的作用是提取 Landmark 序列,其能從音訊輸入中捕捉複雜的面部表情和嘴唇動作。 Lmk2Video 是利用這種 Landmark 序列來產生時間上穩定一致的高品質人像影片。
圖 1 給出了 AniPortrait 框架的概況。
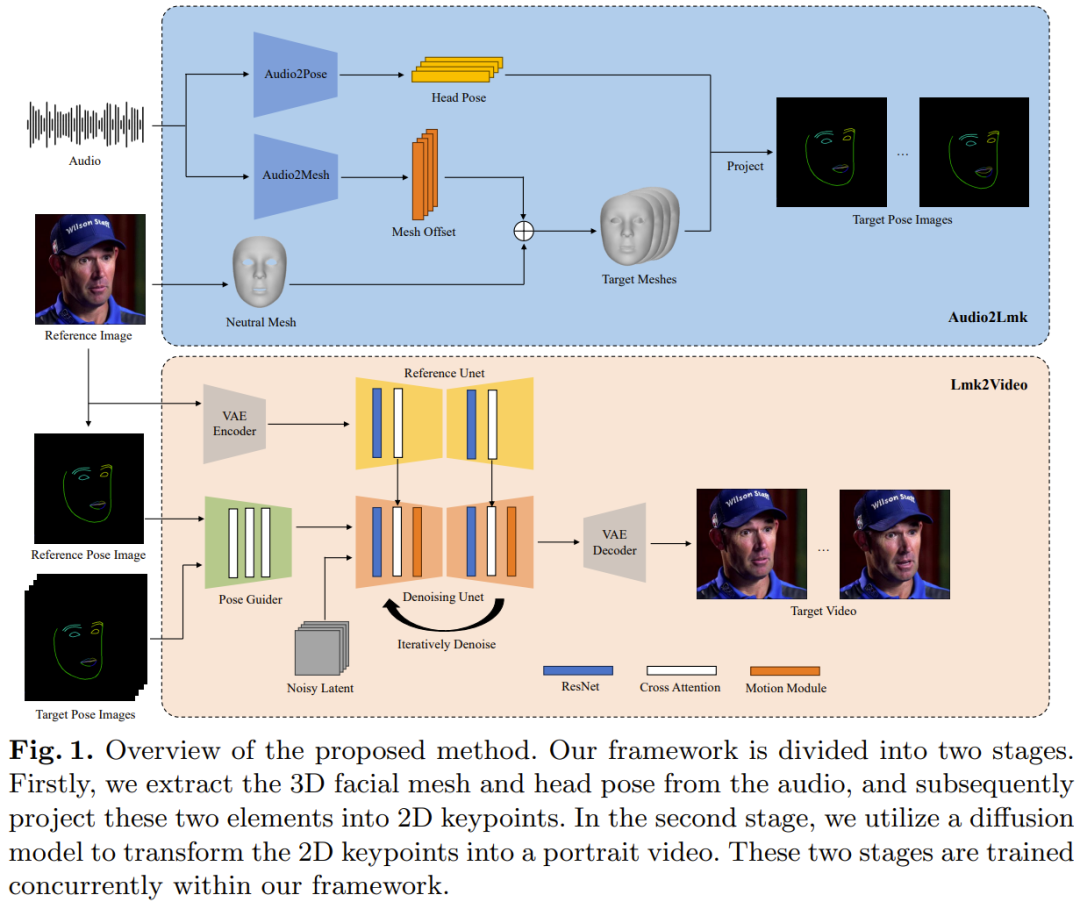 對於一段語音片段序列,這裡的目標是預測對應的 3D 人臉網格序列和姿勢序列。 該團隊採用了預先訓練的 wav2vec 來提取音訊特徵。該模型具有很好的泛化性能,並且可以準確識別音訊中的發音和語調 —— 這對產生具有真實感的人臉動畫至關重要。透過利用所獲得的魯棒的語音特徵,使用一種包含兩個 fc 層的簡單架構就可以有效地將它們轉換成 3D 人臉網格。團隊觀察到,這種簡單直接的設計不僅能確保準確度,還能提升推理過程的效率。 在將音訊轉換成姿勢的任務中,該團隊使用的骨幹網路依然是同樣的 wav2vec。但是,這一個網路的權重不同於音訊到網格模組的網路。這是因為:姿勢與音訊中的節奏和音調的關聯更加緊密,而音訊到網格任務關注的重點(發音和語調)卻不一樣。為了將先前狀態的影響納入考量,團隊採用了 transformer 解碼器來解碼姿勢序列。在這個過程中,該模組使用交叉注意力機制將音訊特徵整合進解碼器。對於上述兩個模組,訓練所使用的損失函數都是簡單的 L1 損失。 在獲得了網格和姿勢序列之後,再使用透視投影將它們轉換為 2D 的人臉 Landmark 序列。這些 Landmark 是下一階段的輸入訊號。 #給定一張參考人像和一個人臉Landmark 序列,該團隊提出的Lmk2Video 可以創建具有時間一致性的人像動畫。這個動畫過程是將動作與 Landmark 序列對齊,同時維持與參考影像一致的外觀。該團隊採取的想法是將人像動畫表示成一個人像幀構成的序列。 Lmk2Video 的這個網路結構設計的靈感來自 AnimateAnyone。其中的骨幹網路是 SD1.5,整合了一個時間運動模組,能有效地將多幀雜訊輸入轉換成一個視訊幀序列。 另外,他們也使用了一個ReferenceNet,其同樣採用了SD1.5 的結構,作用是提取參考影像的外觀資訊並將其整合進骨幹網路中。此策略設計可確保人臉 ID 在整個輸出影片中保持一致。 不同於 AnimateAnyone,這裡提升了 PoseGuider 的設計的複雜性。原來的版本只是整合了幾個卷積層,之後 Landmark 特徵與骨幹網路的輸入層的隱含特徵融合。而騰訊的這個團隊發現,這種初級設計無法捕捉嘴唇的複雜運動。因此,他們採用了 ControlNet 的多尺度策略:將對應尺度的 Landmark 特徵整合進骨幹網路的不同模組。儘管有這些改進,但最終模型的參數數量仍然相當低。 該團隊還引入了另一項改進:將參考映像的 Landmark 用作額外的輸入。 PoseGuider 的交叉注意力模組能促進參考 Landmark 和每個畫面的目標 Landmark 之間的互動。這個過程能為網路提供額外的線索,使其能夠理解人臉 Landmark 和外觀之間的關聯,由此可幫助人像動畫產生更精準的動作。 Audio2Lmk 階段使用的骨幹網路是wav2vec2.0。用於提取 3D 網格和 6D 姿勢的工具是 MediaPipe。 Audio2Mesh 的訓練資料來自騰訊的內部資料集,其中包含接近一個小時的來自單一說話者的高品質語音資料。 為了確保 MediaPipe 提取出的 3D 網格的穩定性,在記錄期間,表演者頭部位置穩定並且面向相機。訓練 Audio2Pose 使用的是 HDTF。所有的訓練操作都在單一A100 上執行,使用了Adam 優化器,學習率設定為1e-5.起始步驟階段關注的重點是訓練骨幹網路 ReferenceNet 以及 PoseGuider 的 2D 元件,而不管運動模組。在後續步驟,則會凍結其它所有組件,專注於訓練運動模組。為了訓練模型,這裡使用了兩個大規模高品質人臉視訊資料集:VFHQ 和 CelebV-HQ。所有資料都經由 MediaPipe 提取 2D 臉部 Landmark。為了提升網路對嘴唇運動的敏感性,該團隊的做法是在根據 2D Landmark 渲染姿勢圖像時,給上下唇標註不同的顏色。 所有影像的解析度都重新調整變成了 512x512。模型的訓練使用了 4 台 A100 GPU,每一步耗時 2 天。優化器是 AdamW,學習率固定為 1e-5。 #如圖2 所示,新方法得到的動畫在品質和真實度上都非常出色。
對於一段語音片段序列,這裡的目標是預測對應的 3D 人臉網格序列和姿勢序列。 該團隊採用了預先訓練的 wav2vec 來提取音訊特徵。該模型具有很好的泛化性能,並且可以準確識別音訊中的發音和語調 —— 這對產生具有真實感的人臉動畫至關重要。透過利用所獲得的魯棒的語音特徵,使用一種包含兩個 fc 層的簡單架構就可以有效地將它們轉換成 3D 人臉網格。團隊觀察到,這種簡單直接的設計不僅能確保準確度,還能提升推理過程的效率。 在將音訊轉換成姿勢的任務中,該團隊使用的骨幹網路依然是同樣的 wav2vec。但是,這一個網路的權重不同於音訊到網格模組的網路。這是因為:姿勢與音訊中的節奏和音調的關聯更加緊密,而音訊到網格任務關注的重點(發音和語調)卻不一樣。為了將先前狀態的影響納入考量,團隊採用了 transformer 解碼器來解碼姿勢序列。在這個過程中,該模組使用交叉注意力機制將音訊特徵整合進解碼器。對於上述兩個模組,訓練所使用的損失函數都是簡單的 L1 損失。 在獲得了網格和姿勢序列之後,再使用透視投影將它們轉換為 2D 的人臉 Landmark 序列。這些 Landmark 是下一階段的輸入訊號。 #給定一張參考人像和一個人臉Landmark 序列,該團隊提出的Lmk2Video 可以創建具有時間一致性的人像動畫。這個動畫過程是將動作與 Landmark 序列對齊,同時維持與參考影像一致的外觀。該團隊採取的想法是將人像動畫表示成一個人像幀構成的序列。 Lmk2Video 的這個網路結構設計的靈感來自 AnimateAnyone。其中的骨幹網路是 SD1.5,整合了一個時間運動模組,能有效地將多幀雜訊輸入轉換成一個視訊幀序列。 另外,他們也使用了一個ReferenceNet,其同樣採用了SD1.5 的結構,作用是提取參考影像的外觀資訊並將其整合進骨幹網路中。此策略設計可確保人臉 ID 在整個輸出影片中保持一致。 不同於 AnimateAnyone,這裡提升了 PoseGuider 的設計的複雜性。原來的版本只是整合了幾個卷積層,之後 Landmark 特徵與骨幹網路的輸入層的隱含特徵融合。而騰訊的這個團隊發現,這種初級設計無法捕捉嘴唇的複雜運動。因此,他們採用了 ControlNet 的多尺度策略:將對應尺度的 Landmark 特徵整合進骨幹網路的不同模組。儘管有這些改進,但最終模型的參數數量仍然相當低。 該團隊還引入了另一項改進:將參考映像的 Landmark 用作額外的輸入。 PoseGuider 的交叉注意力模組能促進參考 Landmark 和每個畫面的目標 Landmark 之間的互動。這個過程能為網路提供額外的線索,使其能夠理解人臉 Landmark 和外觀之間的關聯,由此可幫助人像動畫產生更精準的動作。 Audio2Lmk 階段使用的骨幹網路是wav2vec2.0。用於提取 3D 網格和 6D 姿勢的工具是 MediaPipe。 Audio2Mesh 的訓練資料來自騰訊的內部資料集,其中包含接近一個小時的來自單一說話者的高品質語音資料。 為了確保 MediaPipe 提取出的 3D 網格的穩定性,在記錄期間,表演者頭部位置穩定並且面向相機。訓練 Audio2Pose 使用的是 HDTF。所有的訓練操作都在單一A100 上執行,使用了Adam 優化器,學習率設定為1e-5.起始步驟階段關注的重點是訓練骨幹網路 ReferenceNet 以及 PoseGuider 的 2D 元件,而不管運動模組。在後續步驟,則會凍結其它所有組件,專注於訓練運動模組。為了訓練模型,這裡使用了兩個大規模高品質人臉視訊資料集:VFHQ 和 CelebV-HQ。所有資料都經由 MediaPipe 提取 2D 臉部 Landmark。為了提升網路對嘴唇運動的敏感性,該團隊的做法是在根據 2D Landmark 渲染姿勢圖像時,給上下唇標註不同的顏色。 所有影像的解析度都重新調整變成了 512x512。模型的訓練使用了 4 台 A100 GPU,每一步耗時 2 天。優化器是 AdamW,學習率固定為 1e-5。 #如圖2 所示,新方法得到的動畫在品質和真實度上都非常出色。

此外,使用者還可以編輯其中間的 3D 表徵,從而對最終輸出進行修改。舉個例子,使用者可從某個來源提取 Landmark 並修改其 ID 訊息,從而實現臉部重現效果,如下影片所示: 更多細節請參考原論文。
更多細節請參考原論文。 以上是Up主已經開始鬼畜,騰訊開源「AniPortrait」讓照片唱歌說話的詳細內容。更多資訊請關注PHP中文網其他相關文章!























