
想了解更多AIGC的內容,
請造訪:51CTO AI.x社群
https ://www.51cto.com/aigc/
「只要」10萬美元,訓練Llama-2等級的大模型。
尺寸更小但效能不減的MoE模型來了:
它叫做JetMoE,來自MIT、普林斯頓等研究機構。
性能妥妥超過同等規模的Llama-2。
△賈揚清轉發
要知道,後者可是數十億美元等級的投入成本。
JetMoE發布即完全開源,且學術界友善:僅使用公開資料集與開源程式碼,以消費級GPU就能進行微調。
不得說,大模型的打造成本,真的比人們想的便宜更多了。
Ps. Stable Diffusion前老闆Emad也點了讚:
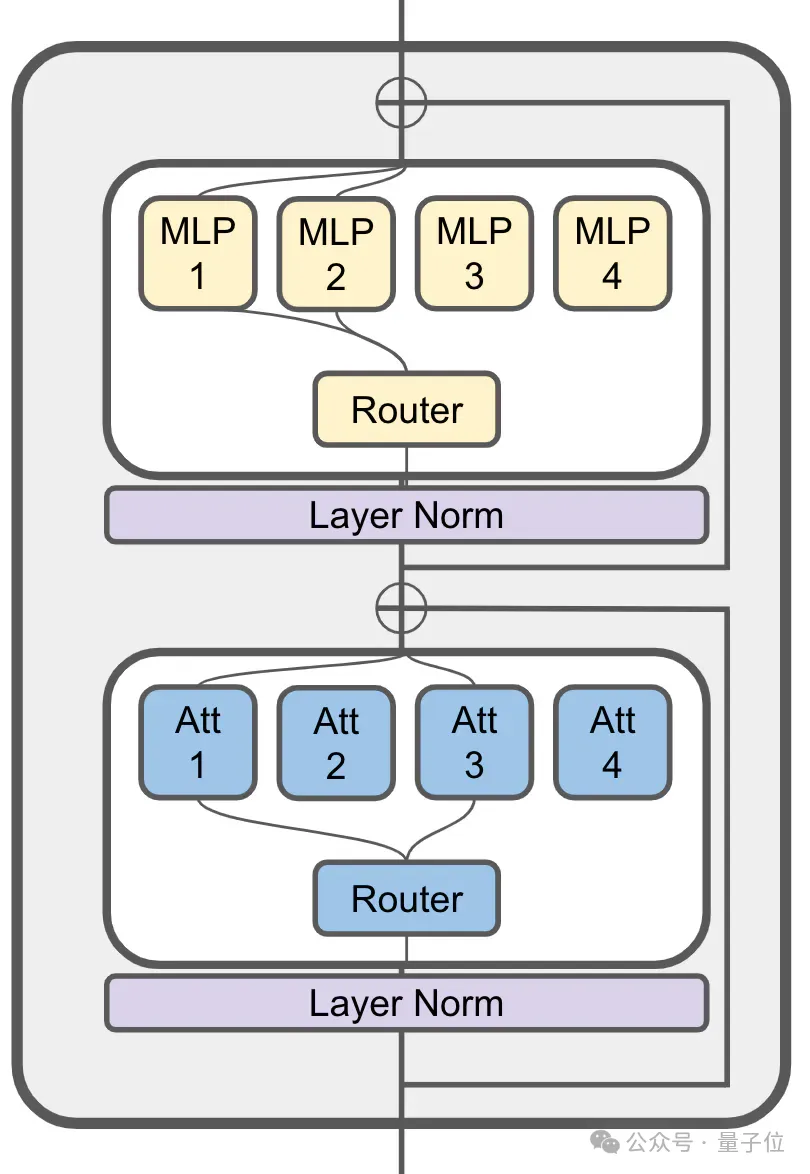
JetMoE啟發ModuleFormer的稀疏激活架構。
(ModuleFormer,一個基於稀疏專家混合(SMoE)的模組化架構,可提高大模型效率和靈活性,去年6月提出)
它的注意力層中仍然使用了MoE:
80億參數的JetMoE一共有24個區塊,每塊包含2個MoE層,分別是注意力頭混合 (MoA) 和MLP專家混合 (MoE)。
每個MoA和MoE層又有8個專家,每次輸入token啟動2個。
JetMoE-8B使用公開資料集中的1.25T token進行訓練,學習率5.0 x 10-4,全域batch size為4M token。
具體訓練方案遵循MiniCPM(來自面壁智能,2B模型就能趕上超Mistral-7B)的思路,共包含兩階段:
第一階段使用線性預熱的恆定學習率,用來自大規模開源預訓練資料集的1萬億個token進行訓練,這些資料集包括RefinedWeb、Pile、Github data等等。
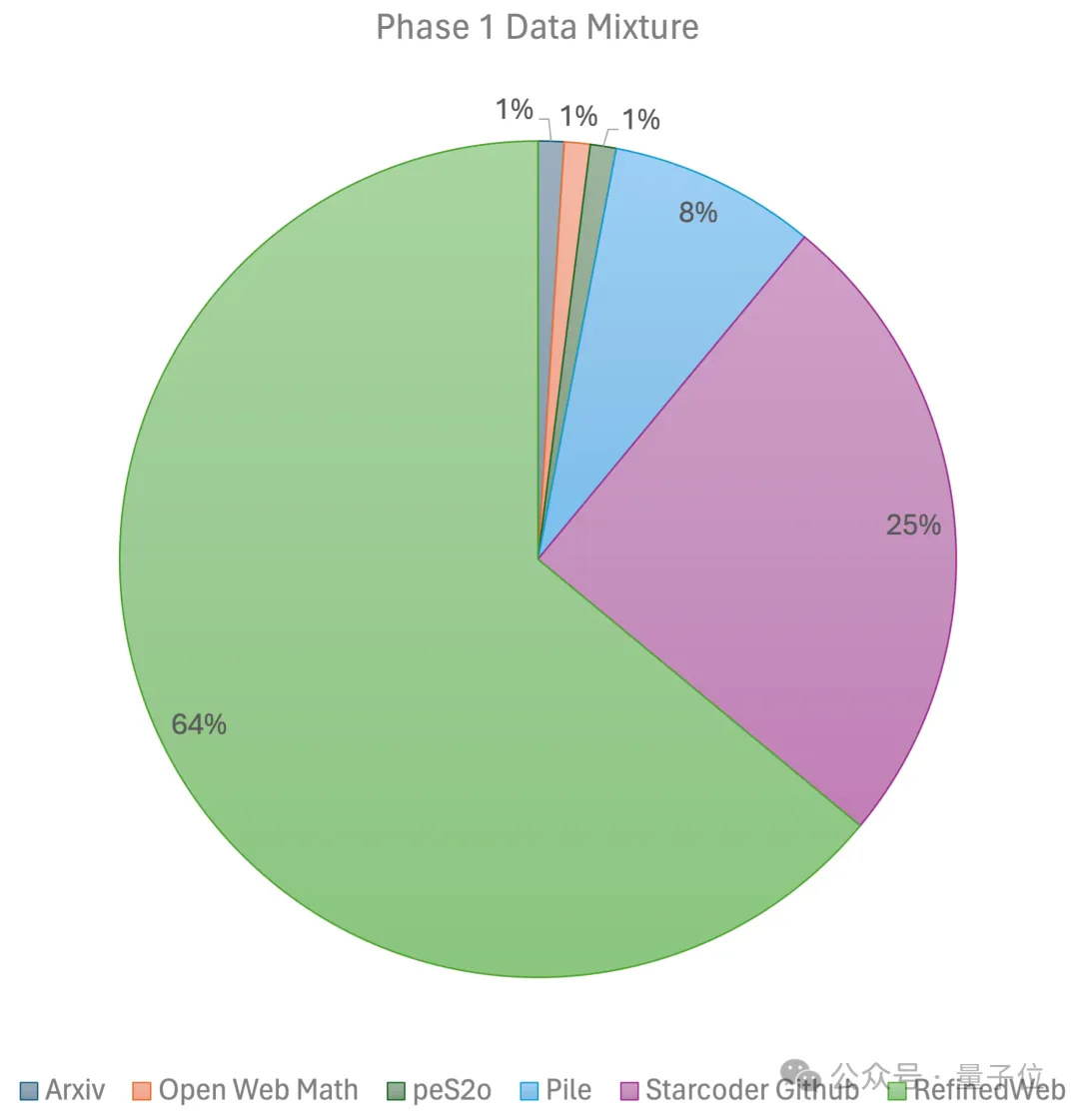
第二階段則使用指數學習率衰減,用2500億個token訓練第一階段資料集和超高品質開源資料集的token。
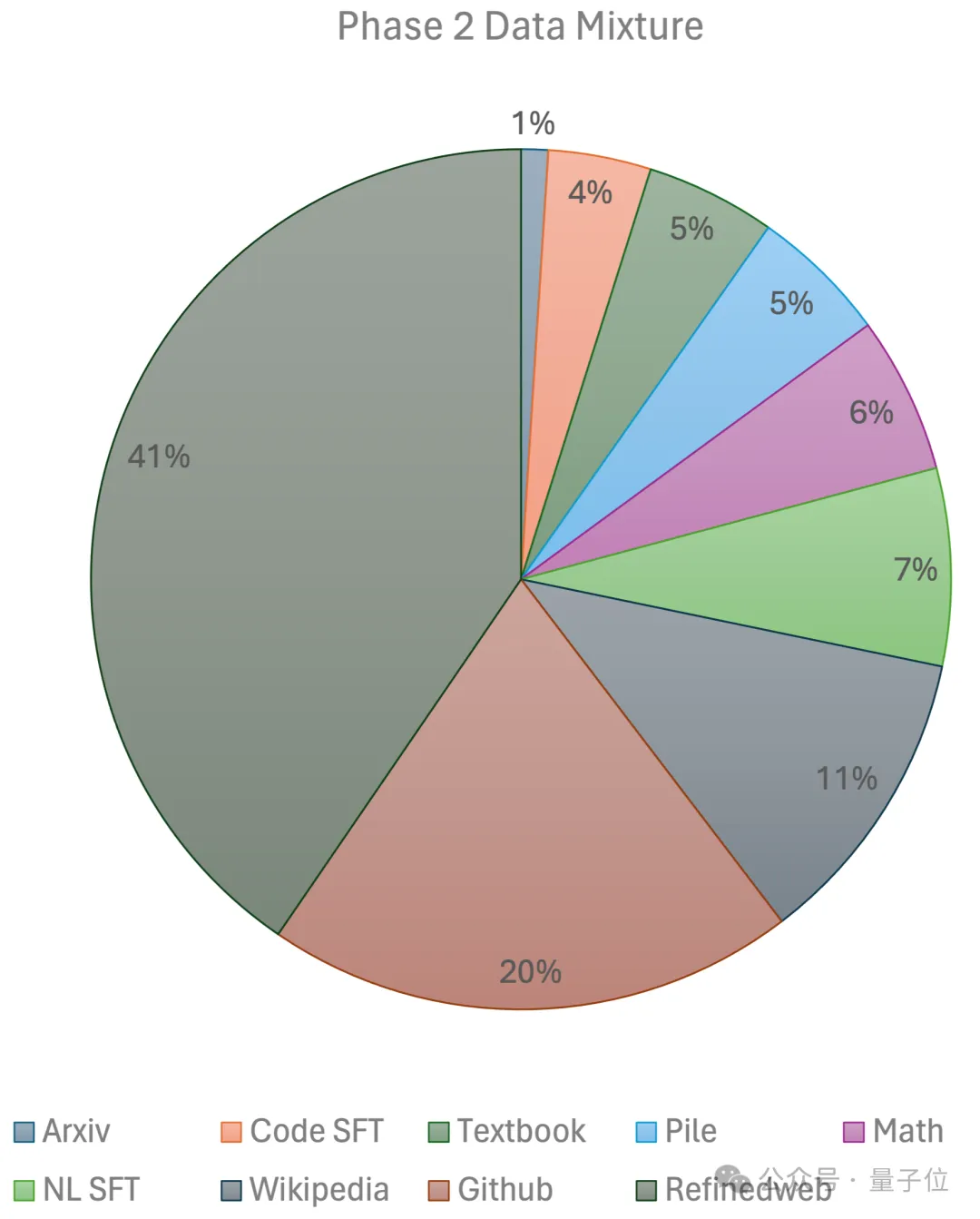
最終,團隊使用96×H100的GPU集群,#花費2週時間、約8萬美元搞定JetMoE-8B。
更多技術細節將在不久後發布的技術報告上揭露。
而在推理過程中,由於JetMoE-8B僅具有22億個激活參數,因此計算成本大大降低-
同時,它還收穫了不錯的性能表現。
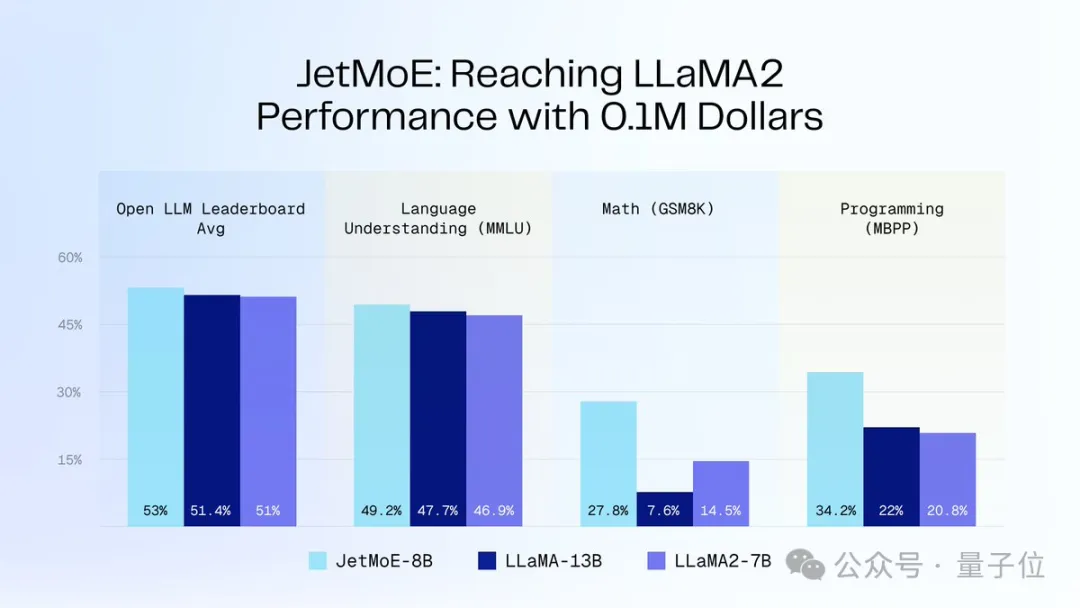
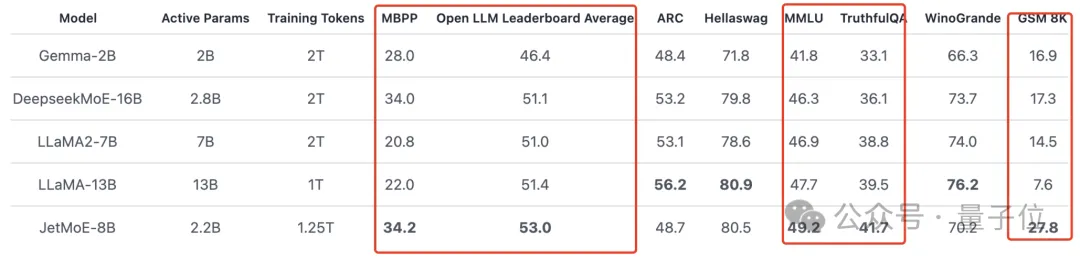
如下圖所示:
JetMoE-8B在8個評測基準上獲得了5個sota(包括大模型競技場Open LLM Leaderboard),超過LLaMA -13B、LLaMA2-7B和DeepseekMoE-16B。
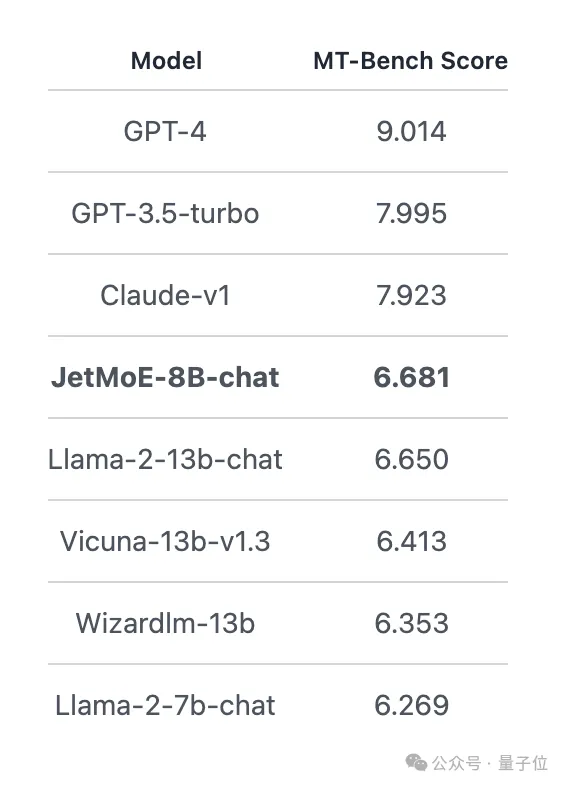
在MT-Bench基準上得分6.681,也超過了130億參數的LLaMA2、Vicuna等模型。
JetMoE共4位作者,分別為:
MIT-IBM Watson Lab研究員,研究方向NLP。
本碩畢業於北航,博士經歷於Yoshua Bengio創辦的Mila研究機構。
MIT博士在讀, 研究方向為3D成像的資料高效機器學習。
UC柏克萊本科畢業,去年夏天加入MIT-IBM Watson Lab,導師為Yikang Shen等。
#普林斯頓博士在讀生,本科畢業於北大應用數學和電腦科學,目前也是Together. ai 的兼職研究員,與Tri Dao合作。
#MIT博士在讀,同時在創業,MyShell#的AI研發主管。
這家公司剛剛融資了1,100萬美元,投資者包括Transformer的作者。
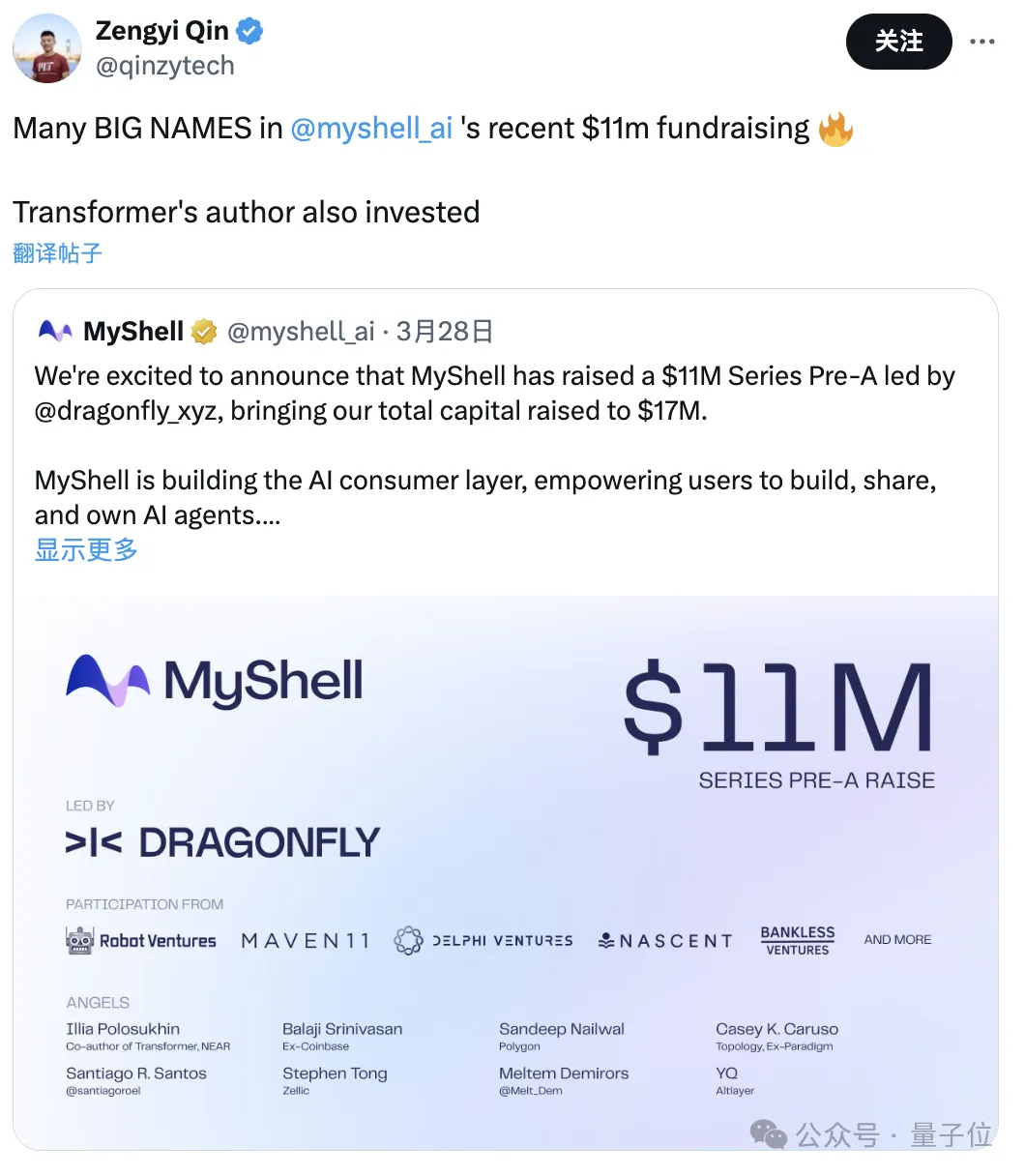
傳送門:https://github.com/myshell-ai/JetMoE
參考連結:https:// twitter.com/jiayq/status/1775935845205463292
想了解更多AIGC的內容,
請造訪:51CTO AI.x社群
https://www.51cto.com/aigc/
以上是10萬美元訓練Llama-2級大模型!全華人打造新型MoE,賈揚清SD前CEO圍觀的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















