
在大模型落地應用的過程中,端側 AI 是非常重要的方向。
近日,史丹佛大學研究人員推出的 Octopus v2 火了,受到了開發者社群的極大關注,模型一夜下載量超 2k。
20 億參數的 Octopus v2 可以在智慧型手機、汽車、個人電腦等端側運行,在準確性和延遲方面超越了 GPT-4,並將上下文長度減少了 95%。此外,Octopus v2 比 Llama7B RAG 方案快 36 倍。 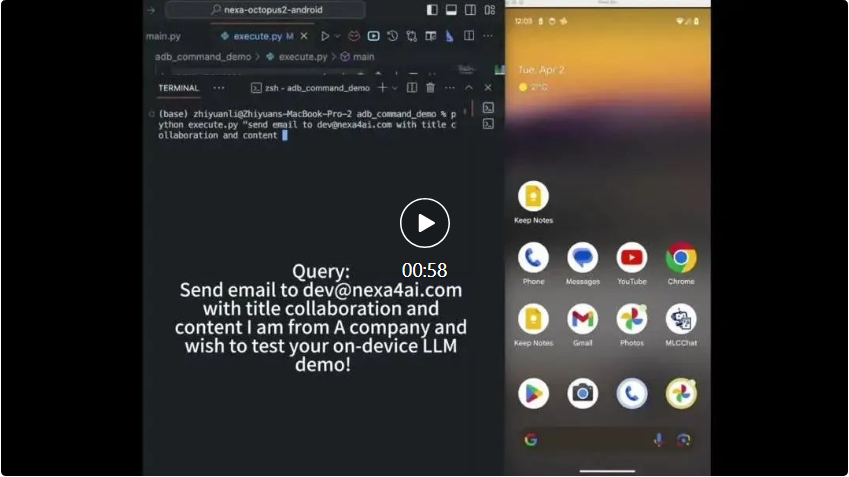

論文:Octopus v2: On-device language model for super agent
模型概述
Octopus-V2-2B 是一種開源語言模型,擁有20億參數,專為Android API量身定制。它可以在Android設備上無縫運行,並將實用性擴展到從Android系統管理到多個設備的編排等各種應用程式。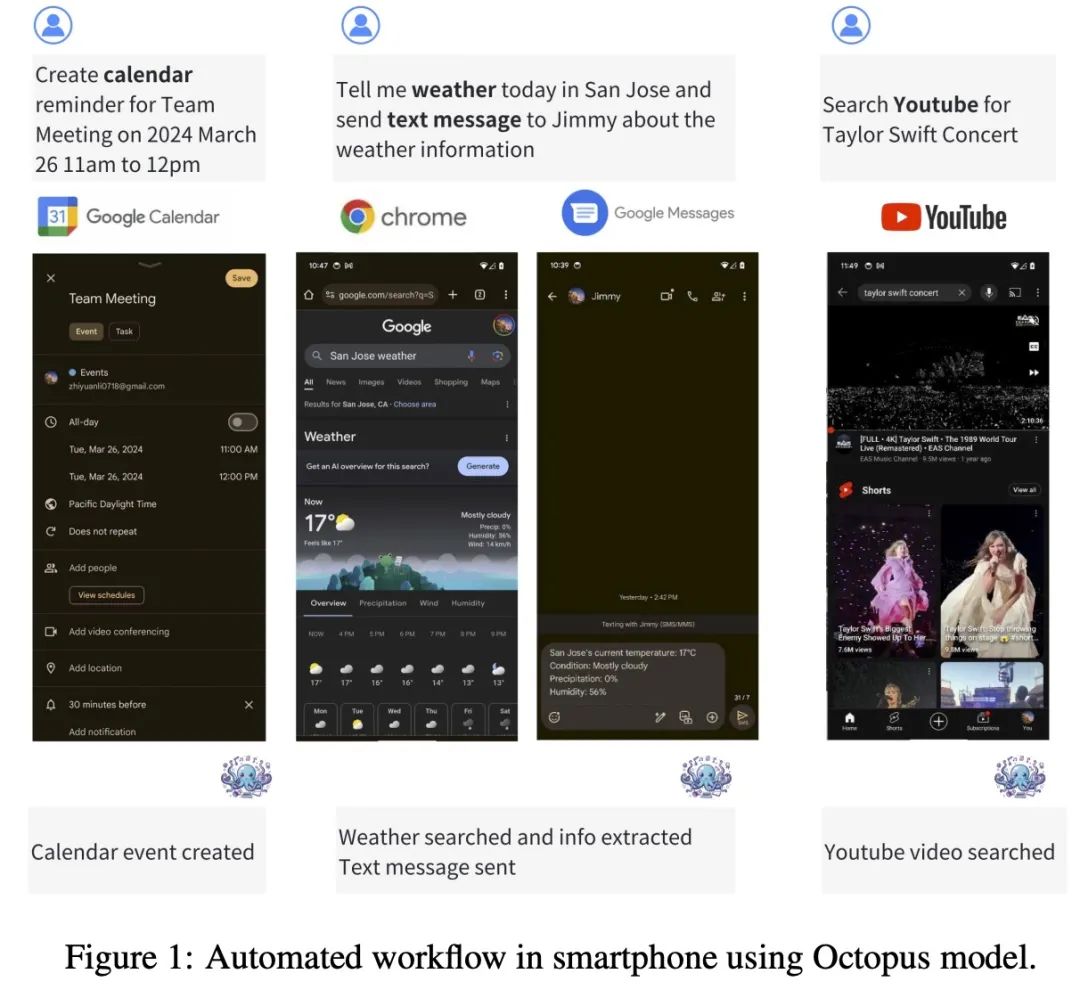
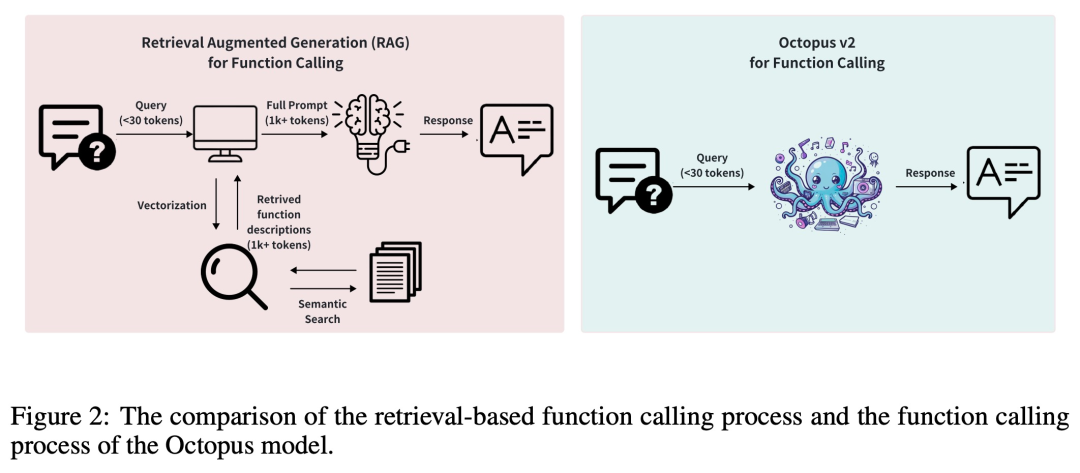
資料集
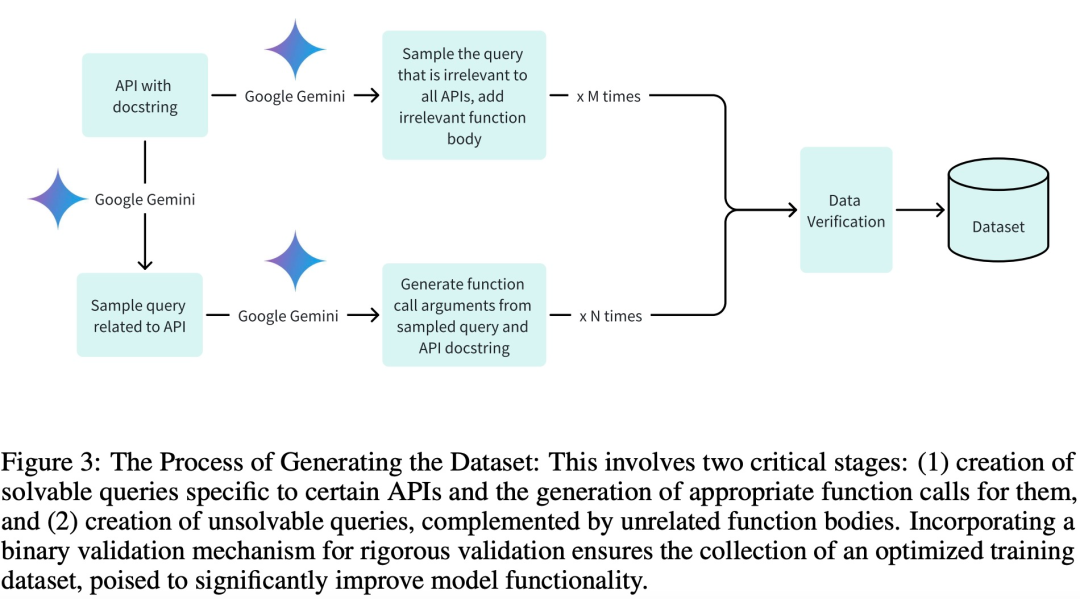
為了訓練、驗證和測試階段採用高品質資料集,特別是實現高效訓練,研究團隊用三個關鍵階段創建資料集:
def get_trending_news (category=None, region='US', language='en', max_results=5):"""Fetches trending news articles based on category, region, and language.Parameters:- category (str, optional): News category to filter by, by default use None for all categories. Optional to provide.- region (str, optional): ISO 3166-1 alpha-2 country code for region-specific news, by default, uses 'US'. Optional to provide.- language (str, optional): ISO 639-1 language code for article language, by default uses 'en'. Optional to provide.- max_results (int, optional): Maximum number of articles to return, by default, uses 5. Optional to provide.Returns:- list [str]: A list of strings, each representing an article. Each string contains the article's heading and URL. """
模型開發與訓練
該研究採用Google Gemma-2B 模型作為框架中的預訓練模型,並採用兩種不同的訓練方法:完整模型訓練和LoRA 模型訓練。 在完整模型訓練中,研究使用 AdamW 最佳化器,學習率設定為 5e-5,warm-up 的 step 數設定為 10,採用線性學習率調度器。 LoRA 模型訓練採用與完整模型訓練相同的最佳化器和學習率配置,LoRA rank 設定為 16,並將 LoRA 應用於以下模組:q_proj、k_proj、v_proj、o_proj、up_proj、down_proj。其中,LoRA alpha 參數設定為 32。 對於兩種訓練方法,epoch 數皆設定為 3。 使用以下程式碼,就可以在單一 GPU 上執行 Octopus-V2-2B 模型。from transformers import AutoTokenizer, GemmaForCausalLMimport torchimport timedef inference (input_text):start_time = time.time ()input_ids = tokenizer (input_text, return_tensors="pt").to (model.device)input_length = input_ids ["input_ids"].shape [1]outputs = model.generate (input_ids=input_ids ["input_ids"], max_length=1024,do_sample=False)generated_sequence = outputs [:, input_length:].tolist ()res = tokenizer.decode (generated_sequence [0])end_time = time.time ()return {"output": res, "latency": end_time - start_time}model_id = "NexaAIDev/Octopus-v2"tokenizer = AutoTokenizer.from_pretrained (model_id)model = GemmaForCausalLM.from_pretrained (model_id, torch_dtype=torch.bfloat16, device_map="auto")input_text = "Take a selfie for me with front camera"nexa_query = f"Below is the query from the users, please call the correct function and generate the parameters to call the function.\n\nQuery: {input_text} \n\nResponse:"start_time = time.time () print ("nexa model result:\n", inference (nexa_query)) print ("latency:", time.time () - start_time,"s")評估
Octopus-V2-2B 在基準測試中表現出卓越的推理速度,在單一A100 GPU 上比「Llama7B RAG 解決方案」快36 倍。此外,與依賴叢集 A100/H100 GPU 的 GPT-4-turbo 相比,Octopus-V2-2B 速度提高了 168%。這種效率突破歸功於 Octopus-V2-2B 的函數性 token 設計。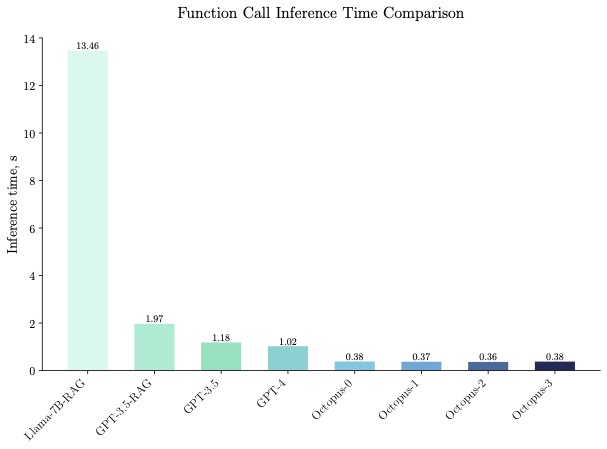
Octopus-V2-2B 不僅在速度上表現出色,在準確率上也表現出色,在函數呼叫準確率上超越「Llama7B RAG 方案」31%。 Octopus-V2-2B 實現了與 GPT-4 和 RAG GPT-3.5 相當的函數呼叫準確率。
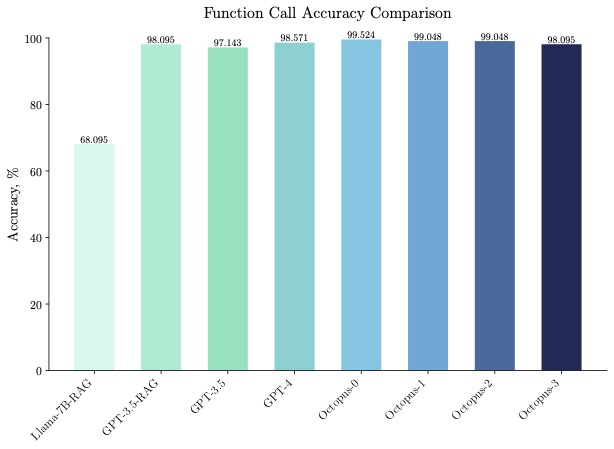
有興趣的讀者可以閱讀論文原文,了解更多研究內容。
以上是超越GPT-4,史丹佛團隊手機可跑的大模型火了,一夜下載量超2k的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















