
4月7日訊息,阿里雲通知千問開源320億參數模型Qwen1.5-32B,可最大限度兼顧效能、效率和記憶體佔用的平衡,為企業和開發者提供更高性價比的模型選擇。目前,通知千問共開源6款大語言模型,在海內外開源社群累積下載量突破300萬。
通用問題千問先前已開發了5億、18億、40億、70億、140億和720億參數模型,並均已升級至1.5版本。其中,幾款小尺寸模型可方便地部署在端側,720億參數模型則擁有業界領先的效能,並多次登上HuggingFace等模型榜單。此次開源的320億參數模型,將在效能、效率和記憶體佔用之間實現更理想的平衡。例如,相較於相14B模型,32B在智能體場景下能力較強;相較於72B,32B的推理成本較低。通用問題團隊希望32B開源模型能為下游應用提供更優的解決方案。
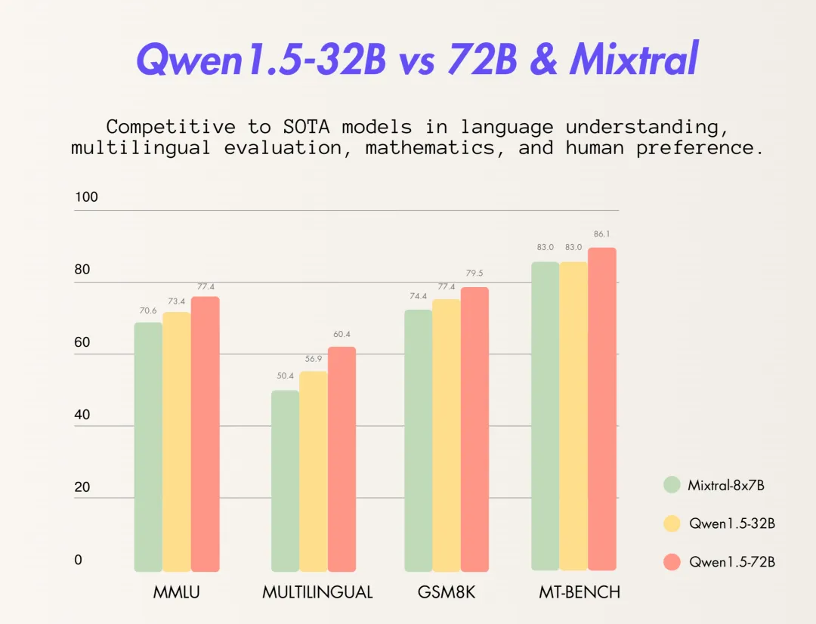
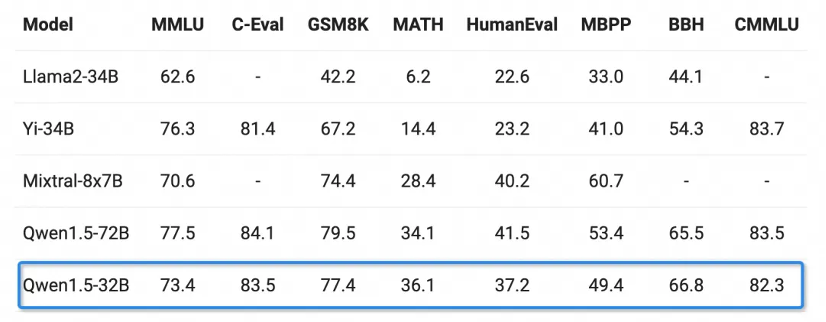
基礎能力方面,透過千問320億參數模型在MMLU、GSM8K、HumanEval、BBH等多個測試中表現優異,性能接近千問720億參數模型,遠超其300億級參數模型。
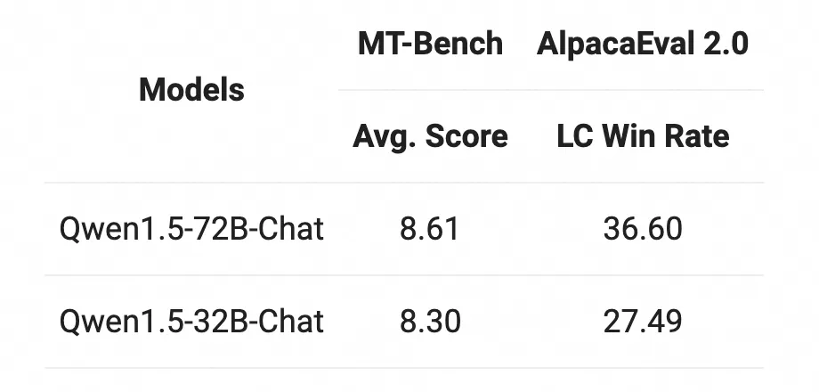
Chat模型方面,Qwen1.5-32B-Chat模型在MT-Bench評測得分超過8分,與Qwen1.5-72B-Chat之間的差距相對較小。
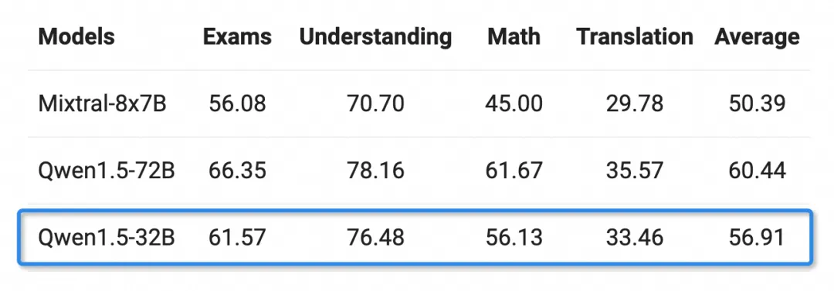
有著豐富語言能力的人,在選擇了包括阿拉伯語、西班牙語、法語、日語、韓語等在內的12種語言後,可以在考試、理解、數學及翻譯等多個領域做了評估。 Qwen1.5-32B的多語言能力僅限於通用千問720億參數模型。
以上是通義千問開源320億參數模型,已實現7款大語言模型全開源的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















