

Mistral開源8X22B大模型,OpenAI更新GPT-4 Turbo視覺,都在欺負Google

真有圍剿 Google 的態勢啊!

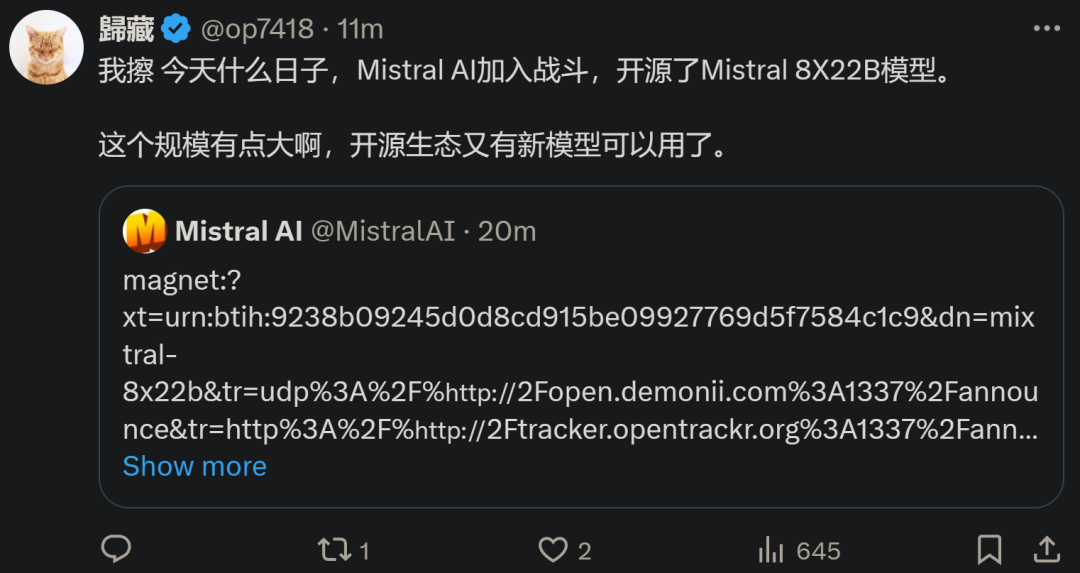
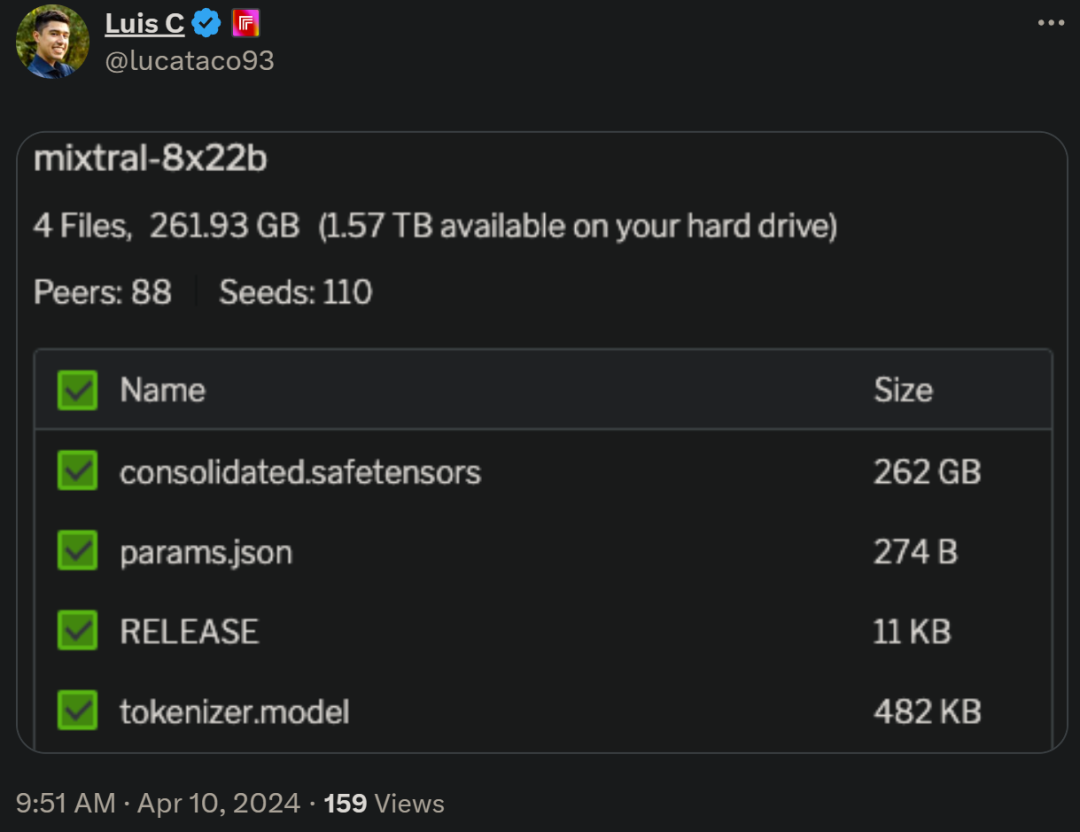

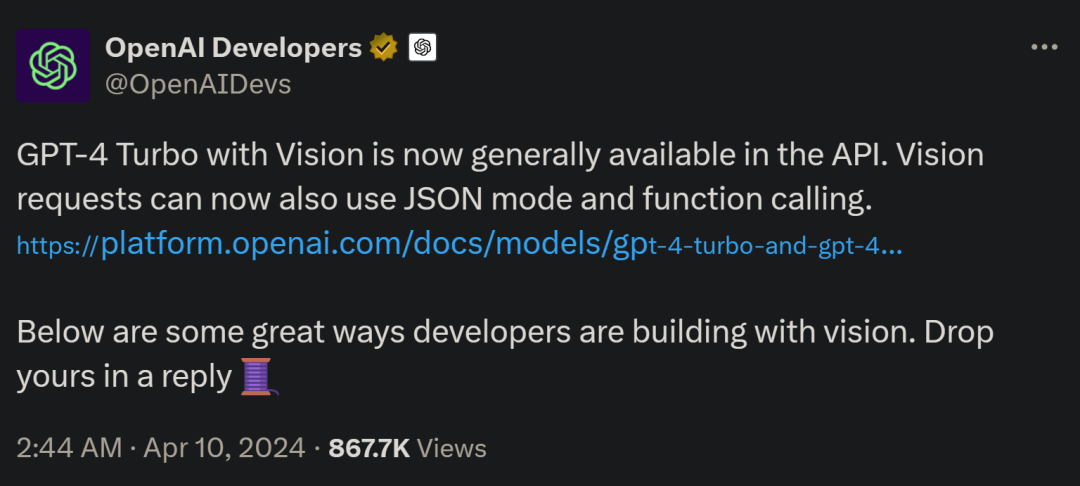



以上是Mistral開源8X22B大模型,OpenAI更新GPT-4 Turbo視覺,都在欺負Google的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 加密數字資產交易APP推薦top10(2025全球排名)
Mar 18, 2025 pm 12:15 PM
加密數字資產交易APP推薦top10(2025全球排名)
Mar 18, 2025 pm 12:15 PM
本文推荐十大值得关注的加密货币交易平台,涵盖币安(Binance)、OKX、Gate.io、BitFlyer、KuCoin、Bybit、Coinbase Pro、Kraken、BYDFi和XBIT去中心化交易所。这些平台在交易币种数量、交易类型、安全性、合规性、特色功能等方面各有千秋,例如币安以其全球最大的交易量和丰富的功能著称,而BitFlyer则凭借其日本金融厅牌照和高安全性吸引亚洲用户。选择合适的平台需要根据自身交易经验、风险承受能力和投资偏好进行综合考量。 希望本文能帮助您找到最适合自
 歐易okex賬號怎麼註冊、使用、註銷教程
Mar 31, 2025 pm 04:21 PM
歐易okex賬號怎麼註冊、使用、註銷教程
Mar 31, 2025 pm 04:21 PM
本文詳細介紹了歐易OKEx賬號的註冊、使用和註銷流程。註冊需下載APP,輸入手機號或郵箱註冊,完成實名認證。使用方面涵蓋登錄、充值提現、交易以及安全設置等操作步驟。而註銷賬號則需要聯繫歐易OKEx客服,提供必要信息並等待處理,最終獲得賬號註銷確認。 通過本文,用戶可以輕鬆掌握歐易OKEx賬號的完整生命週期管理,安全便捷地進行數字資產交易。
 binance怎麼註冊詳細教程(2025新手指南)
Mar 18, 2025 pm 01:57 PM
binance怎麼註冊詳細教程(2025新手指南)
Mar 18, 2025 pm 01:57 PM
本文提供Binance幣安註冊及安全設置的完整指南,涵蓋註冊前的準備工作(包括設備、郵箱、手機號及身份證明文件準備),詳細介紹了官網及APP兩種註冊方式,以及不同級別的身份驗證(KYC)流程。此外,文章還重點講解瞭如何設置資金密碼、開啟雙重驗證(2FA,包括谷歌身份驗證器和短信驗證)以及設置防釣魚碼等關鍵安全步驟,幫助用戶安全便捷地註冊和使用Binance幣安平台進行加密貨幣交易。 請務必在交易前了解相關法律法規及市場風險,謹慎投資。
 gate.io手機app使用教程
Mar 26, 2025 pm 05:15 PM
gate.io手機app使用教程
Mar 26, 2025 pm 05:15 PM
gate.io手機app使用教程:1、安卓用戶,訪問 Gate.io 官方網站,下載安卓安裝包,您可能需要在手機設置中允許安裝來自未知來源的應用;2、ios用戶,在 App Store 中搜索 "Gate.io" 下載。
 如何優化jieba分詞以改善景區評論的關鍵詞提取效果?
Apr 01, 2025 pm 06:24 PM
如何優化jieba分詞以改善景區評論的關鍵詞提取效果?
Apr 01, 2025 pm 06:24 PM
如何優化jieba分詞以改善景區評論的關鍵詞提取?在使用jieba分詞處理景區評論數據時,如果發現分詞結果不理�...
 虛擬幣最老的幣排行榜最新更新
Apr 22, 2025 am 07:18 AM
虛擬幣最老的幣排行榜最新更新
Apr 22, 2025 am 07:18 AM
虛擬貨幣“最老”排行榜如下:1. 比特幣(BTC),發行於2009年1月3日,是首個去中心化數字貨幣。 2. 萊特幣(LTC),發行於2011年10月7日,被稱為“比特幣的輕量版”。 3. 瑞波幣(XRP),發行於2011年,專為跨境支付設計。 4. 狗狗幣(DOGE),發行於2013年12月6日,基於萊特幣代碼的“迷因幣”。 5. 以太坊(ETH),發行於2015年7月30日,首個支持智能合約的平台。 6. 泰達幣(USDT),發行於2014年,是首個與美元1:1錨定的穩定幣。 7. 艾達幣(ADA),發
 okex交易平台官網登錄入口
Mar 18, 2025 pm 12:42 PM
okex交易平台官網登錄入口
Mar 18, 2025 pm 12:42 PM
本文詳細介紹了歐易OKEx網頁版登錄的完整步驟,包括準備工作(確保網絡連接穩定及瀏覽器更新)、訪問官網(注意網址準確性,避免釣魚網站)、找到登錄入口(點擊官網首頁右上角的“登錄”按鈕)、輸入登錄信息(郵箱/手機號及密碼,支持驗證碼登錄)、完成安全驗證(滑動驗證、谷歌驗證或短信驗證)等五個步驟,最終成功登錄後即可進行數字資產交易等操作。 安全便捷的登錄流程,保障用戶資產安全。
 虛擬幣購買app安全靠譜的top10推薦
Mar 18, 2025 pm 12:12 PM
虛擬幣購買app安全靠譜的top10推薦
Mar 18, 2025 pm 12:12 PM
2025年全球虛擬幣交易平台Top 10推薦,助您玩轉數字貨幣市場!本文將為您深度解析幣安(Binance)、OKX、Gate.io、BitFlyer、KuCoin、Bybit、Coinbase Pro、Kraken、BYDFi和XBIT去中心化交易所等十家頂級平台的核心優勢和特色功能。無論是追求高流動性、豐富的交易類型,還是注重安全合規、創新功能,都能在此找到適合您的平台。 我們將從交易品種、安全性、特色功能等方面進行全面對比,助您選擇最合適的虛擬貨幣交易平台,把握2025年數字貨幣投資機遇
