

大模型做時序預測也很強!華人團隊啟動LLM新能力,超越一眾傳統模式實現SOTA

大語言模型潛力被激發-
無需訓練大語言模型就能實現高精度時序預測,超越一切傳統時序模型。
蒙納士大學、螞蟻和IBM研究院共同開發了一個通用框架,成功推動了大語言模型跨模態處理序列資料的能力。該框架已成為一項重要的技術創新。

時序預測有益於城市、能源、交通、遙感等典型複雜系統的決策。
自此,大模型可望徹底改變時序/時空資料探勘方式。
通用大語言模型重編程框架
研究團隊提出了一個通用框架,將大語言模型輕鬆用於一般時間序列預測,而無需做任何訓練。
主要提出兩大關鍵技術:時序輸入重編程;提示做前綴。
Time-LLM首先使用文字原型(Text Prototypes)對輸入的時間資料進行重編程,透過使用自然語言表徵來表示時間資料的語義訊息,進而對齊兩種不同的資料模態,使大語言模型無需任何修改即可理解另一種資料模態背後的資訊。同時,透過大語言模型不需要任何特定的訓練資料集,即可理解不同的資料模態的背後訊息。這種方法不僅能夠提高模型的準確性,還能夠簡化資料預處理過程。
為了更好地處理輸入時序資料和對應任務的解析,作者提出了Prompt-as-Prefix(PaP)的範式。此範式透過在時序資料表徵前加入額外的上下文資訊和任務指令,充分啟動LLM在時序任務上的處理能力。這種方法可以在時序任務上實現更精細的解析,並且透過在時序資料表格前添加額外的上下文資訊和任務指令,充分啟動LLM在時序任務上的處理能力。
主要貢獻包括:
- 提出了透過重編程大型語言模型用於時序分析的全新概念,無需對主幹語言模型做任何修改。
- 提出一個通用語言模型重編程框架Time-LLM,它包括將輸入時序資料重新編程為更自然的文本原型表示,並透過聲明性提示(例如領域專家知識和任務說明)來增強輸入上下文,以指導LLM進行有效的跨域推理。

- 在主流預測任務中的表現始終超過現有最好的模型效能,尤其在少樣本和零樣本情境中。此外,Time-LLM在維持出色的模型重編程效率的同時,能夠實現更高的效能。大幅釋放LLM在時間序列和其他順序資料方面尚未開發的潛力。
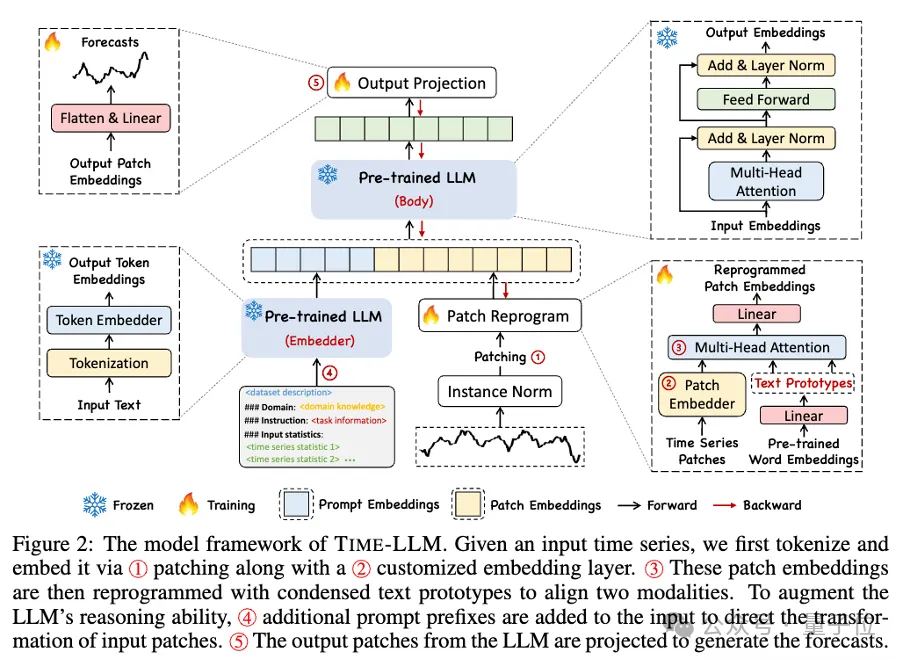
具體來看這個框架,首先,輸入時序資料先透過RevIN歸一化操作,然後被切分成不同patch並對應到隱空間。
時序資料和文字資料在表達方式上有顯著差異,兩種屬於不同的模態。
時間序列既不能直接編輯,也不能無損地用自然語言描述。因此,我們需要將時序輸入特徵對齊到自然語言文字域上。

而對齊不同模態的一個常見方式是cross-attention,但是LLM固有的詞彙表很大,因此無法有效直接將時序特徵對齊到所有單字上,而且也並不是所有字詞都和時間序列有對齊的語意關係。
為了解決這個問題,這項工作對詞彙表進行了線形組合來獲取文本原型,其中文本原型的數量遠小於原始詞彙量,組合起來可以用於表示時序數據的變化特徵。
而為了充分啟動LLM在指定時序任務上的能力,這項工作提出了提示做前綴的範式。
通俗點說,就是把時間序列資料集的一些先驗訊息,以自然語言的方式,作為前綴prompt,和對齊後的時序特徵拼接餵給LLM,是不是能夠提升預測效果?
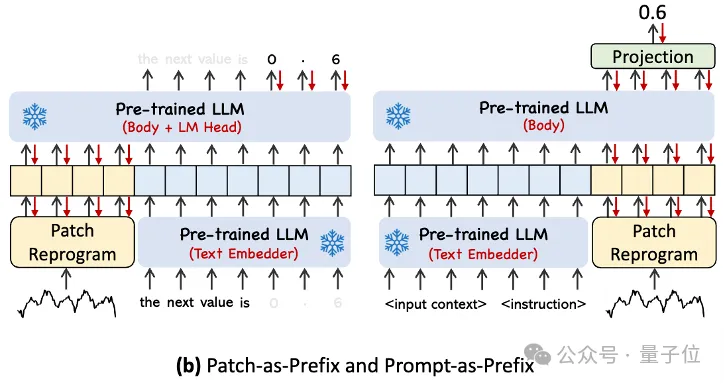
在實務中,作者確定了建立有效提示的三個關鍵元件:
資料集上下文;(2)任務指令,讓LLM適配不同的下游任務;(3)統計描述,例如趨勢、延遲等,讓LLM更能理解時序資料的特性。

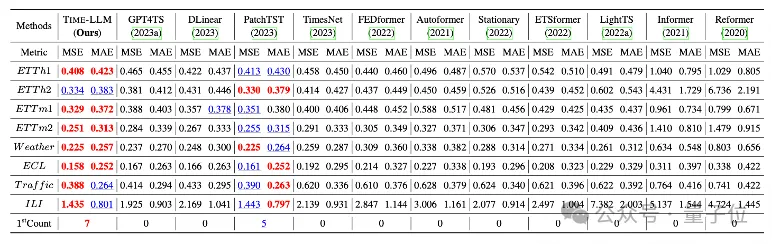
团队在长程预测上经典的8大公开数据集上进行了全面的测试。
结果Time-LLM在基准比较中显著超过此前领域最优效果,比如对比直接使用GPT-2的GPT4TS,Time-LLM有明显提升,表明了该方法的有效性。
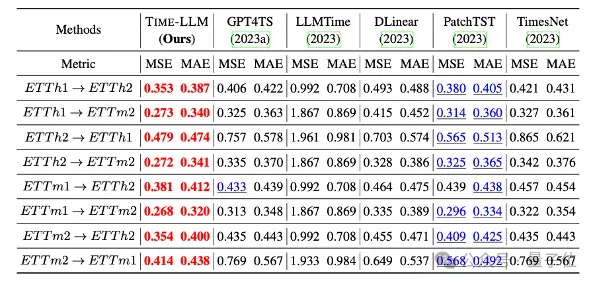
此外,在zero-shot场景中也表现了很强的预测能力。
本项目获得蚂蚁集团智能引擎事业部旗下AI创新研发部门NextEvo支持。
感兴趣的小伙伴可戳下方链接了解论文详情~
论文链接https://arxiv.org/abs/2310.01728。
以上是大模型做時序預測也很強!華人團隊啟動LLM新能力,超越一眾傳統模式實現SOTA的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
如何配置Debian Apache日誌格式
Apr 12, 2025 pm 11:30 PM
本文介紹如何在Debian系統上自定義Apache的日誌格式。以下步驟將指導您完成配置過程:第一步:訪問Apache配置文件Debian系統的Apache主配置文件通常位於/etc/apache2/apache2.conf或/etc/apache2/httpd.conf。使用以下命令以root權限打開配置文件:sudonano/etc/apache2/apache2.conf或sudonano/etc/apache2/httpd.conf第二步:定義自定義日誌格式找到或
 Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌如何幫助排查內存洩漏
Apr 12, 2025 pm 11:42 PM
Tomcat日誌是診斷內存洩漏問題的關鍵。通過分析Tomcat日誌,您可以深入了解內存使用情況和垃圾回收(GC)行為,從而有效定位和解決內存洩漏。以下是如何利用Tomcat日誌排查內存洩漏:1.GC日誌分析首先,啟用詳細的GC日誌記錄。在Tomcat啟動參數中添加以下JVM選項:-XX: PrintGCDetails-XX: PrintGCDateStamps-Xloggc:gc.log這些參數會生成詳細的GC日誌(gc.log),包含GC類型、回收對像大小和時間等信息。分析gc.log
 debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
在Debian系統中,readdir函數用於讀取目錄內容,但其返回的順序並非預先定義的。要對目錄中的文件進行排序,需要先讀取所有文件,再利用qsort函數進行排序。以下代碼演示瞭如何在Debian系統中使用readdir和qsort對目錄文件進行排序:#include#include#include#include//自定義比較函數,用於qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何優化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系統中,readdir系統調用用於讀取目錄內容。如果其性能表現不佳,可嘗試以下優化策略:精簡目錄文件數量:盡可能將大型目錄拆分成多個小型目錄,降低每次readdir調用處理的項目數量。啟用目錄內容緩存:構建緩存機制,定期或在目錄內容變更時更新緩存,減少對readdir的頻繁調用。內存緩存(如Memcached或Redis)或本地緩存(如文件或數據庫)均可考慮。採用高效數據結構:如果自行實現目錄遍歷,選擇更高效的數據結構(例如哈希表而非線性搜索)存儲和訪問目錄信
 Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
Debian syslog如何配置防火牆規則
Apr 13, 2025 am 06:51 AM
本文介紹如何在Debian系統中使用iptables或ufw配置防火牆規則,並利用Syslog記錄防火牆活動。方法一:使用iptablesiptables是Debian系統中功能強大的命令行防火牆工具。查看現有規則:使用以下命令查看當前的iptables規則:sudoiptables-L-n-v允許特定IP訪問:例如,允許IP地址192.168.1.100訪問80端口:sudoiptables-AINPUT-ptcp--dport80-s192.16
 Debian Nginx日誌路徑在哪裡
Apr 12, 2025 pm 11:33 PM
Debian Nginx日誌路徑在哪裡
Apr 12, 2025 pm 11:33 PM
Debian系統中,Nginx的訪問日誌和錯誤日誌默認存儲位置如下:訪問日誌(accesslog):/var/log/nginx/access.log錯誤日誌(errorlog):/var/log/nginx/error.log以上路徑是標準DebianNginx安裝的默認配置。如果您在安裝過程中修改過日誌文件存放位置,請檢查您的Nginx配置文件(通常位於/etc/nginx/nginx.conf或/etc/nginx/sites-available/目錄下)。在配置文件中
 Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
在Debian郵件服務器上安裝SSL證書的步驟如下:1.安裝OpenSSL工具包首先,確保你的系統上已經安裝了OpenSSL工具包。如果沒有安裝,可以使用以下命令進行安裝:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私鑰和證書請求接下來,使用OpenSSL生成一個2048位的RSA私鑰和一個證書請求(CSR):openss
 Debian syslog如何排查故障
Apr 13, 2025 am 06:48 AM
Debian syslog如何排查故障
Apr 13, 2025 am 06:48 AM
Debian系統的Syslog服務負責記錄和管理系統日誌,是診斷系統故障的重要工具。通過分析日誌,可以有效排查硬件問題、軟件錯誤和安全事件。以下步驟和命令將指導您如何利用DebianSyslog進行故障排查:一、查看系統日誌實時查看最新日誌:使用tail-f/var/log/syslog命令,可以監控系統日誌的實時更新,方便觀察系統事件和錯誤信息。查看內核日誌:使用dmesg命令查看內核的詳細日誌信息,有助於發現底層硬件或驅動程序的問題。使用journalctl(systemd
