

長文本殺不死RAG:SQL+向量驅動大模型與大數據新範式,MyScale AI資料庫正式開源

大模型與 AI 資料庫雙劍合璧,成為大模型降本增效,大數據真正智慧的致勝法寶。

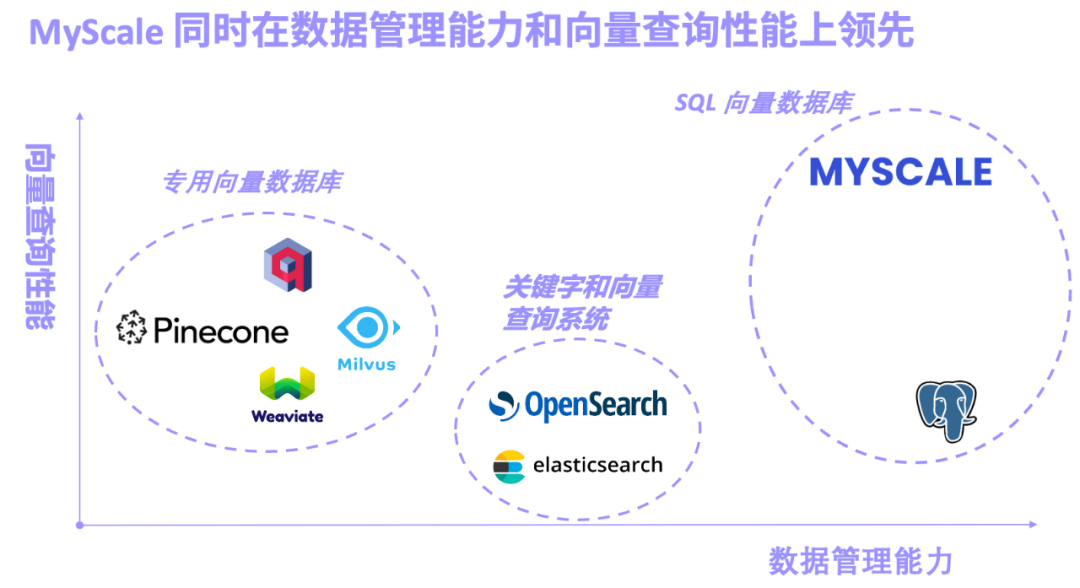
以Pinecone/Weaviate/Milvus 為代表的專用向量資料庫,一開始即為向量檢索設計打造,向量檢索性能出色,不過通用的數據管理功能較弱。 以Elasticsearch/OpenSearch 為代表的關鍵字與向量檢索系統,因其完善的關鍵字檢索功能而廣泛生產應用,不過系統資源佔用較多,關鍵字與向量的聯合查詢精度和效能不盡人如意。 以 pgvector(PostgreSQL 的向量搜尋外掛程式)和 MyScale AI 資料庫為代表的 SQL 向量資料庫,基於 SQL 且資料管理功能強大。不過因為 PostgreSQL 行存的劣勢和向量演算法的局限性,pgvector 在複雜向量查詢中精確度較低。
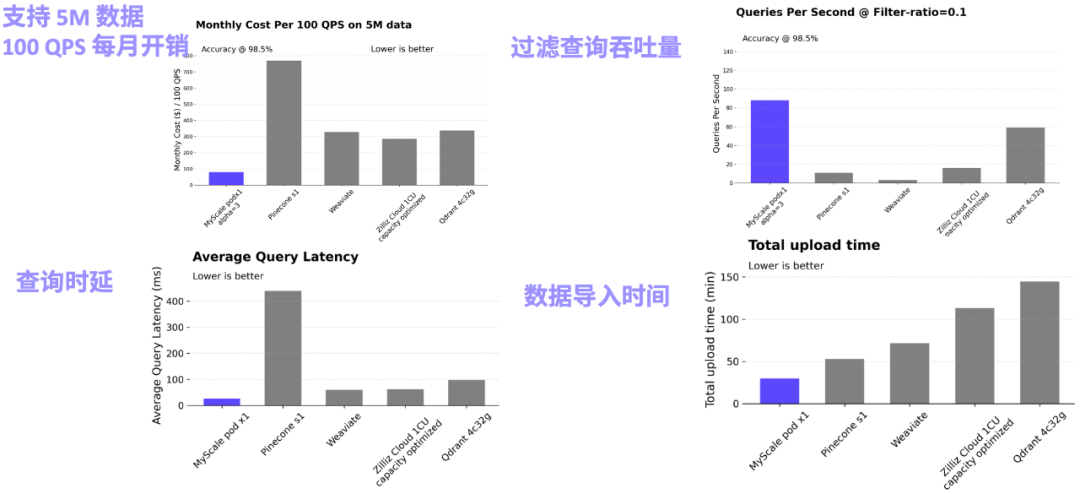
的提升。
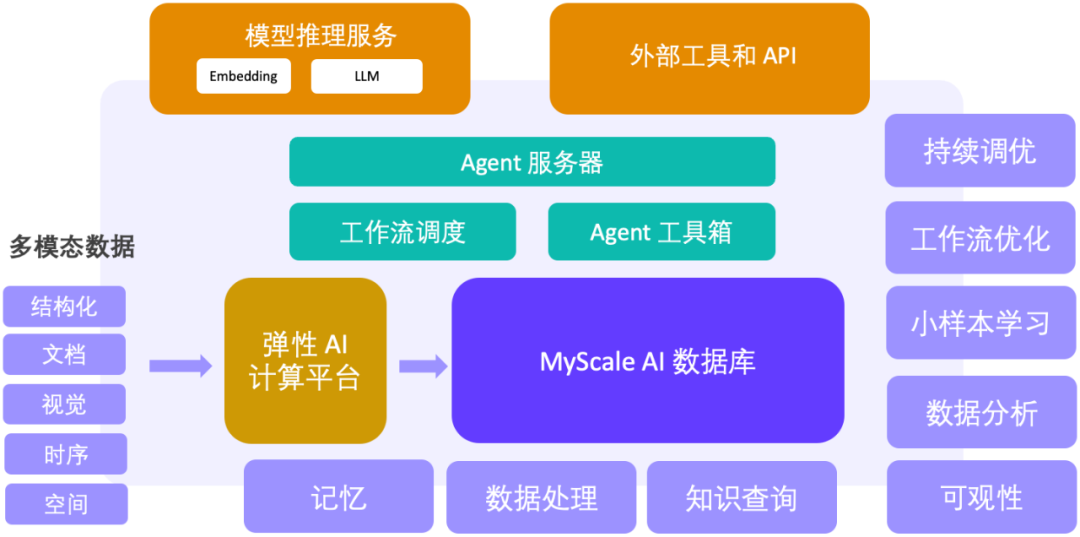
以上是長文本殺不死RAG:SQL+向量驅動大模型與大數據新範式,MyScale AI資料庫正式開源的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 git怎麼刪除倉庫
Apr 17, 2025 pm 04:03 PM
git怎麼刪除倉庫
Apr 17, 2025 pm 04:03 PM
要刪除 Git 倉庫,請執行以下步驟:確認要刪除的倉庫。本地刪除倉庫:使用 rm -rf 命令刪除其文件夾。遠程刪除倉庫:導航到倉庫設置,找到“刪除倉庫”選項,確認操作。
 git服務器怎麼連接公網
Apr 17, 2025 pm 02:27 PM
git服務器怎麼連接公網
Apr 17, 2025 pm 02:27 PM
將 Git 服務器連接到公網包括五個步驟:1. 設置公共 IP 地址;2. 打開防火牆端口(22、9418、80/443);3. 配置 SSH 訪問(生成密鑰對、創建用戶);4. 配置 HTTP/HTTPS 訪問(安裝服務端、配置權限);5. 測試連接(使用 SSH 客戶端或 Git 命令)。
 git代碼衝突怎麼處理
Apr 17, 2025 pm 02:51 PM
git代碼衝突怎麼處理
Apr 17, 2025 pm 02:51 PM
代碼衝突是指當多個開發者修改同一段代碼導致 Git 合併時無法自動選擇更改而出現的衝突。解決步驟包括:打開有衝突的文件,找出衝突代碼。手動合併代碼,將要保留的更改複製到衝突標記內。刪除衝突標記。保存並提交更改。
 git怎么生成ssh密鑰
Apr 17, 2025 pm 01:36 PM
git怎么生成ssh密鑰
Apr 17, 2025 pm 01:36 PM
為了安全連接遠程 Git 服務器,需要生成包含公鑰和私鑰的 SSH 密鑰。生成 SSH 密鑰的步驟如下:打開終端,輸入命令 ssh-keygen -t rsa -b 4096。選擇密鑰保存位置。輸入密碼短語以保護私鑰。將公鑰複製到遠程服務器上。將私鑰妥善保存,因為它是訪問帳戶的憑據。
 git怎麼檢測ssh
Apr 17, 2025 pm 02:33 PM
git怎麼檢測ssh
Apr 17, 2025 pm 02:33 PM
要通過 Git 檢測 SSH,需要執行以下步驟:生成 SSH 密鑰對。將公鑰添加到 Git 服務器。配置 Git 使用 SSH。測試 SSH 連接。根據實際情況解決可能遇到的問題。
 git賬戶怎麼添加公鑰
Apr 17, 2025 pm 02:42 PM
git賬戶怎麼添加公鑰
Apr 17, 2025 pm 02:42 PM
如何將公鑰添加到 Git 賬戶?步驟:生成 SSH 密鑰對。複製公鑰。在 GitLab 或 GitHub 中添加公鑰。測試 SSH 連接。
 git怎麼創建項目
Apr 17, 2025 pm 04:18 PM
git怎麼創建項目
Apr 17, 2025 pm 04:18 PM
使用 Git 創建項目需要以下步驟:1. 安裝 Git 官網下載相應版本的 Git 並安裝;2. 初始化項目使用 git init 創建存儲庫;3. 添加文件用 git add 將文件添加到暫存區;4. 提交更改用 git commit 提交更改並添加說明;5. 推送更改用 git push 將更改推送到遠程存儲庫;6. 拉取更改用 git pull 從遠程存儲庫獲取最新更改。
 git怎麼分開commit
Apr 17, 2025 pm 02:36 PM
git怎麼分開commit
Apr 17, 2025 pm 02:36 PM
使用 git 可以分開提交代碼,提供精細的變更追踪和獨立的工作能力。步驟如下: 1. 添加已更改的文件; 2. 提交特定更改; 3. 重複上述步驟; 4. 推送提交到遠程倉庫。
