

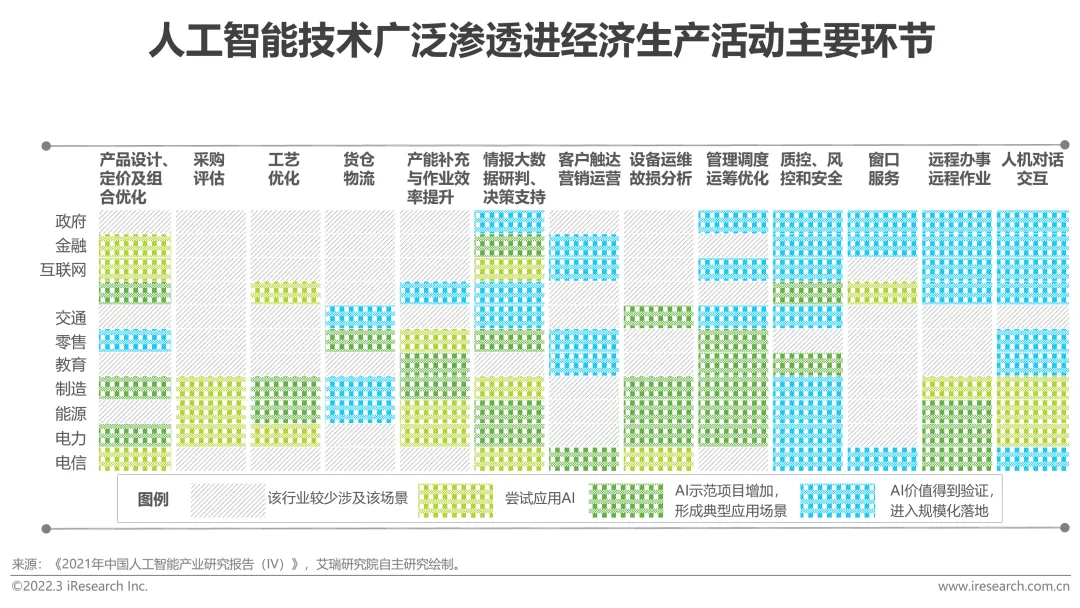
近年來,隨著新科技模式的出現,各產業應用場景價值打磨與大量資料累積下的產品效果提升,人工智慧應用已從消費、網路等領域,向製造業、能源、電力等傳統產業輻射。各產業企業在設計、採購、生產、管理、銷售等經濟生產活動主要環節的人工智慧技術和應用成熟度不斷提升,加速人工智慧在各環節的落地覆蓋,逐漸將其與主要業務相結合,以實現產業地位提高或經營效益優化,進一步擴大自身優勢。
人工智慧技術創新應用的大規模落地,推動了大數據智慧市場的蓬勃發展,同樣也為底層的數據治理服務注入了市場活力。
伴隨著大數據、雲端運算以及演算法的發展,人工智慧的熱潮從幾年前一直延續至今,並且廣泛應用於多個行業和領域,成為當前正在進行的科技革命的領導技術。而人工智慧在如火如荼的資料治理領域又怎麼能缺席呢?資料治理和人工智慧,看似不相關的兩個詞,他們兩個放一起,會發生什麼故事?
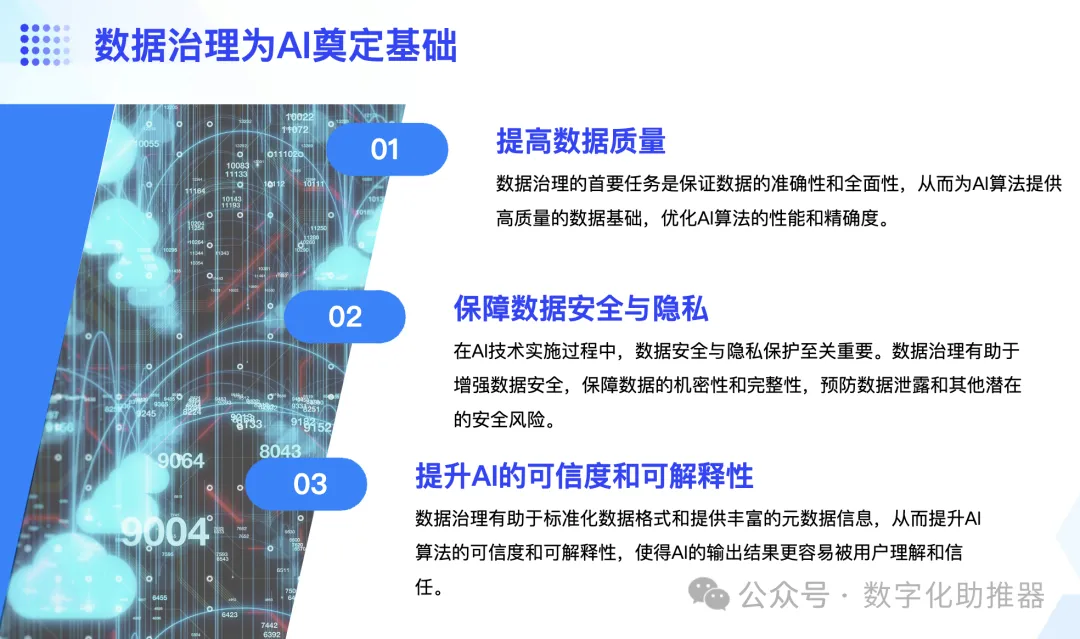
大數據是不斷累積、清洗、轉換、分類等的資料積累,而資料治理則為大數據的呈現提供了更為規範的管理模式。由於目前大部分人工智慧的形式需要透過大量的資料運算實現,因此離不開大數據和資料治理的支援。人工智慧需要依賴大數據平台和技術來幫助完成深度學習演化。

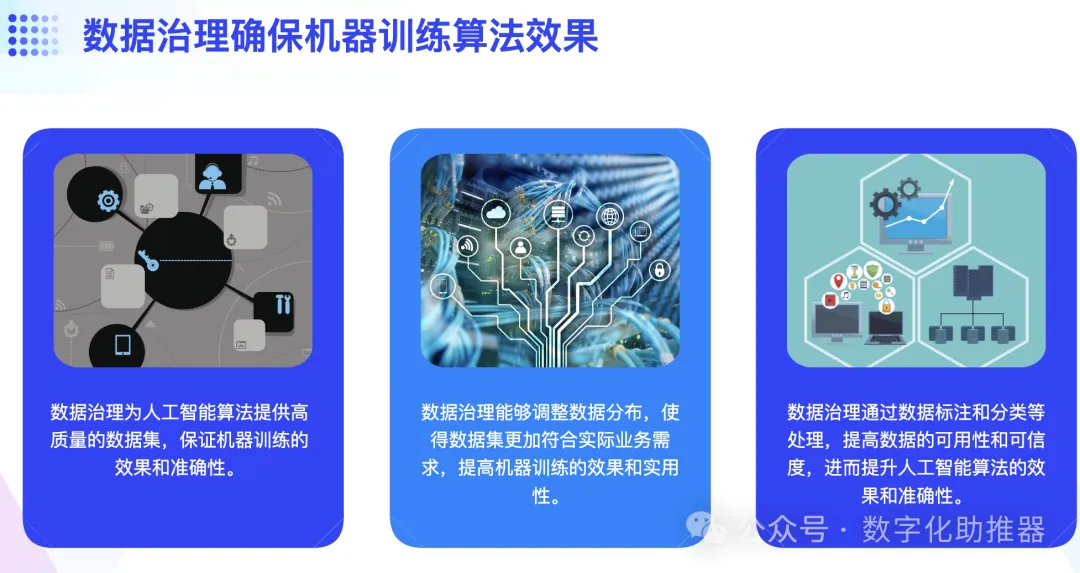
大部分的人工智慧分為訓練(Training)和預測(Predict)兩個環節。機器訓練演算法的效果依賴於所輸入的資料品質的優勢,如果輸入的資料有偏差,那麼輸出的演算法也會產生偏差,這可能直接導致所得結果的不可用。資料治理在提升資料品質方面具有重要作用。透過梳理資料品質需求、定義資料品質檢查規則、制定資料品質改善方案、設計並實施資料品質管理工具、監控資料品質管理作業程序和績效等資料品質管理環節,企業可以獲得乾淨的、結構清晰的數據,為深度學習等人工智慧技術提供可信賴的資料輸入。

目前人工智慧發展中面臨的很大限制是資料權屬和隱私權保護問題。個人隱私資料應該受到保護,這些資料的濫用可能對個人造成巨大的財產損失甚至人身傷害。所謂隱私保護,其實就是對隱私資料的保護,歸根究底就是對資料使用者的隱私保護。資料治理工具從技術層面設計了保護隱私資料的諸多環節,提供資料模糊化、資料脫敏、資料加密,可為企業個人資料保護奠定基礎,進而實現人工智慧應用的資料合規性。

在傳統的元資料管理中,對於非結構化資料的元資料擷取通常是透過建立非結構化資料的搜尋索引的方式。而語音辨識、影像辨識、文字分析等人工智慧技術可幫助實現元資料的最初業務詞庫的構建,成為提取各類有價值的非結構化元資料的資源池。

#在資料標準的實作初期,需要存量系統的資料庫字段進行摸底,識別出共有的、重複使用的業務字段,作為建立資料標準的依據。如果完全靠人工梳理,需要協調各業務部門大量人員參與,工作量龐大且容易出錯。借助機器學習、自然語言處理技術,可以根據字段業務名快速的整理出高頻詞根,將可能需要幾個月的工作在幾天內完成。
資料標準管理的另一個重要環節是標準與元資料的對應。在業務系統眾多,資料標準與業務系統的元資料進行映射往往是實施工程師的惡夢,一不小心就容易出錯。有了人工智慧技術,可以對業務欄位名稱進行自然語言處理,精確分詞,根據字根相似性將資料標準與元資料自動映射起來。
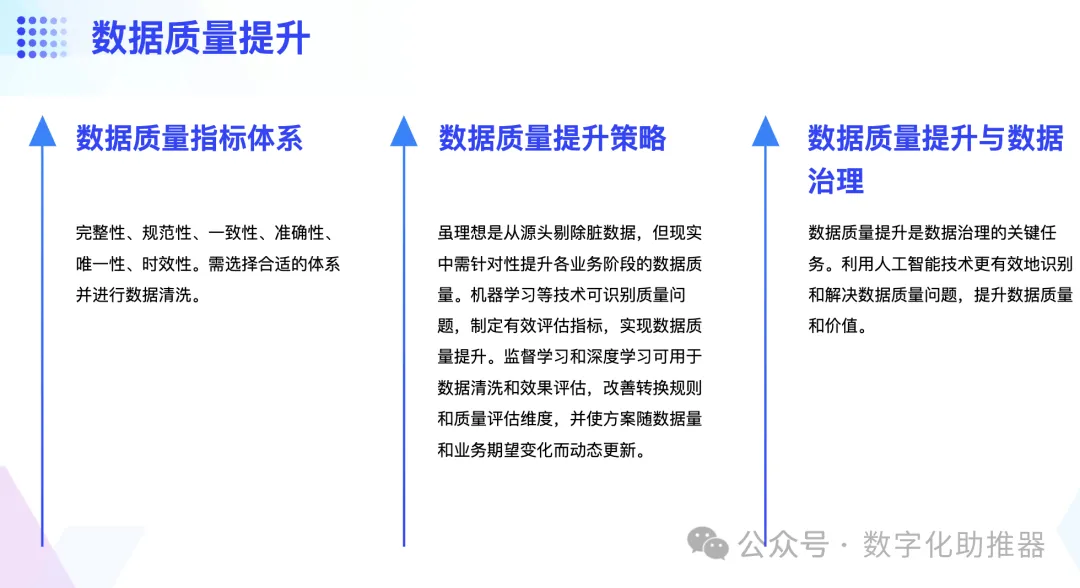
資料品質是保證資料高效應用的基礎。衡量資料品質的指標系統包括完整性、規範性、一致性、準確性、唯一性、時效性。在實施資料品質提升方案之前,需要依據不同的業務規則和業務期望選擇合適的資料品質指標體系,並進行資料的清洗。
一般資料品質改善的理想模式是從資料來源剔除髒數據,但在現實中並不可行。因此,根據業務期望,應針對性地提升各個業務階段的資料品質。機器學習(如分類學習、聚類、迴歸等)可擷取並識別存在的品質問題,從而製定有效的資料品質評估指標,以最大化實現此指標下的資料品質的提升。同時,監督學習、深度學習也將實現對資料清洗和資料品質的效果評估,進而改善轉換規則和資料品質評估維度,並隨著資料量和業務期望的逐漸變化,使資料品質提升方案動態更新。

#資料安全性是指讓資訊或資訊系統免受未經授權的存取、使用、破壞、修改、銷毀的過程或狀態。人工智慧技術可以進行敏感資料的分類分級。應用機器學習、自然語言處理和文字聚類分類技術,能對資料進行基於內容的即時精準分類分級,而資料的分類分級是資料安全治理的核心環節。例如,利用資料分類引擎在郵件內容過濾、保密文件管理、情報分析、反詐欺、資料防外洩等領域明顯提升了安全性。

#主資料指企業核心業務實體的數據,也叫黃金數據,是在整個價值鏈上被重複、共享應用於多個業務流程的、各個業務部門與各個系統之間共享的基礎數據,是各業務應用和各系統之間進行資訊交互的基礎。但在主資料管理的過程中,企業可能面臨如何在數量龐大的資料項中識別主資料、如何建立統一的主資料標準等問題。
確定主資料依賴企業對業務需求的理解和對應「黃金資料」的定義。通常來說,每個主資料主題域都有自己專用的記錄系統,並且分散在各個業務系統中。人工智慧相關技術可以幫助我們在所有數據中篩選出頻繁出現或流動的數據,同時快速確定主數據的可靠與可信任數據來源,建立完整的主數據視圖。

數劇管理面臨的一個挑戰是在企業眾多的系統中對於同一資料項目或重複的資料項目進行配對和合併,解決該挑戰的一個方法是建立資料匹配規則,包括不同置信水平的匹配接受度。有些匹配需要極高的信任度,可以基於跨多個字段的準確數據匹配實現;有些匹配僅僅由於數據值的衝突,可以採用較低的信任度。機器學習、自然語言處理可協助建立重複資料識別的配對規則,在識別欄位重複的主資料之後不進行自動合併,並確定與主資料相關的記錄,建立交叉引用關係。
透過人工智慧技術降低資料治理的門檻將成為資料治理發展的重要方向。充分考慮到數據治理高複雜性的特點,數據治理平台不斷融合AI新技術,力求透過智慧化管理來簡化數據治理實施過程,大大地解放技術人員,幫助企業實現更有效率的數據治理,遠離「數據黑洞」。

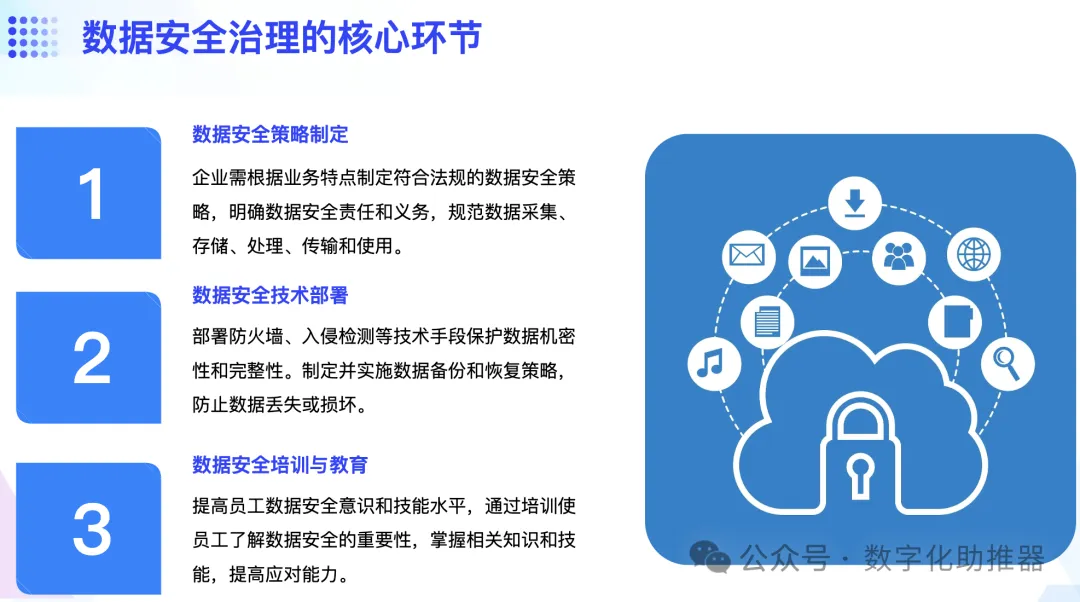
1、智慧化元資料服務。 睿治平台支援全自動元資料擷取與關聯,實現元模型智慧化應用,提供圖形化元資料分析視圖。
2、智慧化探查資料品質。 睿治平台內建數理統計演算法、綁定機器學習演算法,實現自動探查資料質量,同時支援智慧修復。
3、智慧化建構資料標準。 睿治平台支援智慧化映射及落標,形成的資料標準與業務資料雙向評估。
4、智慧化識別主資料。 睿治平台自動識別主數據,幫助重複數據自動匹配和合併,建立完整的主數據視圖。
隨著資料治理和人工智慧兩個領域的快速發展,二者的融合將會有更多場景和商業模式。
企業在部署AI應用時,資料資源的優劣極大程度決定了AI應用的落地效果。因此,為推動AI應用的高品質落地,開展針對性的資料治理工作為首要且必要的環節。而對於企業本身已建構的傳統資料治理體系,目前多停留在對於結構性資料的治理優化,在資料品質、資料欄位豐富度、資料分佈和資料即時性等維度尚難滿足AI應用對數據的高品質要求。 為確保AI應用的高品質落地,企業仍需進行以人工智慧應用的二次資料治理工作。 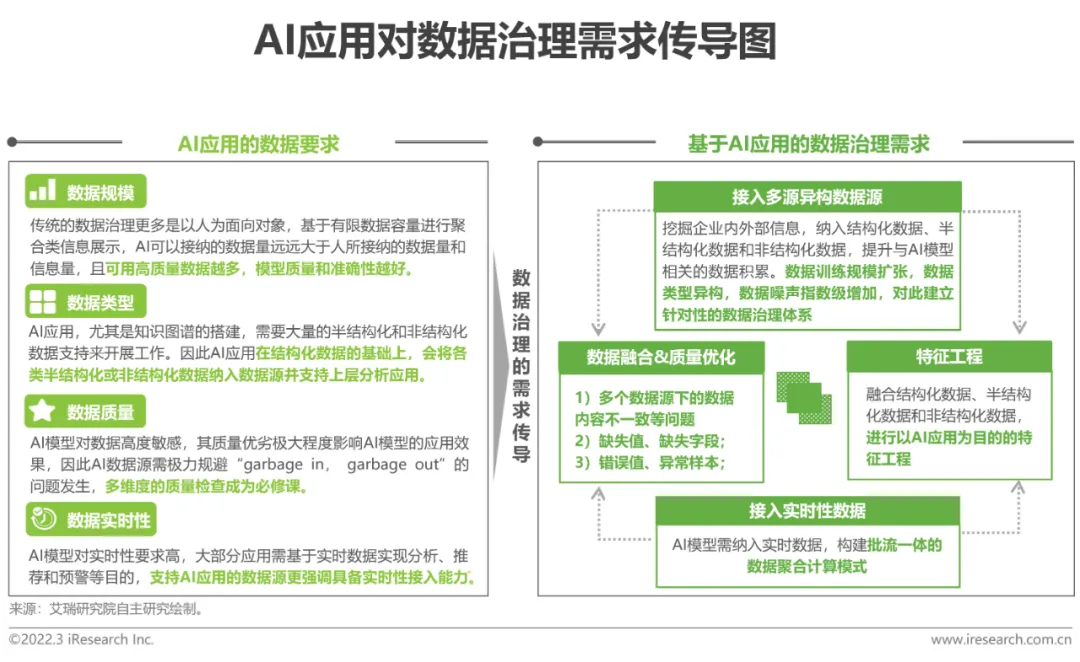
面向人工智慧的資料治理是傳統資料治理體系在以AI應用落地為導向下的體系「升級」。
從資料管理維度來看,以人工智慧為導向的資料治理體系仍會根據資料結構化流向、資料資產管理需求、資料安全需求等角度順應建構元資料管理、資料資產管理、主資料管理、資料生命週期管理和資料安全隱私管理等元件模組。而在資料治理過程中,則會更強調底層實現多源資料融合、資料擷取頻率、資料標準建立、資料品質管理,滿足AI模型所需資料的規模、品質和時效,以AI應用的資料需求為核心,優化對應模組的體系建置。
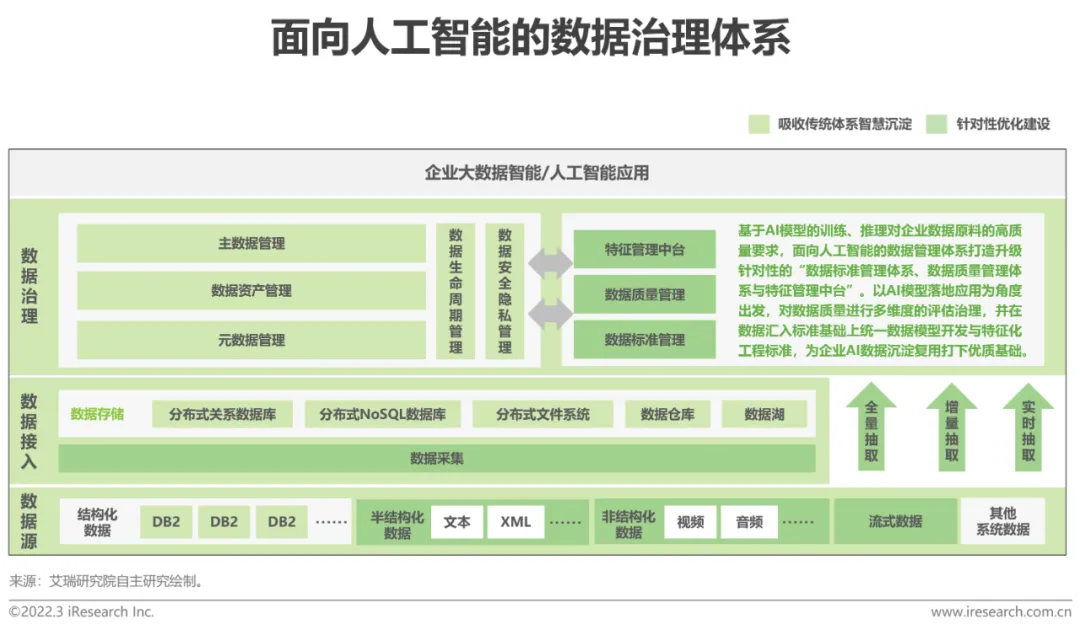
#以人工智慧為導向的資料治理服務常包含於資料服務、平台能力及資料產品三類採購形式中。第一類,資料服務即以單獨的資料治理產品形式出現;第二類,資料平台,主要包括大資料平台、資料中台、資料倉儲和AI能力平台等項目;第三類,資料產品,範圍限定在應用AI演算法的資料產品,可劃分為機器學習產品、自然語言理解產品及知識圖譜三類AI產品。
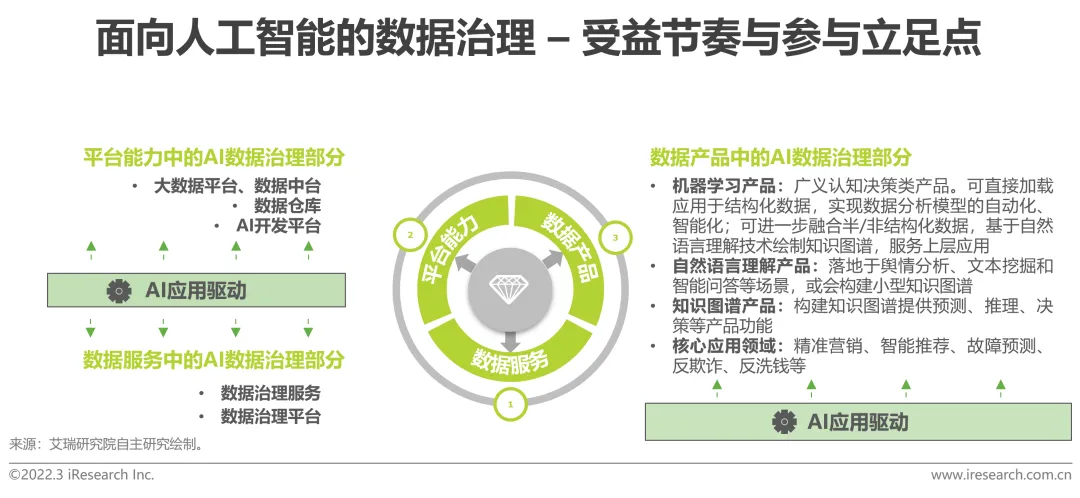
如今AI產品需求旺盛,AI開發平台陸續推進AI產品的規模化落地,且AI資料治理效果與最終平台產品交付效果緊密相連。
整體來看,尖端技術手段應用可以讓資料治理工作趨於流程化、自動化與智慧化,同時讓資料變得可擴展、更負責可溯、更可信,已然成為未來資料管理發展的必經之路。
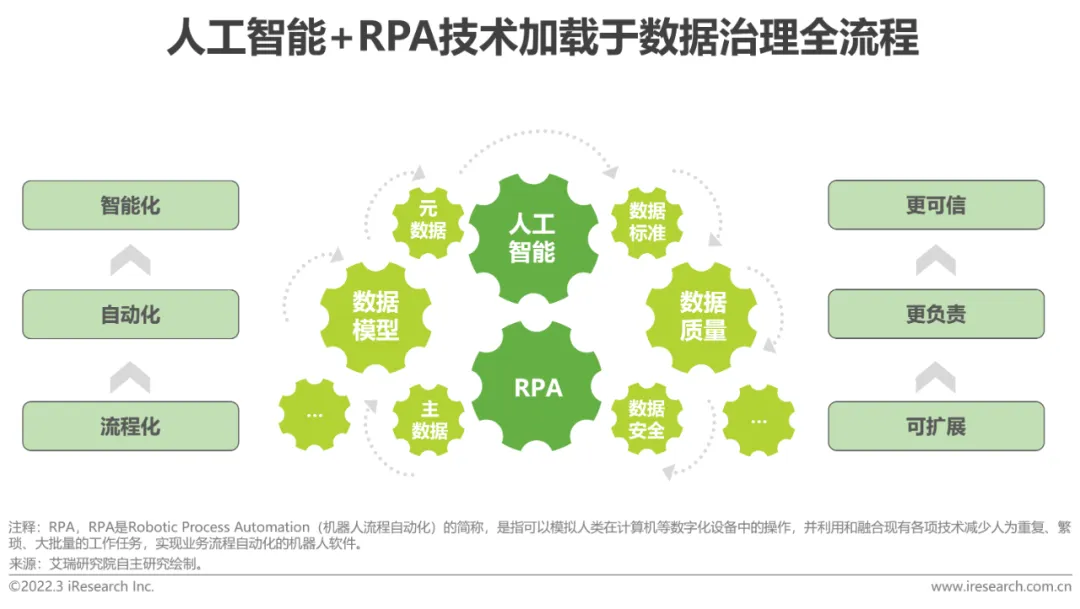
相互關聯,互為依托,共同促進人工智慧應用的內外發展
#以人工智慧為導向的資料治理充分利用機器學習技術,將資料治理環節自動化智慧化,可極大提升資料治理工作效率,同時基於自然語言理解和知識圖譜挖掘關聯非結構化資料的應用價值,解決資料品質管理的傳統難題,使治理後的資料更加契合AI應用的要求,從效率和質量雙側推進AI模型的落地應用。
同時,AI應用落地效果的顯著優化也會為企業帶來更多智慧轉型信心,讓其增加相關AI專案的預算投入,進一步推動相關治理體系建設,打造「治理AI」的良性循環
以上是以AI為導向的資料治理體系如何建構?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















